1. 정렬
1-1. ORDER BY
- 조회된 데이터들을 다양한 목적에 맞게 특정 칼럼을 기준으로 정렬하여 출력하는데 사용
- 컬럼명 대신 ALIAS나 컬럼 순서를 나타내는 정수 사용도 가능
- 기본적인 정렬 순서는 오름차순
- 숫자형 데이터 타입 : 오름차순으로 정렬했을 경우 가장 작은 값부터 출력
- 날짜형 데이터 타입 : 오름차순으로 정렬했을 경우 날짜 값이 가장 빠른 값이 먼저 출력 (과거가 먼저 출력)
ORDER BY절의 NULL 값
- Oracle은 NULL 값을 가장 큰 값으로 간주
- 오름차순으로 정렬했을 경우 가장 마지막에, 내림차순의 경우 가장 먼저 위치
- SQL SERVER는 NULL 값을 가장 작은 값으로 간주
2. 그룹
2-1. GROUP BY
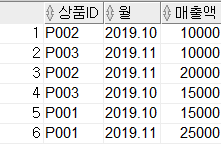
2-2. ROLLUP
- 인수의 순서에 영향을 받음
ROLLUP(item_id, month)
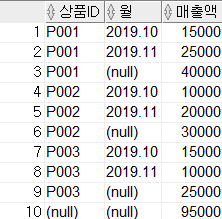
SELECT item_id, month, SUM(amount) AS amount
FROM sales
GROUP BY ROLLUP(item_id, month);ROLLUP(month, item_id)
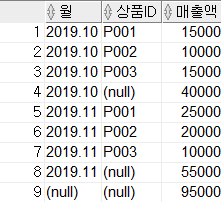
SELECT month, item_id, SUM(amount) AS amount
FROM sales
GROUP BY ROLLUP(month, item_id);2-3. CUBE
- 그룹핑 컬럼이 가질 수 있는 모든 경우의 수에 대하여 소계(SUBTOTAL)과 총계(GRAND TOTAL)을 생성
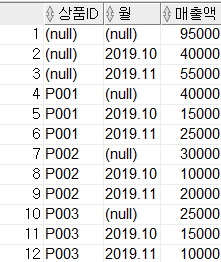
SELECT item_id, month, SUM(amount) AS amount
FROM sales
GROUP BY CUBE(item_id, month);2-4. GROUPING SETS
- 인자별 소계(SUBTOTAL)만이 생성됨
- ROLLUP과 CUBE와 달리 계층 구조가 나타나지 않음 > 인자의 순서가 달라도 결과는 동일
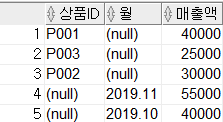
SELECT item_id, month, SUM(amount) AS amount
FROM sales
GROUP BY GROUPING SETS(item_id, month);- 괄호로 묶은 집합별로도 집계를 구할 수 있음
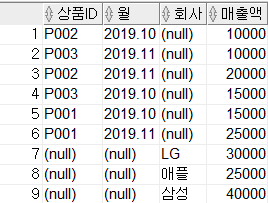
SELECT item_id, month, company, SUM(amount) AS amount
FROM sales
GROUP BY GROUPING SETS((item_id, month), company);2-5. GROUPING
- 직접 그룹별 집계를 구하지는 않지만 ROLLUP, CUBE, GROUPING SETS를 지원하는 역할
- 집계가 계산된 결과는
GROUPING(표현식) = 1, 그 외에는GROUPING(표현식) = 0
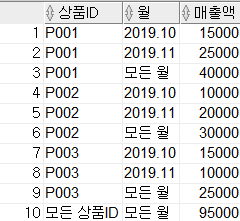
SELECT
CASE GROUPING(item_id) WHEN 1 THEN '모든 상품ID' ELSE item_id END AS item_id,
CASE GROUPING(month) WHEN 1 THEN '모든 월' ELSE month END AS month,
SUM(amount) AS amount
FROM sales
GROUP BY GROUPING SETS((item_id, month), company);3. 집합 연산자
- 서로 다른 두 개의 결과를 연산을 통해 새로운 결과 추출
집합 연산자 사용 조건
- 두 집합의 SELECT 절에 오는 컬럼의 개수, 데이터 타입이 동일해야 함
- 두 집합의 컬럼명은 달라도 상관 없음
집합 연산자의 종류
UNION: 두 집합을 더해서 결과를 출력 / 중복 값 제거하고 정렬UNION ALL: 두 집합을 더해서 결과를 출력 / 중복 값 제거 안하고 정렬 안함INTERSECT: 두 집합의 교집합 결과를 정렬하여 출력MINUS: 두 집합의 차집합 결과를 출력 / 쿼리의 순서 중요 / INTERSECT와 반대의 결과
3-1. INTERSECT
- 데이터의 타입, 순서, 개수가 맞아야 함
SELECT col1, col2 FROM table1
INTERSECT
SELECT col3, col4 FROM table2;
개린이