✔️ Kafka의 정의
- 빠르고 확장 가능한 작업을 위해 데이터 피드의 분산 스트리밍, 파이프 라이닝 및 재생을 위한 실시간 스트리밍 데이터를 처리하기 위한 목적을 설계된 오픈 소스 분산형 게시-구독 메시징 플랫폼
- 서버 클러스터 내에서 데이터 스트림을 레코드로 유지하는 방식으로 작동하는 브로커 기반 솔루션
- 여러 데이터 센터에 분산되어 있을 수 있으며 여러 서버 인스턴스에 걸쳐 레코드 스트림(메시지)을 토픽으로 저장하여 데이터 지속성을 제공할 수 있다.
✔️ Kafka 프로세스
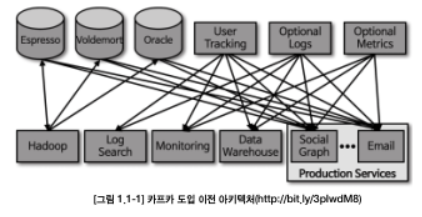

- 각각의 애플리케이션끼리 연결하여 데이터를 처리하는 것이 아니라 한 곳에 모아 처리할 수 있도록 중앙집중화했다. 따라서 데이터 스트림을 한 곳에서 실시간으로 관리할 수 있게 해준다.
- 카프카를 중앙에 배치함으로써 소스 애플리케이션과 타깃 애플리케이션 사이의 의존도를 최소화하여 커플링을 완화하였다.
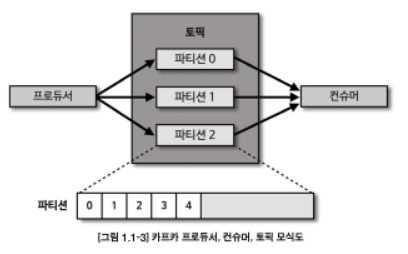
- 카프카 내부에 데이터가 저장되는 파티션의 동작은 FIFO 방식의 큐 자료구조와 유사하다. 큐에 데이터를 보내는 것이 프로듀서이고 데이터를 가져가는 것이 컨슈머이다.
- 카프카는 최소 3대 이상의 서버(브로커)에서 분산 운영하여 프로듀서를 통해 전송받은 데이터를 파일 시스템에 안전하게 기록한다. 서버 3대 이상으로 이루어진 카프카 클러스터 중 일부 서버에 장애가 발생하더라도 데이터를 지속적으로 복제하기 때문에 안전하게 운영할 수 있다.
- 또한, 데이터를 묶음 단위로 처리하는 배치 전송을 통해 낮은 지연과 높은 데이터 처리량도 가지게 되었다.
✔️ Kafka 핵심 요소
👉 Event (메시지)
producer와 consumer가 데이터를 주고 받는 단위
👉 Producer
이벤트를 게시(post)하는 클라이언트 어플리케이션
👉 Consumer
Topic을 구독하고 이로부터 얻어낸 이벤트를 처리하는 클라이언트 어플리케이션
👉 Topic
이벤트가 게시되고 가져가지는 곳. 파일시스템의 폴더와 유사하며, 이벤트는 폴더 안의 파일과 유사하다.
👉 Partition
Topic은 여러 Broker에 분산되어 저장되며, 이렇게 분산된 Topic을 Partition이라고 한다. 같은 Key(키)를 가지는 이벤트는 같은 Partition에 저장된다.
👉 Pull 모델
Consumer는 Pull 모델을 기반으로 메시지 처리를 진행한다. 즉, Broker가 Consumer에게 메시지를 전달하는 것이 아닌 Consumer가 필요할 때 Broker로부터 메시지를 가져와 처리하는 형태이다.
✔️ 빅데이터 파이프라인에서 카프카의 역할
❄️ 데이터 레이크 (data lake)
- 빅데이터를 저장하고 활용하기 위해 일단 생성되는 데이터를 모두 모으는 것
- 데이터 웨어하우스와 다르게 필터링되거나 패키지화되지 않은 데이터가 저장된다.
- 운영되는 서비스로부터 수집 가능한 모든 데이터를 모으는 것이다.
- 엔드 투 엔드 방식
- 하지만 점점 서비스가 비대해지고 복잡해지면서 파편화되고 올라가는 문제점이 발생한다.
🥗 데이터 파이프라인
- 위의 문제점을 해결하기 위해 데이터 추출(extracting), 변경(transforming), 적재(loading)하는 과정을 묶은 것
- 엔드 투 엔드 방식의 데이터 수집 및 적재를 개선하고 안정성을 추구하며, 유연하면서도 확장 가능하게 자동화하였다.
✔️ 아파치 카프카가 왜 데이터 파이프라인으로 적합한가?
1️⃣ 높은 처리량
- 동일한 양의 데이터를 보낼 때 네트워크 통신 횟수를 최소한으로 줄인다면 동일 시간 내에 더 많은 데이터를 전송할 수 있다.
- 많은 양의 데이터를 묶음 단위로 처리하는 배치로 빠르게 처리할 수 있기 때문에 대용량의 실시간 로그데이터를 처리하는 데에 적합하다.
- 또한, 파티션 단위를 통해 동일 목적의 데이터를 여러 파티션에 분배하고 데이터를 병렬 처리할 수 있다.
- 파티션 개수만큼 컨슈머 개수를 늘려서 동일 시간당 데이터 처리량을 늘리는 것이다.
2️⃣ 확장성
- 가변적인 환경에서 안정적으로 확장 가능하도록 설계되었다.
- 브로커의 개수를 늘리고 줄이는 스케일 아웃, 스케일 인이 가능하다.
3️⃣ 영속성
- 생성한 프로그램이 종료되더라도 사라지지 않는 데이터의 특성
- 전송 받은 데이터를 메모리에 저장하지 않고 파일 시스템에 저장한다.
- 페이지 캐시 영역을 메모리에 따로 생성하여 사용한다.
- 캐시 메모리 영역을 사용하여 한 번 읽은 파일 니용은 메모리에 저장시켰다가 다시 사용하는 방식이기 때문에 카프카가 파일 시스템에 저장하고 데이터를 저장, 전송하더라도 처리량이 높다.
4️⃣ 고가용성
- 3개 이상의 서버들로 운영되는 카프카 클러스터는 일부 서버에 장애가 발생하더라도 무중단으로 안전하고 지속적으로 데이터를 처리할 수 있다
- 클러스터로 이루어진 카프카는 데이터의 복제를 통해 고가용성의 특징을 갖는다.
- 프로듀서로 전송 받은 데이터를 여러 브로커에 저장하는 것이다.
❓ 카프카 클러스터를 3대 이상의 브로커들로 구성해야 하는 이유
카프카를 안전하게 운영하기 위해 최소 3대 이상의 브로커로 클러스터를 구성할 것을 추천한다.
1대 → 브로커의 장애가 서비스의 장애로 이어지므로 테스트 목적으로만 사용한다.
2대 → 한 대의 브로커에 장애가 발생하더라도 나머지 한 대 브로커가 살아 있으므로 안정적인 데이터 처리가 가능하다. 하지만 브로커 간 데이터가 복제되는 시간 차이로 인해 일부 데이터가 유실될 가능성이 있다.
유실을 막기 위해 min.insync.replicas 옵션을 2로 설정하면 최소 2개 이상의 브로커에 데이터가 완전히 복제됨을 보장하며, 이 때 브로커를 3대 이상으로 운영해야만 한다. 3개 중 1개의 브로커에 장애가 나더라도 지속적으로 데이터를 처리할 수 있기 때문이다.
[참고]
(도서) 아파치 카프카 애플리케이션 프로그래밍 with 자바 | 최원영 지음
https://www.tibco.com/ko/reference-center/what-is-apache-kafka
