2024-06-21

안녕하세요
오늘은 금요일이에요 ㅡ,,.
좀 더 힘내보고 잠 좀 잡시다
♾️ DBScan / K-means
저희 조는 스포티파이 데이터셋을 가지고
각자 다른 전처리 방식을 이용하고
StandardScaler 표준화를 통일하여
클러스터링 기법 또한 다르게 진행해보았는데요 !!
저는 오늘
DBScan 이상치 제거
→ StandardScaler 표준화
→ PCA 분석
→ K-means 클러스터링
위 군집 분석을 총합해
실루엣 계수와 시각화를 통해 군집이 어떻게 잘 이뤄졌는지 하루종일
🤪🌀🤪🌀🤪🌀🤪🌀
돌려봤답니다 !!
맨 처음에 했던 코드는
# 데이터 불러오기
sp_df = pd.read_csv('/6월_심화프로젝트/data/data.csv')
# 선택할 특성 컬럼
cols = ['valence', 'acousticness', 'danceability', 'energy', 'loudness', 'tempo', 'instrumentalness', 'key', 'liveness']
# 이상치 제거를 위한 DBSCAN (스케일링 없이 원본 데이터 사용)
pca = PCA(n_components=4)
pca_df = pca.fit_transform(sp_df[cols])
pca_df = pd.DataFrame(data=pca_df, columns=['PC1', 'PC2', 'PC3', 'PC4'])
outlier_detection = DBSCAN(eps=0.5, min_samples=10)
outliers = outlier_detection.fit_predict(pca_df)
# 이상치를 제외한 데이터프레임 생성
pca_df['Outlier'] = outliers
filtered_df = pca_df[pca_df['Outlier'] != -1]
# 이상치 제거 후 원본 데이터에서 동일한 행만 선택
filtered_sp_df = sp_df.iloc[filtered_df.index]
# 데이터 스케일링 (스탠다드)
scaler = StandardScaler()
filtered_scaled = scaler.fit_transform(filtered_sp_df[cols])
filtered_scaled_df = pd.DataFrame(filtered_scaled, columns=cols)
# 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지
pca_final = PCA(n_components=4)
pca_final.fit(filtered_scaled_df)
print('pca_final :', pca_final.explained_variance_ratio_, '/', pca_final.explained_variance_ratio_.sum())
출력값 :
pca_final : [0.29655379 0.16400035 0.10988422 0.10918926] / 0.6796276107577658
# 주성분 분석 (PCA)
pca_final_df = pca_final.fit_transform(filtered_scaled_df)
pca_final_df = pd.DataFrame(data=pca_final_df, columns=['PC1', 'PC2', 'PC3', 'PC4'])
# K-means를 사용하여 클러스터링
model = KMeans()
visualizer = KElbowVisualizer(model, k=(3, 12))
visualizer.fit(pca_final_df)
visualizer.show()
# KMEANS
# 군집개수(n_cluster) 6이 나왔지만
optimal_k = 4
kmeans = KMeans(n_clusters=optimal_k, random_state=42, init='random')
# pca df를 이용한 kmeans 알고리즘 적용
kmeans.fit(pca_final_df)
clusters = kmeans.fit_predict(pca_final_df)
# 클러스터 번호 가져오기
labels = kmeans.labels_
# 클러스터 번호가 할당된 데이터셋 생성
kmeans_df = pd.concat([pca_final_df, pd.DataFrame({'Cluster': labels})], axis=1)
# 시각화를 위한 2차원 플롯
plt.figure(figsize=(8, 8))
sns.scatterplot(data=kmeans_df, x='PC1', y='PC2', hue='Cluster')
plt.title('The Plot Of The Clusters (2D)')
plt.show()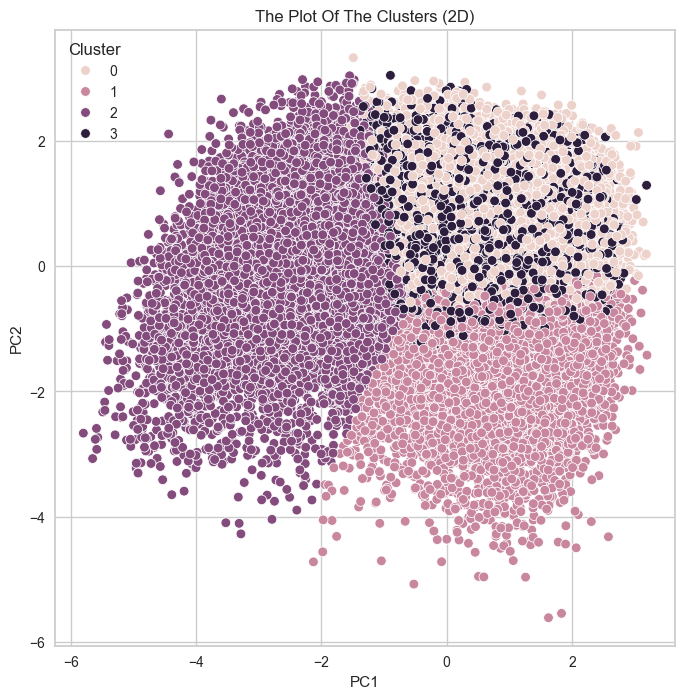
kmeans_df.value_counts('Cluster')
출력값 : Cluster
0 12487
2 11749
3 11474
1 10158
Name: count, dtype: int64
# 실루엣 계수 계산
silhouette_avg = silhouette_score(filtered_scaled_df, clusters)
silhouette_values = silhouette_samples(filtered_scaled_df, clusters)
print("Silhouette Score:", silhouette_avg)
출력값 : Silhouette Score: 0.2324696606740722
# 실루엣 플롯 생성
fig, ax = plt.subplots(figsize=(10, 6))
y_lower, y_upper = 0, 0
for i in range(optimal_k):
ith_cluster_silhouette_values = silhouette_values[clusters == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = plt.cm.nipy_spectral(float(i) / optimal_k)
ax.fill_betweenx(np.arange(y_lower, y_upper),
0, ith_cluster_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
ax.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper
ax.set_title("The silhouette plot for the various clusters.")
ax.set_xlabel("The silhouette coefficient values")
ax.set_ylabel("Cluster label")
ax.axvline(x=silhouette_avg, color="red", linestyle="--")
ax.set_yticks([]) # Clear the yaxis labels / ticks
ax.set_xticks(np.arange(-0.1, 1.1, 0.2))
plt.show()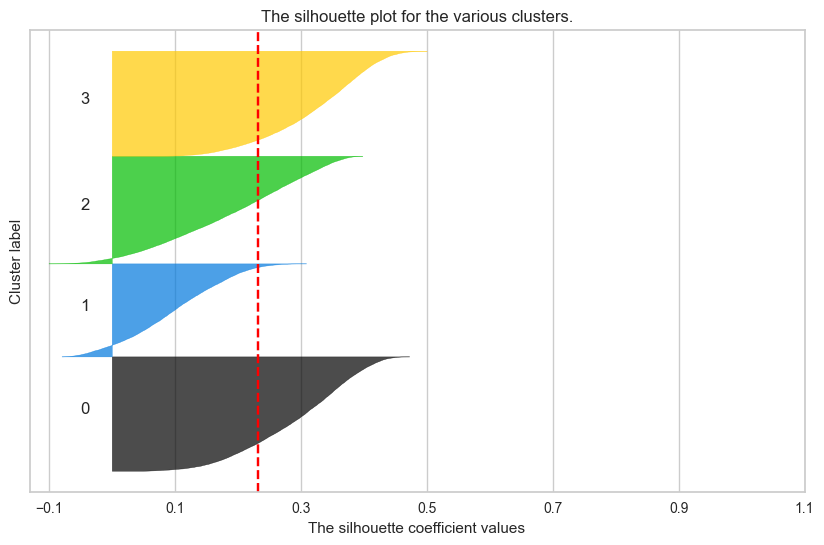
📌 선정 칼럼
'valence'
'acousticness'
'danceability'
'energy'
'loudness'
'tempo'
'instrumentalness'
'key'
'liveness'
총 9개
실질적으로 칼럼은 총 19개가 있었지만
범주형 데이터를 제외하고,
유저에게 음원 추천 서비스모델을 진행하는데 연관성이 없는 발매연도나 발매일을 제외하고
청취자가 직접적으로 느낄만한 정성적인 데이터, 주관적인 감정이 들만한 컬럼으로만 뽑았다
마치라잌 곡의 빠르기나 춤을 출만한 정도인지, 에너지가 느껴지는지 요로콤총합해서 돌린 데이터 셋의 군집을 살펴보면
주성분의 설명력을 가지는 수치가 0.67로 나쁘지도 않고
실루엣 계수가 0.22로 그리 나쁜 수치도 아니긴 하다만
본 데이터 갯수가 17만개인데 이상치 제거를 통해서 클러스터를 확인해보면
0 12487
2 11749
3 11474
1 10158분포는 잘 됐지만,,,,,,
과반수를 훨씬 넘게 데이터가 삭제당했고
2차원 pca 시각화 또한 잘 뭉쳐져있지만 이리저리 영역침범이 된 걸 볼 수 있다.
그래서 두번째 시도 !!
# 데이터 불러오기
sp_df = pd.read_csv('6월_심화프로젝트/data/data.csv')
# 선택할 특성 컬럼
cols = ['valence', 'acousticness', 'danceability', 'energy', 'loudness', 'tempo', 'instrumentalness']
# 이상치 제거를 위한 DBSCAN (스케일링 없이 원본 데이터 사용)
pca = PCA(n_components=4)
pca_df = pca.fit_transform(sp_df[cols])
pca_df = pd.DataFrame(data=pca_df, columns=['PC1', 'PC2', 'PC3', 'PC4'])
outlier_detection = DBSCAN(eps=0.5, min_samples=10)
outliers = outlier_detection.fit_predict(pca_df)
# 이상치를 제외한 데이터프레임 생성
pca_df['Outlier'] = outliers
filtered_df = pca_df[pca_df['Outlier'] != -1]
# 이상치 제거 후 원본 데이터에서 동일한 행만 선택
filtered_sp_df = sp_df.iloc[filtered_df.index]
# 데이터 스케일링 (스탠다드)
scaler = StandardScaler()
filtered_scaled = scaler.fit_transform(filtered_sp_df[cols])
filtered_scaled_df = pd.DataFrame(filtered_scaled, columns=cols)
# 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지
pca_final = PCA(n_components=4)
pca_final.fit(filtered_scaled_df)
print('pca_final :', pca_final.explained_variance_ratio_, '/', pca_final.explained_variance_ratio_.sum())
출력값 :
pca_final : [0.43367162 0.1830631 0.12641238 0.11804259] / 0.861189695966337
# 주성분 분석 (PCA)
pca_final_df = pca_final.fit_transform(filtered_scaled_df)
pca_final_df = pd.DataFrame(data=pca_final_df, columns=['PC1', 'PC2', 'PC3', 'PC4'])
# K-means를 사용하여 클러스터링
model = KMeans()
visualizer = KElbowVisualizer(model, k=(3, 12))
visualizer.fit(pca_final_df)
visualizer.show()
# KMEANS
# 군집개수(n_cluster) 이번엔 그래프에 나온대로 7로 설정
optimal_k = 7
kmeans = KMeans(n_clusters=optimal_k, random_state=42, init='random')
# pca df를 이용한 kmeans 알고리즘 적용
kmeans.fit(pca_final_df)
clusters = kmeans.fit_predict(pca_final_df)
# 클러스터 번호 가져오기
labels = kmeans.labels_
# 클러스터 번호가 할당된 데이터셋 생성
kmeans_df = pd.concat([pca_final_df, pd.DataFrame({'Cluster': labels})], axis=1)
# 시각화를 위한 2차원 플롯
plt.figure(figsize=(8, 8))
sns.scatterplot(data=kmeans_df, x='PC1', y='PC2', hue='Cluster')
plt.title('The Plot Of The Clusters (2D)')
plt.show()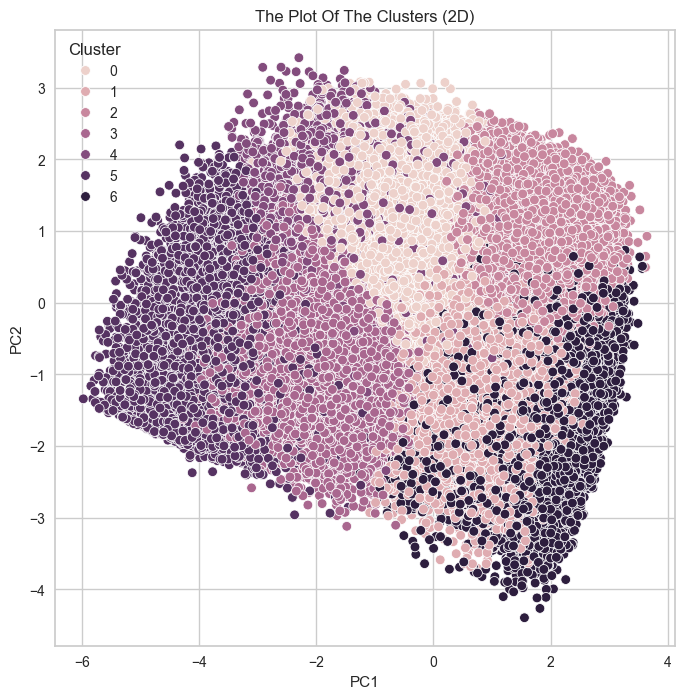
kmeans_df.value_counts('Cluster')
출력값 : Cluster
2 32488
0 30827
3 23158
1 22354
6 20807
5 9181
4 8985
Name: count, dtype: int64
# 실루엣 계수 계산
silhouette_avg = silhouette_score(filtered_scaled_df, clusters)
silhouette_values = silhouette_samples(filtered_scaled_df, clusters)
print("Silhouette Score:", silhouette_avg)
출력값 : Silhouette Score: 0.35773682057075473
# 실루엣 플롯 생성
fig, ax = plt.subplots(figsize=(10, 6))
y_lower, y_upper = 0, 0
for i in range(optimal_k):
ith_cluster_silhouette_values = silhouette_values[clusters == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = plt.cm.nipy_spectral(float(i) / optimal_k)
ax.fill_betweenx(np.arange(y_lower, y_upper),
0, ith_cluster_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
ax.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper
ax.set_title("The silhouette plot for the various clusters.")
ax.set_xlabel("The silhouette coefficient values")
ax.set_ylabel("Cluster label")
ax.axvline(x=silhouette_avg, color="red", linestyle="--")
ax.set_yticks([]) # Clear the yaxis labels / ticks
ax.set_xticks(np.arange(-0.1, 1.1, 0.2))
plt.show()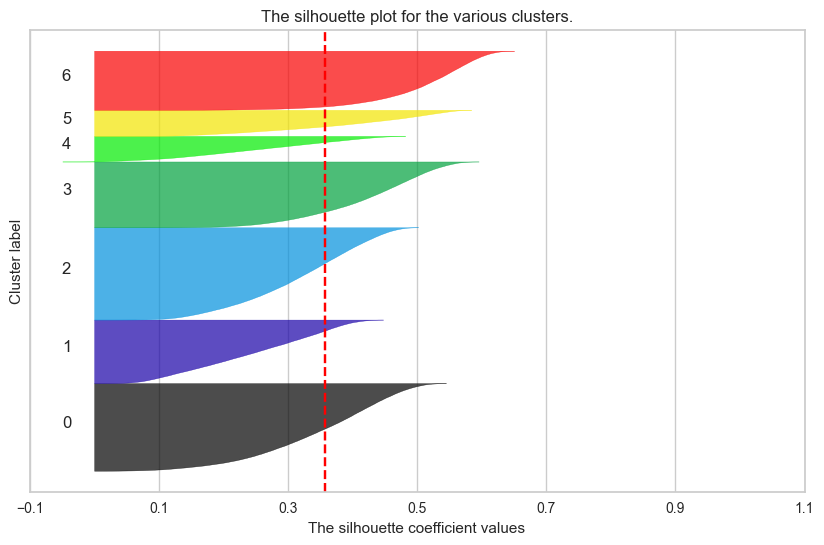
📌 선정 칼럼
'valence'
'acousticness'
'danceability'
'energy'
'loudness'
'tempo'
'instrumentalness'
총 7개
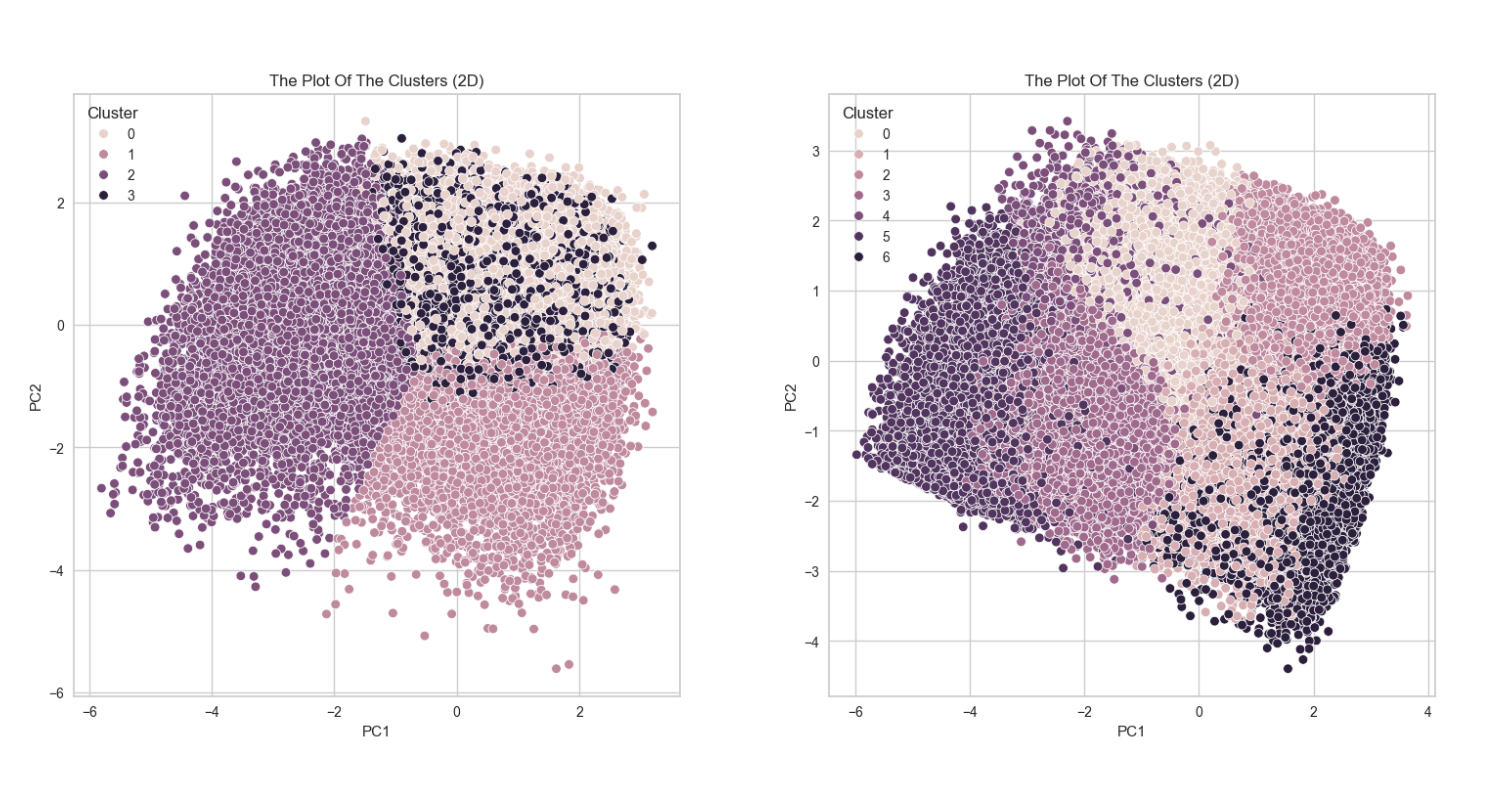
왼쪽이 첫번째 코드
오른쪽이 두번째 코드이번엔 클러스터 개수를 7개로 해보았는데
흠... 오른쪽이 클러스터가 4개인 걸 상대적으로 비교하면
7개치고 군집이 잘 된 편이긴 하고..
이상치를 제거해서 날라간 데이터도 3만 개로 비교적 첫번째보단 훨씬 덜 날라갔고
실루엣 계수도 훨씬 높지만
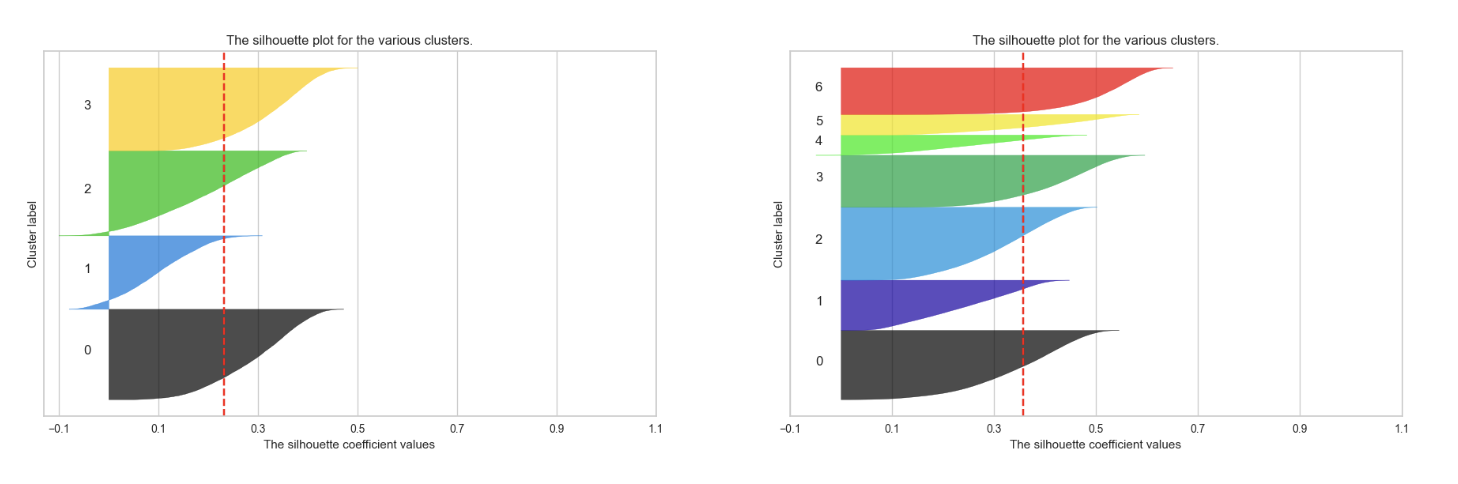
차라리 클러스터가 4개인 게 나은 것 같다.
진짜 라스트팡
📌 선정 칼럼
'valence'
'acousticness'
'danceability'
'energy'
'loudness'
'tempo'
총 6개
# 데이터 불러오기
sp_df = pd.read_csv('6월_심화프로젝트/data/data.csv')
# 선택할 특성 컬럼
cols = ['valence', 'acousticness', 'danceability', 'energy', 'loudness', 'tempo']
# 이상치 제거를 위한 DBSCAN (스케일링 없이 원본 데이터 사용)
pca = PCA(n_components=4)
pca_df = pca.fit_transform(sp_df[cols])
pca_df = pd.DataFrame(data=pca_df, columns=['PC1', 'PC2', 'PC3', 'PC4'])
outlier_detection = DBSCAN(eps=0.5, min_samples=10)
outliers = outlier_detection.fit_predict(pca_df)
# 이상치를 제외한 데이터프레임 생성
pca_df['Outlier'] = outliers
filtered_df = pca_df[pca_df['Outlier'] != -1]
# 이상치 제거 후 원본 데이터에서 동일한 행만 선택
filtered_sp_df = sp_df.iloc[filtered_df.index]
# 데이터 스케일링 (스탠다드)
scaler = StandardScaler()
filtered_scaled = scaler.fit_transform(filtered_sp_df[cols])
filtered_scaled_df = pd.DataFrame(filtered_scaled, columns=cols)
# 설정한 주성분의 갯수로 전체 데이터 분산을 얼만큼 설명 가능한지
pca_final = PCA(n_components=4)
pca_final.fit(filtered_scaled_df)
print("Explained Variance Ratio Sum:", pca_final.explained_variance_ratio_.sum())
출력값 : Explained Variance Ratio Sum: 0.9173151766020753
# 주성분 분석 (PCA)
pca_final_df = pca_final.fit_transform(filtered_scaled_df)
pca_final_df = pd.DataFrame(data=pca_final_df, columns=['PC1', 'PC2', 'PC3', 'PC4'])
# K-means를 사용하여 클러스터링
model = KMeans()
visualizer = KElbowVisualizer(model, k=(3, 12))
visualizer.fit(pca_final_df)
visualizer.show()
# KMEANS
# 군집개수(n_cluster) 6, 초기 중심 설정방식 랜덤
optimal_k = 4
kmeans = KMeans(n_clusters=optimal_k, random_state=42, init='random')
# pca df를 이용한 kmeans 알고리즘 적용
kmeans.fit(pca_final_df)
clusters = kmeans.fit_predict(pca_final_df)
# 클러스터 번호 가져오기
labels = kmeans.labels_
# 클러스터 번호가 할당된 데이터셋 생성
kmeans_df = pd.concat([pca_final_df, pd.DataFrame({'Cluster': labels})], axis=1)
# 시각화를 위한 2차원 플롯
plt.figure(figsize=(8, 8))
sns.scatterplot(data=kmeans_df, x='PC1', y='PC2', hue='Cluster')
plt.title('The Plot Of The Clusters (2D)')
plt.show()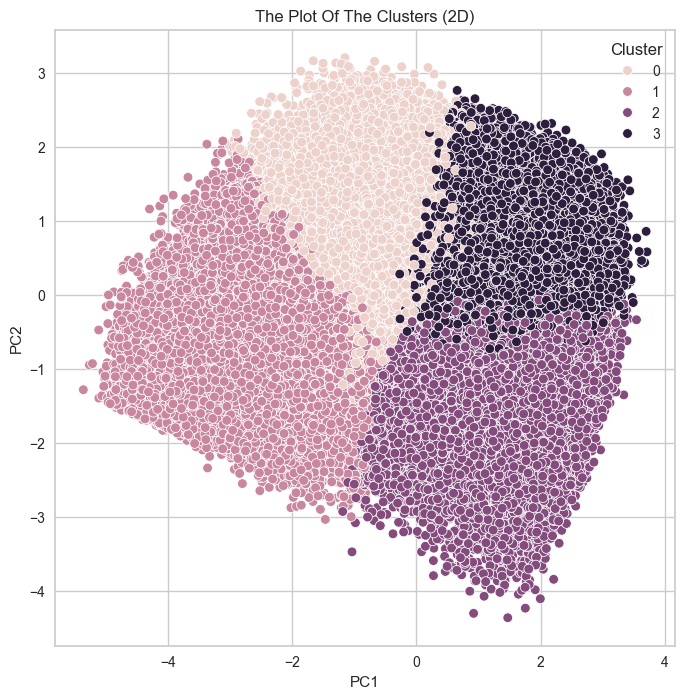
kmeans_df.value_counts('Cluster')
출력값 : Cluster
3 42945
0 42769
2 34733
1 31378
Name: count, dtype: int64
# 실루엣 계수 계산
silhouette_avg = silhouette_score(filtered_scaled_df, clusters)
silhouette_values = silhouette_samples(filtered_scaled_df, clusters)
print("Silhouette Score:", silhouette_avg)
출력값 : Silhouette Score: 0.28995315283280976
# 실루엣 플롯 생성
fig, ax = plt.subplots(figsize=(10, 6))
y_lower, y_upper = 0, 0
for i in range(optimal_k):
ith_cluster_silhouette_values = silhouette_values[clusters == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = plt.cm.nipy_spectral(float(i) / optimal_k)
ax.fill_betweenx(np.arange(y_lower, y_upper),
0, ith_cluster_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
ax.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
y_lower = y_upper
ax.set_title("The silhouette plot for the various clusters.")
ax.set_xlabel("The silhouette coefficient values")
ax.set_ylabel("Cluster label")
ax.axvline(x=silhouette_avg, color="red", linestyle="--")
ax.set_yticks([]) # Clear the yaxis labels / ticks
ax.set_xticks(np.arange(-0.1, 1.1, 0.2))
plt.show()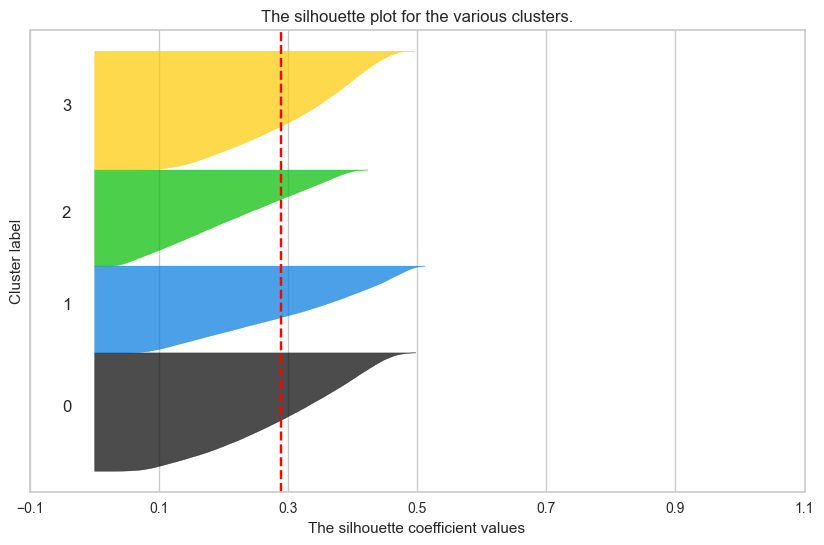
데이터 돌려놓고 기다리다가 결과보고
좀 감동했던 시각화.... 🥹
클러스터도 나름 구역마다 격차도 크지 않고
군집도 상당히 잘돼있고
실루엣계수도 처음보단 컸고
시각화가 좀 잘돼서 제 자신에게 좀 .. 감동함 ㅋㅋ
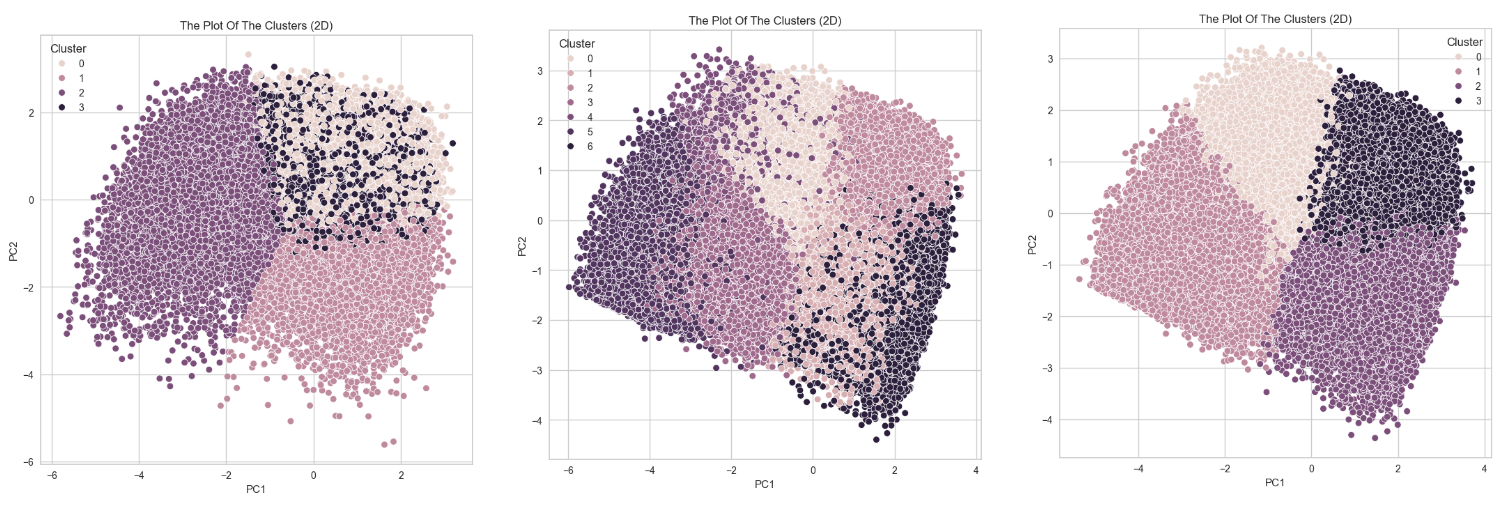
크으 조은 건 한 번 더
오늘 하루를 통으로 코드 돌려보느라 정신이 없었네요 ㅎㅎ,, 😅
팀원들과 열심히 코드를 돌려본 결과 !
군집이나 최종 모델이 제일 훌륭했던 전처리는
Isolation Forest 방법으로 채택되어서
다시 주말부터
코드 돌려서 군집 당 EDA를 시작할 계획입니다
다들 금요일까지 고생 많으셨으니까
좀만 숨 돌리고
더 해보자구요 ~!!!
오늘도 고생 많으셨습니다 😇🍀🍀🍀
