2024-06-25

안녕하세요 ~!
오늘은 프로젝트 발표회가 있었습니다
방금까지 다 마치고 이제 하루 마무리하려
TIL 쓰고 있습니다 ㅎㅎ
어제는 첨부하지 못했던
군집 별 음원 랜덤 플레이 리스트 생성하는 코드 소개해드릴게요
♾️ 스포티파이 추천 음악 리스트 생성
# 데이터 불러오기
sp_df = pd.read_csv('6월_심화프로젝트/data/data.csv')
# 음악 특징과 관련이 있는 컬럼 선택
cols = ['valence', 'acousticness', 'danceability', 'duration_ms', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo']
sp_df_2 = sp_df[cols]
# 이상치 제거 (Isolation Forest)
clf = IsolationForest(random_state=42).fit(sp_df_2)
pred = clf.predict(sp_df_2)
sp_df_2['anomaly'] = pred
df_if = sp_df_2[sp_df_2['anomaly'] == 1].copy()
df_if.drop(labels='anomaly', axis=1, inplace=True)
>>> 이상치가 아닌 데이터만 df_if에 할당
해당 열 선택 / 열 제거 / df_if에서 직접 제거위처럼 이상치를 제거한 데이터는 (df_if)의 원본 인덱스를 저장해두고,
나중에 결과를 원본 데이터에 반영할 때 사용합니다 !
# 원본 인덱스 저장 (표준화 전에 저장)
original_indices = df_if.index
# 데이터 스케일링 (스탠다드)
sd = StandardScaler()
df_if[cols] = sd.fit_transform(df_if[cols])
>> 컬럼 값들이 동일한 스케일(평균 0, 표준편차 1로 생성되도록)
# PCA 분석 (주성분 4개)
pca = PCA(n_components=4)
pca_df = pca.fit_transform(df_if[cols])
pca_df = pd.DataFrame(data=pca_df, columns=['PC1', 'PC2', 'PC3', 'PC4'])
pca_df.index = original_indices
>>> PCA 데이터 프레임의 인덱스를 위에 따로 저장해둔 원본 데이터 인덱스로 설정
# K-means 군집 분석
optimal_k = 4
kmeans = KMeans(n_clusters=optimal_k, random_state=42, init='random')
kmeans.fit(pca_df)
labels = kmeans.labels_
>>> 데이터가 속한 군집의 레이블을 labels에 저장
# 원본 데이터에 군집 레이블 추가
sp_df['Cluster'] = np.nan
sp_df.loc[original_indices, 'Cluster'] = labels
>>> 맨 처음 sp_df 데이터에 군집 레이블을 추가
이상치를 제거한 데이터의 인덱스에 해당하는 행에 군집 레이블을 할당
# 군집 -1이 있는지 확인 및 제거
sp_df_clean = sp_df[sp_df['Cluster'] != -1].copy()
>>> -1 = 이상치 / 이상치를 제거한 깨끗한 데이터 프레임 생성
# 원본 데이터에서 랜덤으로 10곡의 음악 리스트를 추출
random_sample = sp_df_clean.sample(n=10, random_state=None)
>>> 위에 이상치 없는 깨끗한 데이터 프레임을 이용해 랜덤으로 음원 추출
n(개수) = 10개, random_state=None으로 고정값 없이 추출
# 추출된 음악 리스트의 군집 비율 계산
cluster_counts = random_sample['Cluster'].value_counts(normalize=True)
>> 무작위로 선택된 10곡의 군집 비율을 계산
# 각 군집의 비율에 따라 추천할 곡의 수 계산
recommendation_counts = (cluster_counts * 10).round().astype(int)
>>> 10곡을 기준으로 비율에 맞게 추천할 곡의 수 선정
# 추천 음악 리스트 생성
recommendation_list = []
for cluster, count in recommendation_counts.items():
if count > 0:
cluster_songs = sp_df_clean[sp_df_clean['Cluster'] == cluster].sample(n=count, random_state=None)
recommendation_list.append(cluster_songs)
# 추천 음악 리스트 결합
recommendation_df = pd.concat(recommendation_list)
# 군집 별로 정리하기
random_sample = random_sample.sort_values(by='Cluster')
recommendation_df = recommendation_df.sort_values(by='Cluster')
list_cols = ['release_date', 'artists', 'name', 'Cluster']
print("랜덤 10곡 음악 리스트 :")
display(random_sample[list_cols])
print("추천 음악 리스트 :")
display(recommendation_df[list_cols])위와 같은 코드를 뽑아보면
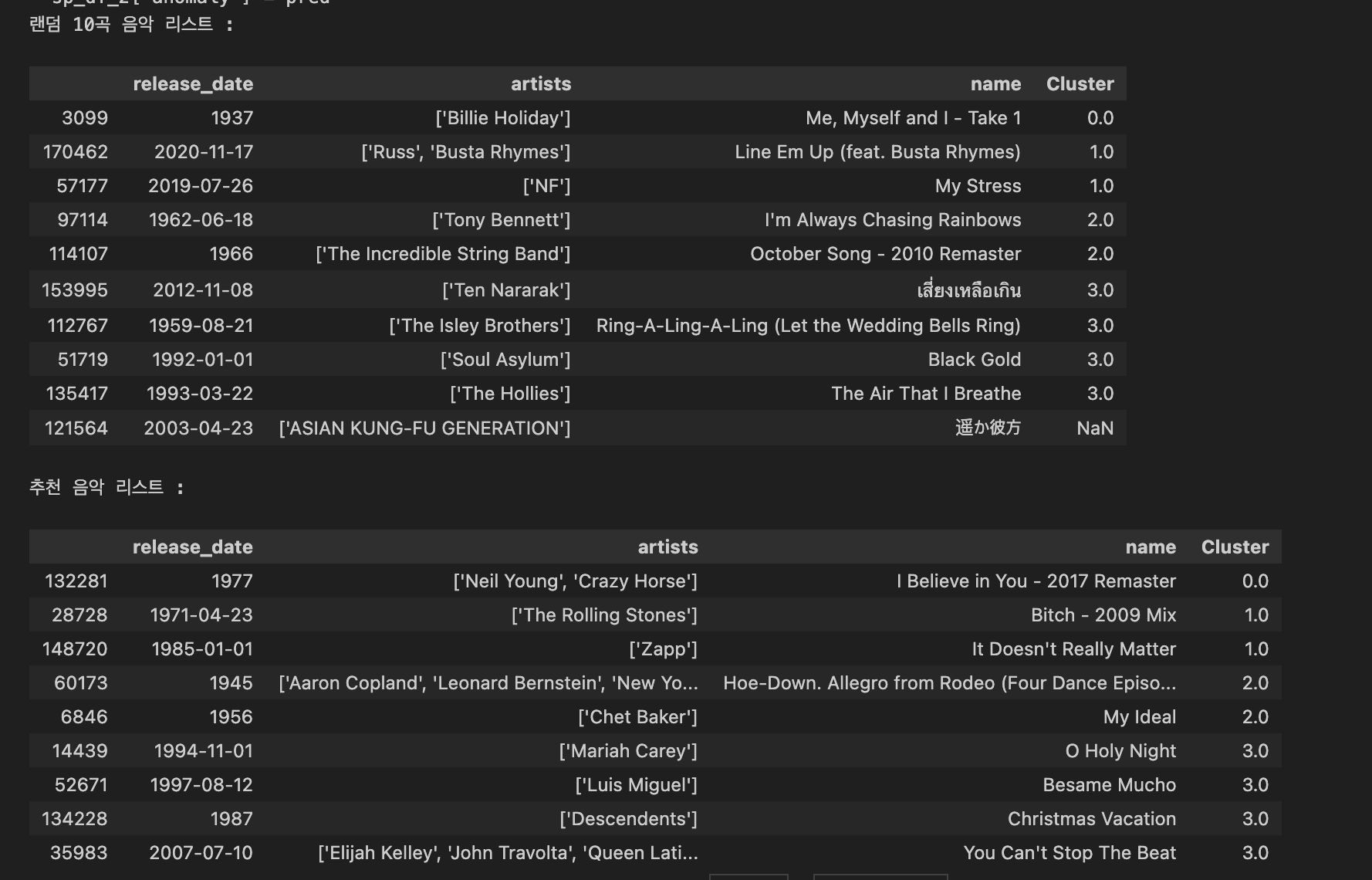
랜덤으로 10곡이 추출되며
그 옆에 클러스터 번호가 할당된 것을 알 수 있습니다 !!!
랜덤으로 추출된 클러스터의 비율만큼
또 다른 추천 음악 리스트가 생성된 것을 알 수 있구요 ㅎㅎ
발표회는 성공적으로 마쳤습니다 !!!!
저희 조는 비지도 학습이라는 면에서 정답이 없는 프로젝트의 결과물을 산출하는데
흥미로워 군집분석을 선택했는데요
정답이 없는만큼 제일 좋은 결과를 도출하기까지 정말 힘들었습니다.., 😇
같은 주제를 선정한 다른 팀들의 발표를 보니 더 실감이 났습니다
각 팀마다 선정한 클러스터 갯수나 PCA 갯수도 달라서
모든 팀들의 군집 결과가 달랐던 게 흥미로웠네요 ㅎㅎ!!
인사이트도 모두 다르게 도출한 것도 신기했구요 ..,
그리고 마지막으로 튜터님께서 저희팀 고생했다고 팀 이름 말씀해주셨을 때
하.... 레알 쌈@뽕해서 깔롱 직였습니다
아무튼 프로젝트 마무리 잘해서 좋았다는 뜻이구요
저보다 팀원들이 정말 더 고생 많으셨을 겁니다....,
저같은 똥멍청이랑 같이 팀하느라 답답하셨을 텐데 안 패고 데리고 다녀주셔서
감사해요 ㅎㅎ,,, 🥹
다들 오늘도
고생 많으셨구요 푹 주무시고
낼 봬요 🍀🍀🍀🍀
