2024-07-17

안녕하세요 !
평일의 중간까지 왔네요 ㅎㅎ
하루의 마무리 TIL쓰고 끝내겠습니당
♾️ 데이터 수집 방법 2
어제는 오픈 API를 통한 데이터 수집 방법을 알아보았는데요
오늘은 크롤링과 스크래핑을 통한 데이터 수집 방법을 알아보겠습니다 !
✓ 크롤링
: 웹상에 존재하는 모든 웹 페이지를 방문하여 데이터를 수집하는 방법
모든 페이지를 방문하며, 각 페이지의 링크를 따라가면서 자동으로 데이터를 수집
✓ 스크래핑
: 특정 웹 사이트나 페이지에서 필요한 데이터를 자동으로 추출하는 방법
원하는 정보를 추출하기 위해 HTTP GET 요청 전송
ex)
크롤링 : 레시피 사이트의 전체를 탐색하여 모든 레시피를 수집
스크래핑 : 레시피 사이트의 "백숙" 레시피 페이지에서 제목, 재료 목록, 조리 방법만 추출
|
⛔️ 크롤링/스크래핑 주의사항
해당 사이트 URL 뒤 robots.txt 를 붙여
합법인지 확인 : (=로봇 배제 표준(Robots Exclusion Standard)을 준수했는가)
ex) https://nbcamp.spartacodingclub.kr/robots.txt
User-agent: *
Allow: / >> 허용
Disallow : >> 허용하지 않음✓ 웹의 구성요소
|
✓ HTML (Hyper Text Markup Language) : 웹 사이트의 뼈대
✓ CSS (Cascading Style Sheets) : 예쁘게 꾸며줌 ex) 글꼴 색상 등
✓ javascript : 동작 ex) 스크롤 바 등
✓ HTLM의 구조, XPATH
HTML(HyperText Mark-up Language)
프로그래밍 언어가 아닌, 문서를 설명해주는 정보를 현하는 마크업 언어
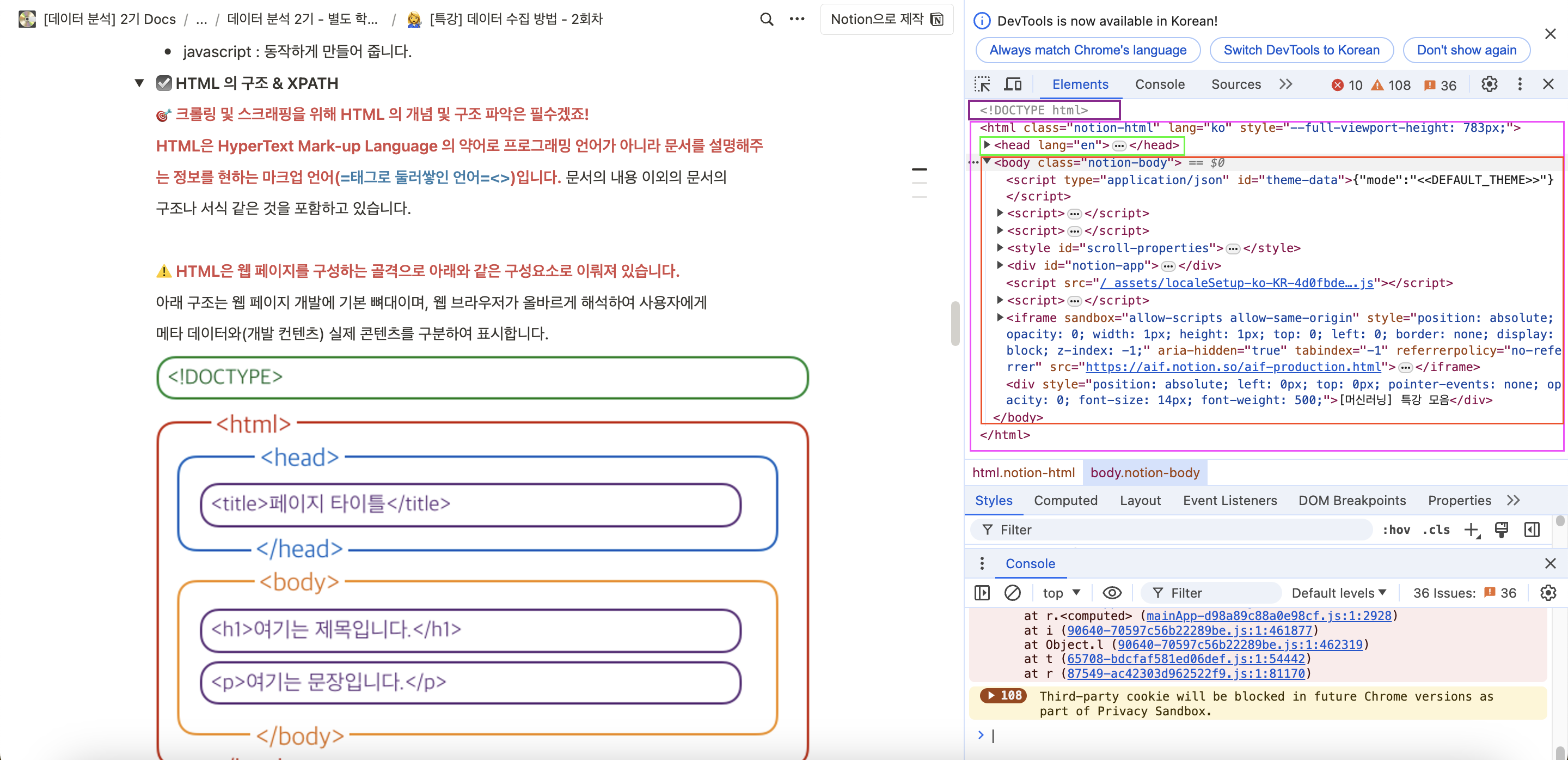
보이는 사진처럼
head부분이 접혀지긴 했지만.. 무튼 !
웹사이트에서 F12 버튼을 눌러주면 HTML의 구조를 볼 수 있습니다 !
(자판 잘못칠 때마다 나오던 게 이거였다니....)
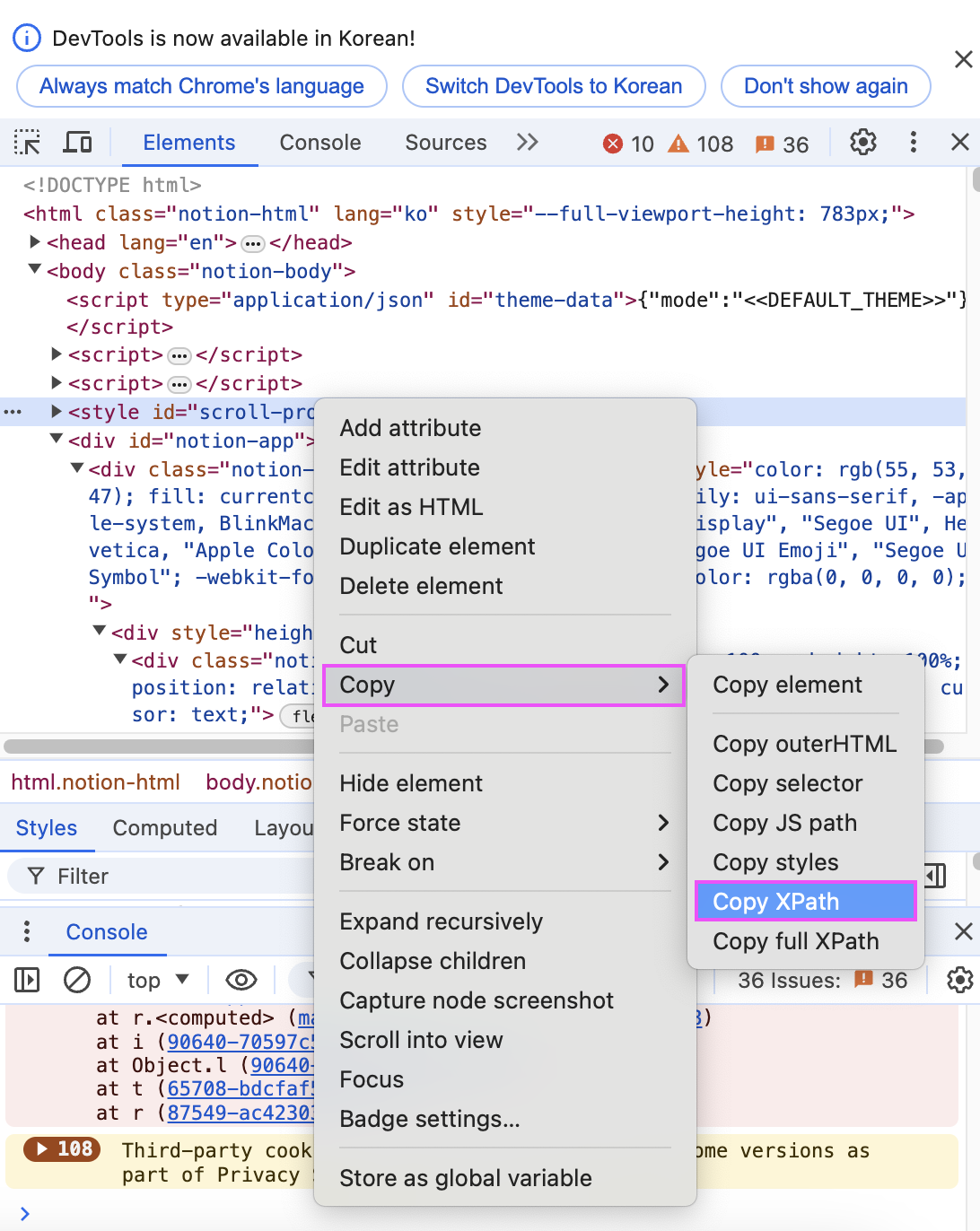
HTML 구조 내의 XPATH를 복사해주고
파이썬에서 BeautifulSoup 및 Selenium 라이브러리를 사용해주면
데이터 추출을 해볼 수 있습니다 !
내일 더 자세하게 복습해서
실습 환경 만들어오겠습니다...
♾️ 빅데이터
✓ 빅데이터란
- 빅데이터는 데이터의 양(Volume), 데이터 유형과 소스 측면의 다양성(Variety), 데이터 수집과 처리 측면에서 속도(Velocity)가 급격히 증가하면서 나타난 현상
+가치(Value) 또는 정확성(Veracity)
(가트너그룹의 더그래니 3V)
|
✓ 빅데이터의 기능
1️⃣ 산업혁명의 석탄, 철
: 서비스 분야의 생산성까지 끌어올려 사회, 경제 등 생활전반에 혁명적 변화를 가져올 것
2️⃣ 21세기의 원유
경제 성장에 정보 제공을 통해 산업 전반의 생산성 향상, 새로운 산업 전망 기대
3️⃣ 렌즈
: 빅데이터도 산업 발전 큰 기여 기대
ex) 구글의 Ngram Viewer, 현미경
4️⃣ 플랫폼
: 공동 활용의 목적으로 구축된 유무형의 구조물, 다양한 서드파티 비즈니스에 활용
ex) 페이스북, 카카오톡 등
|
✓ 빅데이터의 변화
✓ 사전처리 → 사후처리
기존에는 필요한 정보만 수집하고 필요하지 않은 정보는 버리는 시스템에서
→ 가능한 많은 데이터를 모아 인사이트를 발굴
✓ 표본조사 → 전수조사
데이터 수집 비용 감소와 클라우드 발전으로 데이터 처리 비용 감소
✓ 질 → 양
데이터의 양이 증가할 경우 양질의 정보 > 오류 정보
전체적으로 좋은 결과 산출에 긍정적인 영향을 미침
✓ 인과관계 → 상관관계
실시간 상관관계 분석을 통해 도출된 인사이트를 바탕으로 액션
오늘도 .. 어찌저찌 보냈네요
내일 또또 ! 화이팅입니다
고생 많으셨습니다 🍀🍀🍀
