Reference
- 내용전반: edwith
지금까지는 DB 스키마가 주어져 있다고 가정하고 쿼리를 수행하는 방법에 대해 다루었는데, 이제 스키마를 설계하는 방법에 대해 다룹니다
🌀 E-R 모델 기본
🔸 Entity / Attribute / Entity Set
DB는 개체(entity)들의 집합과 개체들 간의 관계로 모델링할 수 있습니다
🔘 Entity
Entity란, 다른 객체와 구별되어 존재하는 하나의 객체를 뜻합니다. 예로, 사람이나 책처럼 구체적인 것이 될 수도 있고 수업이나 비행기예약처럼 추상적인 것도 entity가 될 수 있습니다. (그간 다루던 튜플이 entity라 표현되는 듯 합니다)
🔘 Attribute
이러한 entity는 Attribute를 가지고 있습니다. Attribute는 값을 가지고 있고 각 entity는 attribute에 대한 자신만의 값을 가집니다. attribute는 어떤 entity 집합의 구성원들이 공통적으로 가지는 특징을 표현해줍니다. 해당 집합의 attribute들의 일부로 각 entity를 고유하게 식별할 수 있게 됩니다
🔘 Entity Set
Entity Set은 같은 attribute를 가지고 있는 entity들의 집합입니다 (그간 다루던 relation이 entity set이라 표현되는 듯 합니다). entity set은 서로 중복될 수도 있는데 예로 person은 student이거나 instructor가 될 수 있습니다
🔸 Relationship / Relationship Set

🔘 Relationship
Relationship이란, entity 간 의미있는 연관성을 의미합니다. 즉, entity들이 서로 어떻게 연관되어 있는지를 말합니다. 위 예시는 Einstein이라는 instuctor와 Peltier라는 student가 있는데 두 entity의 관계가 advisor라는 의미입니다
위와 같이 삼지창(?)으로 표시하며 예제에서는 (44553, 22222)라는 순서쌍이 advisor의 원소입니다. 즉, 둘 사이에는 advisor 관계가 있다는 것을 의미합니다
🔘 Relationship Set
Relationship은 각 entity 간의 관계를 뜻하고, Relationship Set은 이런 Relationship의 집합을 뜻합니다
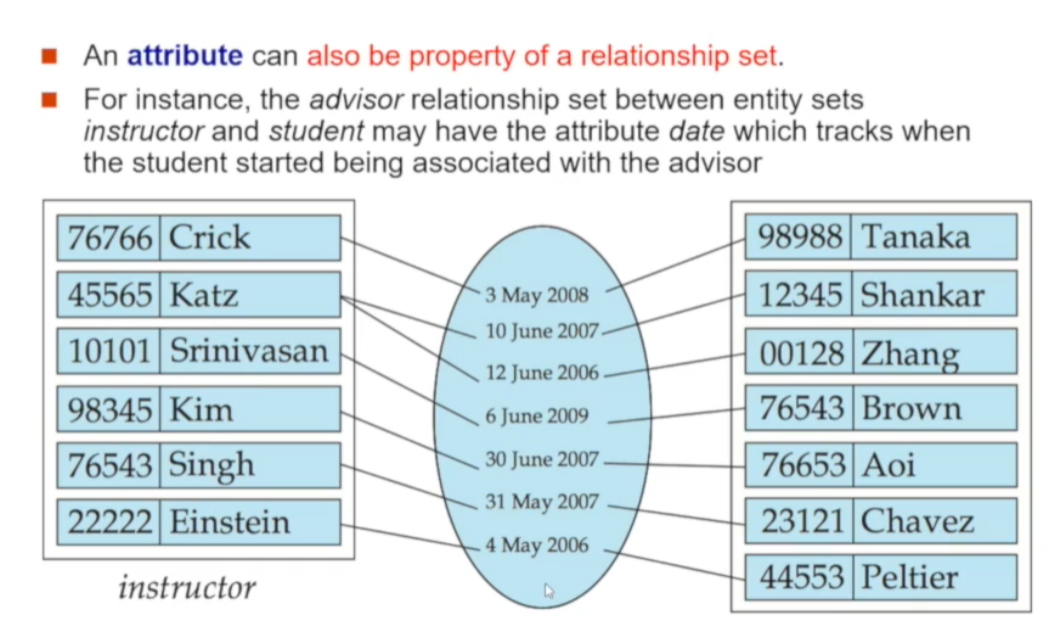
🔘 Relationship Set의 Attribute
Relationship set 역시 Attribute를 가질 수 있습니다. instructor(좌)와 student(우) entity들 간에는 advisor(중간)라는 Relationship set을 가지는데 advisor는 Date라는 Attribute를 가집니다

🔘 Relationship Set의 Key
Relationship set에도 각 Relation을 구분하기 위한 Key 개념이 존재합니다. Relationship set의 key는 참여하는 entity set의 key들을 사용하여 만들게 됩니다. 위는 student의 s_id와 instructor의 i_id의 조합이 advisor라는 Relationship set의 superkey로 선정한 예시입니다

🔘 Relationship Set의 Degree 개념
Relationship set에는 Degree(차수) 개념이 있습니다. 해당 relationship set에 참여하는 entity set의 개수를 말합니다. 직전까지 살펴봤던 instructor와 student 간의 advisor 관계는 두 개의 entity set만 참여하므로 binary relationship이라고 합니다. 대부분의 관계는 binary로 되어 있습니다
🔸 Attribute
🔘 Attribute
entity 는 Attribute의 집합으로 표현할 수 있습니다. attribute는 해당 entity set의 모든 멤버가 가지고 있는 특성을 말합니다
🔘 Domain
Domain이란, 각 attribute에 허용되는 값들의 집합을 뜻합니다
🔘 Attribute type
Attribute type에는 아래와 같은 종류가 있습니다
- Simple vs Composite
Simple attribute는 더 이상 작은 단위로 나눠지지 않는 값을 가지는 경우를 말하고, 반대로 Composite attribute는 더 작은 단위/속성으로 나눠질 수 있습니다 - Single-valued vs Multi-valued
Single-valued attribute는 특정 entity에 대해 하나의 값만 가지고, Multi-valued는 한 번에 여러 개의 값을 가질 수 있는 경우입니다 (ex. 연락처 attribute에는 집전화/휴대폰 등 여러 개가 올 수 있음) - Derived
직접 저장되지 않고 필요할 때마다 다른 attribute을 이용하여 계산되는 경우입니다 (Swift의 computed 프로퍼티 느낌)
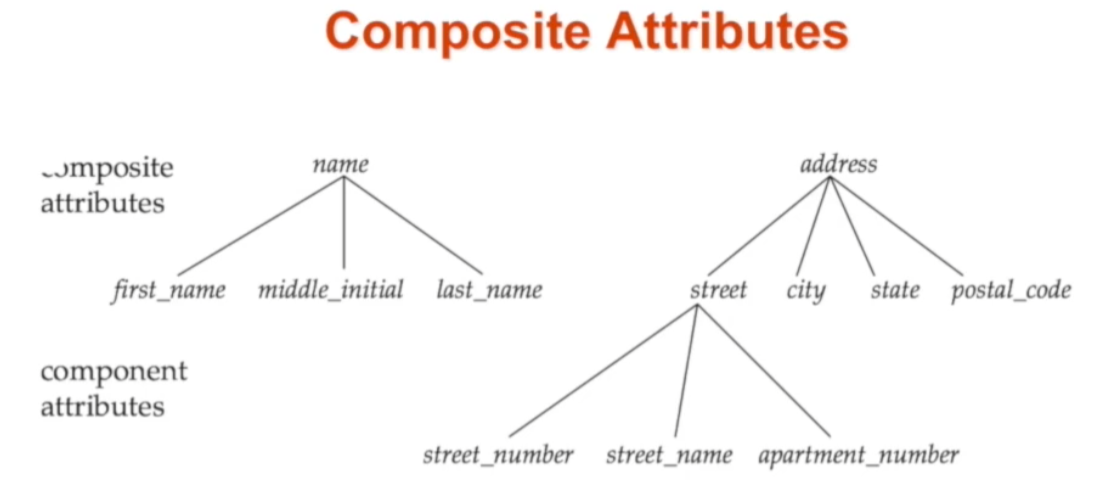
🔘 Composite Attribute 예시
Composite Attribute를 좀 더 살펴보면, 이는 경우에 따라 해당 속성 값의 전체 혹은 일부만을 참조하고 싶을 때 유용합니다. 예로, name이라는 attribute는 풀네임으로 필요할 때도 있지만 first name만이 필요한 경우도 있습니다. 또한, address의 예처럼 계층 구조를 가질 수 있어 모델링을 더 명확하게 할 수 있고 연관된 attribute들을 하나의 그룹으로 묶을 수 있다는 장점이 있습니다
🔸 Mapping Cardinality 제약
E-R 모델에는 Mapping Cardinality 제약과 Participation Constraints 두 가지 제약 개념이 있는데 먼저 Mapping Cardinality 제약에 대해 알아봅니다
🔘 Mapping Cardinality란?
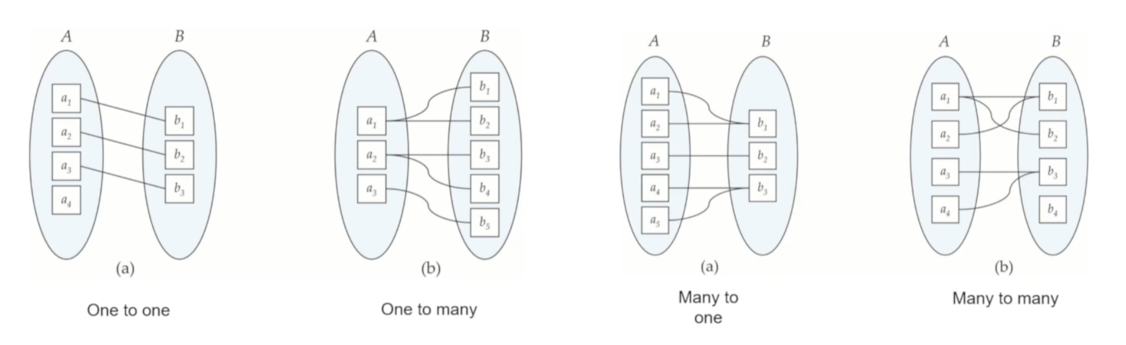
Mapping Cardinality는 개별 entity들이 맵핑되는 개수를 말하며 아래와 같이 4가지 유형으로 나뉩니다
(참고로 맵핑이 안되는 entity가 존재할 수도 있습니다)
🔘 유형별 Relationship Set Key 결정
이전에 다룬 것처럼 Relationship set에도 key 개념이 존재합니다. Relationship set의 key는 참여하는 entity set의 key들을 사용하여 만들게 되는데 이 때 Mapping Cardinality에 따라 key 결정 방법이 다릅니다
Mapping Cardinality는 위 그림처럼 두 개의 entity set만 참여하는 binary relationship을 기술하는데 가장 유용하게 사용됩니다. binary relationship에는 4가지 유형이 있으며 우선 각 유형별 candidate key를 결정하는 방법을 알아봅니다
(One과 Many는 해당 Relationship에서 한 번만 등장하느냐 여러 번 중복으로 등장할 수 있느냐를 뜻합니다)
-
Many to Many
Many to Many Relationship일 경우 advisor의 primary key는각 entity set의 primary key의 합집합이 될 수 있습니다. (ex. 위에서처럼 student의 기본키 s_id와 instructor의 기본키 i_id의 조합이 advisor의 기본키가 될 수 있다) -
Many to One / One to Many
Many 쪽에 있는 기본키를 Relationship의 기본키로 결정하게 됩니다. many 쪽의 entity 간 구분이 되어야 하기 때문입니다 -
One to One
두 entity set중어느 쪽의 기본키를 Relationship의 기본키로 사용하더라도 모든 relationship을 구분할 수 있습니다
그리고 하나 이상의 candidate key가 존재하는 경우 primary key를 선택할 때는 entity set의 의미를 고려해야 합니다. 기존 예시의 student와 instructor의 경우 교수가 학생을 지도하는 관계라는 의미를 고려하여 적절한 것을 고르게 됩니다
🔸 Participation 제약
E-R 모델의 또 다른 제약개념인 Participation Constraint은 참여에 관한 제약조건으로 전체참여와 부분참여가 있습니다
🔘 Total participation(전체참여)
모든 entity가 적어도 하나의 Relationship에 참여하는 것을 말합니다
🔘 Partial participation(부분참여)
일부 entity는 참여하지 않을 수 있다는 것을 말합니다
🔸 Redundant Attribute
Redundant Attribute란, Relationship을 통해 알 수 있는 중복 정보는 삭제하는 것을 말합니다
예로, instructor와 department라는 entity set은 공통적으로 dept_name이라는 attribute를 가지고 있는 상황을 가정합니다. 여기서 만약 inst_dept라는 relationship으로 둘을 연결한다면 어느 한 쪽은 dept_name이 없어도 됩니다. 왜냐하면 자신이 가지고 있지 않더라도 inst_dept를 타고 다른 쪽 entity set을 통해 해당 정보를 얻을 수 있기 때문입니다
하지만 E-R 모델을 막상 관계형 모델로 맵핑할 때는, 이렇게 삭제시킨 attribute를 다시 도입할 때도 있습니다
🔸 Weak Entity Set
🔘 Weak Entity Set
Weak Entity Set은 충분한 Attribute가 없어 primary key를 갖고 있지 않은 경우를 말합니다. 반대로 primary key를 가진 Entity set은 Strong Entity Set이라 합니다
🔘 Identifying Entity Set
이런 weak Entity Set는 다른 entity set에 의존하게 되는데, 이 때 의존당하는 entity set을 Identifying Entity Set이라 합니다
🔘 Identifying Relationship
weak Entity Set과 identifying Entity Set 간 관계를 Identifying Relationship이라 합니다
🔘 Identifying Relationship 규칙
여기서 identifying Entity Set -> weak Entity Set는 One to Many이고, weak Entity Set의 모든 entity는 Identifying Relationship에 참여해야 합니다(전체참여)
🔘 Discriminator
discriminator 혹은 partial key라고 불리는 구별자는 weak Entity Set의 모든 entity를 구별하는 Attribute 집합입니다. 이것만으로는 Weak의 entity를 구분할 수 없고 (그러니 weak지), identifying Entity Set의 primary key와 discriminator를 합쳐서 Weak Entity Set의 primary key가 만들어집니다
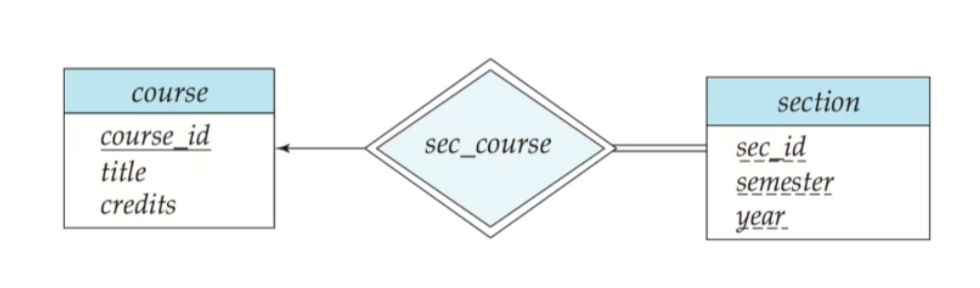
🔘 Identifying Relationship 다이어그램 표현
E-R 다이어그램에서 Identifying Relationship은 두 겹의 다이아몬드로 표현합니다. discriminator는 점선 밑줄로 표현합니다. One to Many 관계이며 전체참여도 표현되어 있습니다. 위 예시에서 Weak Entity Set의 primary key는 (course_id, sec_id, semester, year)입니다
🌀 E-R 다이어그램
대표적인 예시들에 대해 Entity와 Relationship을 다이어그램으로 표현하는 방법을 다룹니다
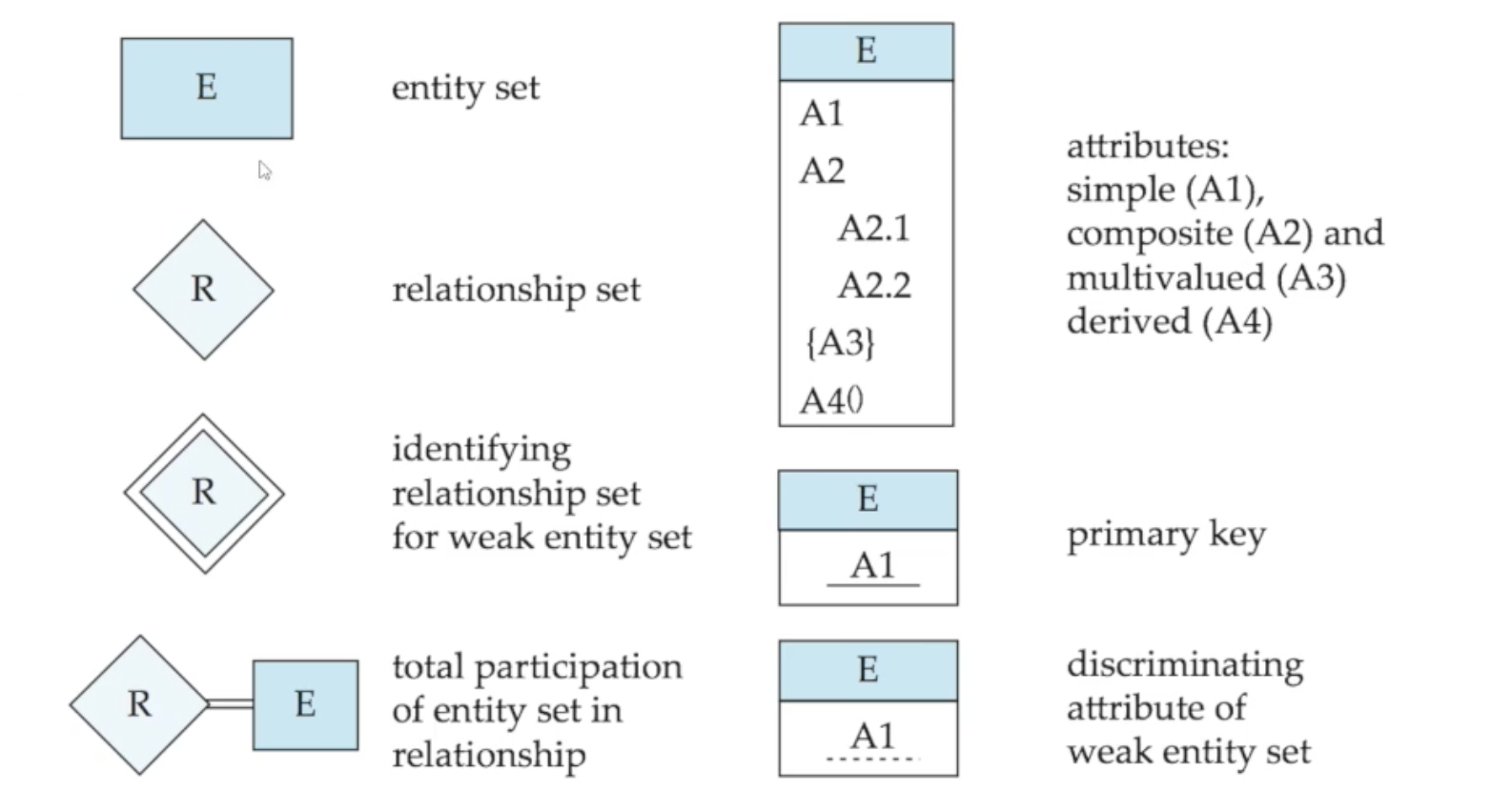
🔸 기본표현
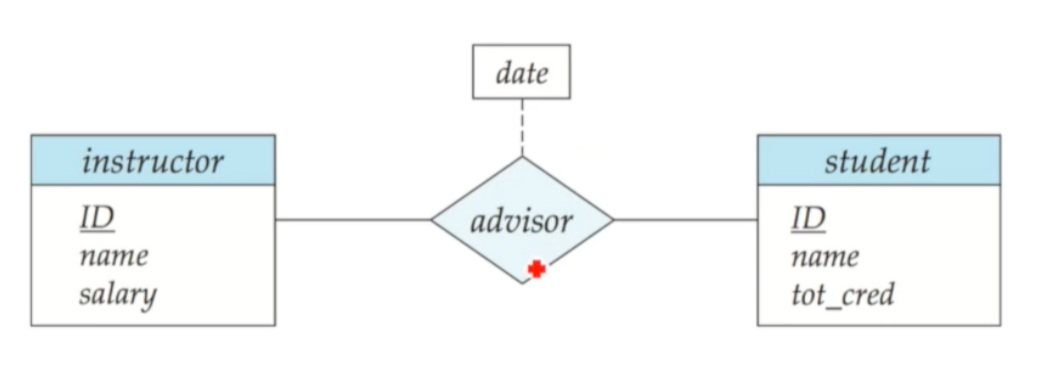
instructor/student는 entity set이고, 박스 내부는 attribute들입니다. 이 중 밑줄 친 것은 primary key를 나타냅니다. 중간의 마름모는 relationship을 나타내며 점선 date는 relationship의 attribute를 나타냅니다

🔘 Composite, Multi-valued, Derived Attribute
Composite, multi-valued attribute 표현 예시. Composite는 들여쓰기를 사용하고, Multi-valued는 중괄호를 사용합니다. 사진엔 안 나오지만 derived attribute는 이름 뒤에 소괄호가 붙습니다
🔸 Entity Role 표현
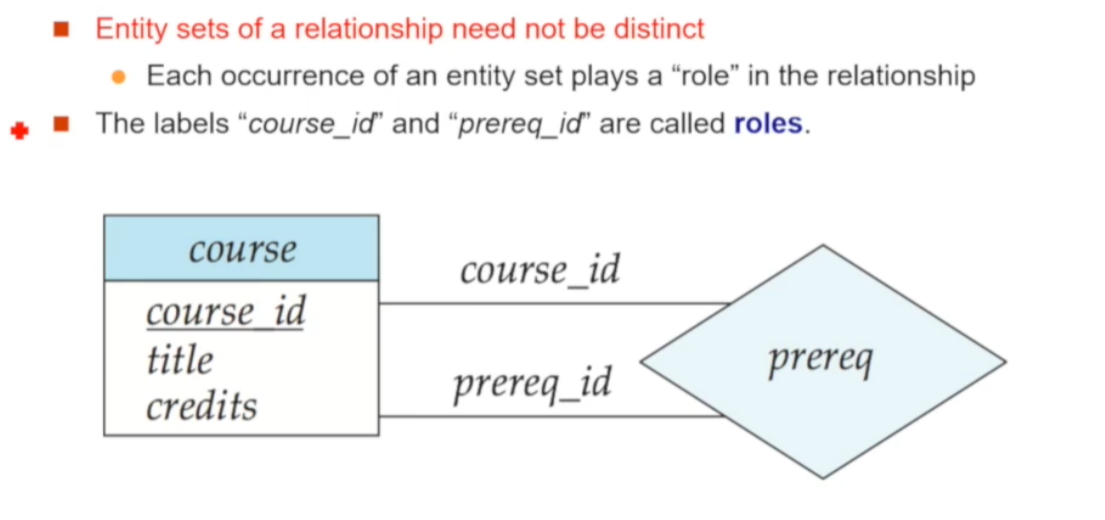
🔘 Entity role
Entity role이란, entity가 relationship 내에서 어떠한 역할을 수행하는지를 말합니다. 사실 일반적으론 적어주지 않아도 entity set의 이름 자체가 역할로 사용되므로 (ex. instructor는 relationship에서 이름 그대로 교수 역할로 사용됨) 특별히 명시하지 않아도 됩니다
🔘 Role 명시가 필요한 경우
하지만 위 예시처럼, 선수과목 개념을 표현하기 위한 prereq relationship 내에서 course라는 동일한 entity set이 2번 이상 참여하면 역할 구분을 위해 레이블 등을 사용하여 명시해주는 것이 좋습니다. 예제에선 한 번은 course_id로, 다른 한 번은 prereq_id로 참여하게 됩니다
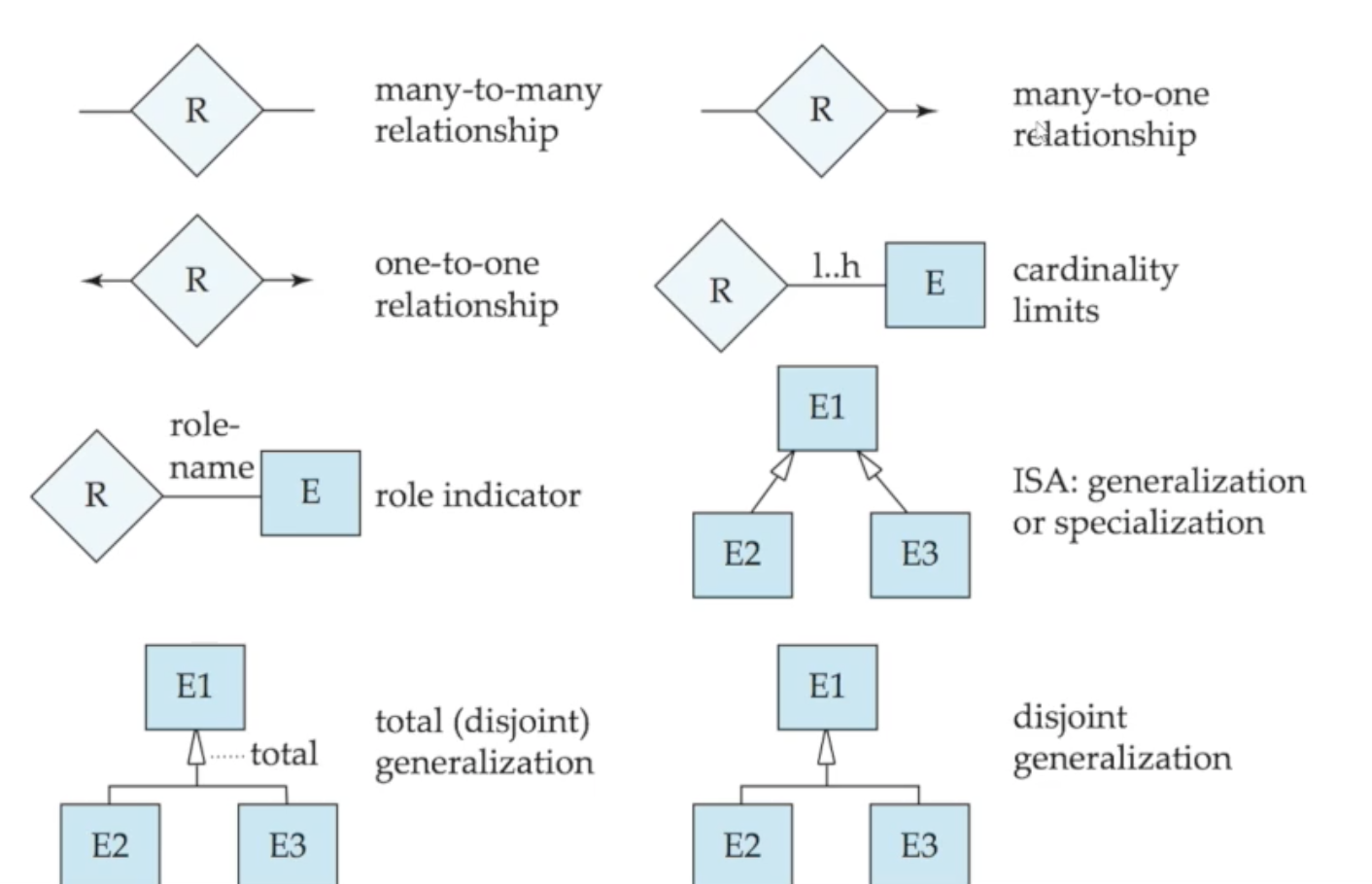
🔸 Cardinality Constraint 표현
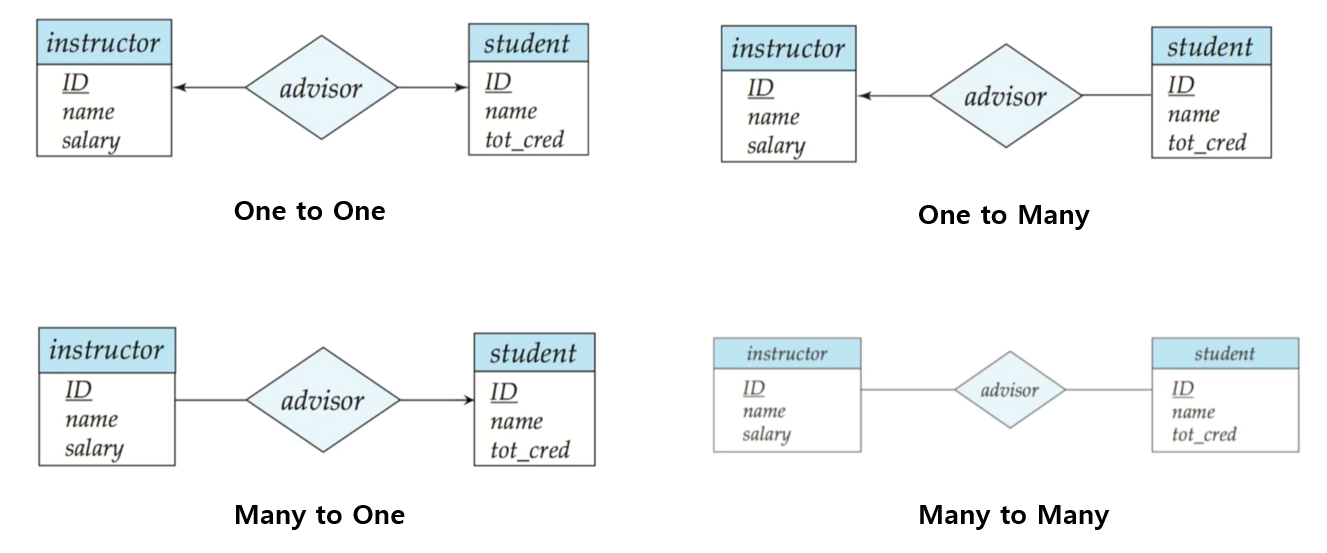
🔘 기본표현
E-R 다이어그램에서 Mapping Cardinality는 위와 같이 One은 화살선으로, Many는 실선으로 표현할 수 있습니다
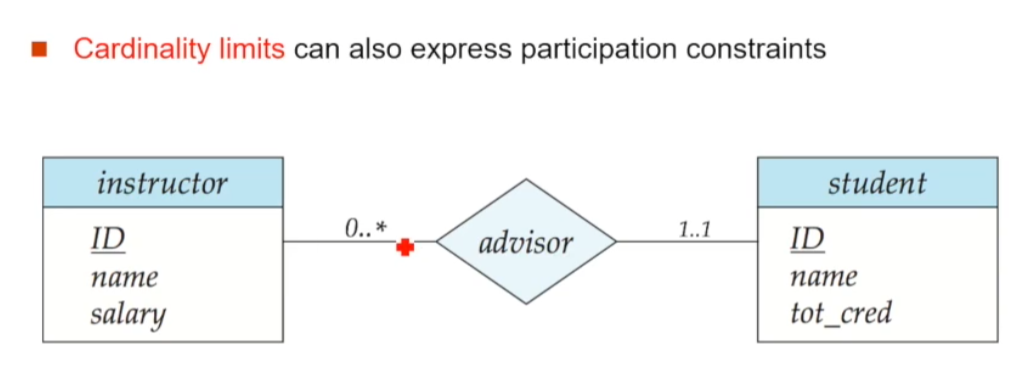
🔘 Cardinality Limit으로 표현
Cardinality Limit라는 개념을 통해 {min}..{max}의 포맷으로 직접적인 숫자로 표현할 수도 있습니다 (별 표시는 제한이 없다는 의미입니다). 이 방식은 min이 0이냐 아니냐에 따라 Participation Constraint도 동시에 표현할 수 있습니다
🔸 Participation Constraint 표현
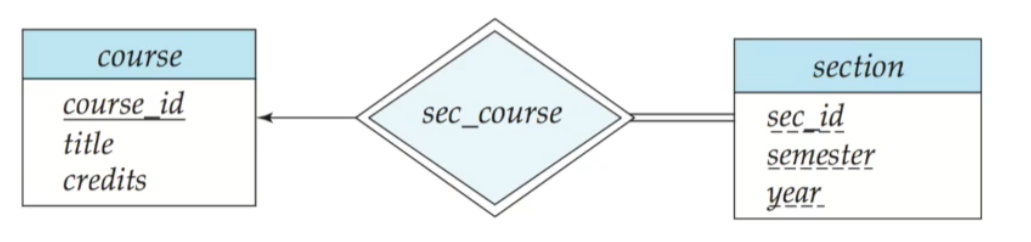
부분참여는 한 줄로, 전체참여는 두 줄로 표현합니다
🔸 Ternary Relationship 표현
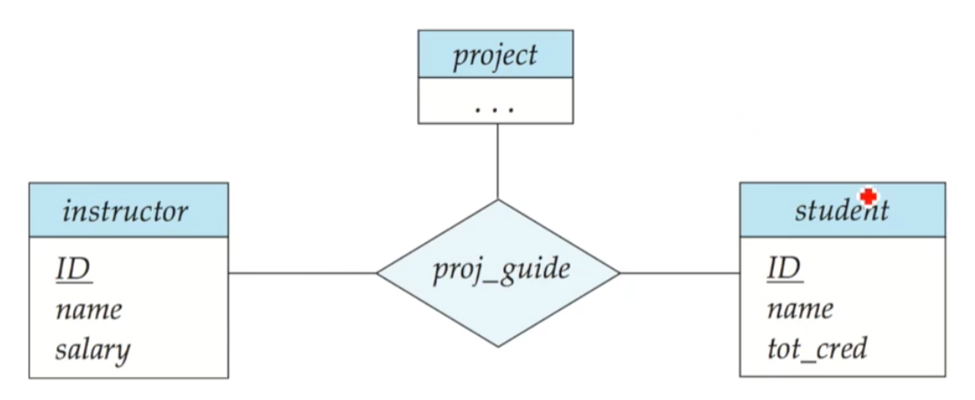
가끔씩 등장하는 non-binary relationship 표현입니다
🔘 일반적으로 Ternary Relationship에서 밖으로 나가는 화살표(One표현)은 최대 1개 만을 허용합니다
그 이유는 의미가 모호하여 책이나 DB 시스템마다 동일한 표현에 대해 전혀 다르게 해석되기도 하기 때문입니다. 위 다이어그램에서 만약 instructor와 student 모두에 화살표가 있다면 하나의 instructor당 하나의 student만 존재한다는 뜻인데 이 표현은 여러 의도로 사용될 수 있습니다
예로, 아래 2가지 정도의 특정 의도를 표현하기 위해 사용되기도 합니다. (Entity Set) A,B,C와 (Relationship) R가 있고, B와 C 모두로의 화살표가 있는 상황입니다
- A가 B+C라는 특별한 Entity set과 관계를 가짐을 표현하려는 경우
- A와 B로 이루어진 각 쌍은 C의 특정 Entity와 연결됨을 표현하려는 경우
🌀 E-R 모델 -> 관계형 모델 변환
E-R 모델과 관계형 모델은 비슷한 원리로 설계되어서 상호변환이 가능합니다. 이번 섹션에서는 E-R 모델을 이전에 다루었던 관계형 모델로 어떻게 변환하는지를 다룹니다
Entity Set과 Relationship Set은 관계형 모델의 Relation 스키마로 항상 나타낼 수 있습니다. E-R 다이어그램에 일치하는 DB는 Relation의 모음으로 표현될 수 있습니다. 각 Entity Set과 Relationship Set에 상응하는 유일한 Relation이 존재합니다
🔸 Simple Attribute
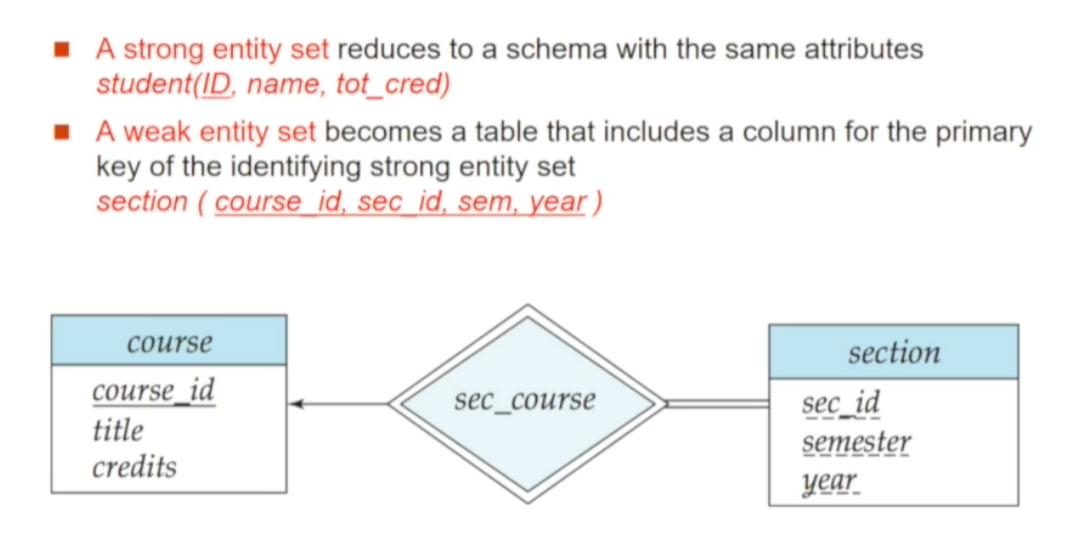
먼저, simple attribute로 이루어진 Entity set을 표현하는 방법을 알아봅니다. (simple attribute는 composite의 반대로 쪼갤 수 없는 하나의 값만 가지는 attribute를 말함).
🔘 Strong Entity Set
Strong Entity Set 스키마는 그대로 Relation 스키마로 변환됩니다. 그리고 각 Entity는 하나의 튜플이 됩니다. 또한, 기존의 Attribute를 모두 그대로 가지게 됩니다. primary key 역시 동일합니다
- Attribute : 그대로
- Primary key : 그대로
🔘 Weak Entity Set
Weak Entity Set은 identifying strong Entity Set의 primary key를 포함하는 Table로 표현할 수 있습니다. 위 예시에선 course_id라는 Attribute를 추가하여 Relation 스키마로 표현할 수 있습니다. Weak의 primary key는 자신의 discriminator와 Strong의 primary key (course_id)를 합한 것이 됩니다
- Attribute : 자신의 Attribute + Strong의 primary key
- Primary key : 자신의 discriminator + Strong의 primary key
- Foreing key constraint : Strong의 primary key
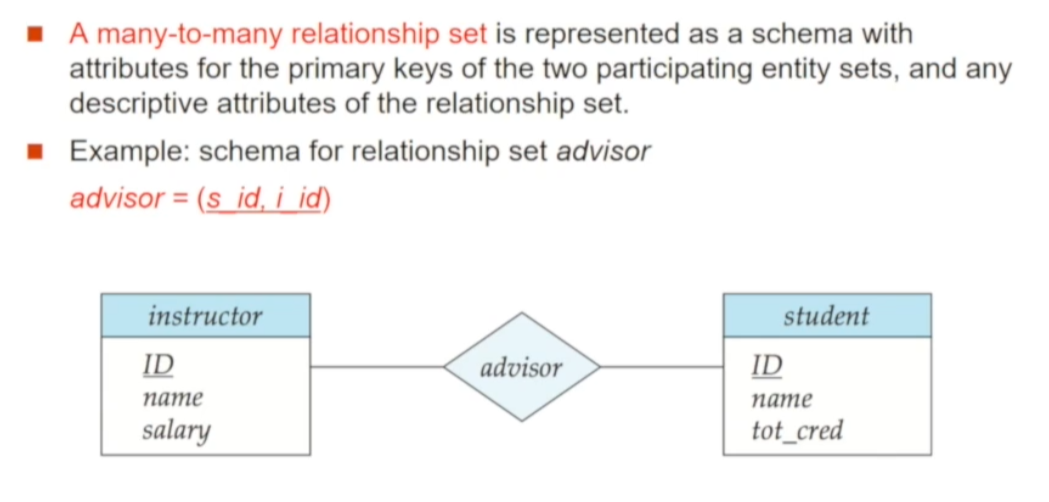
Relationship Set를 Relation으로 표현하는 방법은 Cardinality에 따라 차이가 다릅니다
🔘 Many to Many - Relationship Set
우선, Many to Many인 경우 "참여 Entity Set의 primary key" + "Relationship Set을 설명하는 Attribute(= Entity Set을 연결하는데 사용되는 Attribute)"를 attribute로 가지는 Relation 스키마로 표현할 수 있습니다. 위 예시에서는 advisor가 자체적인 attribute를 가지고 있지 않기 때문에 instructor/student의 primary key만으로 Relation 스키마가 이루어집니다. 또한, advisor의 primary key 역시 instructor/student의 primary key가 됩니다
- Attribute : 참여 Entity Set의 primary key 합 + Relationship Set Attribute
- Primary key : 참여 Entity Set의 primary key 합 + Relationship Set Attribute
- Foreing key constraint : 참여 Entity Set의 primary key 합
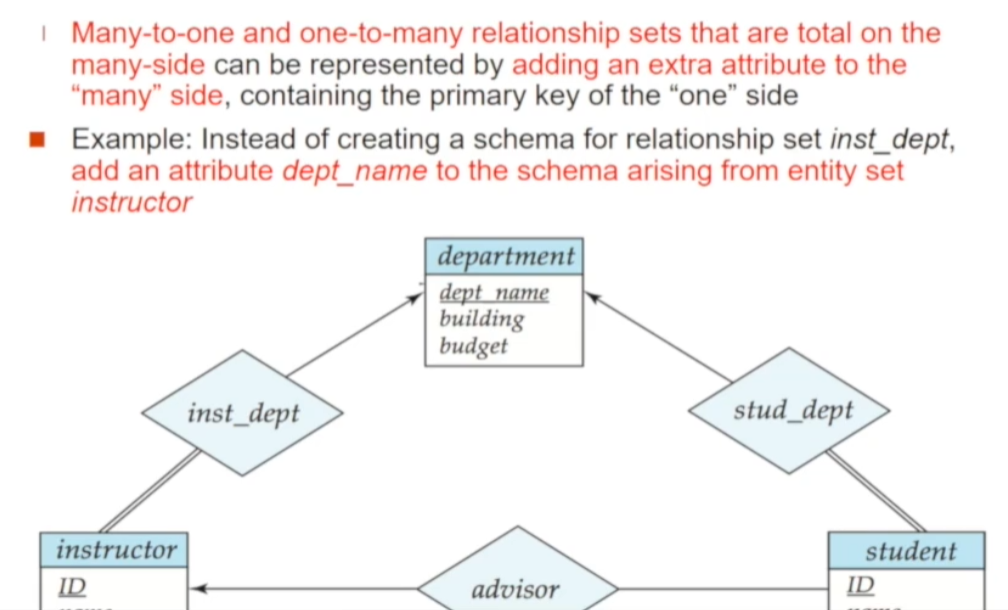
🔘 Many to One / One to Many - Relationship Set
Many 쪽이 전체참여(total participation) 조건을 만족시킬 경우 many쪽 table에 extra attribute를 추가하여 Relation 스키마로 나타낼 수 있습니다 (extra에는 One쪽의 primary key를 포함하여 기타등등이 들어갑니다). 위 예시에서 instructor와 department가 Many to One의 관계이며, instructor를 표현하는 테이블에 department 속성(dept_name)을 넣어주면 inst_dept가 하는 역할을 대신하는 Relation 스키마를 만들 수 있습니다
- Attribute : many쪽 table + One쪽 primary key
🔘 One to One - Relationship Set
Many to One / One to Many에선 Many쪽을 먼저 골랐다면, One to One은 양쪽 Entity Set 중 아무나 골라 뼈대 테이블로 두고 Extra Attribute를 추가하여 Relation을 만듭니다. 하지만 만약 Many로 고른 쪽이 전체참여가 아닌 부분참여일 경우 Extra Attribute로 추가해주는 One쪽의 primary key에 해당하는 값은 NULL이 발생할 수 있습니다. 왜냐하면, 부분참여라 함은 Many쪽에서 One과의 관계에 참여하지 않는 튜플이 존재한다는 것이고 One쪽과 연결이 없는 상태이므로 One쪽 Attribute인 primary key에 대응되는 값은 충분히 없을 수 있기 때문입니다
🔘 Identifying - Relationship Set
Identifying Relationship Set은 따로 만들 필요가 없습니다. 왜냐하면 weak Entity Set을 Relation으로 만들면 필요한 모든 내용이 포함되기 때문입니다
🔸 Composite/Multi-valued Attribute
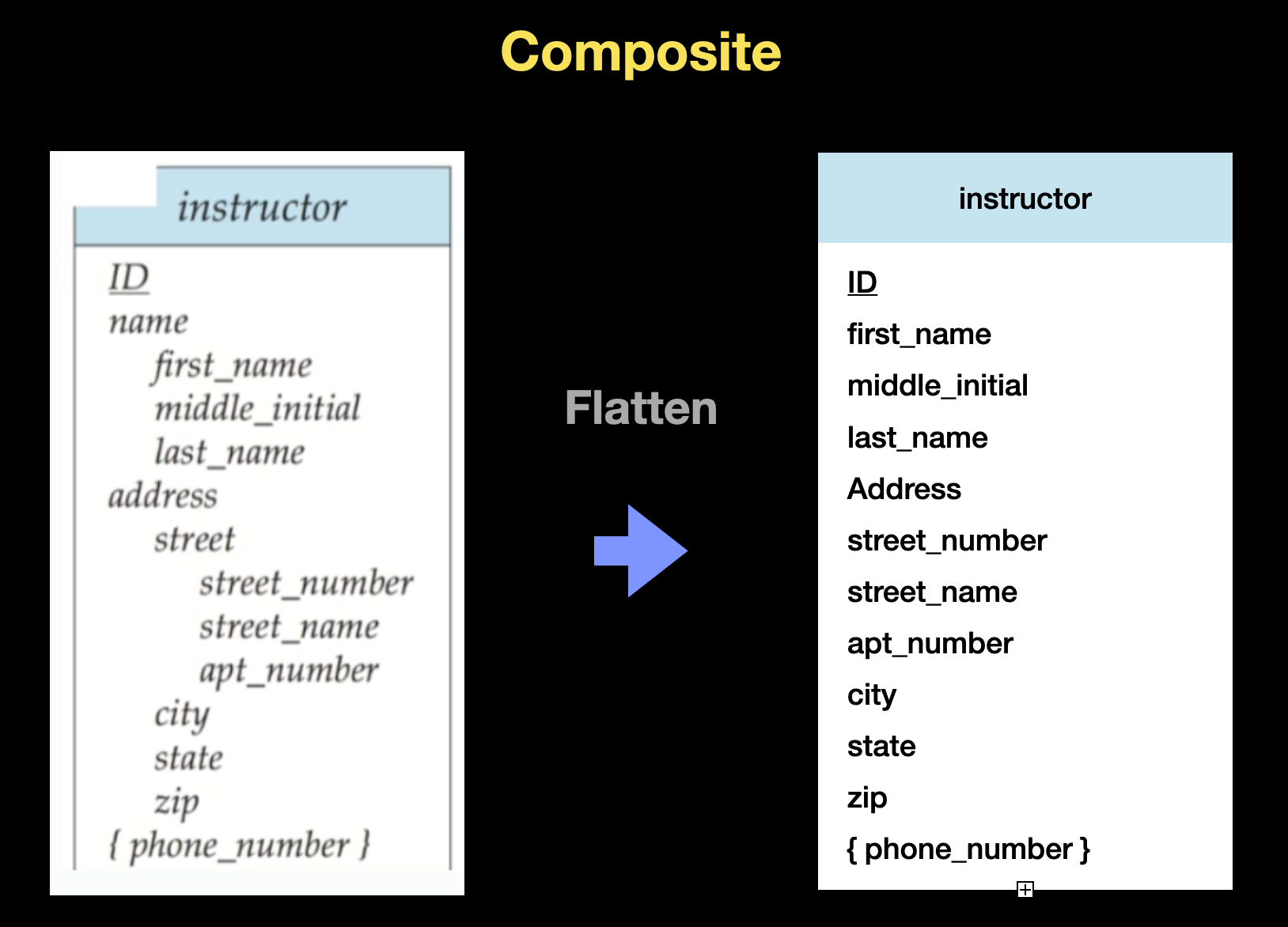
🔘 Composite Attribute
계층 구조를 가지는 Composite Attribute는 하위 attribute를 전부 별도의 attribute로 만들어 평평하게 만들어 주는 방법이 있습니다 (계층 구조를 없앰). 위 예시에서는 상위 attribute의 이름을 전부 접두어로 붙혀 주었는데 구분이 잘 된다면 빼도 괜찮습니다
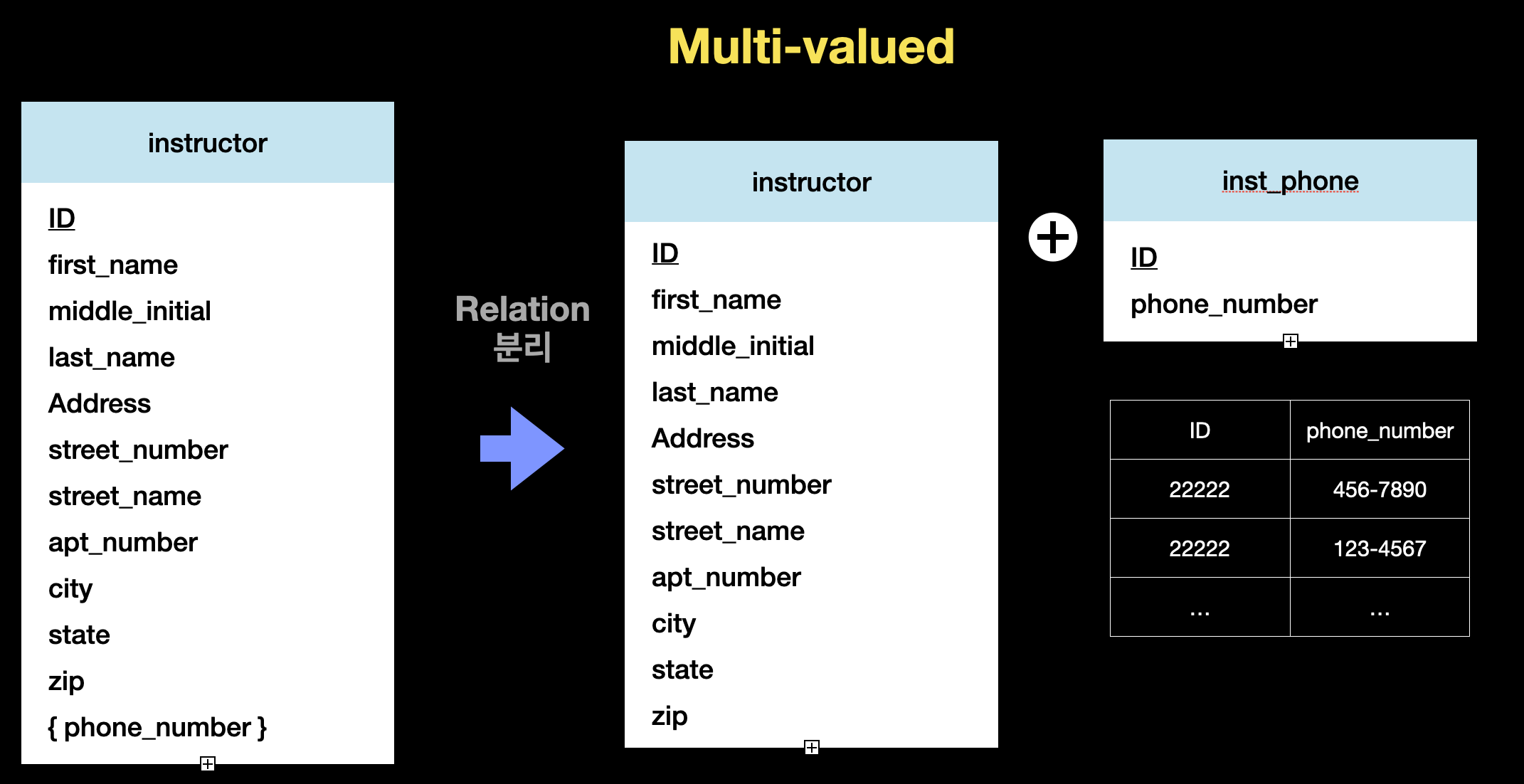
🔘 Multi-valued Attribute
한 번에 여러 값을 가지는 Multi-valued의 경우 별도의 스키마를 만들어 주게 됩니다. 만약 Entity Set E와 Multi-valued attribute M이 있다면 EM 스키마를 만들게 됩니다
EM 스키마는 E의 primary key와 M으로 이루어지며 EM의 primary key는 자신의 모든 attribute가 됩니다. 예로, instructor라는 Enitity Set에 Multi-valued attribute인 phone_number가 있다면, instructor의 primary key와 phone_number로 구성된 inst_phone 스키마를 만들게 됩니다. 그리고 phone_number의 각 값은 새로이 만든 inst_phone의 독립된 튜플이 됩니다
이렇게 만들어진 EM 스키마는 E의 primary key로 만들어진 Foreing key constraint를 가지게 됩니다
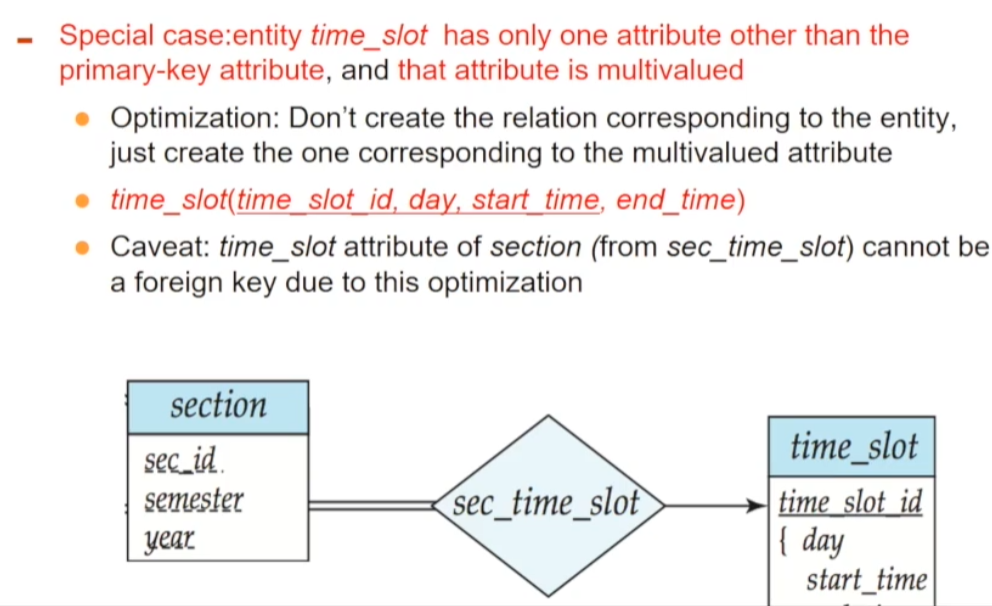
🔘 Multi-valued 특이 케이스
특별한 케이스가 있는데, E가 이미 primary key + M 만으로 구성되어 있는 경우라면 최적화를 위해 별도로 만들진 않습니다. 위 예시에선 time_slot은 tiem_slot_id라는 primary key 외에는 전부 Multi-valued만 가지고 있습니다. 이 경우엔 별도의 Relation을 생성하지 않고 그대로 만듭니다 (time_slot_id, day, start_time, end_time)
그런데 이러면 원래 primary key였던 time_slot_id에 대해 튜플이 없거나 복수의 튜플을 가질 수 있게 됩니다. 이렇게 중복이 가능하므로 sec_time_slot이 참조할 foreign key가 될 수 없게 됩니다. (최적화도 하면서 온전히 해결하는 방법은 설명하지 않는 것으로 보아 아마 없나 봅니다)
🌀 디자인 고려사항
🔸 Entity Set vs Attribute
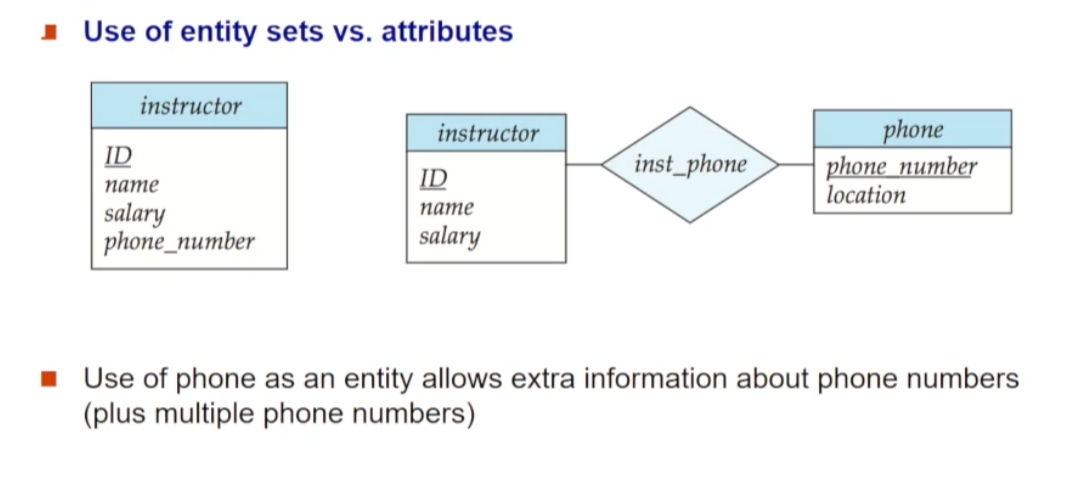
어떤 것을 Entity Set으로 만들고, 어떤 것을 Attribute로 만들지에 대해 다룹니다. 위 예시는 전부 하나의 entity set으로 만든 경우(좌)와 phone정보를 분리한 경우(우)를 나타냅니다. phone 정보를 분리했을 때의 장점은 하나의 instructor가 여러 개의 phone을 가질 수 있고 number 외에도 추가적인 phone 정보를 표현해줄 수 있다는 것입니다
🔸 Entity Set vs Relationship Set
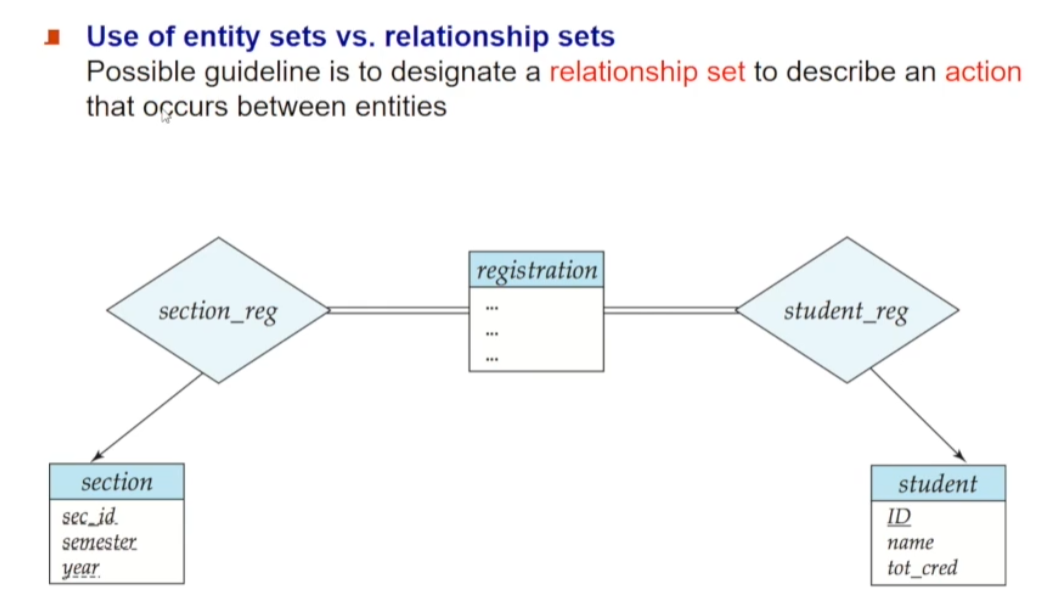
이에 관한 가이드라인으로, 두 entity set 사이에 어떤 action이 발생하는지를 표현하고 싶을 때 Relationship Set을 사용하라는 것 입니다. 위 예시는 하나의 Relationship Set으로도 충분히 연결할 수 있는 section/student를, 수강기록을 나타내는 registration과 section_reg/student_reg로 만든 것입니다. 저장 공간 측면에서는 하나의 Relationship Set 표현이 나을 수 있지만, 다른 정보를 registration이라는 수강정보와 연결시킨다면 따로 entity set을 만드는 게 좋을 수 있습니다
🔸 Relationship Attribute 배치
Relationship Attribute 배치란, instructor와 student 사이에 advisor라는 관계집합이 있을 때 연결고리로 삼을 Date라는 Attribute를 advisor 자체에 정의할지 entity set인 student에 정의할지와 같은 고민입니다
🔘 Cardinality 별 가능한 배치 위치
이는 Cardinality 별로 다른데 기본적으로 Relationshipt Set에는 항상 가능하며
- One-to-One : 양쪽 Entity Set 어디든 가능
- One-to-Many/Many-to-One : Many쪽 가능
- Many-to-Many : Entity set에는 불가
🔸 Binary vs non-Binary
우선, 이미 binary인건 binary로 사용합니다. 반면 non-binary는 여러 개의 binary로 쪼갤 수 있는 경우도 있어서 이렇게 쪼개는게 가능한 경우엔 어떤 모습이 더 잘 표현하는 것인지 고민해야 합니다 (원래부터 non-binary라서 쪼갤 수 없는 경우도 존재하며 그 때는 non-binary를 사용합니다). 쪼개는 방법에 대해 더 다뤄 보자면,

🔘 쪼개기 예시
쪼개는 간단한 예로, 아이/아버지/어머니가 ternary로 연결되어 있을 때 아이/아버지와 아이/어머니라는 두 개의 binary로 대체하는 것이 있습니다. 위 자료에 non-binary를 binary로 바꾸는 일반적인 과정을 설명하고 있으나 이해가 안되어 pass.. 아무튼 이런 변환은 추가적인 저장공간을 요구하고 디자인이 더 복잡해질 수 있어 항상 바람직하진 않다는 점에 유의합니다

non-binary를 binary로 바꾸려면 제약조건도 변환해주어야 합니다. 이것도 이해가 안되어 pass..제약조건을 변환하는 것은 방법이 없는 경우도 있습니다
🌀 Extended E-R 모델
대부분의 DB 특성은 지금까지 배웠던 기본적인 E-R 개념으로 모델링할 수 있습니다. 하지만 Extended E-R 모델을 사용하면 더 잘 표현할 수 있는 DB들이 존재합니다
🔸 Specialization이란?
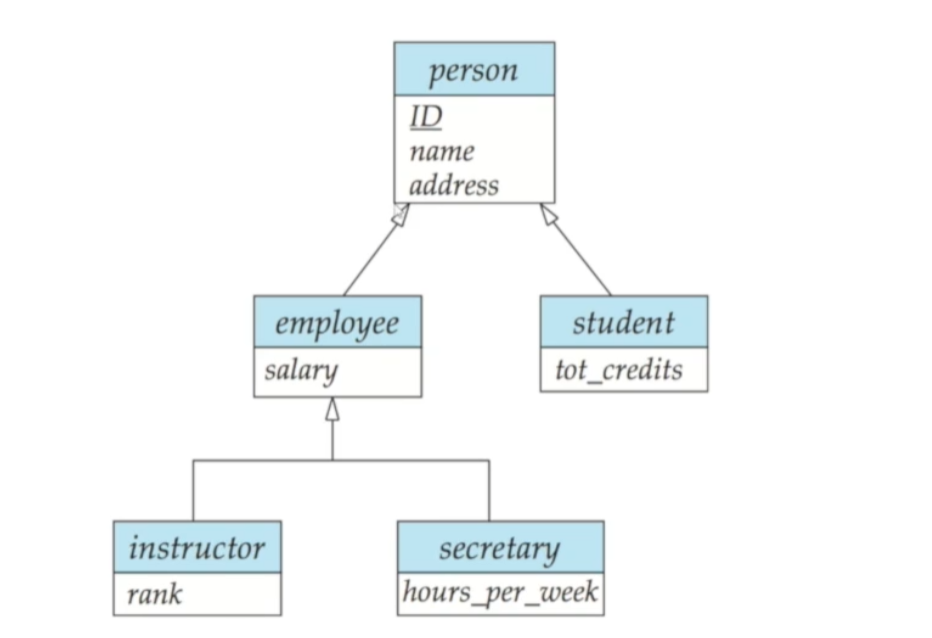
🔘 Specialization
Specialization은 하위집합을 만들어가는 개념으로, Entity Set에 subgrouping/상속관계를 지정하는 것을 말합니다. subgroup은 원본 Entity Set이 가지고 있지 않던 Attribute를 가지거나 참여하지 않던 관계에 참여할 수 있습니다
🔘 다이어그램 표현
위 그림처럼 속이 빈 화살표로 표현합니다. person이 상위 집합이고 employee가 하위 집합입니다. 이 화살표는 상속과 같은 의미인 ISA 관계를 보여주는 것인데, ISA는 영어 "is a"에서 나온 말로 employee is a person을 의미합니다
🔘 Attribute Inheritance
Attribute Inheritance는, 하위집합이 상위집합의 모든 Attribute와 참여 관계를 상속받음을 뜻합니다
🔸 Generalization이란?
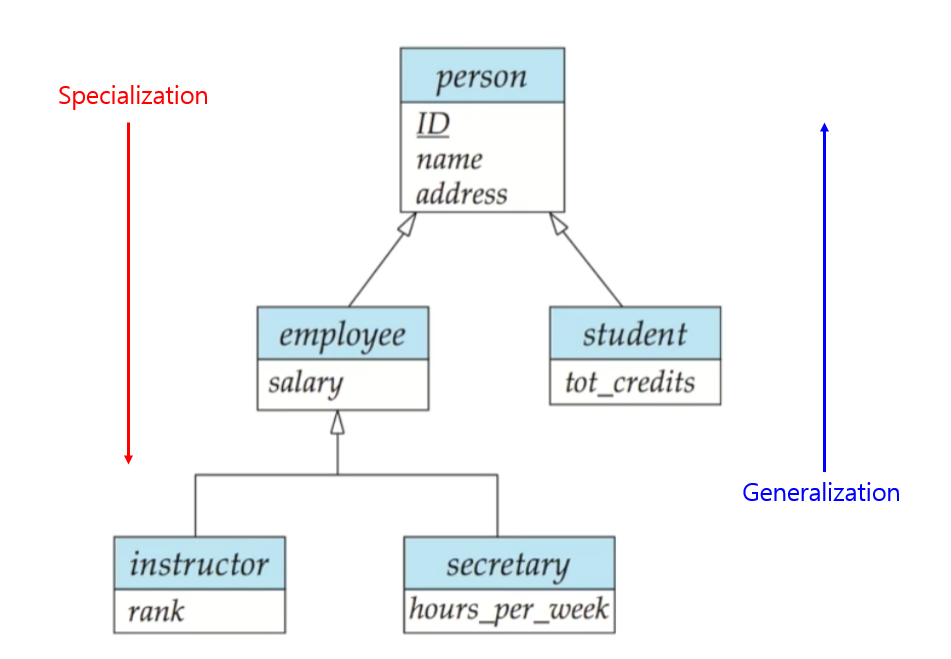
Generalization는 상위집합을 만들어가는 개념으로, 동일한 기능을 공유하는 여러 Entity Set들을 상위집합으로 결합해나가는 것을 말합니다. Specialization과는 역의 관계를 가집니다. 그래서 다이어그램 표현이 동일합니다
🔸 Specialization/Generalization 디자인 제약조건
🔘 Specialization 제약조건
상위집합에서 Entity 하나를 집고 하위집합 중 하나를 집어, 이 Entity가 해당 하위집합의 멤버가 될 수 있는지에 대한 제약조건이 있습니다. condition-defined와 user-defined 두 가지가 있습니다
-
condition-defined는 명확한 조건이 존재하고 해당 Entity가 이 조건을 만족하는지 여부에 따라 멤버가 될 수 있는지를 평가합니다. 예로, person의 하위집합인 senior-citizen에 대해 "나이 65세 이상"과 같은 명확한 조건을 만드는 것입니다 -
이에 반해,
user-defined는 명확한 조건이 없고 결정권자 개인의 기준에 의해서 결정하는 것입니다. 예로, 어느정도 연수가 끝난 직원을 부서에 배치할 때 명확한 조건없이 팀장이 개인적인 기준에 의해서 배치하는 것이 있습니다
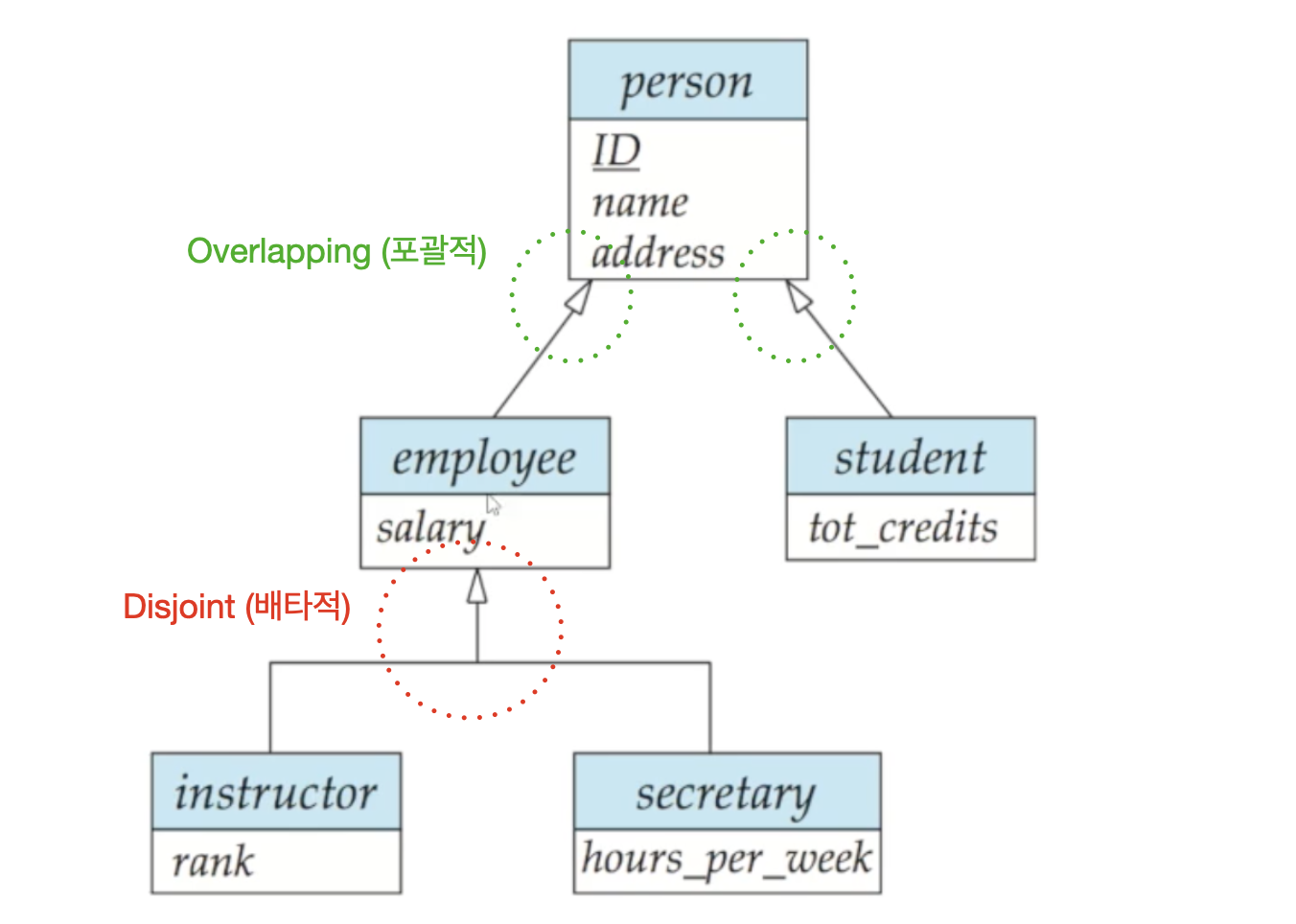
🔘 Generalization 제약조건
하나의 Generalization에서 어떤 entity가 여러 하위집합에 속할 수도 있는가에 대한 제약조건을 말합니다. disjoint와 overlapping 두 가지가 있습니다
-
Disjoint는 하나의 entity는 오직 하나의 하위집합에만 속해야 함을 뜻하며 위와 같이 모이는 화살표로 표현합니다. 예로, employee와 student를 상위집합 person으로 Generalization 하였다면, person의 모든 entity는 employee와 student 중 반드시 하나에만 속해야 합니다 -
Overlapping은 하나 이상의 하위집합에 속할 수 있는 것을 말하며 위와 같이 분리된 화살표로 표현합니다. 직전 예시에서 person의 어떤 entity가 employee면서 student일 수 있는 상황을 말합니다
🔘 Generalization 제약조건 2
추가로, Completeness constraint가 있는데, 상위집합의 entity가 적어도 하나의 하위집합에 속해야만 하는가에 대한 제약조건입니다. (이전에 다룬 전체참여/부분참여와 비슷한 개념같기도)
total: 적어도 하나의 하위집합에는 속해야 한다partial: 어느 하위집합에도 속하지 않는 entity가 존재한다
🔸 Aggregation이란?
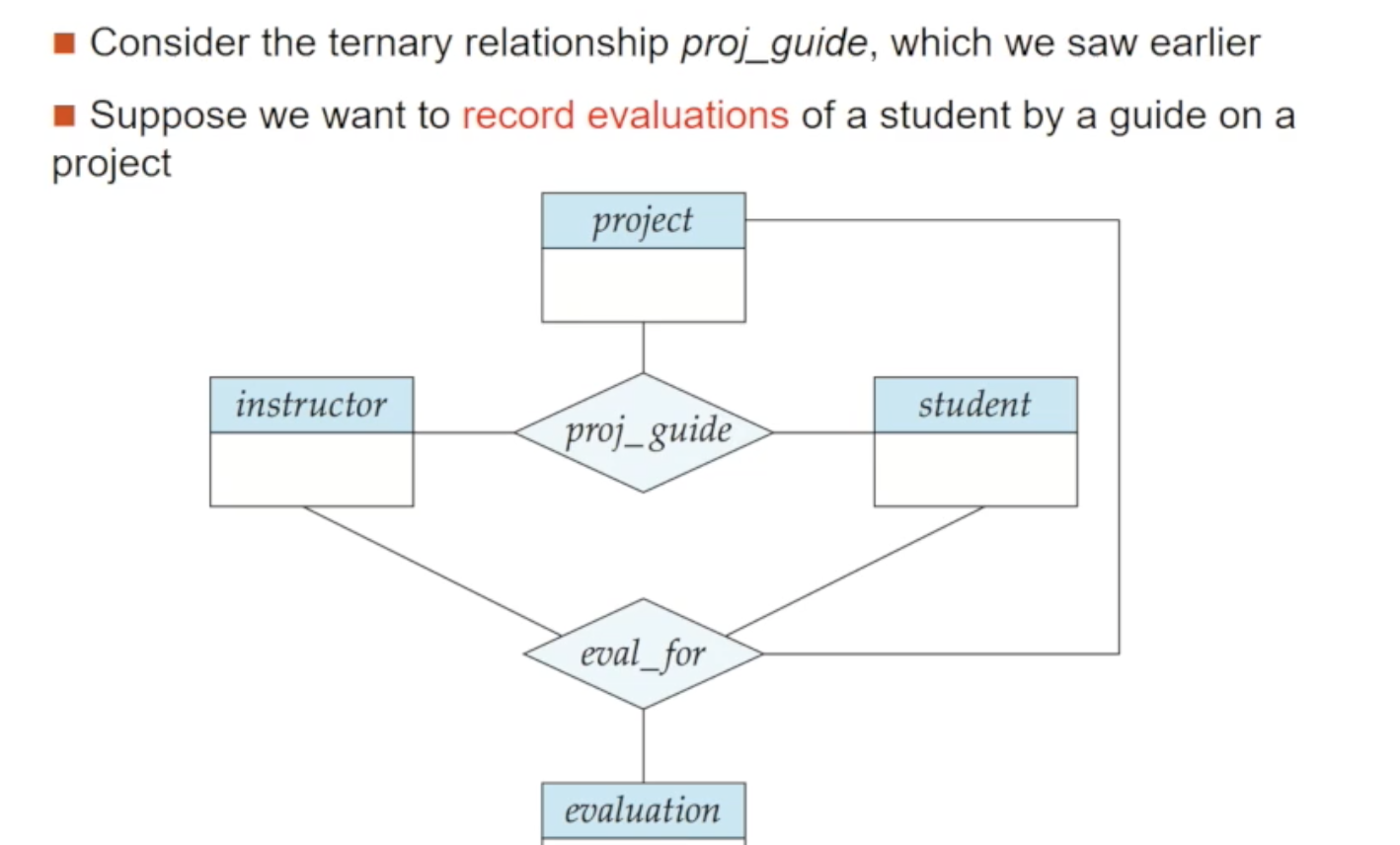
🔘 기존 E-R 모델의 한계
E-R 모델의 한 가지 한계는 relationship 간의 relationship을 표현하지 못한다는 것입니다. 위 사진에서 project/instructor/student의 ternary 관계집합인 proj_guide에 대해 생각해봅시다. 이렇게 프로젝트에 참여하여 학생을 지도하는 교수님은 매월 평가 보고서를 제출해야 한다는 요구사항으로 evaluation이 만들어졌고 관계에 참여시키는게 필요한 상황입니다. 위 예시에선 이를 위해 단순하게 project/instructor/student 모두와 관계를 맺었습니다만, 사실 이렇게 만들어진 eval_for는 기존의 proj_guide와 같은 정보를 표현하게 되어 중복이 발생합니다
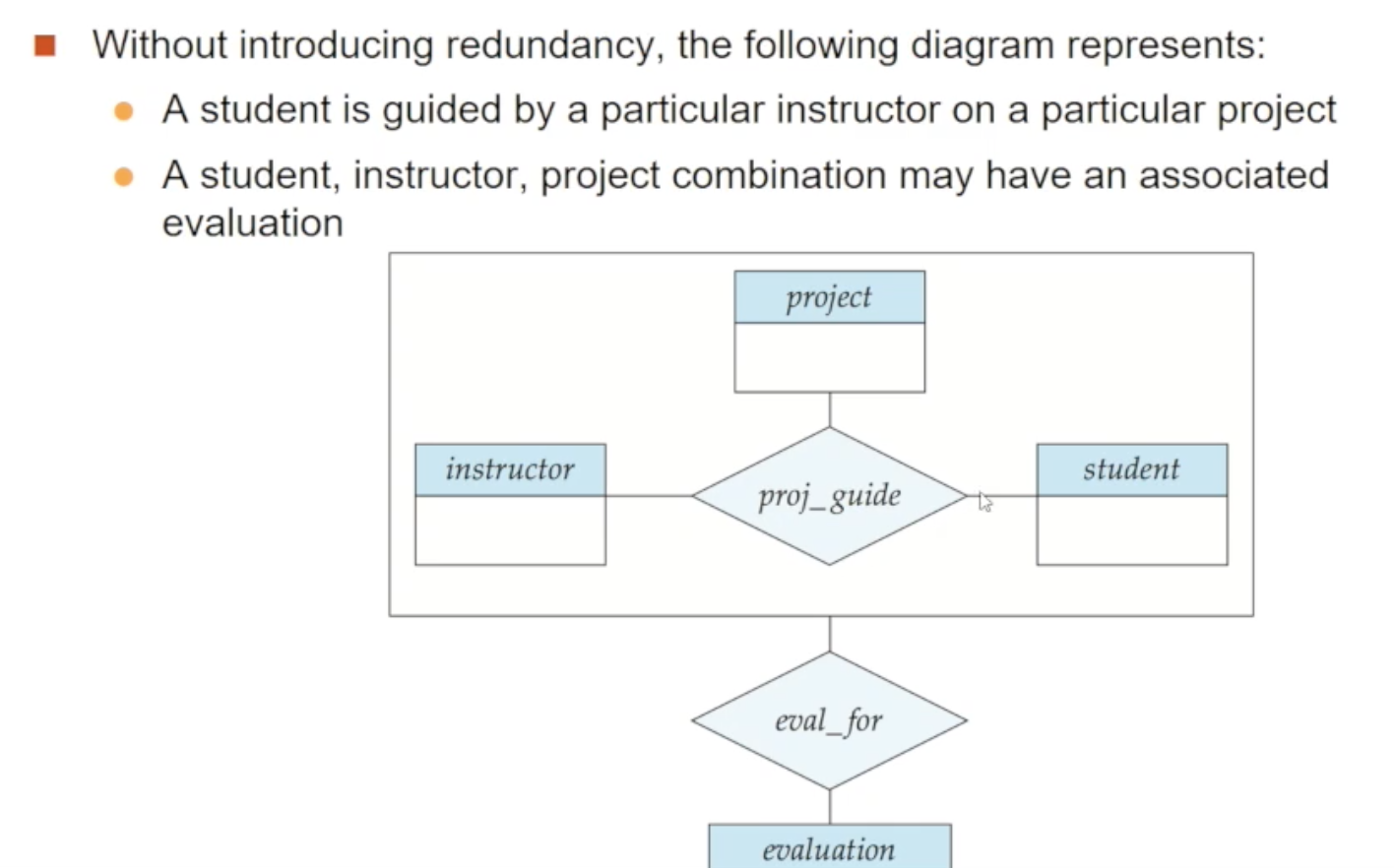
🔘 Aggregation이란
이런 중복을 aggregation이라는 이름의 통합화를 통해 제거할 수 있습니다. 어떤 relationship을 추상적인 entity set으로 취급하여 relationship 간의 relationship을 허용해줍니다. 위 그림에선 proj_guide와 그에 참여하는 entity set들을 묶어 하나의 entity set으로 취급한 후 evaluation과 관계를 맺은 것입니다. 이를 통해 중복없이 각 project/instructor/student의 조합은 하나의 관련 evaluation으로 연결되는 것을 표현할 수 있습니다
🔸 Specialization을 실제 스키마로 구현하기
여러 방법이 있습니다
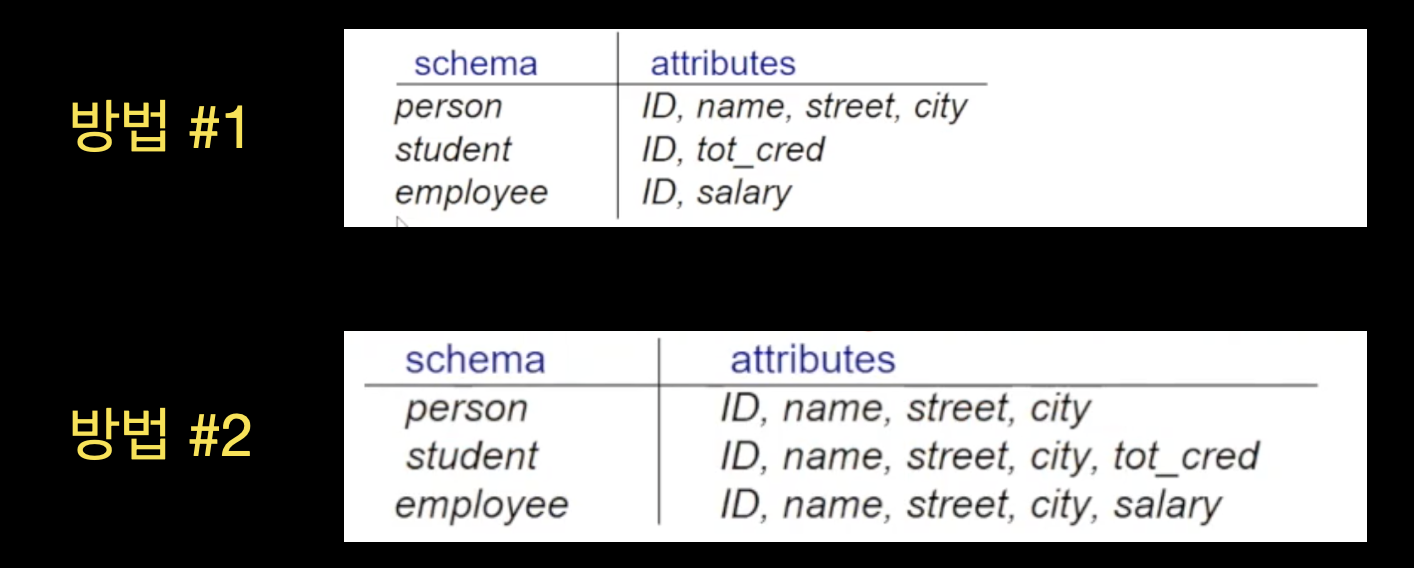
🔘 방법 #1
첫 번재 방법은 하위집합이 상위집합으로부터 기본키만 취하는 것입니다. 상속받은 기본키에 더해 자신의 자체 속성을 추가하여 스키마를 구성합니다
하지만 이 방법에는 상위집합과 하위집합 두 개의 relation에 접근해야 되는 일이 발생한다는 단점이 있습니다. 예로, employee에 대한 모든 정보를 취득하려면 person에도 접근하여 name, street, city를 가져와야 합니다
🔘 방법 #2
두 번째 방법은 표에 보이듯이 합집합 개념으로 스키마를 만드는 것입니다. 하위집합의 자체 속성과 상속받은 속성을 모두 포함하게 됩니다
이 방법을 사용할 때 만약 Specialization이 total이라면, student와 employee에 person의 모든 정보가 담겨 있으므로 상위집합 person을 위한 스키마는 별도로 작성할 필요가 없어집니다. 오히려 하위집합들의 합집합 형태를 띄는 view relation이라 볼 수 있습니다. 하지만 foreign key constraint를 명시하기 위해서는 필요할 수도 있습니다
이 방법 역시 단점이 존재합니다. Specialization이 overlapping이라 어떤 person이 student면서 employee인 경우에 중복이 발생합니다. 하나의 동일한 person정보 name,street,city가 student에도 있고 employee에도 중복으로 존재하게 됩니다
🔸 Aggregation을 실제 스키마로 구현하기
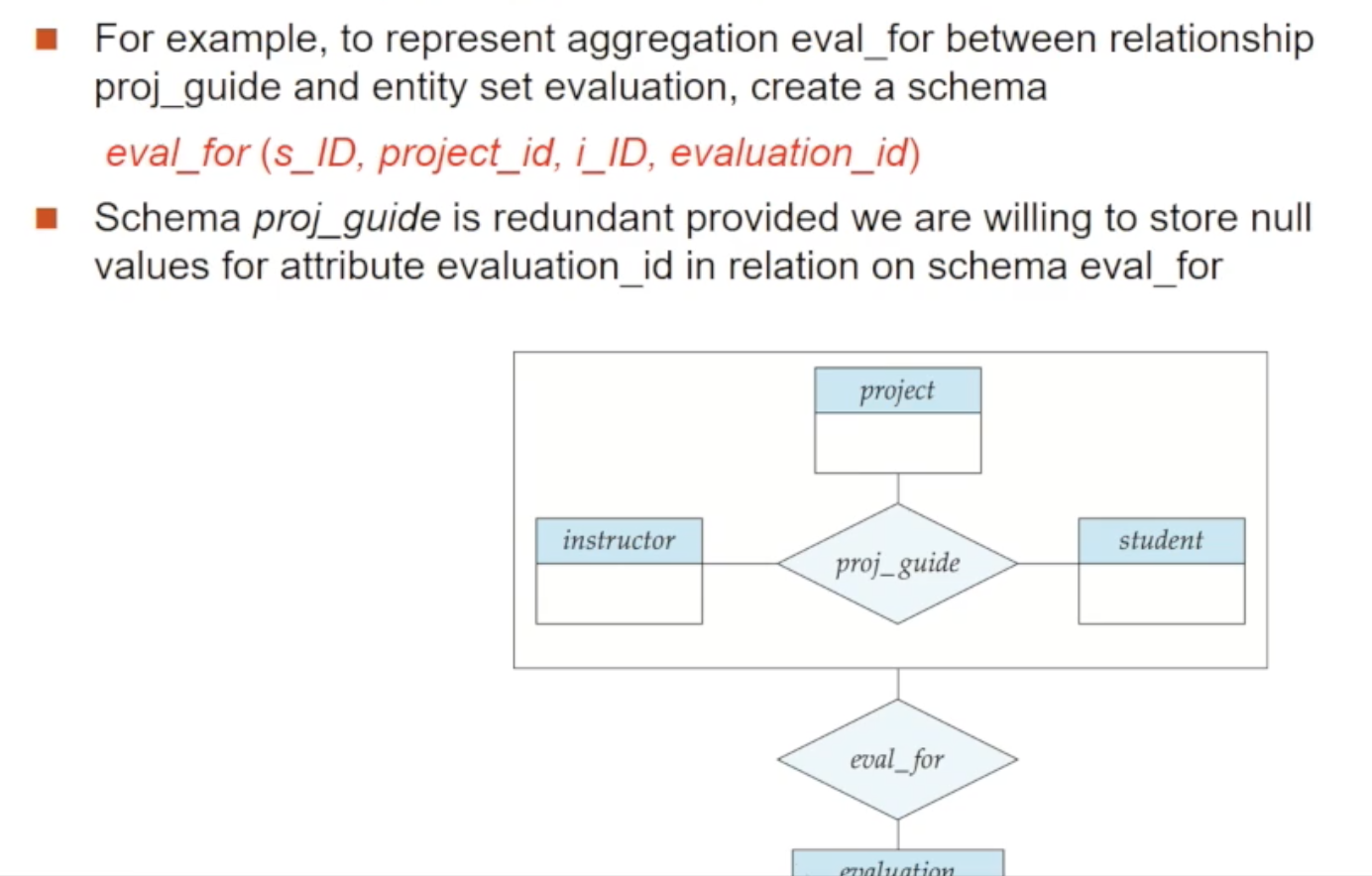
Aggregation은 relationship과 relationship 간의 관계 연결을 표현하기 위해 한 쪽 relationship + 참여 entity set들을 묶어 하나의 entity set으로 만들어주는 것이었습니다
새로이 연결하려는 관계집합에 대한 스키마를 표현하려면, 새로운 entity set의 기본키와 연결대상 관계집합의 기본키를 가지게 하면 됩니다. 위 사진에서 보면, eval_for라는 관계집합에 대한 스키마를 만드려면, 먼저 evaluation의 기본키(evaluation_id)를 포함하고 proj_guide의 기본키(s_ID,project_id,i_ID)를 가지게 하면 됩니다. 추가로, 자신만의 속성을 가지고 있다면 그것도 포함시킵니다
🌀 E-R 모델 총정리
🔸 디자인 고려사항

- 객체 표현을 위해 Attribute를 사용할지 / Entity Set을 사용할 것인지
- 실세계의 개념을 나타낼 때 Entity Set으로 나타낼지 / Relationship Set으로 나타낼지
- ternary Relationship을 그대로 사용할지 / 여러 개의 binary로 분리할지
- strong으로 만들지 / weak로 만들지
- Specialization/Generalization 사용여부 (디자인에 있어 모듈화에 유용)
- Aggregation 사용여부 (student/instructor/project와 proj_guide와 같은 내부구조에 대해선 자세히 고려하지 않고 그냥 aggregated된 한 덩어리로 다룰 수 있기에 편하다)
🔸 다이어그램