Reference
🐶 제네릭 메서드 메커니즘
제네릭 타입 변수가 어떻게 저장되고 복사되는지, Dispatch는 어떻게 동작하는지 알아봅니다

위와 같이 제네릭 타입을 파라미터로 받는 함수 foo()/bar()가 있습니다. 여기서 foo()메서드에 Point인스턴스를 전달하면 어떻게 될까요?
Swift는 제네릭타입 T를 call context에 따라 argument 타입으로 바인딩(대체)합니다. 즉, T를 Point로 바인딩하게 됩니다

메커니즘을 조금 더 구체적으로 알아봅시다. 이전에 살펴봤던 프로토콜 타입을 다룰 때와 유사하면서도 약간 다릅니다. 제네릭도 PWT와 VWT를 사용하게 됩니다. 하지만 한 번의 호출에 하나의 타입만을 다루므로, 여러 타입 인스턴스들을 하나의 틀에 담기 위해 만들어진 Existential container는 사용되지 않습니다
대신, 해당 인스턴스의 PWT와 VWT를 추가 argument로 전달하게 됩니다

이후 제네릭 타입 파라미터인 local의 값을 채우기 위해, 함께 전달된 VWT로 allocate/copy를 수행합니다. 그리고 draw() 메서드 구현체를 결정하기 위해서는 PWT를 사용합니다
여기서 Existential container과 비슷하지만 약간 다른 컨테이너가 등장합니다. 사실 다르다기보단 Existential container에서 valueBuffer만 추려낸 형태입니다. PWT / VWT는 별도의 파라미터로 전달받으므로 3word valueBuffer만 가지는 형태의 컨테이너에 local이 저장됩니다. 3word를 초과할 경우 마찬가지로 Heap 할당이 발생합니다
🐱 Specialization 최적화
제네릭 메서드의 성능에 대해 알아봅니다. Specialization이라는 최적화 기법이 핵심입니다
🌀 Specialization 메커니즘
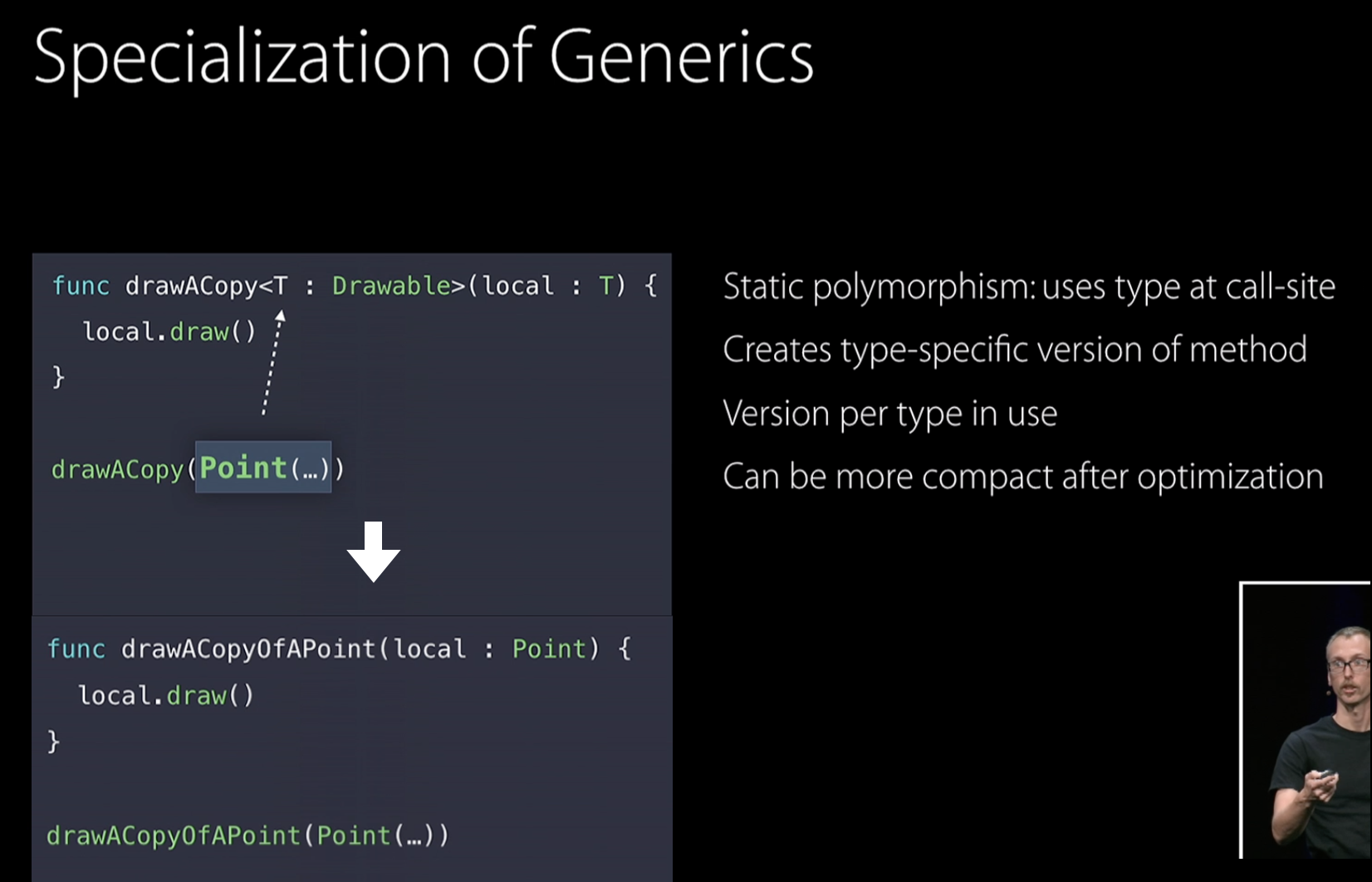
Generic Specialization이라는 컴파일러 최적화 기법이 있습니다. 이 기법을 사용하면 제네릭 메서드에 대해 타입전용 메서드들을 만들어내게 됩니다. 위와 같이, 우리는 drawACopy()메서드만 구현하였지만, 최적화를 통해 Point 전용 메서드 drawACopyAPoint()가 만들어집니다.
즉, Specialization을 통하면 파라미터 타입의 다형성은 지원하면서도 메서드 구현체가 무엇인지 명확하므로 Static Dispatch가 가능하도록 구현할 수 있습니다
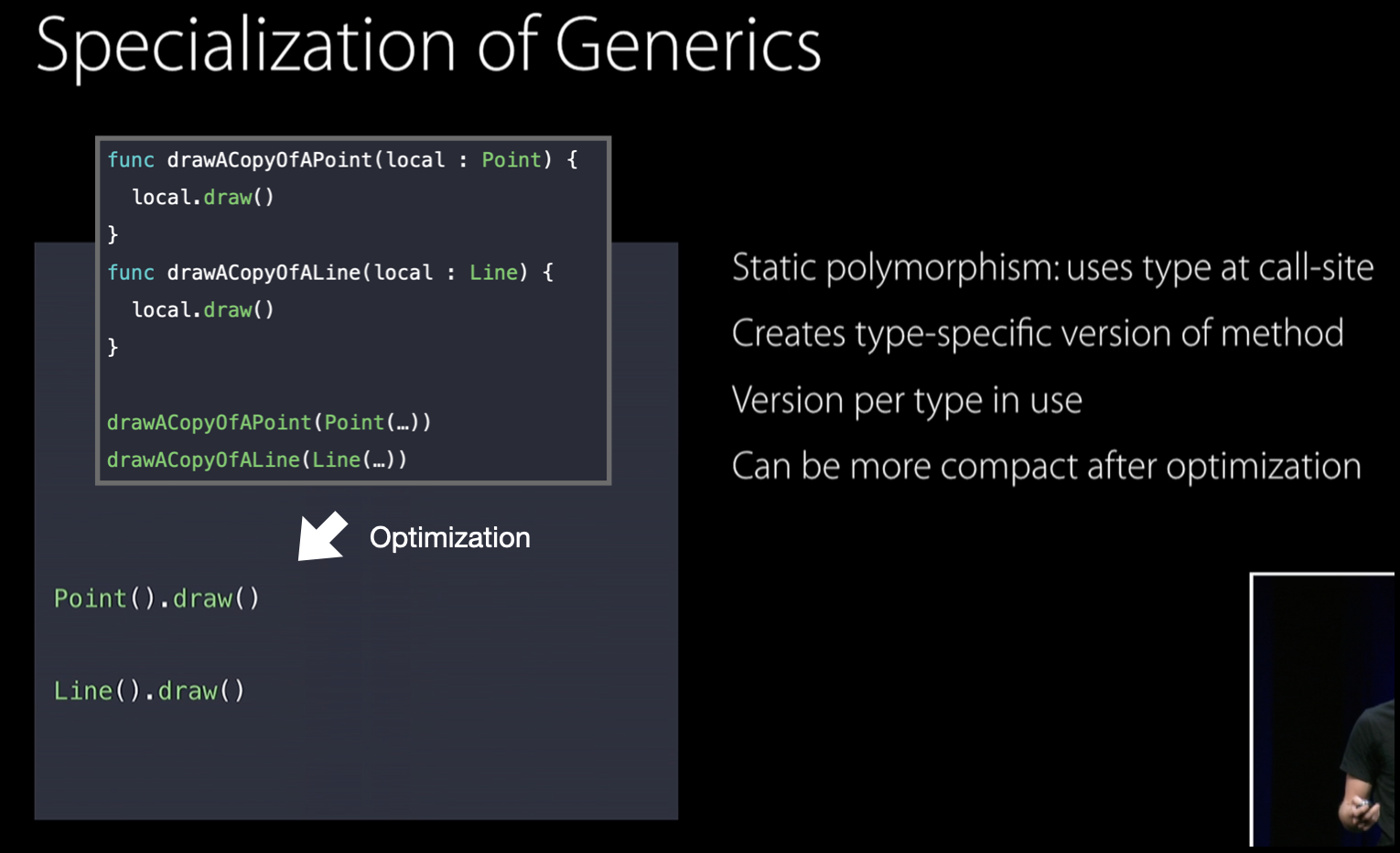
물론 코드 사이즈가 너무 늘어나는 것 아니냐는 의문이 있을 수 있습니다. 하지만 이런 방식은 컴파일러에게 더 많은 context를 제공함으로써 공격적인 최적화가 가능해지기에 경우에 따라선 위 예제와 같이 코드 사이즈를 오히려 줄여버릴 수도 있게 됩니다
🌀 Specialization 적용 조건
🔸 1. 명확한 타입 추론

Specialization을 적용하려면 몇가지 조건이 있습니다. 먼저, 호출부에서 arguement의 타입을 명확히 추론할 수 있어야 합니다. (예제에서는 Point)
🔸 2. 타입 정의부와 제네릭 메서드를 함께 컴파일

그리고, argument로 넘길 타입의 정의부와 해당 제네릭 메서드를 함께 컴파일해야 서로의 관계를 파악하고 최적화를 적용할 수 있습니다. 여기서 WMO(Whole Module Optimization)를 사용하면 Specialization를 적용할 기회를 향상시킬 수 있습니다 (WHO는 Xcode8부터 기본적용)
🐭 제네릭 stored 프로퍼티
제네릭 Stored 프로퍼티의 메커니즘을 알아봅니다

비교를 위해 먼저 가져온 프로토콜 타입을 사용하는 예제입니다. 이 예제를 프로토콜 타입으로 구현할 경우 메모리 표현에 보이듯 2번의 Heap 할당 비용이 들게 됩니다

이걸 제네릭 코드로 구현하면 어떻게 될까요? 놀랍게도 Heap 할당없이 사용할 수 있게 됩니다
제네릭 메서드를 최적화했던 것처럼 Specialization을 통해, Pair(Line,Line)라는 storage 타입을 inline으로 만들어 내게 됩니다. 이로 인해 일반적인 value type과 동일하게 사용할 수 있게 되어 Heap 할당 비용을 없애고 Static Dispatch를 사용하게 됩니다
🐹 케이스별 성능비교
🌀 Specialization 적용
🔸 Struct

Specialization을 적용한 제네릭 Struct는 사실상 일반적인 struct와 동일합니다. Heap 할당과 reference counting이 없으며, Static Dispatch와 함께 컴파일러 최적화를 누릴 수 있습니다
🔸 Class

이 또한 일반적인 class와 동일합니다. 원래 class가 그렇듯 Heap 할당이 필요하고, Referenc counting이 발생하며, V-Table을 통한 Dynamic Dispatch를 사용합니다
🌀 Specialization 미적용
🔸 Small Value

3word valueBuffer에 모든 value를 담을 수 있는 경우, Heap 할당과 reference counting은 막을 수 있습니다. 하지만, Specialization은 불가한 경우이므로 PWT를 통한 Dynamic Dispatch를 사용해야 합니다
🔸 Large Value

value가 3word를 초과하면서 Specialization도 안된다면 Heap 할당이 불가피합니다 (Indirect Storage로 Copy on Write을 구현하여 비용을 경감시킬 여지는 있습니다). 또한 Reference counting이 발생하고 Dynamic Dispatch를 사용해야 합니다
🐰 Summary

dynamic한 런타임 타입 요구사항이 가장 적은 추상화 메커니즘을 선택할 것. Static할수록 컴파일 타임에 프로그램이 올바른지 확인하고 최적화 기회가 많아집니다
- 되도록 value sementic을 사용하는 struct/enum을 사용하여 의도치않은 sharing을 방지하고 최적화 기회를 제공할 것
- identity로 다루는게 필요하거나 OOP framework를 사용해야 하는 경우 class를 사용하되 우리가 다뤘던 referece counting을 줄이는 기법들을 적용하려 노력할 것
- 제네릭 사용을 권장합니다. Specialization과 함께 Static한 다형성을 구현할 수 있습니다
- Dynamic한 다형성이 필요한 경우엔 상속 대신 프로토콜 타입을 사용하면 value type도 지원할 수 있습니다
프로토콜타입 / 제네릭타입으로 Large value를 다뤄야 하는 경우, Indirect Storage(copy on write)를 사용하여 Heap 할당 비용을 줄일 여지가 있습니다
