
이번주는 JPA 대해 배우게 된다!
실습 내용은 간단한 것 같으니, 돌아가는 원리에 대해 공부해보자
@PersistenceContext?
EntityManager를 주입할 때, 사용하는 어노테이션이다.
사용해야 하는 이유?
-
EntityManager는 동시성 문제 때문에 쓰레드 간에 EntityManager를 공유해서는 안된다.
-
@PersistenceContext가 EntityManger를 주입받을 때, 동시성 문제가 발생하지 않도록 도와준다.
- 스프링 컨테이너가 초기화되면서, EntityManager를 Proxy로 감싸준다.
- EntityManager 호출 시마다 Proxy를 통해, EntityManager를 생성하여 Thread-Safe를 보장한다.
@GeneratedValue strategy 종류
총 4가지가 있다
-
GenerationType.IDENTITY
- EntityManager.persist() 할 때, Insert SQL을 실행하여 DB에서 식별자 값을 받아온다.
- 영속성 컨텍스트 1차 캐시에 값을 넣어주기 때문에, 관리가 가능해진다.
- 원래는 DB에 값을 넣기 전까지 기본키를 알 수 없기 때문에, 1차 캐시에서 PK와 객체를 가지고 관리를 못하는데, 해당 전략에선 가능하다.
- 대량의 데이터를 삽입하거나 병렬 처리가 필요한 경우, 다른 전략을 사용하는 것이 성능 면에서 더 유리할 수 있다.
-
GenerationType.SEQUENCE
hibernate: call next value for USER_PK_SEQ- EntityManager.persist() 호출하기 전에, 하이버네이트에서 위를 실행하여 기본키를 가져온다.
- IDENTITY 전략과 다르게 쿼리문을 실행하지 않는다.
- 하지만, SEQUENCE 값을 계속 DB에서 가져와야 해서 성능 저하 생길 수 있음
- 그래서, allocationSize 크기를 조절해 개선한다.
- @SequenceGenerator가 필요하다.
@Entity @SequenceGenerator( name = "USER_PK_GENERATOR", sequenceName = "USER_PK_SEQ", initailValue = 1, allocationSize = 50 ) public class PkEx() { @Id @GeneratedValue(strategy = GenerationType.SEQUENCE, generator="USER_PK_GENERATOR") private Long id; private String name; } -
GenerationType.TABLE
- 키를 생성하는 테이블을 사용하는 방법ㅂ으로 Sequence와 유사하다.
- @TableGenerator가 필요하다.
- 시퀀스를 지원하지 않는 데이터베이스를 사용할 때나, 프로젝트에서 데이터베이스 간 이식성을 극대화하고자 할 때 사용된다.
- 그러나 성능 측면에서 제약이 있으므로, 가능하면 다른 전략을 쓰는 것이 좋다.
@Entity
@TableGenerator(
name = "USER_PK_GENERATOR",
table = "USER_PK_SEQ",
pkColumnValue = "USER_SEQ",
allocationSize = 1
)
public class PkEx() {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator="USER_PK_GENERATOR")
private Long id;
private String name;
}-
GenerationType.AUTO
- 기본 설정 값이며, 각 데이터베이스에 따라 기본키를 자동으로 생성한다.
- 기본키의 제약조건
- null이면 안된다.
- 유일하게 식별할 수 있어야 한다.
- 변하지 않는 값이어야 한다.
CrudRepository vs JpaRepository
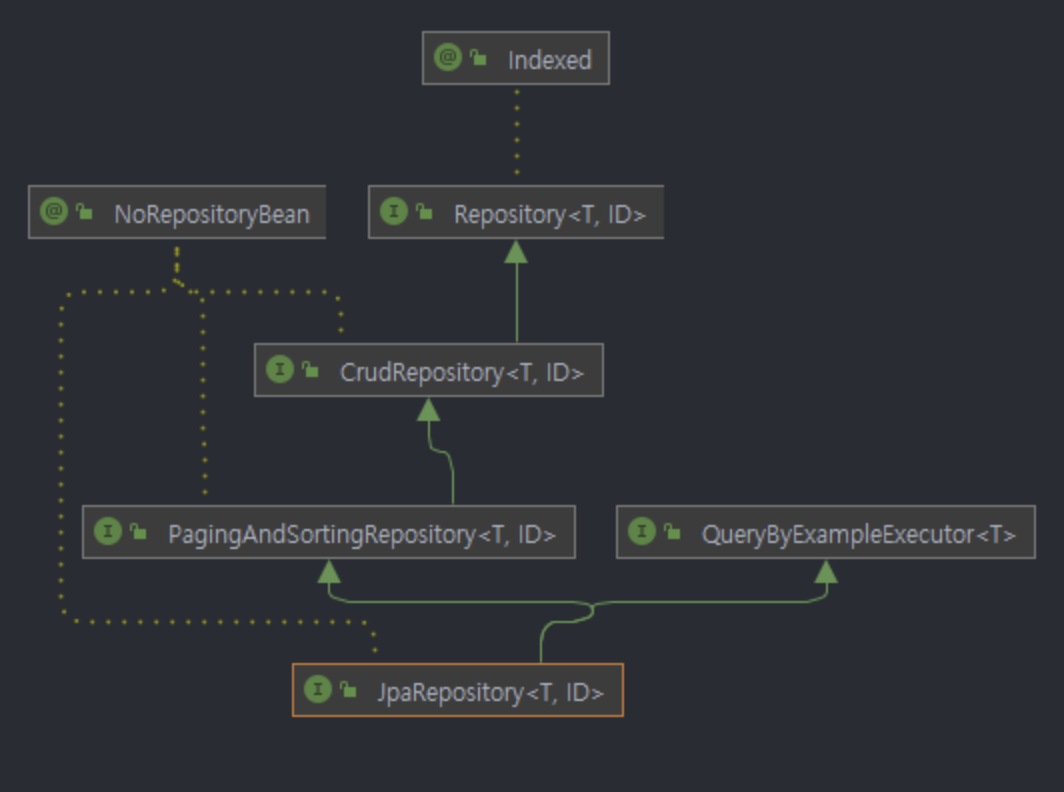
위 사진을 보면, JpaRepository는 CrudRepository를 상속받은 PagingAndSortingRepository를 상속받음을 알 수 있다. 그래서, JpaRepository는 CrudRepository에 정렬, 페이징 기능이 추가되었음을 알 수 있다.
//CrudRepository
Iterable<T> findAll();
//JpaRepository
List<T> findAll(Sort sort);두 repository에서 findAll을 가져와봤는데, 둘의 차이를 확실히 볼 수 있다.
CrudRepository의 findAll은 반환형이 Iterable인데, JpaRepository에선 List이다.
또한, Sort 파라미터를 받고 있어, JpaRepository에서만 정렬을 지원함을 알 수 있다.
CrudRepository 왜 쓸까?
이렇게 보면, JpaRepository가 CrudRepository의 상위호환이라 전혀 사용할 이유가 없어보이는데, 사용하는 경우가 존재한다.
- 시스템의 설계를 간단하게 만들기 위해서
- 현재 단순 CRUD 기능만 제공하고자 할 때, 불필요하게 정렬, 페이징 관련 인터페이스를 상속 받을 이유가 없다.
- 다른 개발자가 명세를 착각할 수 있다
- 해당 기능이 페이징, 정렬 기능을 사용하지 않는데, 다른 개발자들이 명세만 보고 사용한다고 착각할 수 있다.

꾸준히 성실하게