gSpan을 검색해보면 graph-based substructure pattern mining을 위한 알고리즘이라는 결과가 자주 나타난다.
쉽게 말하자면 여러 개의 graph에서 공통으로 자주 나타나는 subgraph를 찾아내는 알고리즘이다. 이때 vertex와 edge가 모두 label이 있는 그래프를 이용하며 edge extension 방식이다.
이 알고리즘에서 중요하게 쓰이는 개념은 다음과 같다.
DFS tree
DFS code
DFS lexicographic order
minimum DFS code
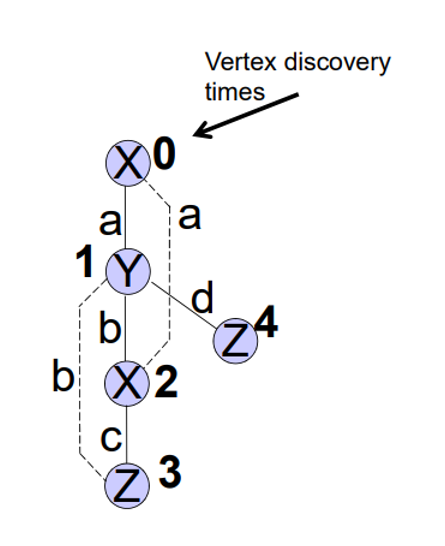
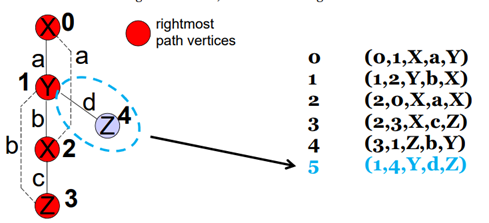
이것은 DFS 방식을 통해 만들어지는 DFS tree이다. 이 그림에서 숫자는 DFS 방식으로 진행할 때 발견되는 순서대로 붙게 된다. 여기서 알아야 하는 개념이 right-most path인데 이 개념을 알기 위해 우선 시작 vertex와 right-most vertex를 알아야한다.
- 시작 vertex : V0
- right-most vertex : Vn(위 그림에서는 V4)
right-most vertex는 V0과 Vn을 이어주는 가장 짧은 path이다.
(위 그림에서는 V0-V1-V4)
이 DFS tree를 표현하기 위해 나온 개념이 DFS code이다.

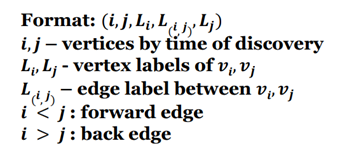
위 그래프에 대한 DFS code는 위과 같다.
DFS code는 서로 다른 두 vertex를 연결하는 edge를 표현하는데 이를 보는 방법은 예를 들어 설명하겠다.
예를 들어 위 표에서 첫번째 줄은
"X label을 가진 V0"과 "Y label을 가진 V1"을 연결하는 "a label을 가진 edge"를 표현한 것이다.
또한 DFS code에서 알아야하는 개념으로 Format:(i,j,Li,L(i,j),Lj)에서
i < j인 경우: forward edge(그래프에서 진한 선)
i > j인 경우: backward edge(그래프에서 점선)
가 있다.
이것은 추후에 필요한 개념이니 일단 알아두도록 하자.
또한 DFS code에서 edge들의 순서는 아래와 같은 규칙에 의해 결정된다.
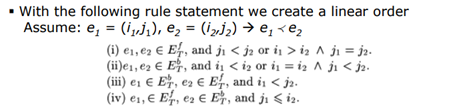
이러한 방식으로 DFS code를 생성할 때 같은 그래프일지라도 시작vertex에 따라 다른 DFS code가 생성될 것이다. 이러한 여러 개의 DFS code를 하나로 정의하기 위해 DFS lexicographic order와 minimum DFS code라는 개념이 나온다.
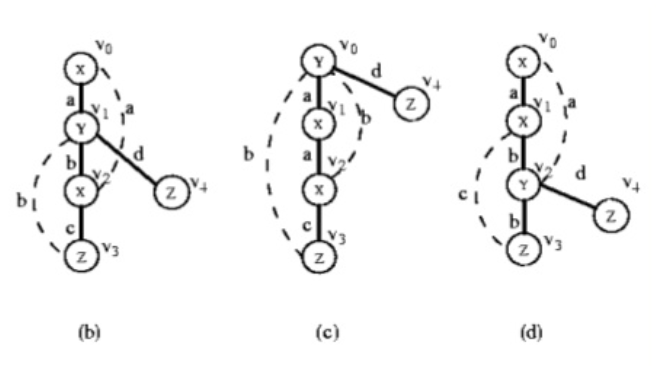

사전적인 순서를 통해 제일 먼저 나오는 DFS code를 minimum DFS code라고 한다.
(B) (0, 1, x, y, a)
(C) (0, 1, y, x, a)
(D) (0, 1, x, x, a)
세번째 값에 의해서 (B,D < C)
네번째 값에 의해서 (D < B)
따라서 (D < B < C)가 되며 위 그림에서 (D)가 minimum DFS code이다. 그리고 minimum DFS code가 아닌 DFS code는 제거하도록 한다.

이러한 Theorem을 통해 graph pattern mining에서 발생하는 isomorphic 문제를 해결할 수 있다.
gSpan은 앞서 말했듯 edge extension 방식인데 이는 forward edge와 backward edge에 따라 방법이 다르다.
forward edge extension은 right-most path에서 edge를 추가하는 방식이다.
기존의 right-most path가 (V0-V1-V2-V3)이었으며 이 위의 어느 vertex에서든 forward edge extension이 가능하다.
backward edge extension은 rigth-most vertex에서 edge를 추가하는 방식이다.
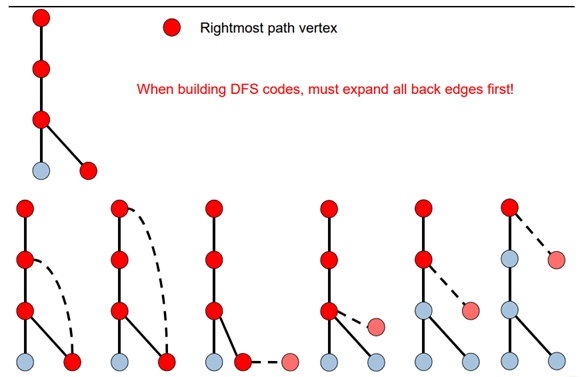
각각의 그래프에서 가장 오른쪽에 있는 빨간색 vertex가 right-most vertex이다. 이 vertex에서 backward edge extension이 가능하다.
위의 방식으로 edge를 extension하며 minimum DFS code가 아닌 경우, min_support 값보다 작은 support 값을 가진 경우 제거를 하며 진행한다.
전체적인 흐름은 아래 그림을 보면 알 수 있다.
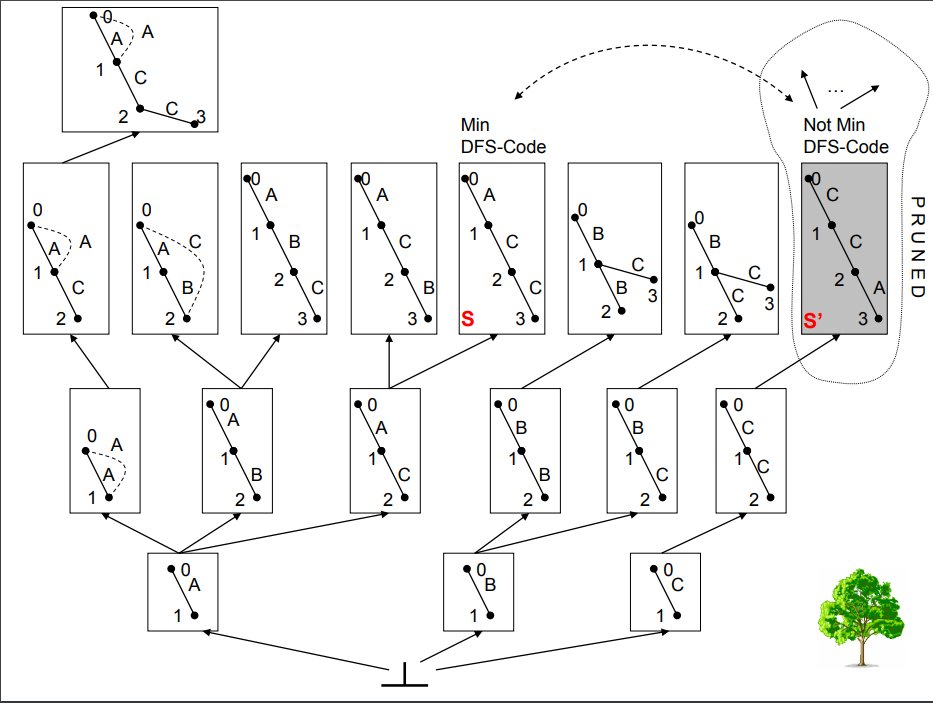
gSpan 알고리즘은 아래와 같다.


참고
https://www.slideshare.net/SadikMussah/gspan-algorithm
https://www.cs.helsinki.fi/u/langohr/graphmining/slides/chp2a.pdf
https://hpi.de/fileadmin/user_upload/fachgebiete/mueller/courses/graphmining/GraphMining-04-FrequentSubgraph.pdf
https://www.csc2.ncsu.edu/faculty/nfsamato/practical-graph-mining-with-R/slides/pdf/Frequent_Subgraph_Mining.pdf
https://www.ke.tu-darmstadt.de/lehre/archiv/ws0809/ml-sem/slides/Yingting_Fan.pdf
