
1.CRUD
- 데이터베이스에서 데이터를 추출하고 조작하는 데에 사용하는 데이터 처리 언어
| 이름 | 조작 | SQL |
|---|---|---|
| Create | 생성 | insert |
| Read | 읽기 | select |
| Update | 갱신 | update |
| Delete | 삭제 | delete |
1-1.테이블 생성하기 create
CREATE TABLE 테이블명 (
열명1 데이터타입1 제약조건1,
열명2 데이터타입2 제약조건2,
...
제약조건N
);1-2.데이터 삽입하기 insert
INSERT INTO users (name, email, age) VALUES ('John Doe', 'john.doe@example.com', 28);1-3.데이터 조회하기 select
SELECT * FROM users;1-4.데이터 수정하기 update
UPDATE users SET age = 29 WHERE name = 'John Doe';1-5.데이터 삭제하기 delete
DELETE FROM users WHERE name = 'John Doe';2.여러가지 Join
2-1.Inner Join
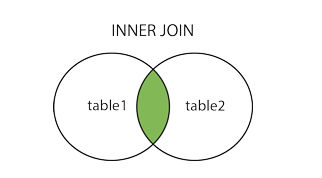
select
column_name
from table1 inner join table2 ON table1.column_name = table2.column_name;select
가져올컬럼1,
가져올컬럼2,
...
from 겹칠테이블1 inner join 겹칠테이블2 on 테이블1의공통컬럼 = 테이블2의공통컬럼2-2.Full Outer Join (Full Join)
- 일치하는 항목이 없더라도 두 테이블 모두에서 모든 레코드를 선택
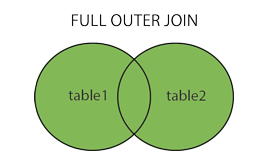
select
column_name
from table1 full outer join table2 ON table1.column_name = table2.column_name;select
가져올컬럼1,
가져올컬럼2,
...
from 합칠테이블1 full outer join 합칠테이블2 on 테이블1의공통컬럼 = 테이블2의공통컬럼3.데이터 그룹화
- 동일한 값을 가진 행을 요약 행으로 그룹화
- 집합을 그룹화하기 위해 Group by 집계 함수와 함께 자주 사용
COUNT(),MAX(),MIN(),SUM(),AVG()
| 집계 함수 | 설명 | 비고 |
|---|---|---|
| COUNT | 행의 개수 | 컬럼의 값이 NULL인 경우 제외 |
| SUM | 합계 | |
| AVG | 평균 | 컬럼의 값이 NULL인 경우 제외 |
| MAX | 최댓값 | |
| MIN | 최솟값 | |
| STDEV | 표준편차 | |
| VAR | 분산 | |
| STRING_AGG | 컬럼 문자열 합치기 | 컬럼의 값이 NULL인 경우 제외 |
- SELECT에서 집계 함수를 제외한 칼럼을 GROUP BY에 기술
3-1.Group by
select
column_1,
column_2,
...,
집계함수(column_3)
from
table_name
group by
column_1,
column_2,
...;select
가져올컬럼1,
가져올컬럼2,
...,
집계함수(집계함수를적용할컬럼)
from
그룹으로묶을컬럼의그룹
group by
집계함수제외한컬럼1,
집계함수제외한컬럼2,
order by
정렬할컬럼;3-2.Group by HAVING
- 집계 함수의 결과를 조건절에 사용하고 싶은 경우 HAVING 절을 사용
- HAVING 절에 일반 칼럼을 조건으로 부여할 수 있지만, 일반 칼럼은 WHERE 절에서 조건을 부여하는 것이 좋음
selet
가져올컬럼1,
...,
집계함수(집계함수를적용할컬럼)
from
그룹으로묶을컬럼의그룹
group by 집계함수제와한컬럼1 having 조건절4.중복 행 제거
4-1.DISTINCT
- 중복된 행을 제거하고 한 번만 표시하고 결과가 오름차순으로 정렬
- SELECT에 없는 컬럼으로 정렬을 할 수 없음 (order by로 정렬)
select distinct
컬럼1,
컬럼2,
...
from 테이블
where 조건--order by를 사용해 중복 제거 후 정렬 변경--
select distinct
가져올컬럼1,
가져올컬럼2,
...
from 테이블
where 조건
order by SELECT에있는정렬할컬럼4-2.Group by
- 조회된 결과를 임의로 정렬을 변경
- SELECT에 없는 다른 컬럼으로 정렬이 필요할 경우 사용
--Group by로 중복 제거--
select
가져올컬럼1,
가져올컬럼2,
...,
집계함수(집계함수를적용할컬럼)
from
그룹으로묶을컬럼의그룹
group by
집계함수제외한컬럼1,
집계함수제외한컬럼2,--SELECT에 없는 컬럼으로 정렬--
select
가져올컬럼1,
가져올컬럼2,
...,
집계함수(집계함수를적용할컬럼)
from
그룹으로묶을컬럼의그룹
order by
SELECT에있는정렬할컬럼,
SELECT에없는정렬할컬럼,
기록으로 흔적을 남기는 것을 좋아합니다