이 글은 "파이썬으로 살펴보는 아키텍쳐 패턴, 해리 퍼시벌 그리고 밥 그래고리" 을 읽고
책의 내용을 참고하여, Django에 해당 구조를 적용한 내용입니다.
아래 코드의 최종본은 Git Repo를 확인해주세요
1. 기존 구조 설명
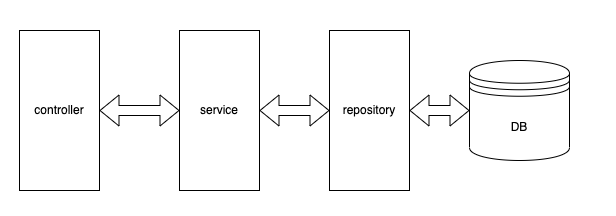
가장 보편적인 계층 구조로, controller, service, repository 레이어는 자신의 하위 레벨의 레이어와 통신하는 구조이다.
- contorller:
http 통신을 책임진다. request를 받고, 서비스 로직을 호출하여 서비스 로직을 실행한 결과를 response 한다. exception이 발생했을 때 error에 관한 response를 해준다 - service:
비지니스 로직이 담겨있다. repository 를 호출하여 DB에 있는 값을 가져오거나 조작한다. 외부 API를 사용할 경우 서비스 레이어에서 호출한다. (구현체는 provider class 등으로 분리한다.) - repository:
DB와의 통신을 책임진다
2. 문제점과 해결방법
문제의 원인은, service 레이어가 repository레이어에 의존성을 갖고 있다는 것이다.
아래 코드1은 repository 레이어에 의존성을 띄고 있는 service 레이어의 모습이다.
from board.repository import post_repo
from custom_exception import NotAllowedToUpdateError
class BoardService:
def update_post(self, post_id: int, user_id: int, update_content: str):
# 해당 유저가 작성자 인지 확인
post = post_repo.get_by_id(post_id)
if post["user"] != user_id:
raise NotAllowedToUpdateError
return post_repo.update(post_id=post_id, data={"content": update_content})
board_service = BoardService()
이는 테스트 코드 작성에서도 문제를 야기한다.
예를 들어, 어떤 게시글을 수정하려고 할 때, 해당 글의 작성자가 아닌 경우 에러를 발생시키는 상황을 테스트 한다고 하자. 그렇다면, 우선 아래와 같은 조건을 충족시킨 상태에서 테스트가 진행되어야 한다.
조건 1. 글을 작성한 유저1, 글을 작성하지 않은 유저2가 있어야함
조건 2. 유저1이 작성한 글이 존재해야함
아래의 코드2를 보자, 실제 코드에서도 사전에 DB 세팅을 위한 어떠한 방법도 취하지 않고 있다.
from board.service import board_service
import pytest
from django.conf import settings
@pytest.fixture(scope="session")
def django_db_setup():
settings.DATABASES
@pytest.mark.django_db()
def test_update_non_exist_post():
sut = board_service.update_post(1, 1, "updated content")
isinstance(sut, dict)
service 레이어가 repository 레이어에 의존적이기 때문에, 위의 테스트를 진행 시키기 위해서는 테스트 DB에 1, 2 번 조건을 충족시키기 위한 값이 세팅 되어야 한다. 이런 방법은 실제로는 불가능할 수도 있고 (테스트 DB를 혼자 사용하는게 아니기 때문에) 또는 가능하더라도 많은 시간이 소모된다.
따라서, service 레이어와 repository 레이어 사이의 의존성을 끊고, set 또는 list 등의 메모리로 데이터를 관리하는 추상화 된 가짜 repository를 만들어 사용할 것이다.
3. 의존성
우선 의존성이 무엇인지 부터 알아보자.
의존성은 꼭 임포트나 호출만을 뜻하지 않는다
대신 한 모듈이 다른 모듈을 필요로 하거나, 안다 라는 좀더 일반적인 생각이 의존성이다
출처: 파이썬으로 살펴보는 아키텍쳐 패턴 (31page), 해리퍼시벌 그리고 밥 그레고리
즉, 단순히 호출이나 import가 아니라 어떠한 모듈이 다른 모듈이 존재한다는 것을 알 때 의존성을 갖고 있다고 할 수 있다.
위에서 봤던 코드1을 다시 보자
from board.repository import post_repo
from custom_exception import NotAllowedToUpdateError
class BoardService:
def update_post(self, post_id: int, user_id: int, update_content: str):
# 해당 유저가 작성자 인지 확인
post = post_repo.get_by_id(post_id)
if post["user"] != user_id:
raise NotAllowedToUpdateError
return post_repo.update(post_id=post_id, data={"content": update_content})
board_service = BoardService()
service 레이어가 repository 레이어의 repository를 import 해서 사용하고 있다.
BoardService는 post_repo가 존재하는 것을 알고 있다.
따라서 BoardService는 post_repo에 의존성을 가지고 있다.
4.의존성 역전 원칙
로버트 마틴의 객체 지향 설계 5대 법칙인 SOLID가 있다.
그 중, D가 DIP(dependency inversion principle)로 의존성 역전 원칙이다.
의존성 역전 원칙은 아래와 같다.
- 고수준 모듈은 저수준 모듈에 의존해서는 안 된다. 두 모듈 모두 추상화에 의존해야 한다.
- 추상화는 세부 사항에 의존해서는 안 된다. 반대로 세부 사항은 추상화에 의존해야 한다.
1번 법칙은 이미 어느정도는 지켜지고 있다고 할 수 있다. DB를 추상화한 repository를 사용하고 있기 떄문에 service에서는 django model이 존재하는 것을 알지도 못하고, 알 필요도 없다.
여기서 DB의 종류가 mysql이 아니라 mongoDB로 바뀐다고 해도, service는 저장소를 알 필요가 없기 때문에 repository만 바꾸면 된다.
2번 법칙은 이해하기가 생각보다 어렵다.
우선, repository와 service 레이어의 의존성을 끊어낸 뒤, 다시 한 번 살펴보자.
5. Service 레이어와 Repository 레이어 의존성 끊어내기
from board.repository import post_repo
from custom_exception import NotAllowedToUpdateError
class BoardService:
def update_post(self, post_id: int, user_id: int, update_content: str):
# 해당 유저가 작성자 인지 확인
post = post_repo.get_by_id(post_id)
if post["user"] != user_id:
raise NotAllowedToUpdateError
return post_repo.update(post_id=post_id, data={"content": update_content})
board_service = BoardService()
위의 BoardService를 보면 post_repo를 import해서 그대로 사용하고 있다.
이 BoardService의 생성자를 수정하여 의존성을 끊어보자
class BoardService:
def __init__(self, repo: AbstractRepo) -> None:
self.repo = repo
def update_post(self, post_id: int, user_id: int, update_content: str):
post = self.repo.get_by_id(post_id)
if post == None:
raise DataNotFoundError
# 해당 유저가 작성자 인지 확인
if post["user"] != user_id:
raise NotAllowedToUpdateError
return self.repo.update(data_id=post_id, data={"content": update_content})
board_service = BoardService(repo=post_repo)
자, 이제 BoardService는 post_repo의 존재를 알 필요가 없다.
대신, 저장소와 통신하는 기능을 가지고 있는 추상화 된 repository에 대한 의존성을 갖는다.
AbstractRepo의 코드를 살펴보자
from typing import Union
from django.db import models
from rest_framework import serializers
class BaseModel(models.Model):
using = "improved_test_code"
id = models.AutoField(primary_key=True)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
class Meta:
abstract = True
managed = False
class AbstractRepo:
def __init__(self, model: BaseModel, serializer: serializers) -> None:
self.model = model
self.serializer = serializer
class BaseRepo(AbstractRepo):
def create(self, data: dict) -> dict:
serializer = self.serializer(data=data)
serializer.is_valid(raise_exception=True)
serializer.save()
return serializer.data
def get_by_id(self, id: int) -> Union[dict, None]:
try:
return self.serializer(self.model.objects.get(id=id)).data
except self.model.DoesNotExist:
return None
def update(self, data_id: int, data: dict):
update_target = self.model.objects.get(id=data_id)
serializer = self.serializer(update_target, data=data, partial=True)
serializer.is_valid(raise_exception=True)
serializer.save()
return serializer.data
class FakeBaseRepo(AbstractRepo):
def __init__(self, model: BaseModel) -> None:
self.in_memory_db = dict()
self.model = model
def create(self, data: dict) -> dict:
self.in_memory_db[str(data["id"])] = data
return data
def get_by_id(self, id: int) -> Union[dict, None]:
data_id_str = str(id)
return self.in_memory_db.get(data_id_str, None)
def update(self, data_id: int, data: dict):
data_id_str = str(data_id)
if data_id_str:
raise self.model.DoesNotExist
update_target = self.get_by_id(data_id)
for column_name in data.keys():
self.in_memory_db[data_id_str][column_name] = update_target[column_name]
return update_target
BaseRepo와 FakeBaseRepo는 모두 AbstractRepo를 상송하여 만들었다.
두 repo는 모두 model과 serializer를 갖는다. 그러나 BaseRepo는 serializer.save 함수를 이용해, 실제로 DB와 통신하는 반면, FakeBaseRepo는 딕셔너리를 이용해서, 메모리에 가상의 DB를 만들고 이 딕셔너리의 값을 조회하거나 수정한다.
자 이제 BoardService는 post_repo라는 repository 레이어에 의존적이지 않고, AbstractRepo라는 추상화된 repository에 의존적이다. BoardService는 추상화에 의존하고 있다.
6. 개선된 구조로 test code 개선하기
기존의 코드는 실제 DB를 사용하고 있었다.
from board.service import board_service
import pytest
from django.conf import settings
@pytest.fixture(scope="session")
def django_db_setup():
settings.DATABASES
@pytest.mark.django_db()
def test_update_non_exist_post():
sut = board_service.update_post(1, 1, "updated content")
isinstance(sut, dict)그러나 이제 BoardService가 추상화된 repo에 의존하고 있으므로
fakeRepo를 이용하여 테스트 해볼 수 있다
import pytest
from board.service import BoardService
from improved_test_code.repository import FakeBaseRepo
from board.models import Post
from user.models import User as CustomUser
fake_post_repo = FakeBaseRepo(model=Post)
fake_user_repo = FakeBaseRepo(model=CustomUser)
board_service = BoardService(repo=fake_post_repo)
@pytest.fixture(scope="session")
def set_up_fake_db():
fake_post_repo.in_memory_db = dict()
fake_user_repo.in_memory_db = dict()
fake_users = [
{
"id": 1,
"name": "user1",
"email": "test@test.com",
"created_at": "2022-09-13 13:12:00",
"updated_at": "2022-09-13 13:12:00",
},
{
"id": 2,
"name": "user2",
"email": "test2@test.com",
"created_at": "2022-09-13 13:12:00",
"updated_at": "2022-09-13 13:12:00",
},
]
for user in fake_users:
fake_user_repo.create(user)
fake_post_repo.create(
{
"id": 1,
"user": 1,
"board": 1,
"content": "created context",
"created_at": "2022-09-13 13:12:00",
"updated_at": "2022-09-13 13:12:00",
}
)
def test_update_non_exist_post(set_up_fake_db):
with pytest.raises(Post.DoesNotExist):
sut = board_service.update_post(
post_id=2, user_id=1, update_content="updated content"
)
앞의 준비 과정의 코드가 다소 많기는 하지만, 이런 코드를 따로 분리하여 매 테스트 마다 일정한 환경을 구축하게 할 수 있을 것이다. 중요한 것은 service와 repository 사이의 의존성을 끊었다는 것이다. 이제 DB에 별도의 환경설정 없이 테스트 코드를 작성 할 수 있다.
