
크롤링이란?
'크롤링'은 웹 상에 존재하는 자료들을 특정한 방식을 사용하여 데이터들을 수집함을 의미한다. 중요한 점은 웹 상의 정보에는 여러가지 종류가 있다라는 점이다.
Lib : Beautiful Soup, requests, csv
나의 경우에는 Python을 이용한 크롤링을 진행하기 때문에 가장 많은 분들이 사용하는 Beautiful Soup 라이브러리를 이용한다.
만약 Java를 이용한다면 자바 버전인 JSoup, 브라우저를 이용한다면 Selenium을 사용하는 것이 일반적이라고 알려져 있다.
오늘은 멜론 차트를 통해 정적, 동적 두가지의 크롤링을 실습해보려한다.
정적 크롤링 실습
데이터 추출을 위해 아래와 같이 각각의 선택자를 확인해야한다.
본인은 차트 데이터가 필요하기에 아래와 같이 선택했다.
선택된 부분을 Copy selector 하게 되면 #frm > div > table > tbody 와 같이 추출할 수 있게 된다.
웹 페이지 요청을 보낸다.
BeautifulSoup을 사용하여 HTML을 파싱한다.
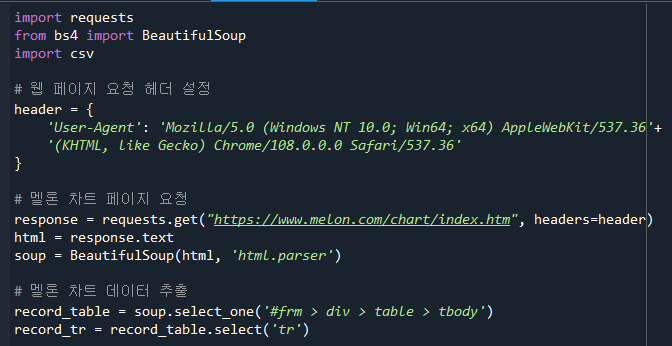
멜론 차트 데이터를 추출한다.
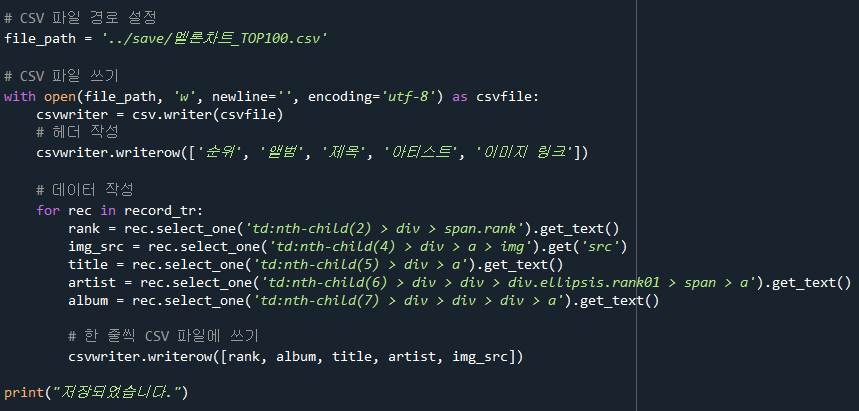
CSV 파일을 열고 데이터를 작성한다.
차트 데이터를 반복하여 CSV 파일에 쓴다.
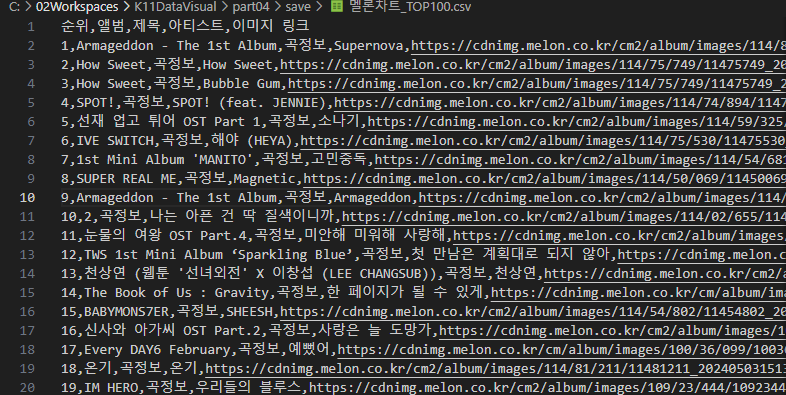
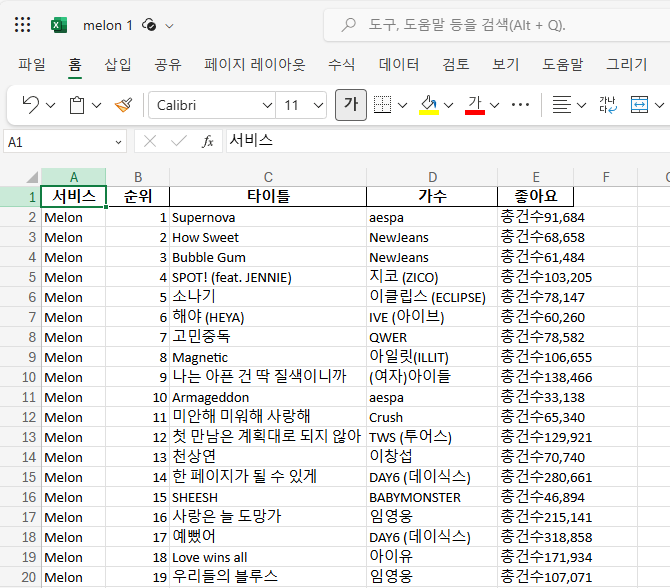
결과는 아래와 같이 저장된다.
동적 크롤링 실습
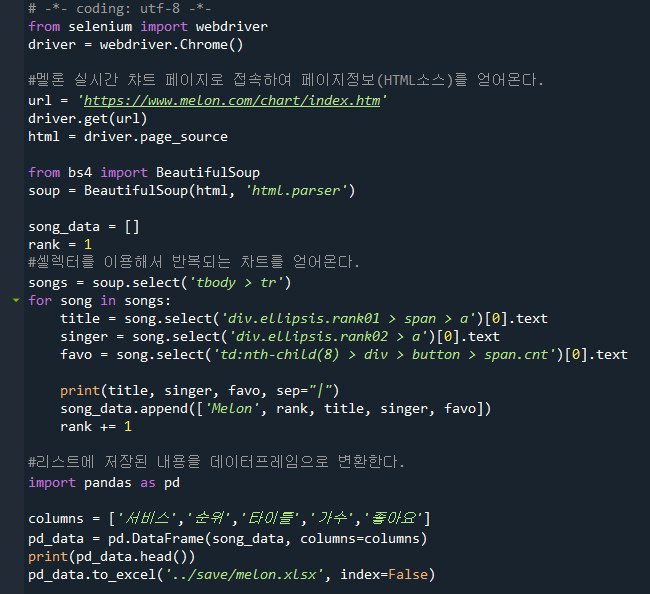
아래는 selenium 라이브러리를 활용한 동적 크롤링이다. 정적 크롤링에서는 'requests'모듈을
사용하여 HTTP 요청을 보내고, 서버로 부터 HTML 코드를 직접 받아왔다면, 동적 크롤링에서는
selenium을 사용하여 실제 웹 브라우저를 제어하여 웹 페이지에 접속하고, javaScript를 포함한
모든 콘텐츠가 로드된 후의 HTML 소스를 가져오는 차이점이 있다.
두 방법 모두 웹 페이지에서 데이터를 추출할 수 있다. 어떤 방법을 사용할지는 웹 페이지의 특성과
크롤링 요구 사항에 따라 달라진다. JavaScript로 동적으로 생성된 콘텐츠를 가져와야 할 경우
selenium을 사용한 동적 크롤링이 필요할 것 이고, 그렇지 않다면 정적 크롤링으로 충분할 수 있다.
마무리
오늘은 정적, 동적 크롤링을 실습하며, 공부해보았다. 활용법을 확실하게 알고 사용해야 할
타이밍에 알맞게 사용하는 역량이 필요하다는 것을 다시 한번 상기할 수 있는 시간이였다.
ps.블로그에 정리를 제때 잘하자 몰아서 하지말구..
