
이 글은 https://bbiguduk.gitbook.io/swift 에 나오는 스위프트 문법을 공부하면서 새롭게 알게 된 지식들을 정리한 포스팅입니다.
- Swift의
String타입은Foundation의NSString클래스와 연결되어 있다.Foundation을import하면 캐스팅 없이String타입으로NSString메서드 사용 가능하다.
문자열 리터럴 (String Literal)
- 여러 줄을 입력할 때는
“””을 사용한다. (다음 줄부터 입력 시작)“””안에서 줄바꿈을 하되 적용하지 않을 때는\를 사용한다.- 공통 들여쓰기는 무시되고, 특정 줄에만 들여쓰기가 되어 있을 경우 적용된다.
- 특별한 처리 없이 문자열 내에서
“사용이 가능하다.
- 문자열 리터럴에 포함될 수 있는 특수문자
- 이스케이프 된 문자
\0(null 문자),\\(역슬래시),\"(쌍따옴표) 와\'(홑따옴표) 등 \\u{n}로 쓰여진 임의의 유니코드 스칼라 값. 여기서 n 은 1-8 자리의 16진수
- 이스케이프 된 문자
빈 문자열 초기화 (Initializing an Empty String)
- 빈
String값을 만들 때는 빈 문자열 리터럴을 할당하거나String()초기화 함수를 사용한다. String값은Bool타입 프로퍼티인isEmpty로 비어있는지 확인할 수 있다.
문자열은 값 타입이다 (Strings Are Value Types)
String타입은 값 타입(value type)이다.- 즉, 함수나 변수에 전달되거나 할당될 때 원본이 아닌 복사본이 만들어져 사용된다.
문자 작업 (Working with Characters)
- 하나의 문자인 문자열 리터럴은
Character타입의 상수 변수로 할당될 수 있다.String초기화 함수로Character타입의 배열을String타입의 값으로 바꿀 수 있다.
let animals: [Character] = ["🐶", "🐱", "🐭", "🐠", "🐦"]
let animalString = String(animals) // 🐶🐱🐭🐠🐦문자열과 문자 연결 (Concatenating Strings and Characters)
String의append()메서드를 사용하여String이나Character값을 추가할 수도 있다.Character타입은 하나의 문자만 가능하기 때문에 추가 불가능하다.
let dragon: Character = "🐲" // String 타입도 가능하다
animalString.append(dragon) // 🐶🐱🐭🐠🐦🐲유니코드 (Unicode)
- 유니코드는 인코딩, 표기, 기타 쓰기 시스템에서 텍스트 프로세싱을 위해 채택하는 국제 표준이다.
- Swift의
String타입은 21-bit 유니코드 스칼라 값(ex:U+0061 == “a”)으로부터 생성된다. - 확장된 문자소 클러스터 (Extended Grapheme Clusters)
- Swift의 Character 타입은 EGC로 표기되는데, 이는 결합된 하나 이상의 유니코드 스칼라 값이다.
- 한글처럼 분해된 시퀀스(스칼라 쌍)를 단일 시퀀스로 표시해준다.
let eAcute: Character = "\u{E9}" // é
let combinedEAcute: Character = "\u{65}\u{301}" // e + ́
print(eAcute, combinedEAcute) // é é
let precomposed: Character = "\u{D55C}" // 한
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ㅎ + ㅏ + ㄴ
print(precomposed, decomposed) // 한 한문자 카운팅 (Counting Characters)
- EGC에서 결합된 유니코드 스칼라는
String의count프로퍼티에 영향을 주지 않는다. (ex: 한글)- 따라서 Swift의
Character는String안에서 동일한 양의 메모리를 차지하지 않는다. String의count프로퍼티는 전체 유니코드 스칼라 값을 순회하며 EGC를 계산하여 결정된다.- 16-bit 코드 유닛(
UTF-16)으로 인코딩하는NSString의length프로퍼티와 값이 다를 수 있다.
- 따라서 Swift의
var word = "cafe"
print(word, word.count) // cafe 4
word += "\u{301}"
print(word, word.count) // café 4문자열 접근과 수정 (Accessing and Modifying a String)
- 문자열 인덱스 (String Indices)
String은 각Character의 위치에 해당하는index type의String.Index프로퍼티를 가진다.Character가 EGC이기 때문에 저장할 메모리의 양이 다르므로, 특정 위치의 문자의 인덱스를 확인하려면 앞에 위치한 문자들의 유니코드 스칼라 값을 순차적으로 계산해야 한다. → 정수 인덱스 불가.startIndex:String의 첫번째 문자 위치 /endIndex:String의 마지막 문자 다음 위치.- 빈 문자열일 경우
startIndex와endIndex가 같다. (nil없음) String의index(_:offsetBy:)메서드로 특정 위치의 인덱스에 접근할 수 있다. (-도 가능)String의indices프로퍼티를 사용하여 각 문자의 인덱스가 담긴 배열에 접근할 수 있다.- 모든
Collection타입들(Array,Dictionary,Set)에서도 동일하게 사용 가능하다.
let greeting = "안녕하세요!"
greeting[greeting.startIndex] // 안
// greeting[greeting.endIndex]
// 마지막 문자 다음 위치여서 에러
greeting[greeting.index(after: greeting.startIndex)] // 녕
// greeting[greeting.index(before: greeting.startIndex)]
// 첫 문자 전 위치여서 에러
greeting[greeting.index(before: greeting.endIndex)] // !
// greeting[greeting.index(after: greeting.endIndex)]
// 마지막 문자 다음 다음 위치여서 에러
greeting[greeting.index(greeting.startIndex, offsetBy: 5)] // !
// greeting[greeting.index(greeting.startIndex, offsetBy: 6)]
// 마지막 문자 다음 위치여서 에러
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "") // 안 녕 하 세 요 !
}- 삽입과 삭제 (Inserting and Removing)
insert(_:at:)/remove(at:): 문자 하나를 삽입/삭제한다.insert(contentsOf:at:)/removeSubrange(_:): 문자열/특정 범위 부분을 삽입/삭제한다.- 역시 다른
Collection타입들도 사용가능한 메서드들이다.
greeting.insert("?", at: greeting.endIndex) // 안녕하세요!?
greeting.insert(contentsOf: " 주인님!", at: greeting.endIndex) // 안녕하세요!? 주인님!
greeting.remove(at: greeting.index(greeting.startIndex, offsetBy: 6))
// 안녕하세요! 주인님!
greeting.removeSubrange(greeting.index(greeting.endIndex, offsetBy: -5)..<greeting.endIndex)
// 안녕하세요!부분 문자열 (Substrings)
- 서브 스크립트나
prefix(_:)와 같은 메서드로 추출한 부분 문자열은Substring타입 인스턴스가 된다.
(이때 서브 스크립트란str[str.startIndex]등의 대괄호([])를 써서 인덱스에 접근하는 방식을 말함)
-SubSting도StringProtocol을 준수하기 때문에String의 거의 모든 메서드를 사용할 수 있다.
-SubString은 원래 문자열을 저장하는데 사용된 메모리의 일부를 재사용한다.
- 즉 부분 문자열이 사용되는 동안 원본 문자열의 메모리가 유지되어야 하므로 장기저장에 적합하지 않다.```swift let greeting = "Hello, World!" let beginning = greeting[..<(greeting.firstIndex(of: ",") ?? greeting.endIndex)] let newString = String(beginning) beginning[...beginning.index(after: beginning.startIndex)] // He // SubString에서도 SubString을 추출해 낼 수 있다. ``` 
문자열 비교 (Comparing Strings)
- 문자열과 문자 일치 (String and Character Equality)
- 두 개의
String혹은Character값의 확장된 문자소 클러스터가 동일할 경우 값이 같다고 한다. - 즉 서로 다른 유니코드 스칼라로 구성되어도, 언어의 의미와 모양이 같으면 동일하다.
- 하지만 모양이 같아도 언어적 의미가 다른 경우(스칼라도 다름)도 있다. (영어의 “A”와 러시아어 “A”)
- 두 개의
let han = "\u{D55C}" // 한
let hanCombined = "\u{1112}\u{1161}\u{11AB}" // ㅎ + ㅏ + ㄴ
print(han == hanCombined) // true- 접두사와 접미사 동등성 (Prefix and Suffix Equality)
hasPrefix(_:)/hasSuffix(_:): 특정 접두사/접미사를 가지고 있는지 확인한다.
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
//...
]
var cnt = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1") {
// if scene.hasSuffix("Capulet's mansion") {
cnt += 1
}
}
print(cnt)문자열의 유니코드 표현 (Unicode Representationas of Strings)
- String이 다른 파일에 쓰여질 때 각 유니코드 스칼라는 유니코드 인코딩 형식 중 하나로 인코딩된다.
- Swift는
String의 프로퍼티로 세 가지 인코딩 형식 중 각각의 코드 유닛에 접근할 수 있다. utf8(UTF-8),utf16(UTF-16),unicodeScalars(UTF-32: 21-bit 유니코드 스칼라 값)
- Swift는
- UTF-8 표현 (UTF-8 Representation)
utf8: 이 프로퍼티를 통해String의 UTF-8 표현에 접근할 수 있다.String.UTF8View타입으로, 각 문자 바이트(8bit-코드유닛)에 대응하는UInt8값의 배열이다.- 아래에서 첫 3개 코드유닛은 UTF-8표현(=ACSII) 문자 D, o, g를 나타내며, 다음 3개 코드유닛은
‼의 3바이트 UTF-8표현이고, 다음 4개 코드유닛은🐶의 4바이트 UTF-8표현이다.
let dogString = "Dog‼🐶"
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
// 68 111 103 226 128 188 240 159 144 182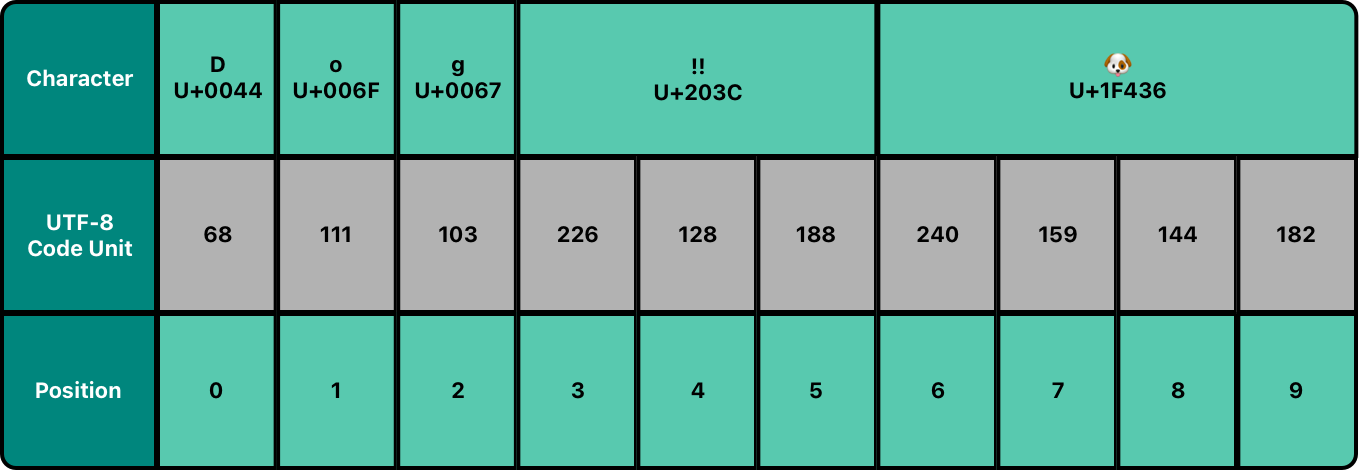
- UTF-16 표현 (UTF-16 Representation)
utf16: 이 프로퍼티를 통해String의 UTF-16 표현에 접근할 수 있다.String.UTF16View타입으로, 각 문자의 16bit-코드유닛에 대응하는UInt16값의 배열이다.- 아래에서 첫 3개는 UTF-16 코드유닛이지만 UTF-8표현과 같은 값을 가지는 문자 D, o, g를 나타내며, 다음 코드유닛은
‼의 유니코드 스칼라 값(U+203C)의 16진수 203C에 해당하는 값을 가지며 UTF-16에서 하나의 코드유닛으로 표현되고, 다음 2개의 코드유닛은🐶의 UTF-16 대리 쌍 표현이다.
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
// 68 111 103 8252 55357 56374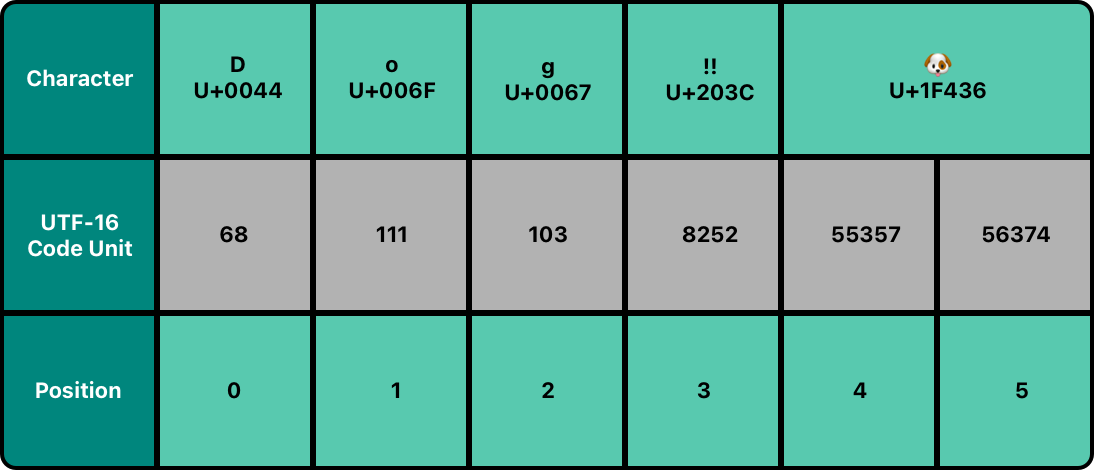
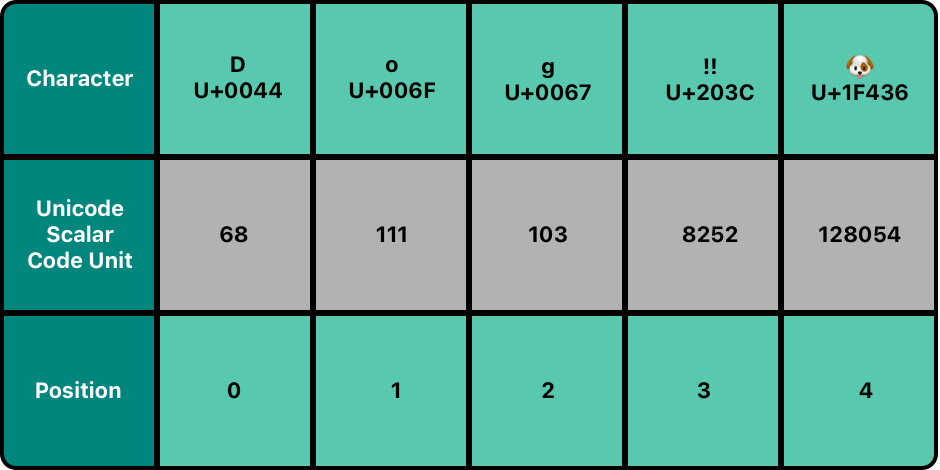
- 유니코드 스칼라 표현 (Unicode Scalar Representation)
-
unicodScalars: 이 프로퍼티를 통해String의 유니코드 스칼라 표현에 접근할 수 있다. -
UnicodeScalar타입의 모음인UnicodeScalarView타입으로,UnicodeScalar은 각 문자에 대응하는 스칼라의 21-bit 값인UInt32값을 반환하는value프로퍼티를 가지고 있다.-
💡 UTF-32인데 21-bit인 이유는, 유니코드 문자가 U+10FFFF까지 21bit로 전부 표현되기 때문.UnicodeScalar는Unicode.Scalar의typealias다.
-
-
아래에서 첫 3개
UnicodeScalar값은 D, o, g를 나타내며, 다음 코드유닛은‼의 유니코드 스칼라 값(U+203C)에 해당하는 십진수 값이며, 다음UnicodeScalar의value는🐶의 유니코드 스칼라 값(U+1F436)에 해당하는 십진수 값이다. -
value프로퍼티를 사용하지 않으면 각UnicodeScalar에 해당하는 문자를 확인할 수 있다.for scalar in dogString.unicodeScalars { print("\(scalar.value) ", terminator: "") } // 68 111 103 8252 128054 // scalar만 프린트하면: D o g ‼ 🐶
-

var yona = IOSDeveloper(stage: 0)