일본어의 반각, 전각
- 일본어는 같은 문자라도 반각과 전각의 구분이 존재
- 아스키코드에서는 이를 구분할 수 없지만 유니코드에서는 구분이 가능
- 유니코드에서는 각각의 문자에 대해 전각과 반각에 해당하는 코드 포인트를 지원하여, 텍스트 표시나 처리 시에 각각의 특성을 고려할 수 있음
문제의 시작
VBA에서
'******************************************************
' 全角を半角に変換
'******************************************************
Function ZenToHan(str As String) As String
Dim i As Integer
Dim result As String
result = ""
For i = 1 To Len(str)
Dim charCode As Integer
charCode = AscW(Mid(str, i, 1)) ' [AscW] : Unicode数値をわかる関数
' 全角文字の範囲 : [&HFF01] ‐ [&HFF5E]
If charCode >= &HFF01 And charCode <= &HFF5E Then
' <全角の範囲にあったら、半角に変える処理をする>
result = result & ChrW(charCode - &HFF00 + &H20)
' [charCode - &HFF00] :
' 全角文字のUnicodeコード値から[&HFF00]を引いた値。半角文字のUnicodeコード値との差。
' → [&H20]を加える : 差を補正し、半角文字のUnicodeコード値を得ます。
' → [ChrW] : Unicodeコード値を文字に変換し、結果文字列に追加します。
Else
' <全角の範囲にないと、何の処理もしない。>
result = result & Mid(str, i, 1)
End If
Next i
ZenToHan = result
End Function- 지금까지 vba 업무를 하면서 이 함수를 만들어서 문제 없이 잘 사용했다.
- AscW함수 (유니코드 포인트 반환) 를 이용해서 해당 글자가 전각 문자 범위 안에 들어있는지 판단 후, 그러하다면 해당 문자를 반각으로 변경하여 최종적으로 반각인 문자열을 반환하는 기능이다.
- 문제는 이 로직을 비쥬얼베이직에서 사용할 수 없었다는 것이다.
VB.Net에서
If charCode >= &HFF01 And charCode <= &HFF5E Then
' 로직 작성 (전각의 범위)
Else
' 로직작성 (전각 범위 이외)
End IfIf currentChar Like "[0-9A-Za-zア-ンヲ-ン゙゚]" Then
' 로직 작성 (반각의 범위)
Else
' 로직작성 (반각 범위 이외)
End If[&HFF01] ‐ [&HFF5E]와 같은 로직으로는 비쥬얼 베이직의 텍스트 박스에서 전각과 반각을 구분해서 카운팅하고 몇 가지 조건에 따른 스크롤바를 추가, 혹은 버튼의 활성화 등의 기능을 구현할 수 없었다.- 굉장히 당황해서 헤매다가, 정규표현식을 사용했더니 코드가 일단 작동하기 시작했다.
- 하지만 아니었다. 무언가 본질적인 문제점을 파악하지 않으면 무조건 잘못되는 부분이 있지 싶었다.
왜 이런일이 생겼을까
만약 문자열이 UTF-8 또는 다른 인코딩으로 인코딩되어 있다면, 직접적인 유니코드 코드 포인트 비교로는 제대로 작동하지 않을 수도 있다.
추측 1
- 현재 업무에서 MS Gothic체를 공통 폰트로 사용 중 -> 왜냐하면 MS Gothic은 문자와 숫자의 너비가 같도록 해주기 때문에 현재 업무에 있어 굉장히 활용도가 높음
- 그런데 MS Gothic체로 입력된 문자열은 윈도우 기반 시스템에서는 주로 CP932 또는 Shift_JIS와 같은 인코딩을 사용 (실제로 Shift_JIS 환경)
- 이 경우, 전각 문자의 유니코드 코드 포인트와 해당 문자열의 실제 코드 포인트는 일치하지 않을 수 있음.
추측 2
- 그럼 왜 VBA에서는 안정적으로 로직이 돌아갔는가
- 아마도 엑셀 VBA에서는 문자열 처리에 있어서 유니코드에 대한 지원이 비교적 잘 되어 있으며, 문자열 내의 문자들을 UTF-16 인코딩을 기준으로 다루기 때문에 문자 인코딩의 차이에 따른 문제가 적을 수 있음.
코드 1 : 유니코드 범위 설정
Function countChars(text As String) As Integer()
Dim zenkakuCnt As Integer
Dim hankakuCnt As Integer
zenkakuCnt = 0
hankakuCnt = 0
'''' 작동하지 않음 (전체적으로 문제)
For i As Integer = 1 To Len(text)
'If AscW(Mid(text, i, 1)) >= &HFF01 And AscW(Mid(text, i, 1)) <= &HFF5E Then
' zenkakuCnt += 1
'Else
' hankakuCnt += 1
'End If
Next
'''' 작동하지 않음 (잘 되는 줄 알았는데 가타카나를 반각으로 인식)
For i As Integer = 1 To Len(text)
'Dim currChar As String
'currChar = Mid(text, i, 1)
'''If currChar Like "[0-9A-Za-zア-ンヲ-ン゙゚]" Then
'If currChar Like "[0-9A-Za-zア-ン¥HFF65-\HFF9F]" Then
' hankakuCnt += 1
'Else
' zenkakuCnt += 1
'End If
Next
'''' 작동함 (IsZenkaku 불린 함수를 이용)
For i As Integer = 1 To Len(text)
Dim currChar As String
Dim isZen As Boolean
currChar = Mid(text, i, 1)
isZen = IsZenkaku(currChar)
If isZen Then
zenkakuCnt += 1
Else
hankakuCnt += 1
End If
Next
Dim result(0 To 1) As Integer
result(0) = zenkakuCnt
result(1) = hankakuCnt
countChars = result
End Function
''' 작동하는 로직
Function IsZenkaku(oneChar As String) As Boolean
Dim charCode As Integer
oneChar = Mid(oneChar, 1, 1)
charCode = AscW(oneChar)
If (charCode >= &HFF61 And charCode <= &HFF9F) Or
(charCode >= &H3040 And charCode <= &H309F) Or
(charCode >= &H30A0 And charCode <= &H30FF) Or
(charCode >= &HFF00 And charCode <= &HFFEF) Then
IsZenkaku = True ' 전각
Else
IsZenkaku = False ' 반각
End If
End Function
- (charCode >= &HFF61 And charCode <= &HFF9F): 전각 가타카나의 유니코드 범위
- (charCode >= &H3040 And charCode <= &H309F): 히라가나의 유니코드 범위
- (charCode >= &H30A0 And charCode <= &H30FF): 가타카나의 유니코드 범위
- (charCode >= &HFF00 And charCode <= &HFFEF): 특수문자의 유니코드 범위
문제점
- 범위를 설정했음에도 특정한 특수문자를 전각이라고 인식하지 못함.
- 예를 들면 별 모양(★)
코드 2 : 내장함수 이용
- 그냥 바이트 수가 1보다 크면 전각이라고 계산하면 안 됨? 이라는 생각에 다다름. 너무 귀찮다.
- 그렇다면 내장함수의 힘을 빌려 구현 가능.
- 결국 지금 전각 반각을 구분하는 이유는 데이터 베이스에 자료가 어떻게 들어갈지 체크하기 위해서니까.
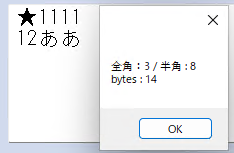
- 개행을 두 개의 반각이라고 인식했다는 가정 하에, 지금까지 중 가장 완벽하게 작동하는 코드였다.
Sub Button7_Click(sender As Object, E As EventArgs) Handles Button7.Click
Dim dialogPopupStr As String = ""
Dim result(0 To 1) As Integer
Dim totalLen As Long = 0
Dim zenLen As Integer = 0
Dim hanLen As Integer = 0
result = countChars(Me.txtBox.Text)
MessageBox.Show("全角:" & result(0) & " / 半角 : " & result(1) & vbCrLf & "bytes : " & Me.getByteCnt(Me.txtBox.Text))
zenLen = result(0)
hanLen = result(1)
'totalLen = (zenLen * 2) + hanLen
totalLen = Me.getByteCnt(Me.txtBox.Text)
'dialogPopupStr += "300字以内で作成してください。" & vbCrLf & "全角:" & zenLen & " 字" & vbCrLf & "半角:" & hanLen & " 字
'
dialogPopupStr += "600バイト以内で作成してください。(現在:" & totalLen & " bytes)" & vbCrLf & "【全角(2バイト)/半角)(1バイト)】" & vbCrLf & "全角:" & result(0) & " 字" & vbCrLf & "半角:" & result(1) & " 字"
If totalLen > 599 Then
Dim dialogPopup As DialogResult = MessageBox.Show(dialogPopupStr,
"確認",
MessageBoxButtons.OKCancel,
MessageBoxIcon.Exclamation,
MessageBoxDefaultButton.Button2)
End If
End Sub
Sub textBox_Change() Handles txtBox.TextChanged
'文字が599字以上になるとスクロールバー
makeScrollBar()
End Sub
Sub makeScrollBar()
Dim textLen As Long
Me.txtBox.MaxLength = 0 ’무한입력
textLen = getBytesCnt(txtBox.Text)
If textLen >= 599 Then
'Me.txtBox.Multiline = True
txtBox.ScrollBars = ScrollBars.Vertical
Else
txtBox.ScrollBars = ScrollBars.None
End If
End Sub
Function countChars(text As String) As Integer()
Dim zenkakuCnt As Integer
Dim hankakuCnt As Integer
zenkakuCnt = 0
hankakuCnt = 0
For i As Integer = 1 To Len(text)
Dim currChar As String
Dim isZen As Long
currChar = Mid(text, i, 1)
isZen = getByteCnt(currChar)
' 일괄적으로 1바이트를 초과하면 전각처리
If isZen > 1 Then
zenkakuCnt += 1
Else
hankakuCnt += 1
End If
Next
Dim result(0 To 1) As Integer
result(0) = zenkakuCnt
result(1) = hankakuCnt
countChars = result
End Function
' 바로 이 함수 !
Function getByteCnt(text As String, Optional encoding As String = "Shift_JIS") As Long
Dim bytes() As Byte
Select Case LCase(encoding)
Case "utf-8"
bytes = System.Text.Encoding.UTF8.GetBytes(text)
Case "shift-jis"
bytes = System.Text.Encoding.GetEncoding("Shift_JIS").GetBytes(text)
Case Else
bytes = System.Text.Encoding.GetEncoding("Shift_JIS").GetBytes(text)
End Select
getByteCnt = UBound(bytes) - LBound(bytes) + 1
End Function- 문제 해결 (일단은..)
요약
- 쓸데없이 자세한 로직보다 가장 간단하고 정확한 로직이 모든 걸 포괄한다...
추가 설명
&HFF61: Visual Basic에서 16진수로 표기된 값. &H는 16진수를 나타내는 접두사이며, 그 이후의 숫자들은 해당 코드 포인트의 16진수 표현.\uFF61: 유니코드에서는 코드 포인트를 \u 뒤에 16진수로 표기. 이 표기법은 유니코드 문자의 문자열 리터럴에서 주로 사용.- 두 표현 방식은 동일한 코드 포인트를 나타내며, 일반적으로 같은 문자를 가리킴.
- 예를 들어,
&HFF61과\uFF61은 모두 전각 가타카나의 첫 번째 문자인。

Working Abroad ...