코볼의 전체 구조
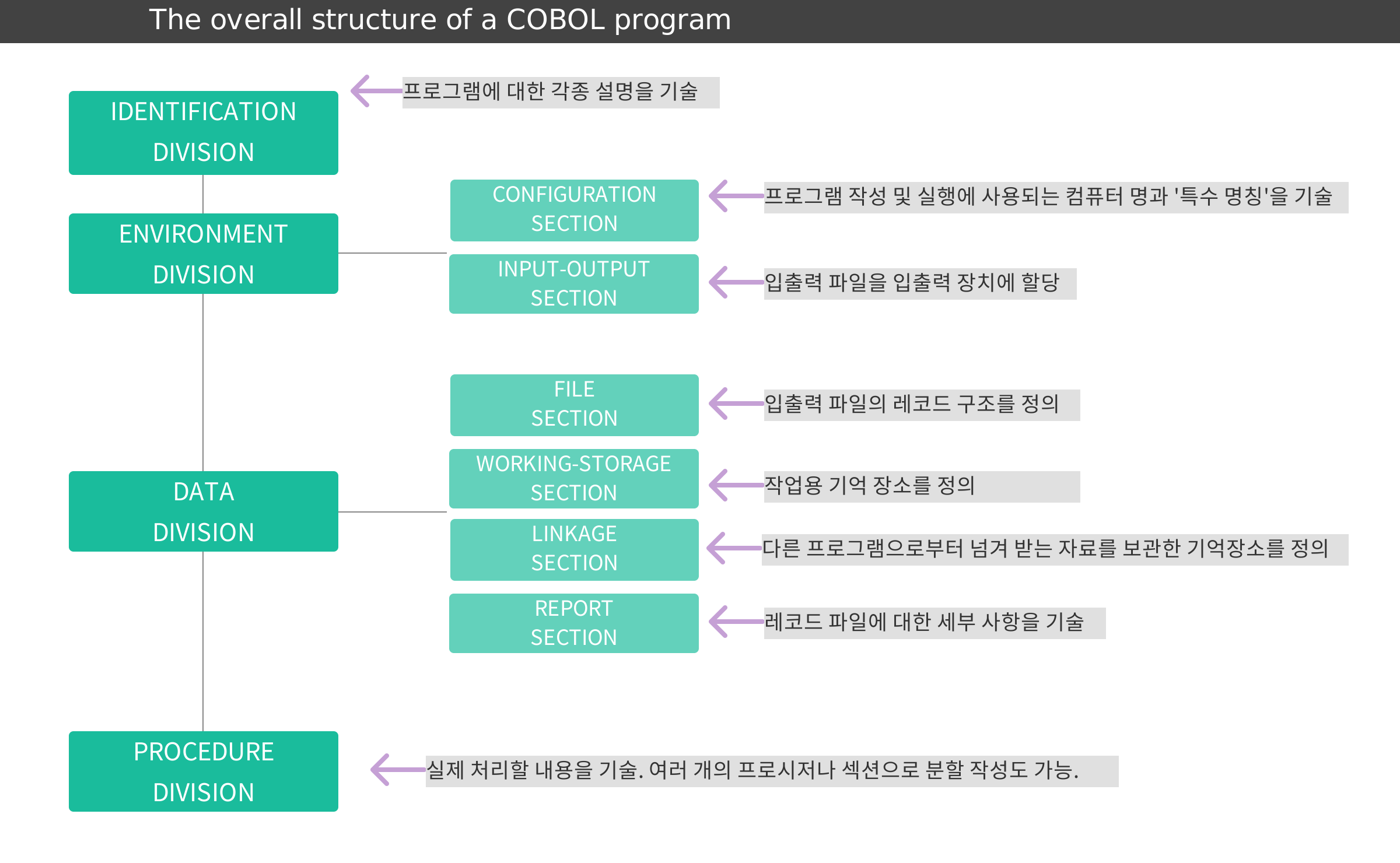
코볼 프로그램 구성 요소
집단화 - 단계
- 문자 (Character)
- 단어 (Word)
- 구(Phrase) / 명령문 (Statement)
- 문장 (Sentence)
- 단락 (Paragraph) / 프로시저 (Procedure)
- 섹션 (Section)
- 부문 (Division)
- 프로그램
<문자 → 단어> 의 예
DIVISION은 D, I, V, ... , N의 문자들을 집합으로 되어 있다.- 그것이 모여 하나의 단어인
DIVISION이 되는 것이다.
<단어 → 명령문> 의 예
GO TO KEUT-P는 각각의 개별적인 단어가 모여서 하나의 명령문(Statement)- 프로그램 실행을
Keut-P프로시저로 이동시킴. - 명령문은 PROCEDURE DIVISION에서 사용되며 처리를 수행한다.
<단어 → 구> 의 예
PIC 9(5) VALUE 12345.PIC 9(5): PIC 구VALUE 12345: VALUE 구- 구(Phrase)는 코볼의 각 예약어 단위로 구성된다.
<명령문 → 문장> 의 예
IF I = 0 GO TO KEUT-P ELSE GO TO GYESAN-P.: 하나의 전체 문장GO TO KEUT-P&GO TO GYESAN-P: 명령문.: 한 문장의 끝에는 반드시 .을 적어야 한다.
<문장 → 단락> 의 예
- 아래는 SECURITY 단락(Paragraph)
SECURITY. CONFIDENTIAL. *> 하나의 문장
SECURITY. PWD - 1234. *> 하나의 문장
SECURITY. ONLY ALLOWED TO MANAGEMENT DEPARTMENT. *> 하나의 문장문자 (Character)
- 코볼에서 사용되는 문자 : 숫자, 영문자, 특수문자
- 각 특수문자는 코볼에 의해 독자적인 기능이 부여되어 있다. ex-주석(*), 문장의 끝(.)
단어 (Word)
- 예약어
- 핵심어(Key Word) : ADD, IF, GO TO ..- 옵션어 (Option Word) : GIVING, ELSE, DEPENDING ..
- 접속어 (Connective) : ADD, OR, OF ..
- 상징값 (Figurative Constant) : ZERO, SPACE, QUOTE ..
- 사용자 정의어 : 프로그램명, 기억장소명, 파일명 ..
- 리터럴 (Literal, 상수) : 123, "SDJ", "COBOL" ...
사용자 정의어
- 프로그램명 (PROGRAM-ID), 자료명, 조건명(IF/PERFORM 문의 조건으로 사용되는 명칭), 프로시저명, 섹션명, 별명(Mnemonic Name : SPECIAL-NAMES을 사용하여 컴퓨터 각 장치에 지정하는 명칭)
- 사용자 정의어 준수 규칙
- 알파벳, 숫자, - 만 사용할 수 있다.
- 첫 번째 글자는 반드시 알파벳이어야 한다. 다만 프로시저는 숫자도 가능.
- 중간에 공란이 있어서는 안 된다.
- 예약어를 사용해서는 안 된다.
- 영어 대문자와 소문자는 구별되지 않는다.
- 최대 30자까지 사용할 수 있다. 다만 PROGRAM-ID는 8자가 최대.
문장 (Sentence)
- 코볼의 각 문장은 다음 요소에 의해 구성됨 : 예약어, 사용자정의어, 리터럴, 계층번호, PIC Phrase(PIC 구), 기호(부호).
- 위의 모든 요소가 사용된 문장 :
77 TestVal 9(5) VALUE IS 100. - 계층번호(77), 사용자 정의어(TestVal), PIC 구(PIC 9(5) - 최대 5글자 폭), 예약어 (VALUE IS), 리터럴(100 - 초기 값을 100으로 설정), 부호(.)
계층번호 (Level Number)
-
DATA DIVISION에서
기억 장소를 정의할 때 사용하며, 기억장소의 등급을 표시한다.-
계층번호: 01 - 49
기술위치: 8열 (A 영역)
용도:
프로그램의 전체적인 구조와 데이터 구조를 정의하는 영역입니다.
주로 레코드 레이아웃, 데이터 구조의 큰 틀을 정의하는 데 사용됩니다.
전체 데이터의 구성과 레코드 간의 관계를 명시합니다. -
계층번호: 66
기술위치: 12열 (B 영역)
용도:
반복적인 작업이나 하위 데이터 항목을 정의하는 영역입니다.
레코드 내의 구성 요소, 배열의 항목 등을 세부적으로 정의할 때 사용됩니다. -
계층번호: 77
기술위치: 8열 (A 영역) 또는 12열 (B 영역)
용도:
단일 데이터 항목이나 상수를 정의하는 영역입니다.
77 레벨의 항목은 일반적으로 변수나 상수를 정의할 때 사용됩니다.
특별한 경우에는 A 영역에 전역 변수로 정의하거나 B 영역에 지역 변수로 정의할 수 있습니다.
-
추가
COBOL의 계층번호는 프로그램의 구조를 논리적으로 나타내기 위한 번호 체계입니다. 이 계층번호 체계는 프로그램 내에서 섹션과 문장의 상대적인 위치를 식별하고, 프로그램의 흐름을 조직화하는 데 사용됩니다. 계층번호는 프로그램 내에서 상하 관계를 나타내며, 다른 섹션 또는 문장으로 분기하거나 호출할 때 사용됩니다. 계층번호는 보통 다음과 같은 형식으로 구성됩니다: N1-N2-N3
N1: 대분류 번호. 보통 섹션을 식별하는 번호로 사용됩니다.
N2: 중분류 번호. 섹션 내에서 구분을 위해 사용될 수 있습니다.
N3: 소분류 번호. 문장 또는 레이블을 구분하기 위해 사용될 수 있습니다.
숫자 계층번호와 "n1, n2, n3"와 같은 계층번호 사이에는 큰 차이가 없습니다. 두 가지 표기법 모두 COBOL 프로그램에서 데이터 항목의 계층을 나타내는 데 사용됩니다. 다만, "n1, n2, n3"와 같은 표기법은 일반적으로 행 레이블이나 문장 레이블을 나타낼 때 사용되며, COBOL의 데이터 정의에서는 주로 사용되지 않습니다. 여기서 주의할 점은, "n1, n2, n3"와 같은 표기법은 주로 코드의 특정 위치를 식별하거나 점프하는 데 사용되며, 데이터 정의와는 더 관련이 있습니다. 데이터 정의에서는 보통 계층번호가 사용되며, 각 계층 번호는 해당 데이터 항목의 특성을 나타내는 데 활용됩니다. 따라서, "계층번호"는 주로 데이터 정의에서 사용되며, 데이터 항목의 계층을 표현하고 기술위치와 용도를 결정하는 데 중요한 역할을 합니다. "n1, n2, n3"와 같은 표기법은 코드 내의 위치를 식별하거나 특정 문장을 실행하는 데 사용되며, 데이터 정의와는 덜 직접적인 연관이 있습니다.
PIC 구 (PIC Phrase)
PIC 구 (Picture Clause) 또는 PIC 구문은 COBOL 프로그래밍 언어에서 데이터 항목의 형식을 정의하는 데 사용되는 중요한 요소입니다. PIC 구문은 데이터 항목이 어떤 형태로 저장되고 표현되어야 하는지를 나타내며, 데이터의 자릿수, 소수점 위치, 문자 형식 등을 지정하는 데 사용됩니다.
PIC 구문은 데이터 항목의 선언 시 사용되며, 데이터 항목의 크기와 형식을 제어합니다. 다양한 PIC 구문을 사용하여 다양한 유형의 데이터를 정의할 수 있습니다.
- 숫자 항목
01 Age PIC 9(3). // 세 자리 숫자
02 Temperature PIC +99V99. // 부호 있는 소수점 숫자
03 Quantity PIC 9(5) VALUE 0.- 문자 항목
01 Name PIC X(30). // 30자의 문자열
02 Initial PIC X. // 단일 문자
03 Grade PIC A(1) VALUE 'A'.- 알파넘릭 항목
01 Student-Id PIC 9(6).
02 Course-Code PIC X(5).
03 Phone-Number PIC X(10).- 날짜 및 시간 항목
01 Birthdate PIC 9(8). // YYYYMMDD 형식의 날짜
02 Event-Time PIC 9(6). // HHMMSS 형식의 시간- 사용자 지정 형식 항목
01 Price PIC $$$$99.99. // 사용자 정의 통화 형식기호 (Symbol)
문장 완성용 기호 (.) :
COBOL에서 각 문장은 마침표(.)로 끝나야 합니다.
마침표는 문장의 종료를 나타내며, 프로그램의 각 문장을 명확하게 구분합니다.
산술 연산용 기호 (+, -, *, / 등) :
COBOL은 산술 연산자를 사용하여 숫자 데이터를 계산하는 데 활용합니다. +는 덧셈, -는 뺄셈, *는 곱셈, /는 나눗셈을 나타냅니다. 예: ADD A TO B, SUBTRACT C FROM D, MULTIPLY E BY F, DIVIDE G INTO H.
관계 연산용 기호 (=, >, <, NOT, AND, OR 등) :
COBOL에서 관계 연산자는 조건을 평가하는 데 사용됩니다.
=는 같음, >는 초과, <는 미만, NOT은 부정, AND는 논리 AND, OR은 논리 OR을 나타냅니다.
예: IF A > B, IF X NOT = Y, IF M < N AND P = Q.
PIC Phrase 편집용 기호 (X, 9, V, S, P, B 등) :
PIC 구문에서 데이터 항목의 편집 규칙을 정의하는 데 사용됩니다.
X는 문자, 9는 숫자, V는 소수점, S는 부호, P는 패킹, B는 바이너리 등을 나타냅니다.
예: PIC X(10)은 10자리 문자열, PIC 9(3)은 세 자리 숫자, PIC S9(5)V99는 부호 있는 소수점 숫자.
콘솔 입출력
- 코드
IDENTIFICATION DIVISION.
PROGRAM-ID. P2-1.
DATA DIVISION.
WORKING-STORAGE SECTION.
PROCEDURE DIVISION.
SiJak-P.
DISPLAY "이름 : KYJ".
DISPLAY "우편번호 : ", 2301234.
STOP RUN.- 결과
이름 : KYJ
우편번호 : 2301234