계산기
개요
이 프로젝트는 자바 언어를 사용하여 여러 방식으로 계산기 프로그램을 만들어 자바에 대한 이해도를 높이는 것을 목적으로 한 블로그입니다.
현재 작성되는 블로그에 해당하는 코드가 이 프로젝트의 최종 모습이 될 예정입니다.
최종 모습인 만큼 어떤 식으로 코드를 짜는 것이 가장 좋을까 고민해봤습니다.
일단 가장 먼저 생각한 것은 level 3에서 문제가 되었던 enum 사용법, 네이밍, 그리고 소수점 포멧 관련된 문제를 해결할 예정입니다.
추가적으로 레이어드 아키텍쳐 형식으로 만들어 보았습니다.
이 프로젝트를 하는 목적을 생각해 보았을 때, 어떤 식으로 코드를 작성해야 좋은 백엔드 개발자가 될지를 고민하는 시간이라고 생각했습니다.
그리고 개발하면서 많이 사용될 형식들을 직접 만들어보고 이해할 수 있는 귀중한 시간이 될 수 있다고 생각했습니다.
Level 3의 문제점
🧭 Enum 사용법
Level3에선 숫자 타입의 데이터를 가져와 식을 enum 안에서 진행되어 그 결과를 return하였습니다.
ADD('+', (x, y) -> x + y),
SUBTRACT('-', (x, y) -> x - y),
MULTIPLY('*', (x, y) -> x * y),
DIVIDE('/', (x, y) -> x / y);이 방법에는 여러 문제가 있었습니다.
일단 먼저 SOLID 원칙에서 SRP를 위반하고 있습니다.
기호를 상수로 바꾸는 로직과 람다식을 이용한 연산 로직이 있습니다.
추후 수정하거나 확장할 일이 생겼을 때 보수하는 것이 어려워질 수 있습니다.
추가적으로, 람다식에서는 예외처리(try-catch)를 할 수 없다는 것을 알게 되었습니다.
PLUS('+'),
SUBTRACT('-'),
MULTIPLY('*'),
DIVIDE('/');그래서 최종 코드에선 연산 로직은 바깥에서 따로 하게 만들고, 기호를 상수로 정의하는 로직에만 사용하였습니다.
🧭 네이밍
사실 level 3에서도 최대한 파일이나 패키지, 변수 네이밍에 신경을 쓰려고 했습니다.
하지만 FormulaDto같은 네이밍같은 경우는 직관적으로 알기 어려울 것 같다는 생각에 RecordDto로 변경하는 등 네이밍을 조금 더 의미있게 쓰려고 수정해봤습니다.
🧭 소수점 포멧
연산 로직이 완료되면 ArrayList에 저장되면 doulbe 타입으로 저장하게 만들었습니다.
이유는 double로 나누기 연산자가 있기 때문에 정확한 계산을 할 수 있다고 생각했기 때문입니다.
하지만 이렇게 하다보니 결과가 소수점으로 굉장히 길게 나왔습니다. 심지어 0으로만 채워지기도 했습니다.
문제는 부동 소수점 오차때문이라고 생각합니다.
저는 이걸 해결하기 위해서 아래 메서드를 따로 만들어서 사용했습니다.
private static String formatDouble(double value) {
return new BigDecimal(value)
.setScale(5, RoundingMode.HALF_UP)
.stripTrailingZeros()
.toPlainString();
}풀이하자면, 결과값을 가져와서 BigDecimal 클래스를 사용합니다.
setScale 메서드로 소수점 5번째자리에서 반올림 시키고,
stripTrailingZeros()로 소수점에 무의미한 0을 제거하고,
toPlainString으로 문자열로 바꾸는 방식입니다.
고민하게 된 문제들
1. 🤔 잘못된 입력을 했을 때, 어떻게하면 프로그램을 종료시키지 않고 다시 입력을 받을 수 있을까?
이미 while문을 사용하고 있었기 때문에 반복문 말고 다른 좋은 방법을 생각해보았습니다.
private static Number inputNumber() {
try {
if (scanner.hasNextDouble()) {
return scanner.nextDouble();
} else if (scanner.hasNextInt()) {
return scanner.nextInt();
} else {
System.out.println("정수 혹은 실수만 입력 가능합니다.");
}
} catch (Exception e) {
InputHandler.printMenu();
scanner.next();
return inputNumber();
}
return 0.1;
}그리고 생각해낸 방법이 예외처리를 하여 재귀함수를 이용하는 것입니다.
생각해낸 방법을 곧바로 코드에 적용했고, 문제는 없어보였습니다.
그런데 계속 보다보니 굳이 int같은 값을 받을 필요가 있는지 의문이 들었고 과감하게 없앴습니다.
public static Double inputNumber() {
String input = scanner.nextLine();
try {
return Double.parseDouble(input);
} catch (NumberFormatException e) {
System.out.println("정수 혹은 실수만 입력 가능합니다.");
return inputNumber();
}
}2. 🤔 스태틱 사용에 대한 고민
계산기 프로그램을 만들면서 static을 여러 곳에 사용했습니다.
사실 이전부터 static을 남발하는 것은 자제하라는 말을 자주들었습니다.
정작 왜 그러는지 찾아보지 않았는데, 이 프로젝트를 하면서 알아보게 되었고 수정하게 되었습니다.
먼저 static의 특징들을 알아보았습니다.
1. 메서드 영역에 저장이 된다.
2. 인스턴스화 없이 바로 객체에서 static로 지정된 변수 혹은 메서드를 불러올 수 있다.
1번에 대해 조금 더 알아보겠습니다.
메서드는 영역에 저장되다보니 프로그램이 종료될 때까지 유지가 됩니다.
그럼 사용하지 않을 때도 계속 유지되다보니 남발하게되면 안 쓰고 있는 데이터를 계속 들고 있게 되니 비효율적입니다.
반면 static과 대척점이라고 할 수 있는 instance는? 인스턴스는 heap에 저장됩니다.
heap은 GC의 관리대상이므로 자동적으로 stack에서 바라보지 않는 데이터들은 자동적으로 제거됩니다.
2번같은 경우는 객체지향 설계 문제입니다.
static같은 경우 public이라면 어디서든 객체만 불러서 사용할 수 있습니다.
인스턴스화가 필요없다 => 인스턴스화 된 것을 쓸 수 없다.
그렇기 때문에 인스턴스화 되면서 사용할 수 있는 객체의 행동과 상태를 사용할 수 없습니다.
추가적으로, 어디서든 불러올 수 있어서 데이터 값이 이곳저곳에서 바뀔 수 있고, 이 static은 프로그램동안 데이터의 하나로써만 사용됩니다.
그래서 객체간의 협력이 어렵습니다.
언제 주로 사용되지?
위에서 얘기한것처럼, 어디서 사용 가능할 수 있고 데이터 하나입니다.
- 상수라면 변경 없이 필요한 곳 적재적소에 사용할 수 있어서 유용할 수 있습니다.
- 한 번만 실행되는 main 메서드 같은 경우라면 static이 효율적일 수 있습니다.
- 인스턴스화하는 것보다 더 효율적이라면 static을 사용해도 괜찮은 것 같습니다.(잘 알아봐야합니다!)
3. 🤔 아키텍쳐
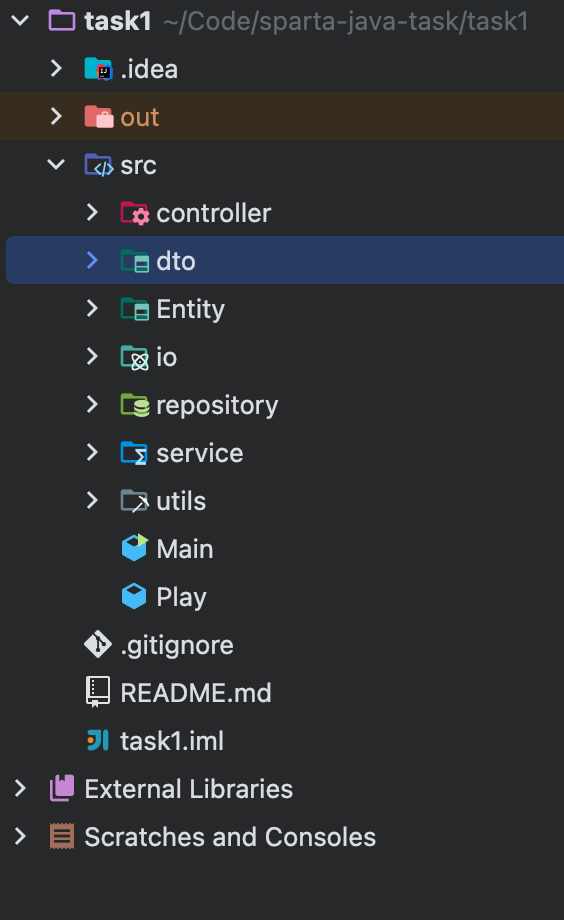
백엔드 개발자라면 어떤 식으로 개발할지 고민했습니다.
자주 사용되는 레이어드 아키텍쳐 형식으로 만드는게 좋겠다는 생각이 들어 직접 실행해보았습니다.
사진과 같이 굉장히 많은 클래스와 패키지가 생겨났고, 오직 Java로만 코드를 했기 때문에 해야할 일이 더 많았던 것 같습니다.
왜 Spring같은 프레임워크를 쓰는지 알 수 있는 시간이였던 것 같습니다.
마무리
아쉬웠던 부분은 아키텍쳐에 너무 많이 신경 썻다는 것입니다.
객체지향의 꽃이라 할 수 있는 네가지의 특징에 조금 더 집중해서 여러 시도를 해봤으면 좋았을거란 생각이 들었습니다.
