DB
1. Index
Index : 검색을 빠르게 하기 위한 수단이다

-- 1) 고유(UNIQUE) 인덱스
-- 중복되지 않는 데이터에 사용하는 인덱스
-- Primary Key 나 Unique key 적용시 생성되는 인덱스
-- CREATE UNIQUE INDEX [인덱스이름] ON [테이블(적용 컬럼)];
-- Duplicate entry 'kim' for key 'emp_ename_idx'
-- 중복되는 데이터가 있는 컬럼에 유니크 인덱스를 설정하면 위와 같은 에러가 발생
create unique index emp_ename_idx on emp(ename);
-- 2) 비고유(NON-UNIQUE) 인덱스
-- 중복되는 데이터가 있는 컬럼에 걸 수 있는 index
-- 외래키 생성시 자동으로 생성된다.
create index emp_ename_idx on emp(ename);
-- 인덱스 확인
show index from emp;
-- 인덱스 삭제(인덱스는 속성으로 취급 된다.)
-- ALTER TABLE emp DROP INDEX [index name];
alter table emp drop index emp_ename_idx;
-- 3) 결합인덱스
-- 복수의 컬럼을 합쳐서 하나의 인덱스로 만들 수 있다.
-- 최대 결합 컬럼은 16개 이다.
-- CREATE UNIQUE INDEX [인덱스이름] ON [테이블(적용 컬럼,...)];
-- 일반 조합 인덱스를 만들고 싶다면 unique 를 빼면 된다.
create unique index emp_combi_idx on emp(ename,job,hiredate);
alter table emp drop index emp_combi_idx;
2. View
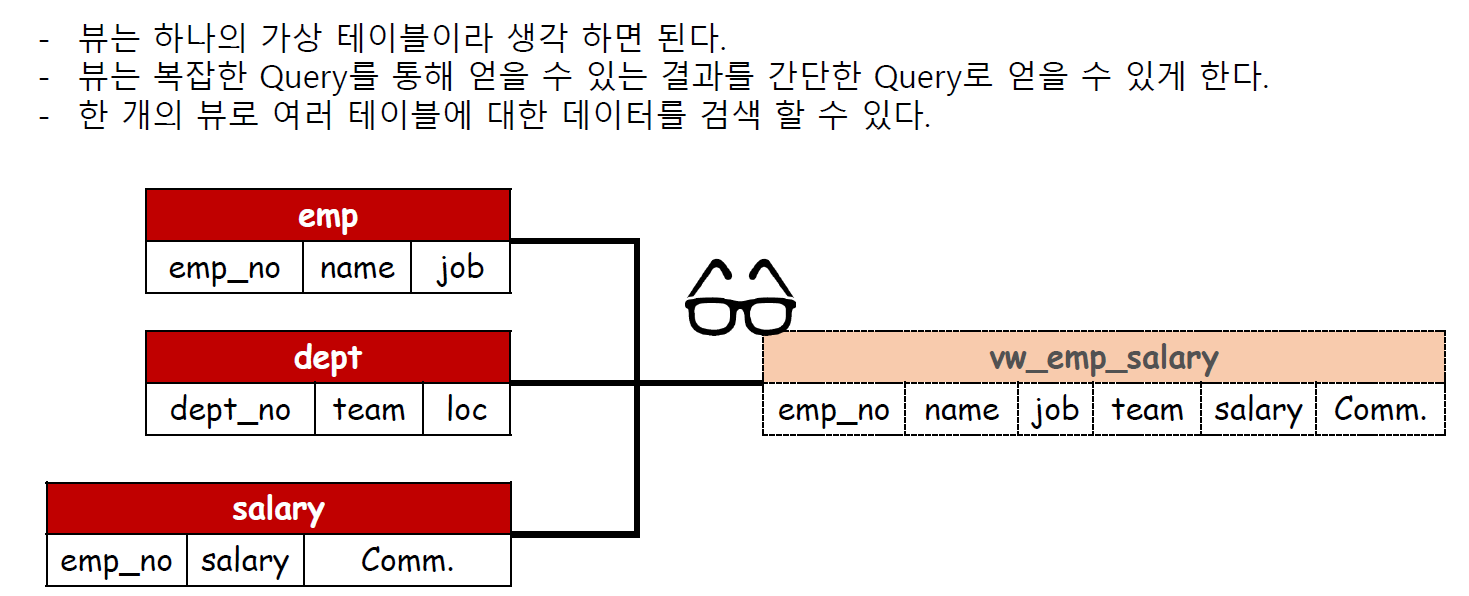
-- 1) 뷰
-- view 는 복잡한 쿼리를 손쉽게 사용할 수 있도록 만들어 놓은 가상 테이블 이다.
-- 복잡한 서브쿼리나 조인을 이용해서 가상 테이블을 만들어 놓으면 해당 테이블만 검색하면 된다.
-- 뷰만의 인덱스를 가질 수 없다
-- 2) 뷰 생성 문법
-- CREATE [OR REPLACE] VIEW [뷰이름] AS [생성할 쿼리문]
-- OR REPLACE 는 기존 뷰를 수정할떄 사용(없으면 생성 있으면 수정)
-- 의도치 않게 기존 뷰를 덮어써 버릴 수 있따.
-- 3) 뷰 생성
create view name_query as
select e.ename, d.deptname from emp e ,dept d
where e.deptno = d.deptno ;
-- 4) 뷰 사용 방법
select * from name_query;
-- 뷰에 보이는 데이터 수정하면 원본도 수정 된다.
update name_query set ename = 'oh' where ename ='kim';
-- 그런데 kim 이 아직 남아있다.
-- 수정되지 않은 kim 은 애초에 뷰를 구성할때 포함되있지 않았다.(등가조인이기 때문에.. deptno =6)
select *from emp;
-- 5) 뷰 수정
-- ALTER TABLE 을 사용 할 수 있지만 OR REPLACE 를 사용할수도 있따.
create or replace view name_query as
select e.ename, d.deptname, d.loc
from emp e ,dept d where e.deptno = d.deptno ;
-- 6) WITH CHECK OPTION : 뷰를 생성한 조건식을 만족하는 컬럼은 UPDATE 를 할 수 없도록 하는 옵션
-- 부서번호 1번의 데이터를 조회하는 뷰
create view check_option as
select deptno ,ename, job from emp where deptno =1 with check option;
select *from check_option;
-- job 컬럼은 수정 가능하다.
update check_option set job = 'manager' where ename ='lee';
-- CHECK OPTION failed `gdj70`.`check_option`
-- view 를 생성하는 조건은 deptno 인데, 이것을 변경 하려고 하면 안된다.
-- WITH CHECK OPTION 이 없다면 변경되겠지만 이 순간에 해당 데이터는 뷰에서 빠지게 된다.
update check_option set deptno = 2 where ename ='lee';
-- 만약 변경을 해야할 상황이라면 해당 테이블에서 수정하면 된다.
select * from emp;
update emp set deptno =2 where ename ='lee';
-- 7) 뷰 확인
show full tables where table_type = 'VIEW';
-- 뷰 구성 쿼리
show create view name_query;
/*CREATE ALGORITHM=UNDEFINED DEFINER=`web_user`@`%`
* SQL SECURITY DEFINER VIEW `name_query`
* AS select `e`.`ename` AS `ename`,`d`.`deptname`
* AS `deptname`,`d`.`loc` AS `loc`
* from (`emp` `e` join `dept` `d`)
* where `e`.`deptno` = `d`.`deptno`
*/
-- 8) 뷰 삭제
drop view check_option;
drop view name_query;
3. Auto_Increment
- 자동 증가 속성
데이터가 추가될때 무조건 함께 추가 되고 계속 증가하기 때문에 중복이 없다.(PK용도로 자주 사용)
- 생성법 1 : 테이블을 만들면서 생성
create table auto_inc(
no int(10) auto_increment primary key
,name varchar(10) not null
);
- 생성법 2 : 이미 만들어진 테이블에 추가
insert into test(no,name) values(1,'a');
alter table test modify no int(10) primary key auto_increment;
- 속성값 초기화
alter table test auto_increment = 100;4. Limit
많은 양의 데이터를 paging 하여 보여 줄때 유용 하다.

- 데이터가 많을 경우 속도가 느리기 때문에 데이터를 먼저 확보하는 방법을 사용한다.
-- 1. 데이터를 정렬 후 확보된 데이터로 가져오는 방법
select
i.emp_no
,i.first_name
,i.family_name
from (select *from employess order by emp_no) i
limit 0,5;
-- 2. index 가 걸려있는 emp_no 를 이용해 기존 데이터와 조인을 해서 데이터 확보
select
e.emp_no
,e.first_name
,e.family_name
from (select emp_no from employess e order by emp_no limit 0,5) i
join employess e on i.emp_no = e.emp_no;5. Function
-
집계 함수 (aggregate)
여러 행 또는 테이블 전체 행으로부터 하나의 결과값을 반환하는 함수 -
Group by 절을 이용하여 그룹당 하나의 결과로 그룹화 할 수 있다.
-
COUNT(column) : 검색한 row 의 수를 반환 한다. (pk를 이용하는것이 좋다)
-
MIN / MAX : 해당 컬럼의 가장 작은,큰 값을 반환 (모든 자료형에 사용가능)
-
AVG(column) : 특정 컬럼의 평균을 반환 한다
-
round() : 특정 소숫점 자리 이하에서 반올림
-
SUM(column) : 특정 컬럼의 합계를 반환한다.
