해외 API 캐싱 서버 구축 및 성능 개선

문제
TMDB API를 통해 서비스를 구현하고 있었습니다.
영화 포스터를 제공하는 API로는 거의 유일해서 선택했습니다.
하지만 해외에 있는 서버이다 보니, 라우팅 지연으로 인해 대기 및 연결 시간이 길었습니다.

그리고 해외 사이트다 보니 국내 인기 영화 순위와 차이가 있었습니다.
다른 API를 써보려고 해도 마땅치 않았습니다.
국내에 영화진흥위원회(KOFIC)가 제공하는 API가 있긴 했지만, 포스터를 제공해주지 않았습니다.
구상 및 해결책
처음엔 두 개의 API를 모두 쓸 생각이었습니다.
KOFIC에서 주간 인기 영화 리스트를 받아온다
⇒ 해당 영화 제목으로 TMDB에 포스터 API 요청을 보낸다.
⇒ 두 요청의 응답을 합쳐서 데이터를 만들어서 화면에 뿌린다.
하지만 이러면 가뜩이나 소요 시간이 긴 해외 API를 쓰면서 다른 요청도 연달아 해야하는 꼴입니다.
그래서 해결 방안을 고민하던 차에, 이전에 공부했던 Next.JS 생각이 났습니다. Next.JS가 제공하던 기능 중 SSG는 프로젝트 빌드 시 미리 데이터 요청을 하고, 해당 요청을 바탕으로 화면을 만들어놓습니다.
- 이번 서버는 일주일에 한 번 캐싱하니 ISR에 가깝겠습니다.
거기서 아이디어를 얻어, 두 개의 API 요청을 미리 해 두고 그 값을 저장해둔다면 어떨까? 하는 생각이 들었습니다.
- CDN을 구축한것과 비슷하네요.
TMDB와 KOFIC에서 필요한 정보만 요청해 온 다음, 캐싱해서 데이터를 다시 가져올 필요 없이 제공한다면? 이 서버를 클라우드로 배포한다면? 영화 순위 API 뿐만 아니라, 다른 기능도 만들 수 있습니다.
구상해 보니 아주 좋은 생각 같아서 바로 만들어봤습니다.
기술 스택
Nest.JS와 EC2를 선택했습니다.
이전에 express로 crud 서버를 구현해 본 적이 있어서 express 기반 프레임워크인 Nest.JS를 써보고 싶었습니다. 그리고 캐싱, cron 등 이번 서버 제작에 핵심적인 기능을 자체적으로 내장하고 있다는 점도 좋았습니다.
Cloudtype으로 express 서버를 간단하게 배포했던 기억이 있어서 사용할까 했지만, 무료 계정은 하루에 한 번 서버를 수동으로 재가동해야 한다는 점이 아주 불편했던 기억이 있어서, AWS에서 제공하는 free tier 인스턴스를 이용하기로 했습니다.
서버 제작
-
KOFIC에서 영화 목록 불러와서 영화 제목 및 기타 정보 추출하기
⇒ 영화 순위는 매주 일요일 바뀌므로 그 전 주의 일요일의 날짜로 데이터 요청하기
-
1에서 얻은 제목 리스트로 TMDB에 포스터 URL 요청하기
⇒ TMDB에서는 영화 제목에 숫자가 들어있으면 한 자 띄워야 제대로 영화 제목을 인식하므로 숫자가 포함된 제목은 수정하기.
-
2, 3 데이터 합쳐서 메모리에 캐싱하기
⇒ 영화 순위는 매주 일요일 바뀌므로 cron을 이용해 일주일에 한 번, 월요일 자정 캐싱하기
-
API요청 시 캐싱한 데이터로 응답하게 하기
이렇게 서버를 만들어서 ec2에 배포했습니다.
성과
TBDB api와 제가 만들어 배포한 AWS api에 각각 열 번씩 요청을 보내고, 그 소요 시간의 평균을 측정했습니다.
네트워크 탭에서 캐시 사용 중지 항목을 체크한 후 진행했습니다.
TMDB API
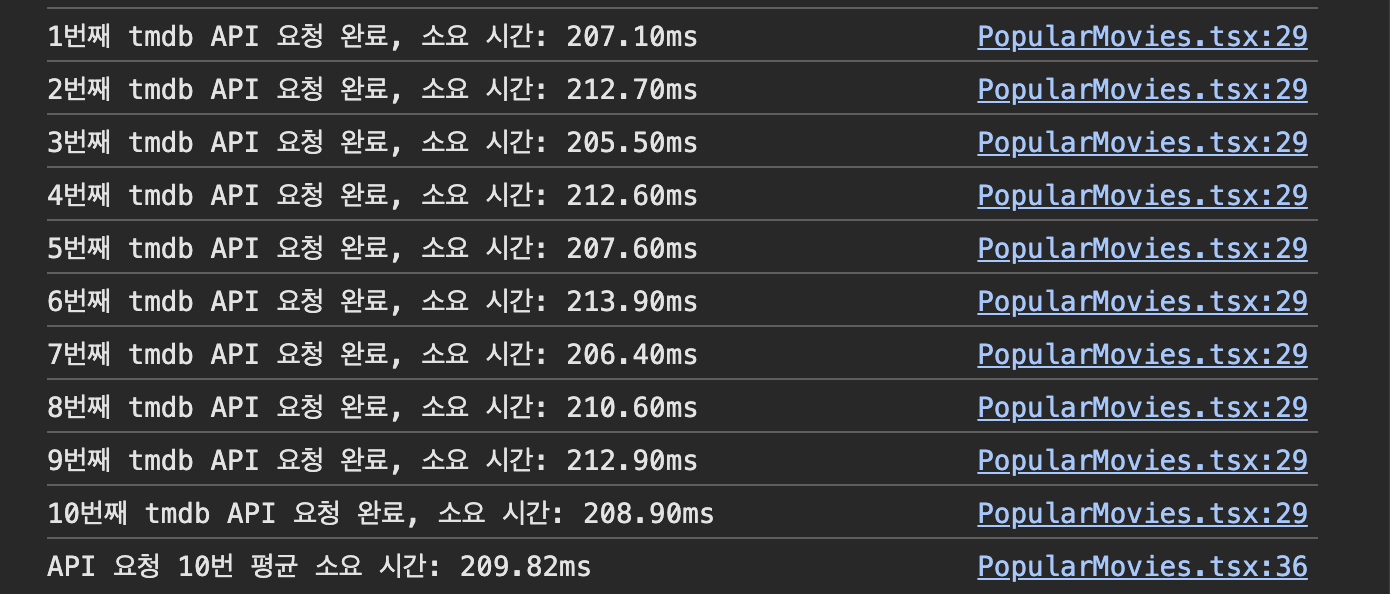
평균 : 209.82ms
AWS API
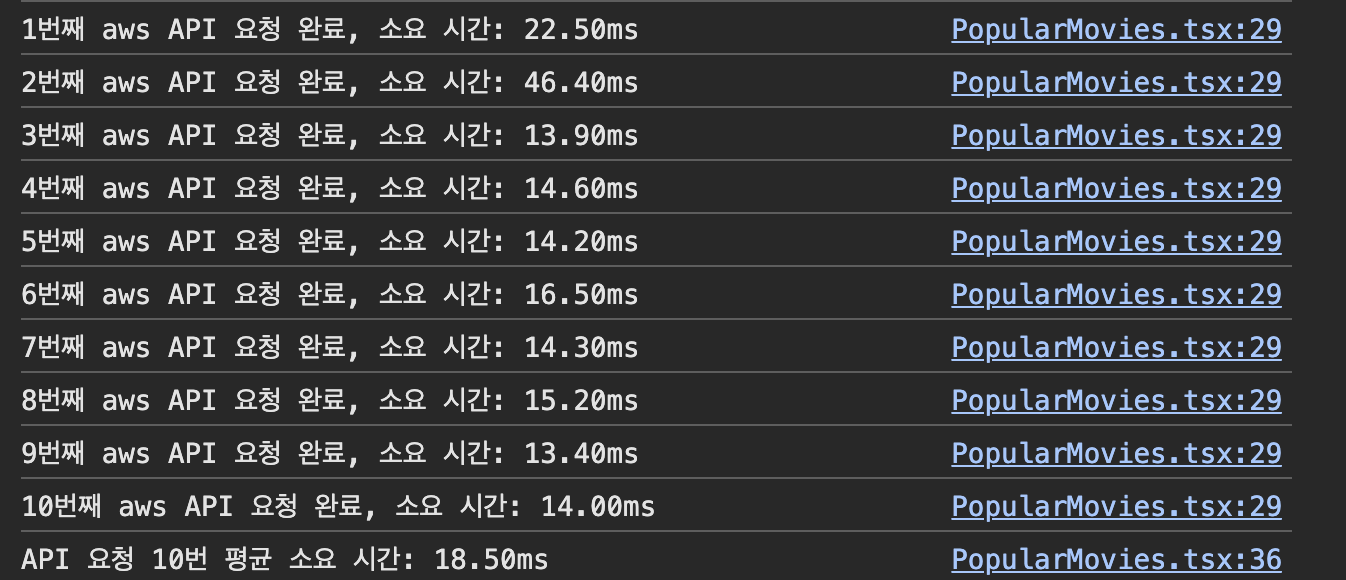
평균 : 18.50ms
아주 만족스럽습니다. 열 배 이상 빨라졌습니다.
개발자도구도 보겠습니다.
TMDB API
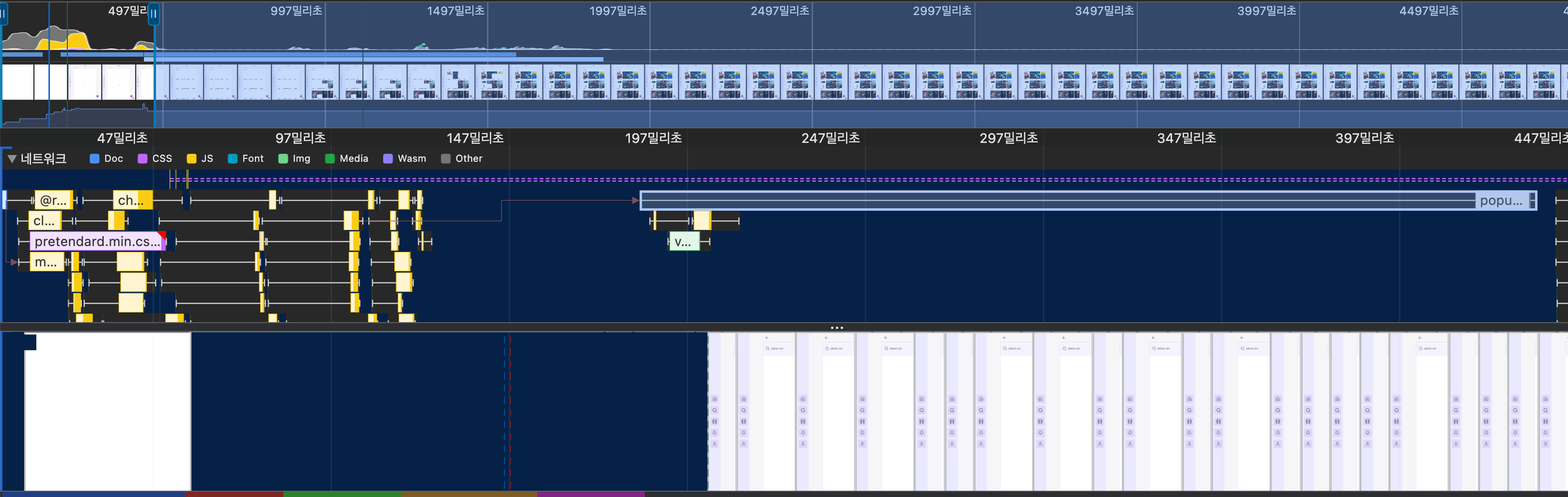
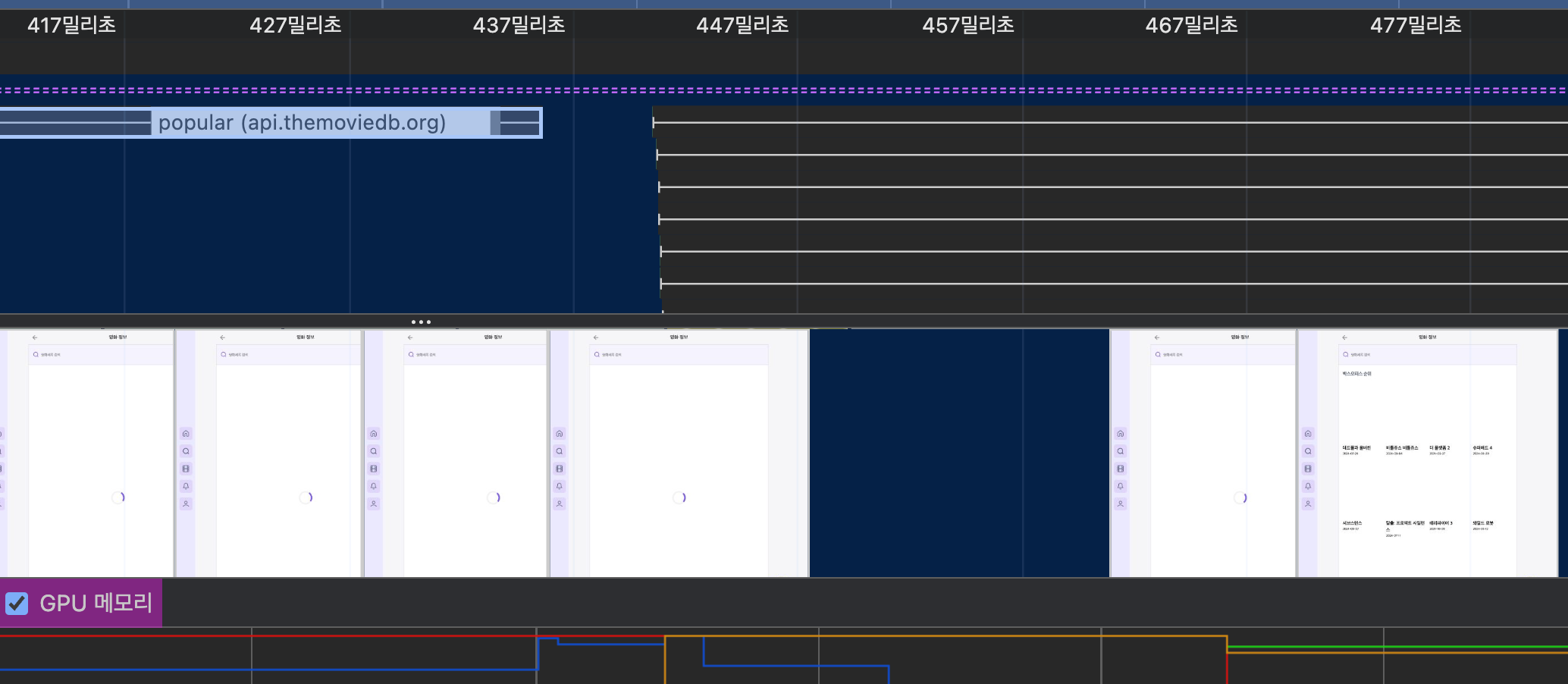
데이터 응답이 와야 화면이 그려지기 시작하므로, 477ms 까지 화면에 spinner만 보입니다.
AWS API
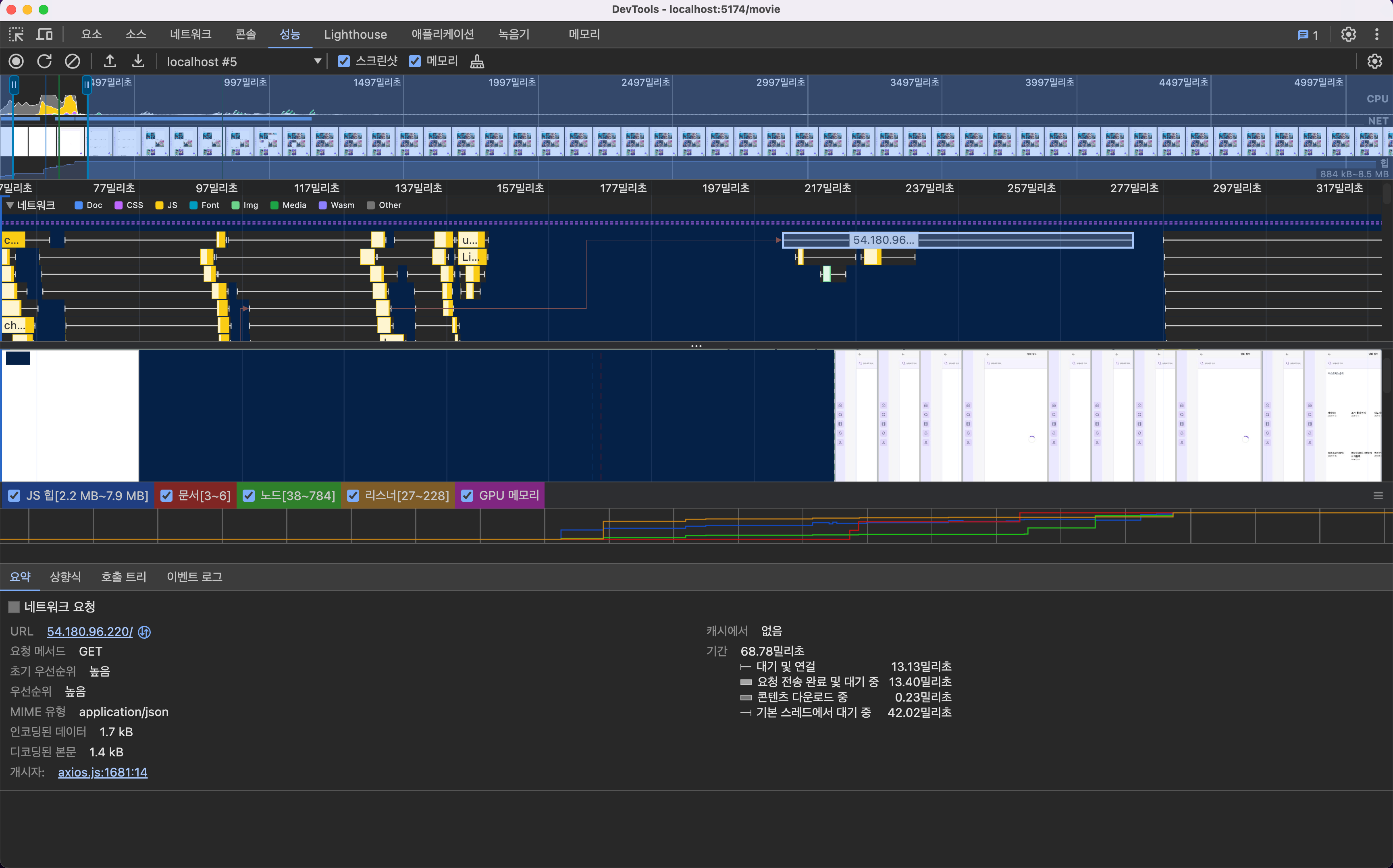
317ms 정도부터 화면이 그려지는 모습입니다.
⇒ API 속도 차이와 비슷한 차이가 납니다
200ms. 사람에 따라 길 수도, 짧을 수도 있는 수치입니다만, 개발 공부를 진행하면서 거의 처음으로 진행한 성능 최적화 작업에서 유의미한 성과를 거두었다고 생각합니다.
개발자도구의 성능 탭을 이렇게 주의 깊게 본 적은 처음인데, depth가 굉장히 깊어서 놀랐습니다. 작은 데이터도 시사하는 바가 있기에 그런 것이겠죠. 개발자도구에 대해 좀 더 공부해 봐야겠다는 생각이 들었습니다.
성과를 측정하면서 느낀 점은, 아 이렇게 측정을 해봐야 실제로 효과가 있다는 걸 알 수 있구나. 라는 겁니다.
어떤 분야의 전문가는 문제 해결의 접근에 있어 모호한 구석이 없어야 한다고 생각합니다. 이 방법이 통할지는 둘째 치고, 이 방법이 불러올 결과에 대해서는 명확히 알아야 한다고 생각합니다.
평소 가지고 있는 생각입니다만, 런앤픽스를 반복하는 자신을 마주치곤 합니다. 전문가가 되고 싶습니다.
겪었던 문제
TMDB요청은 처음 요청 이후에는 거의 소요 시간이 없습니다* 10ms 정도였습니다. 적신호입니다. 몇 시간의 투자가 물거품이 될 상황입니다.
반면 AWS는 TMDM의 첫 요청보다는 짧지만, 그 시간이 줄어들진 않습니다.
문제는 Cache-Control 헤더였습니다.
Client는 네트워크 요청을 하고, Server는 이 요청을 처리합니다. 그런데 만약, 클라이언트가 이전에 요청한 데이터와 새로 요청한 데이터가 같다면 더 이상의 요청은 낭비일 수 있습니다.
이때 쓰이는 것이 HTTP가 제공하는 Cache-Control입니다.
클라이언트의 요청을 캐시 서버나 로컬 캐시 관리자에 전달하고, 캐시 된 문서가 있는지 조회한 후, 존재한다면 유효성 체크까지 마친 뒤, 새로 생성한 헤더와 기존의 Body를 조합해서 서버에서 온 응답처럼 캐시된 데이터를 재사용합니다. 이 때 네트워크 요청을 일어나지 않습니다.
유효성 체크에 유효기간 설정이나 ETag가 쓰이는데,
첫 요청 때 데이터와 Etag를 받고, 다음 요청에 Etag를 같이 보내서 만약 해당 태그의 데이터가 변경되지 않았다면 응답으로 304 Not Modified를 보냅니다. 캐시된 데이터가 사용됩니다.
만약 데이터가 변경되었다면 ETag도 변경되며, 새로운 데이터와 업데이트된 ETag를 받게 됩니다.
- 데이터의 차이를 인식하게 한다는 점에서 mongodb의 __v 필드와 비슷하다는 생각이 들었습니다.
@Header('Cache-Control', 'max-age=3600')이 코드를 AWS 서버에 추가해서 해결했습니다.
