Problem
LeetCode - The World's Leading Online Programming Learning Platform
Given an array of integers nums and an integer target, return indices of the two numbers such that they add up to target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
You can return the answer in any order.
주어진 숫자 리스트에서 합이 주어진 target이 되는 숫자들 조합의 index를 구하여라
Solution
1차 풀이 - 느림
from typing import List
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
length = len(nums)
for i in range(length):
for j in range(i + 1, length):
if nums[i] + nums[j] == target:
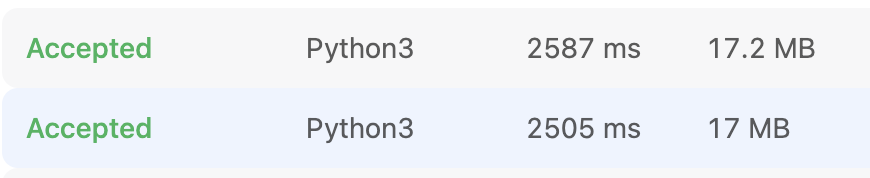
return [i, j]단순하지만 for 문 2번을 중첩으로 돌면서 시간복잡도가 이 되어버린다..
결과
2차 풀이 - 메모리
from typing import List
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
num_dict = defaultdict(list)
for idx, num in enumerate(nums):
num_dict[num].append(idx)
for idx, num in enumerate(nums):
target_num = target - num
if target_num == num:
if len(num_dict.get(num)) == 2:
return num_dict.get(num)
else:
continue
else:
if num_dict.get(target_num) is not None:
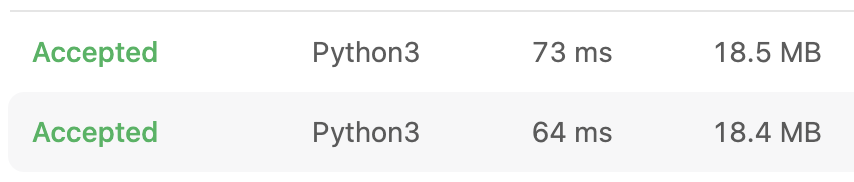
return [idx, num_dict.get(target_num)[0]]dictionary를 이용하여 {num: [idx]}형태로 저장하면서 시간 복잡도는 O(n)으로 낮아졌으나 모든 숫자에 대해 idx를 리스트 형태로 저장하면서 공간복잡도가 쭉 올라갔다.
또한 개인적으로 num_dict.get(target_num)[0]와 같이 [0] 인덱스를 통해서 값을 불러오는 것은 내가 원하는 데이터를 뽑아내는 데에 리스크가 있다고 생각하여 선호하지 않는다.
결과
3차 풀이
from typing import List
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
num_dict = {}
for idx, num in enumerate(nums):
if num_dict.get(num) is not None and num * 2 == target:
return [num_dict[num], idx]
num_dict[num] = idx
for idx, num in enumerate(nums):
target_num = target - num
if target_num != num and num_dict.get(target_num) is not None:
return [idx, num_dict.get(target_num)]2차 풀이에서 단순히 Dict[int: int]가 아닌 Dict[int: List[int]]의 형태로 저장한 이유는 주어진 숫자에 중복이 있을 수 있기 때문이다. 따라서 이번 풀이에서는 해당 케이스를 전처리 과정에서 처리하였다.
if num_dict.get(num) is not None and num * 2 == target- 이미 num_dict에 저장되어 있는 숫자이고, 2를 곱하였을 때 원하는 숫자가 나온다면 저장하지 않고 그대로 return하였다.
if target_num != num and num_dict.get(target_num) is not None- 위의 전처리 과정으로 인해 num * 2 = target이 되는 케이스는 없을 것이다. 따라서 target_num == num인 케이스는 예외처리를 해주었다.
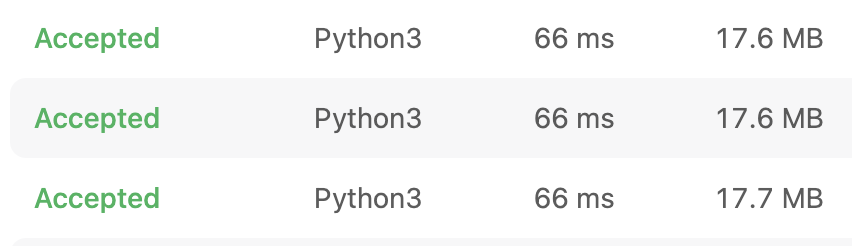
결과적으로 중간에 끝나는 케이스도 있고, dictionary value로 리스트가 아닌 단순 정수를 할당하면서 시간과 메모리를 모두 줄일 수 있었다.
결과
추가적으로
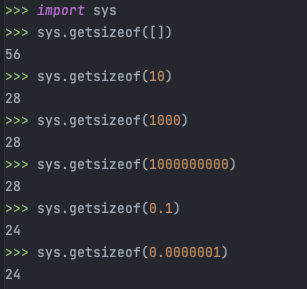
sys.getsizeof(): 객체의 메모리 사이즈를 바이트 단위로 반환
예제를 통해 빈 리스트도 정수보다 2배의 메모리를 차지하는 것을 확인할 수 있다.
Reference
