
모아모아 크롤링, 저장하는 몽고디비!
01. crowling 기초
crowling는 무엇인가요?페이지 내 링크의 모든 내용을 가져오는 것!
scrapy는 무엇인가요?웹에서 내가 원하는 정보를 스크래핑 하는 것!
crowling 시작 템플릿
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작Test. 영화 웹스크래핑
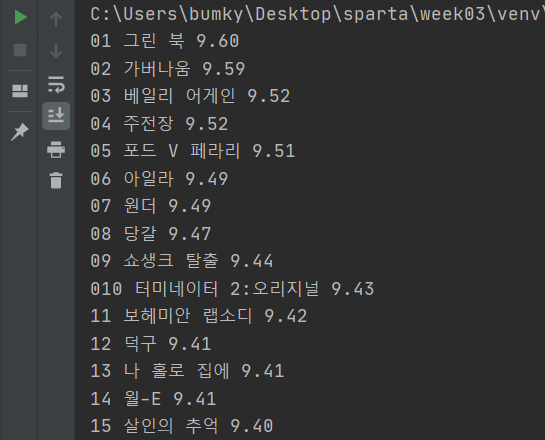
python 코드
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs=soup.select('#old_content > table > tbody > tr')
for movie in trs:
a_tag=movie.select_one('td.title > div > a')
if a_tag is not None:
num=movie.select_one('td:nth-child(1) > img')['alt']
title=a_tag.text
score=movie.select_one('td.point').text
print(num, title, score)Test. 음악 웹스크래핑
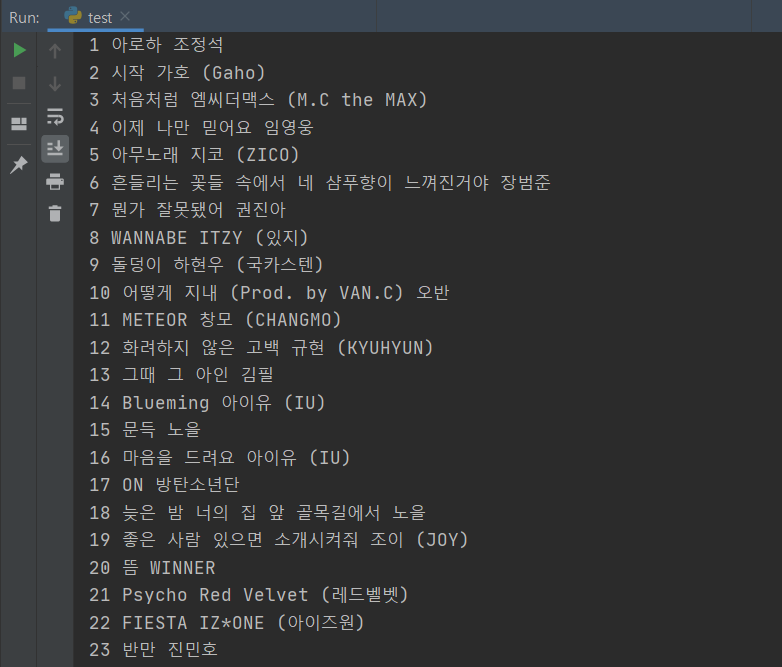
python 코드
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs=soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for song in trs:
num=song.select_one('td.number').text[0:2].strip()
title=song.select_one('td.info > a.title.ellipsis').text.strip()
name=song.select_one('td.info > a.artist.ellipsis').text
print(num, title, name)02. 느낀점
내가 원하는 정보만 잘 선택하는게 중요!

안녕하세요. 클래식을 즐기는 개발자, 이용찬입니다.