📋SQL 개요
✏️정의
- SQL은 관계형 데이터베이스를 관리하고 조작하기 위한 구조화된 질의 언어입니다.
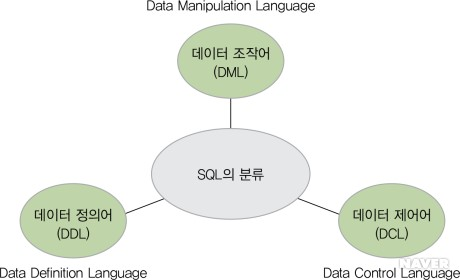
- 기능에 따라 데이터정의어(DDL), 데이터 조작어(DML), 데이터 제어어(DCL)로 나누어집니다.
- DDL
- 테이블의 생성, 수정, 삭제 등에 사용됩니다.
- 주요 구문으로는 CREATE, ALTER, DROP 등이 있습니다.
- DML
- 테이블에서 데이터의 조회, 삽입, 수정, 삭제에 사용됩니다.
- 주요 구문으로는 SELECT, INSERT, UPDATE, DELETE 등이 있습니다.
- DCL
- 데이터에 대한 접근 권한 관리에 사용됩니다.
- 주요 구문으로는 GRANT, REVOKE, COMMIT, ROLLBACK, LOCK 등이 있습니다.
- DDL
✏️실행 과정
MySQL 기준
- 사용자가 작성한 SQL을 데이터베이스로 보냅니다.
- MySQL 쿼리파서는 SQL 문장을 토큰으로 쪼개서 트리를 만듭니다. 이 트리를 Parse Tree라고 하는데 이를 통해 쿼리를 실행합니다. 이 과정에서 문법 오류도 체크합니다.
- 다음으로 전처리기가 Parse Tree을 기반으로 SQL 문장구조에 문제가 없는지 체크합니다. 또한 SQL에 포함된 테이블, 컬럼 이름이 유효한지 접근권한이 있는지 체크합니다.
- 다음으로 옵티마이저가 SQL 실행을 최적화하기 위해 실행 계획을 수립합니다.
- 마지막으로 쿼리 실행엔진이 수립된 실행 계획대로 스토리지 엔진을 호출해서 쿼리를 수행하고 결과를 사용자에게 응답합니다.
📋SQL 구문
✏️SELECT 절의 처리순서
MySQL 기준 4 5 순서 확인
FROM절에서 타겟 테이블이 정해지며, JOIN이 있다면 적용됩니다.WHERE절이 적용되어 튜플이 필터링 됩니다.GROUP BY에 지정한 컬럼을 기준으로 튜플이 그룹화 됩니다.HAVING이 적용되어 GROUP BY로 그룹화된 튜플에 대해 추가적으로 필터링 됩니다.DISTINCT가 적용되어 중복된 튜플이 필터링 됩니다.ORDER BY가 적용되어 튜플이 정렬됩니다.LIMIT이 적용되어 명시된 개수만큼 튜플이 반환됩니다.
✏️SELECT ~ FOR UPDATE 구문에 대해서 설명해주세요.
- SELECT ~ FROM UPDATE 구문은 튜플들을 조회하면서 락을 걸고, 그에따라 다른 트랜잭션은 해당 튜플들을 수정할 수 없습니다.
- 락을 건 트랜잭션 안에서 튜플들에 대한 수정이 진행되고, 해당 트랜잭션이 종료되면 변경 사항이 확정됩니다.
✏️GROUP BY절에 대해서 설명해주세요.
- GROUP BY 절을 사용해서 특정 속성을 기준으로 데이터를 그룹화 할 수 있습니다.
- 주로 집계 함수와 함께 사용됩니다.
- 예를들어 리뷰 테이블에 가게 ID 컬럼과 평점 컬럼이 있을 때,
GROUP BY를 사용하여 가게 ID 기준으로 그룹화하고, SELECT 절에서, 집계함수AVG를 사용하면 가게 별 평균 평점을 조회할 수 있습니다.
그룹 바이 주의사항과 HAVING vs where 내용 추가
✏️ORDER BY절에 대해서 설명해주세요.
- ORDER BY 절을 사용해서 특정 속성을 기준으로 조회 결과를 정렬할 수 있습니다.
- 기본적으로 오름차순(
ASC)으로 정렬되며,DESC키워드를 사용하면 내림차순으로 정렬할 수 있습니다.
📋조인의 종류와 차이점
✏️INNER JOIN vs OUTER JOIN
- INNER JOIN
- ON 절을 통해 조인 조건을 설정하여 두 테이블을 결합할 수 있습니다. 이때, 조인 조건을 만족하는 튜플만 반환합니다. (교집합 결과)
- OUTER JOIN
- 마찬가지로 ON 절을 통해 조인 조건을 설정하여 두 테이블을 결합할 수 있지만, 조인 조건에 맞지 않는 튜플도 포함됩니다.
- 마찬가지로 ON 절을 통해 조인 조건을 설정하여 두 테이블을 결합할 수 있지만, 조인 조건에 맞지 않는 튜플도 포함됩니다.
✏️OUTER JOIN의 종류
- LEFT OUTER JOIN
- 예를 들어, A와 B 테이블이 있을때 LEFT OUTER JOIN을 하면 A 테이블의 모든 결과와 A, B 테이블의 교집합된 결과를 가져옵니다. 만약 A 테이블의 결과 중 B 테이블과 일치하는 결과가 없다면 해당 부분은
NULL값으로 채워집니다.
- 예를 들어, A와 B 테이블이 있을때 LEFT OUTER JOIN을 하면 A 테이블의 모든 결과와 A, B 테이블의 교집합된 결과를 가져옵니다. 만약 A 테이블의 결과 중 B 테이블과 일치하는 결과가 없다면 해당 부분은
- RIGHT OUTER JOIN
- LEFT OUTER JOIN과 반대 방향으로 적용됩니다.
- FULL OUTER JOIN
- LEFT OUTER JOIN과 RIGHT OUTER JOIN의 결과가 모두 존재합니다.
- LEFT OUTER JOIN과 RIGHT OUTER JOIN의 결과가 모두 존재합니다.
✏️CROSS JOIN
- 두 테이블의 가능한 모든 조합 결과를 생성합니다.
- 두 테이블의 각 튜플의 수를 곱한 개수 만큼 결과가 나옵니다.
- 카테시안 곱이라고도 부릅니다.
📋서브쿼리에 대해서 설명해주세요.
- 서브쿼리는 SQL안에 포함된 또 다른 SQL입니다.
- 서브쿼리는 WHERE, SELECT, FROM절에 적용될 수 있습니다.
📋CASCADE 설정에 대해서 설명해주세요.
CASCADE는 참조 무결성을 유지하기 위해 사용되는 설정입니다. 예를들어 게시판과 댓글 테이블이 있고, 게시판 테이블의 외래키를 댓글 테이블이 갖는다고 설정했을 때, ON DELETE CASCADE 설정을 하면 게시판 테이블의 튜플이 삭제 됐을 때, 연관된 댓글 테이블의 튜플도 같이 삭제되게 됩니다.
- 참조 무결성이란?
- 참조할 수 없는 값은 외래키로 가질 수 없다는 규칙입니다.
- 실무에서는 보통 CASCADE 설정하지 않는 이유?
- CASCADE 옵션을 적용하면, 연관된 엔터티의 생명주기를 자동으로 관리해주기 때문에 상당히 편리해보입니다. 하지만 역으로 생각해보면, 해당 옵션으로 인해 엔터티가 어디까지 같이 저장되고 삭제되는지를 코드를 계속 보며 역추적해야하는 불편함이 있습니다. 또한 복잡성이 증가하기 때문에 의도치않은 쿼리의 발생과 데이터 손실의 위험이 있을 수 있습니다.
- 게시글과 첨부 파일 같이 완전히 종속되는 경우에는 CASCADE 옵션의 사용이 적절할 수 있습니다.
- 하지만 완전한 종속이 아닌, 여러 곳에서 참조되는 상황이라면 CASCADE 옵션의 사용은 적절하지 않습니다.
📋VIEW
- 여러 테이블들을 합쳐서 만든 가상의 테이블입니다.
- 여러 테이블들이 합쳐져 하나의 테이블로 정의된 것이기 때문에 SQL 작성을 간단히 할 수 있습니다. 또한 원본 테이블을 노출시키지 않게 함으로 보안성을 제공할 수 있습니다.
📋DISTINCT
DISTINCT를 통해 SELECT 문에서 조회된 튜플들의 결과에서 중복된 부분을 필터링 할 수 있습니다.
📋페이지네이션 쿼리 작성
LIMIT와 OFFSET을 사용하여 페이지네이션 쿼리를 작성할 수 있습니다.
페이지 번호는 OFFSET을 통해, 페이지에 포함된 행 개수는 LMIT를 통해 나타냅니다.
예를들어 주문 테이블 대상 SELECT 쿼리에서 LMIT가 10이고 OFFSET이 10이라면, 11번째 투플부터 20번째 투플까지만 조회할 수 있습니다.
이렇게 하면 2번 페이지에서 10개 행을 보여주는 쿼리가 됩니다.
📋DROP, DELETE, TRUNCATE
- DROP
- 테이블과 테이블에 포함된 데이터, 인덱스, 트리거 등 테이블과 관련된 모든 정보를 제거합니다.
- DELETE
DML이며 테이블의 튜플을 삭제합니다.- 각 행마다 로그를 남겨서 TRUNCATE보다 느립니다.
- ROLLBACK을 할 수 있으며 WHERE과 함께 사용하여 특정 튜플만 삭제할 수도 있습니다.
- TRUNCATE
DDL이며 테이블의 모든 데이터를 제거합니다.- 수행시 DELETE 처럼 행마다 로그를 남지지 않기 때문에 빠르고 ROLLBACK이 불가능합니다.
- AUTO_INCREMENT 값이 초기화 되기도합니다.
📋SQL Injection 공격
✏️정의
- SQL Injection 공격은 악의적인 사용자가 SQL 구문을 클라이언트단 입력폼에 주입하여 서버의 데이터베이스를 공격하는 것입니다.
✏️예방
- 실행할 SQL 구문을 미리 Prepared Statement로 정해두고, 사용자가 입력한 값은 파라미터로만 넣어주는 방식을 사용하면, SQL Injection을 통해 비정상적인 쿼리 수행을 방지할 수 있습니다.
📋알고 있는 SQL 안티패턴이 있다면 설명해주세요.
SELECT 쿼리에서 LIKE를 사용할때 와일드카드를 앞뒤로 넣는 방식은 (LIKE %one%)는 테이블 full scan이 되기 때문에 성능이 떨어지기 때문에 사용을 지양해야합니다.
앞에 붙은 와일드 카드로 인해 정렬 기준이 없어져서 인덱스가 사용 되지 않기 때문입니다.
