HTTP 공부를 하다보면 자주 나오는 것이 인코딩에 대한 내용이다.
인코딩에 대해 이야기 하다보면 ASCII , UTF-8 , EUC-KR ... 등등 다양한 인코딩이 나오는데
그 중 ASCII 코드에 대한 내용을 공부해봤다.
정의
ASCII (American Standard Code for Information Interchange) 는 영문 알파벳을 사용하는 대표적인 문자 인코딩이다.
컴퓨터와 통신장비를 비롯해 문자를 사용하는 많은 장치에서 사용된다.
등장 배경
컴퓨터는 오로지 0 ,1 의 신호만 해석 할 수 있기에 문자와 같은 아날로그 신호를 디지털 신호로 전달해주어야 했다.
이에 아날로그 신호를 디지털 신호로 인코딩 할 표준화 된 체계가 필요했고
그것이 바로 ASCII 코드이다.
디지털 신호와 비트
비트는 binary digit 의 축양형으로 디지털 정보의 가장 작은 단위인 0 또는 1의 값을 갖는다.
컴퓨터는 비트들의 조합을 통해 데이터를 처리하고 저장한다.
비트가 1개가 존재 할 때 처리 가능한 데이터는 0 , 1 로 2가지 신호만 처리가 가능하며
2개 존재 할 때는 00 , 01 , 10 , 11 로 4가지
3개 존재 할 때는 000 , 001 , ... 111 로 8가지 이런식으로 데이터 신호를 처리 할 수 있다.
1비트당 개의 신호가 처리 가능하기 때문에
내가 개의 문자들을 디지털 신호로 처리하고 싶다면 개의 비트만 있다면 모든 신호를 디지털 신호로 처리 할 수 있다.
그래서 1960년 미국 표준 협회는 ASCII 코드를 개발하기 위해 몇 개의 문자들을 디지털 신호로 처리할까 생각하다가 개의 숫자, 특수기호 , 영어 소문자 및 대문자를 디지털 신호로 인코딩 시킬 ASCII 코드를 만들었다.
그러니 맨 처음의 ASCII 코드는 7비트로 이뤄진 디지털 신호들로 아날로그 데이터를 맵핑한 테이블이였다.
그러다가 나중에 통화기호 , 수학기호 , 악센트 등등 다양한 특수 문자까지 포함하기 위해 개의 문자를 맵핑 할 수 있도록 비트로 이뤄진 ASCII 코드들을 만들었다.
해당 코드는 0~9 , a~z , A~Z , 몇 개의 특수 기호들을 비트의 신호들과 맵핑해두었다.
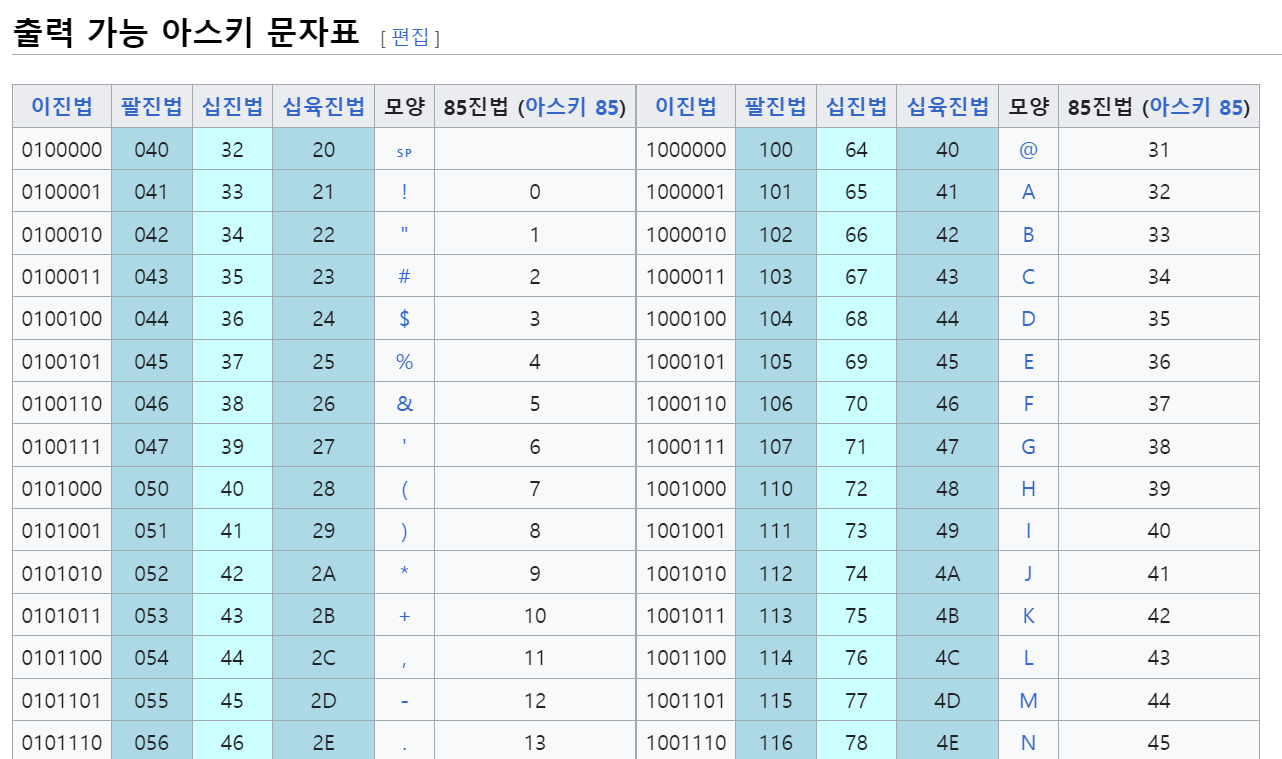
ASCII 에서 살펴볼 수 있다.
아스키코드의 일부를 가져온 것으로 만약 내가 컴퓨터에게 DOG 라는 문자를 보낼 때
아스키코드로 인코딩을 한 값을 이진법으로 표현하면
1000110 (D) , 1001111 (O) , 1000111(G) 로 표현 할 수 있다.
7비트로 이뤄진 것은 가장 앞의 0을 표시하지 않은 것이다.
8비트 표현법으로 D 를 쓰면1000110이 아니라01000110으로 표현 한다.
그럼 해당 이진법을 십육진법으로 표현하면 44 4F 47 , 십진법으로 표현하면 68 79 47 로 표현 가능하다.
그럼 결국 ASCII 코드를 이용하면 영어권 사람들은 본인들의 아날로그 신호를 컴퓨터에게 전달하는 것이 가능하다.
비 영어권은 ?
그럼 우리는 ? 어떻게 아날로그 신호를 디지털 신호로 인코딩 하여 전달 할 수 있을까 ?
그거를 위해 나온 것이 바로 ~ 유니코드 이다.
유니코드
전 세계의 모든 문자를 다루도록 설계된 표준 문자 전산 처리 방식이다.
예전 ASCII 코드가 8비트 내에서 문자를 통합하여 개인 256개의 문자를 인코딩 했다면
유니코드는 2~4 바이트 이상을 이용해 문자들을 인코딩 해둔 맵이다.
각 유니코드는 각 바이트값을 16진수를 이용해서 표현하며 16진수로 표현했음을 이야기 할 수 있도록 U+015A 이런 식으로 U+ 라는 기호를 붙인다.
16진수
16진수는
0~9 ,A(10) ~ F(15)로 정의된다.
16진수 하나는4bit의 정보 하나를 표현 할 수 있다.
0000은0,0010은2,1111은F이런식으로 말이다.
그러면 16진수 2개가 있으면1byte의 정보 를 표현하는 것이 가능하다.
1byte를 자리수 생각 안하고 절반으로 나누면 각4bit의 정보로 표현되며
각4bit의 정보를 16진수로 표현한 후 정의 할 수 있다.
example:00011111이 있다면0001과1111로 나눈 후1F로 정의 가능그럼 16진수는 갑자기 왜 ?
컴퓨터는 일반적으로 바이트 단위로 정보를 나누기 때문에 1바이트를 효과적으로 표현하기 좋은 16진수를 사용 할 수 있다.
표현은 16진법을 이용해 하더라도 컴퓨터에게 넘어갈 때는 이진법 형태로 인코딩 되어 바이트 단위로 넘어간다는 것은 동일하다.
유니코드는 몇 개의 문자를 지정 할 수 있을까 ?
유니코드는 여러가지의 평면으로 구성되어 있다.
| 플레인 | 범위 | 비트 수 | 범위 및 의미 |
|---|---|---|---|
| 기본 다국어 평면 (BMP) | U+0000부터 U+FFFF까지 | 16비트 (2바이트) | 가장 일반적으로 사용되는 문자 |
| 보충 다국어 평면 (SMP) | U+010000부터 U+01FFFF까지 | 21비트 (3바이트) | 다양한 스크립트의 추가 문자 |
| 보충 이디오그래픽 평면 (SIP) | U+020000부터 U+02FFFF까지 | 21비트 (3바이트) | 동아시아 스크립트를 위한 이디오그래픽 문자 |
| 보충 특수 용도 평면 (SSP) | U+E0000부터 U+EFFFF까지 | 21비트 (3바이트) | 특수 목적 문자 및 기호 |
| 보충 사설 사용 영역 (SPUA) | U+F0000부터 U+10FFFF까지 | 21비트 (3바이트) | 사적인 용도 및 특정 응용 프로그램 문자 |
각 평면 별로 다양한 글자 및 기호들이 맵핑 되어 있으며 총 개의 문자 및 특수 기호들이 존재한다.
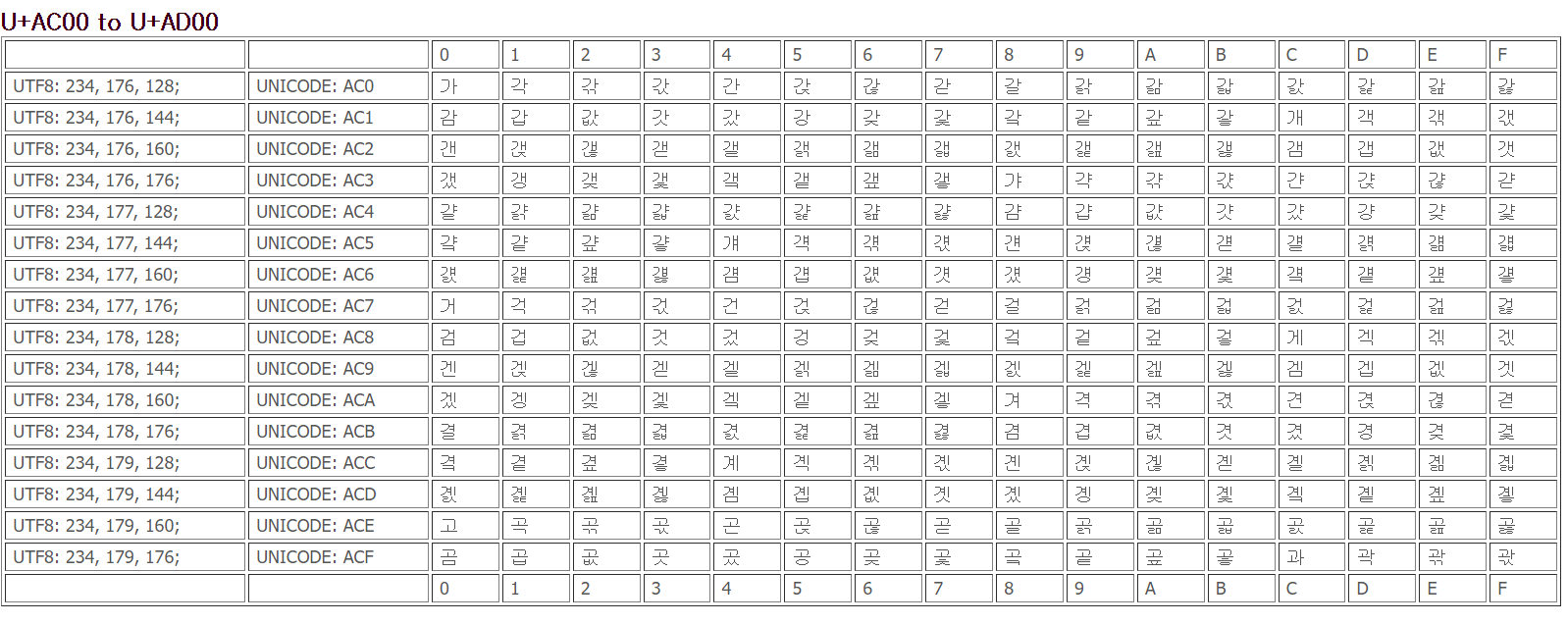
한국어같은 경우는 유니코드 상에서 U+AC00 은 가 , U+AC01 은 각 이런 식으로 인코딩 되어 있다.
이런 인코딩 방식을 완성형 인코딩 방식이라고 한다.
문자를 다루는 인코딩 규칙에 대한 모든 것
해당 영상에 다양한 내용이 들어있다. 정말 도움이 많이 된다 !!
유니코드와 ASCII 코드의 관계
유니코드 하위 평면은 ASCII 코드의 내용과 동일하다.
그러니 128개의 유니코드 값들인 U+0000 ~ U+007F 까지는 ASCII 코드에 맵핑된 값들과 같다.
정리
어쨌든 정리하면 유니코드는 영어권에서만 사용 가능하던
ASCII코드에서 전 세계의 모든 문자 및 특수 기호들을 맵핑해둔 체계이다.
UTF-8 , UTF-16
UTF-8 , UTF-16 은 유니코드로 맵핑된 값들을 인코딩 하는 방식을 의미한다.
해당 방식들의 가장 큰 특징은 가변 길이 인코딩 을 사용한다는 것이다.
그게 어떤 뜻이냐면
우리가 어떤 문자를 컴퓨터에게 넘겨줘 메모리에 할당 할 때
A 라는 문자를 메모리에 저장하기 위해 ASCII 코드를 이용해 1000001 로 변경하고
컴퓨터는 7bit 인 해당 값을 저장하기 위해 메모리의 일곱자리에 1,0,0,0,0,0,1 값을 할당한다.
그럼 유니코드를 이용하는 UTF-8 , UTF-16 을 이용해 A 를 인코딩 한다고 해보자
UTF-8 을 이용하면 A 는 U+0041 이다.
그럼 자리수에 따라서 이진수를 만들면 00000000 00000000 00000000 01000001 가 되고
메모리에는 32bit 자리를 만들어야 한다.
보기만해도 너무 비효율적이다.
그!래!서!
UTF 인코딩 방식은 가변 길이 인코딩 을 이용한다.
UTF-8 은 ASCII 코드로 구성된 문자열의 범위의 경우에는 1byte 의 자리만 준비하도록 한다.
해당 범위를 넘어선 경우에는 해당 범위를 넘어섰으면서 가장 최소한의 바이트 자리만 준비하도록 한다.
예를 들어 한글 문자인 가 의 경우 유니코드 상으로 U+AC00 이다. 이를 십진법으로 표현하면
const encoder = new TextEncoder();
const byteArray = encoder.encode('가');
console.log(byteArray); // Uint8Array(3) [ 234, 176, 128 ]const convertBit = (number) => {
const result = [];
while (number > 1) {
result.push(number % 2);
number = Math.floor(number / 2);
}
result.push(number);
return result.reverse().join('');
};
byteArray.forEach((num) => {
console.log(`${num} : ${convertBit(num)}`);
});
/**
234 : 11101010
176 : 10110000
128 : 10000000
*/로 총 3바이트의 메모리만 준비해두면 된다.
그러니 UTF-8 은 ASCII 코드 내 문자열의 경우엔 메모리에 1바이트만 할당, 그 외의 경우엔 3바이트를 할당하도록 하는 가변 길이 인코딩을 이용한다.
UTF-8 , UTF-16 모두 가변길이 인코딩을 사용한다는 공통점이 존재하지만
UTF-16 은 최소 단위가 1바이트가 아닌 2바이트이다.
ASCII 코드의 문자열이라 할지라도 A 의 경우엔 00000000 01000001 로 메모리에 할당된다.
이는 메모리 효율성이 떨어지기 때문에 대부분 웹의 인코딩 방식은 UTF-8 을 따른다.
그럼 ASCII 코드에 있는 애들만 메모리에 1byte 고 나머지 애들은 3byte 인데 억울해요
어쩔 수 없다.
이런 체계를 만든게 미국과 영국이고 유니코드가 ASCII 코드 이후에 나온 것이기 때문에
회고
야호 드디어 나도 인코딩 관련된 내용이 나왔을 때 흐린 눈으로 회피하지 않아도 될 것 같다.
이걸 공부하며 어떻게 메모리에 아날로그 데이터 값들이 저장되는지 더 이해 할 수 있었다.
참고 자료
Unicode, in friendly terms: ASCII, UTF-8, code points, character encodings, and more
