강의 링크 : http://www.kocw.net/home/cview.do?mty=p&kemId=1169634
강의 회고
RDT 를 보장하기 위해 우루루루 packet 을 보내고
유실되는 패킷들을 위해 Go Back N (GBN) , Selective Repeat 기능이 있다.
GBN , Selective Repeat 모두 sender 가 window 형태로 패킷들을 우루루 쏟아붓는다는 공통점이 있지만
GBN 의 경우엔 유실된 패킷이 있을 경우, 유실된 패킷 이후의 패킷을 몇 개를 전송을 했든 상관 없이 유실된 패킷부터 다시 윈도우를 구성해서 재전송한다.
Selective repeat 의 경우엔 receiver 도 buffer 형태로 받은 패킷들을 저장하며 유실된 패킷만 재전송 받은 후 윈도우를 이동시킨다는 차이점이 존재한다.
TCP
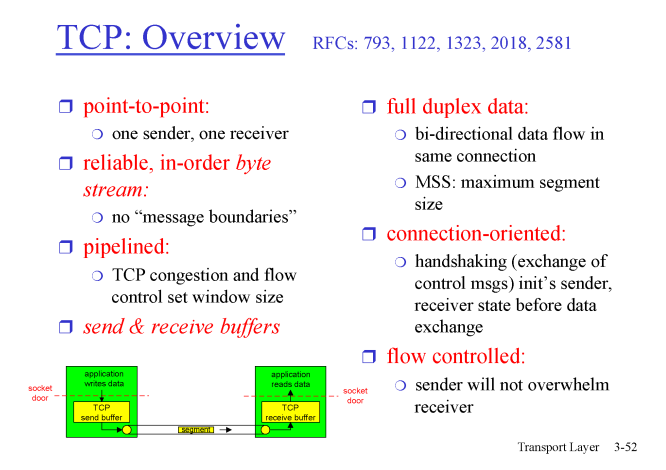
TCP는point to point로sender , recevier의 소켓 한 쌍을 묶어 데이터를 주고 받는다.reliable, in-order byte stream: 유실되는 데이터 없이 모든 데이터의 순서를 유지한 채 보낸다.full duplex data: 양방향 데이터 전송으로 한 명이 영원한sender가 아니라recevier가 되기도 함
- 예를 들어 클라이언트는 HTTP 요청을 보내는sender이면서 서버로부터response를 받는receviersend & recevier buffers: 둘 모두window크기 만큼 데이터를 저장하고 전송하며 둘 모두buffer를 가지고 있음
-sender는 윈도우 사이즈만큼 데이터를 전송하기 위해reciever는out-of-order되는 데이터를 버리지 않기 위해
flow control: 윈도우 사이즈만큼 붓긴 붓지만 리서버 버퍼에 자리가 없으면 리시버의 소화 능력에 알맞게 데이터를 보냄congestion control: 네트워크 상황에 맞춰 데이터를 전송함
어플리케이션 레이어의 전송 단위 : 메시지
트랜스포트 레이어의 전송 단위 : 세그먼트 (헤더와 데이터로 이뤄진)
네트워크 레이어의 전송 단위 : 패킷 (헤더와 데이터 (트랜스포트 레이어의 세그먼트))
링크 레이어의 전송 단위 : 프레임 (헤더와 데이터 (네트워크 레이어의 패킷))
편지와 편지 봉투가 편지 봉투에 담기고 담기고 ... 쭉쭉 엄청 큰 서류봉투 형태로 전송
TCP 헤더의 구성 단위
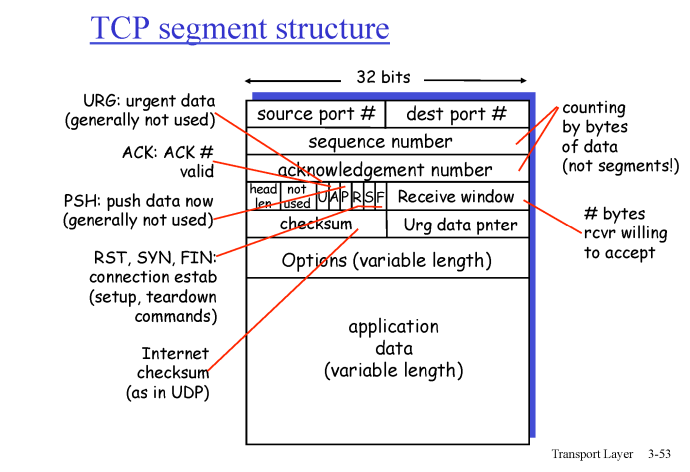
세그먼트의 너비는 32비트이다.
소스 포트 번호: 세그먼트 / 2 로 16비트이다.
- 통신에 가능한 포트 너버는 0~ 2^16로 6만개 정도도착지 포트 번호: 세그먼트 / 2 로 16비트이다.
- 통신에 가능한 포트 너버는 0~ 2^16로 6만개 정도seqeunce numberacknowledgement numberchecksum: 주고 받은 세그먼트의 에러가 있는지 없는지receive window
... 등등
TCP 통신 시나리오
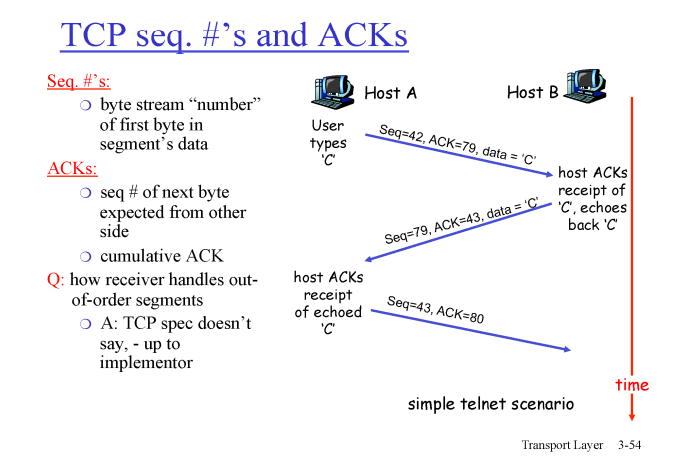
만약 동일한 데이터를 1비트 단위로 주고 받는 통신이 있다고 해보자
HOST A , HOST B 간의 양방향 통신이기 때문에 둘 모두 send buffer , recevier buffer 를 가지고 있다.
맨 첫 상황
HOST A의 send buffer 에는seq #가 42 인 세그먼트가 담겨져있으며 receive buffer 에는seq #가 78 인 세그먼트까지 받았음
==>seq 42 , ACK 79를HOST B에게 전송
HOST A: 야HOST B, 너의send buffer에서seq # 가 79인 세그먼트를 넘겨, 내가 보내는segment 의 seq # 는 42야.
두 번째 상황
HOST B의 send buffer 에는seq #가 79인 세그먼트가 담겨져있으며 receive buffer 에는seq #가 42인 세그먼트까지 받았음
==>seq 79, ACK 43을HOST A에게 전송
HOST B: 야HOST A, 너의send buffer에서seq # 가 43인 세그먼트를 넘겨, 내가 보내는segment 의 seq # 는 79야
이런 식으로 진행되며 각 컴퓨터의 seqeunce number 는 보내고자 하는 세그먼트에 담긴 비트들의 시작주소 이다.
서로 패킷을 통해 데이터를 주고 받을 때 패킷의 헤더 영역에 seq , ACK num 을 같이 보내 서로의 통신을 확인한다.
Timeout
TCP 에서 packet loss 를 막기 위해 사용하는 방법이 timeout 이였다.
내가 보낸 packet 에 대한 feedback 이 어느정도 없을 경우 유실된 걸로 간주하고 다시 그 packet 을 보냈다.
그럼 그 어느정도를 어떻게 규정할까 ?

RTT 보다 타임아웃을 길게 한다면 유실은 막을 수 있지만 너무 길다면 유실된 정보를 늦게 알아차린다.
RTT 보다 타임아웃을 짧게 설정한다면 premature timeout 이 발생하여 불필요한 데이터 재전송이 발생한다.
RTT: round trip time 의 준말로 sender 가 보낸 패킷으로부터 recevier 에게 ACK 를 받을 때 까지 걸리는 시간
제일 효율적인 timeout 시간을 위해서는 RTT 보다 늦으면서 매우 근접한 시간이여야 빠르게 유실을 알아차릴 수 있을 것이다.
하지만 packet 별로 RTT 시간이 다르다. 세그먼트 별로 지나가는 경로(라우터)가 다를 수도 있고 경로가 같더라도 네트워크 상황이 다를 수 있기 때문(큐잉 딜레이)이다.
EstimatedRTT

와우 지수 평활법을 이용해서 RTT 시간을 예측한다.
지수 평활법 : 이전까지의 값을 이용하여 현재의 값을 예측하는 방법
값이 클 수록 이전에 추정된estimatedRTT보다 현재의 실제 왕복 시간인sample RTT를 높게 취급한다.
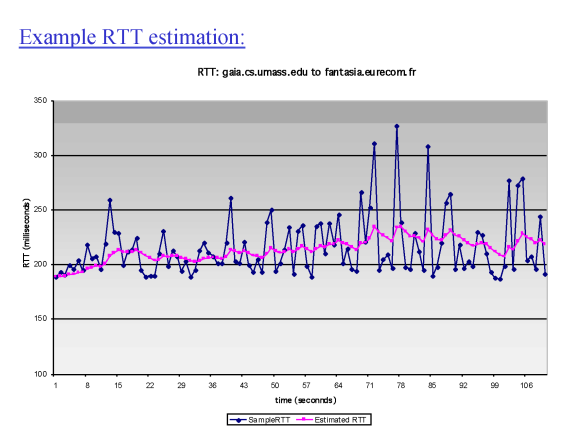
다만 다음처럼 했을 경우 분홍색 선 은 추정된 RTT 값이고 파란색 선은 실제 RTT 값이다.
다음처럼 지수평활법을 이용해서만 구했을 때에는 premature timeout이 일어날 가능성이 높다.

그래서 어느정도의 편차(마진)을 붙여 예측된 RTT 값을 보정해준다.
예측된 RTT 값 + 편차 * 4
Reliable data transfer


복습 할 때 읽어보고 ~~
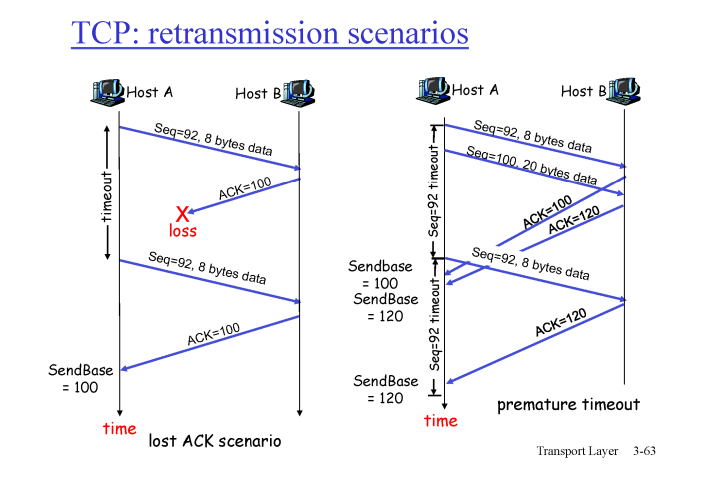
좌측의 경우
- HOST A 에서 seq # 가 92 인 8비트 패킷을 보냈으니 HOST B 에선 92 ~99 까지 수신한다.
- 99까지 받았으니 100 내놔 ==> ACK 100 보냄
- ACK 100 오다가 유실됨
- sender 는 seq # 92 재전송
- recevier 는 무시하고 ACK100 전송
우측의 경우
- HOST A 에서 seq 92 보냄
- HOST B seq 92 받고 ACK 100보냄
- HOST A 에서 seq 100 보냄
- HOST B 에서 seq 100 받고 ACK 120보냄
- HOST A 에서 ACK 100 받기 전에 타임 아웃 발생해서 seq 92 다시 보냄
- HOST B : 응 ~ 안받아 seq 120 내놔
- HOST A에서 ACK 100 , ACK 120 받았으니 리시버가 seq 119 까지 가지고 있다는거를 눈치채고 seq 120 전송함
cumalative ACK 의 장점이다. ACK (n) 이 날라온다면 n까지는 모두 잘 받았다는 거니까
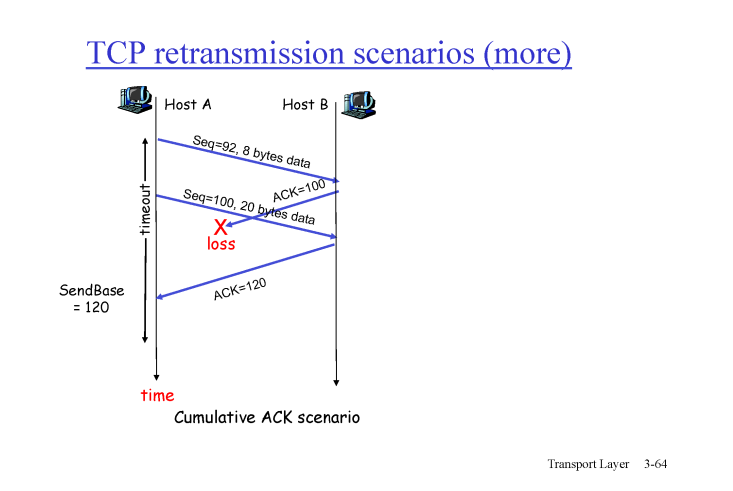
마지막 경우
- HOST A seq 92 보냄
- HOST B 잘 받았다고 ACK 100 보냈는데 유실됨
- HOST A 는 seq 92 의 타임아웃 이전에 seq 100 보냄
- HOST B 잘 받았다고 ACK 120보냄
- seq 92 에 대한 타임아웃이 발생해도 HOST A 는 ACK 가 120이니까 재전송 안함
중요한 예외 케이스
HOST A 측에서 100개의 세그멘테이션을 보낸다고 가정해보자 (seq # 는 1~99까지)
HOST A 에서 100개를 HOST B 한테 호다다다닥 쏟는데
이 중 10번째 페킷이 유실되었다고 가정해보자
그리고 타임아웃 기간이 꽤나 길어서 100개의 RTT 시간보다 짧다고 가정해보자
그럼 HOST A 측에선 10번째 패킷이 유실되었다는 사실을 타임아웃이 지나야만 알 수 있을까 ?
노노농
HOST B 입장에선 9번까지 받을 때 ACK 1 , 2 , ... 9 까진 보낼것이다
그리고 10번은 못받았고
11번부터 계속 받아도 ACK 는 계속 10, 10, 10 .. 계속 애타게 seq 10 인 패킷만을 찾을 것이다.
(리시버 버퍼에선 10 이후의 패킷들은 차곡 차곡 윈도우에 쌓고 있을 것이다. 다만 ACK10을 외칠 뿐)
그래서 동일한 ACK 가 3번 이상 오면 유실 된 것으로 가정해도 된다고 권고한다고 한다. 이런 것을
fast retransmission이라고 한다.
정리
-
TCP 가 보내는 페킷의 헤더에는 다양한 정보들이 있으며 그 곳에는 시퀀스 넘버와 ACK 넘버가 존재한다
- 왜냐면 TCP 통신을 하는 두 OS 는 패킷을 받기도, 주기도 해야 하니까- 이런 것을
full duplex data라고 하며 상호 통신이 가능
- 이런 것을
-
TCP에서는send buffer , receive buffer가 존재하며 seq 넘버는 send buffer 에 담긴 첫 번째 비트의 주소가 된다. -
ACK 넘버는 cumualtive ACK 로 n-1 까지 받았으면 ACK N 을 보내게 된다.
- 그러니 ACK N 을 받았으면 N 전까지의 페킷은 모두 받았다는 이야기sender측에서는ACK N을 받으면 N 이전의 페킷들은 신경 쓸 필요가 없다.
-
TCP 에서는 내가 보낸 페킷이 유실되었다는 것을 타이머를 통해서 눈치 채게 된다.
-
이 때 타이머는 RTT 보다 짧을 경우 조기 타임아웃으로 인해서 불필요한 페킷을 중복되어서 보내게 된다. (리시버는 중복된거 받아도 그냥 안받고 처리해버림)
-
그럼으로 타임아웃 기간은 RTT 보다 어느정도 길게 만들어야 하는데 이를 위해 지수 평활법으로 RTT 시간을 예측하고 어느 정도의 마진을 붙여 RTT 시간을 예측한다.
-
sender 는 유실된 페킷에 대해서 타임아웃이 터지면 유실된 페킷만 다시 재전송 한다.
- 리시버 입장에선 유실된 것 외에 리시버 버퍼에 차곡 차곡 담아놨다.- 유실된게 들어와서 리시버 버퍼가 꽉 차게 되면 차곡 차곡 담긴 리시버 버퍼의 크기에 맞게 ACK 번호가 슝 올라간다.
-
Cumaulative ACK 의 장점
- 만약 ACK 신호가 유실되었다고 가정해보자- 그럼 센더 입장에선 그 유실된 신호에 반응하기 위해서 타임아웃 기간까지 기다려야 할까 ?
- 노노 만약 N 번째 페킷이 유실되었다면 반복적으로 ACK N, ACK N ,ACK N 을 받을테니 몇 번 이상 동일한 ACK 가 날라온다면 N 번째 페킷이 유실된걸로 알고 재전송 하면 된다.
