Database 기초 이해
- 데이터를 저장 및 보존 하는 시스템
- Application에서는 데이터가 메모리 상에서 존재한다. 그리고 메모리에 존재하는 데이터는 보존이 되지 않는다. 해당 Application이 종료하면 메모리에 있던 데이터들은 다시 읽어 들일 수 없다.
- 그럼으로 데이터를 장기 기간동안 저장 및 보존하기 위해서 데이터베이스를 사용하는 것이다.
- 일반적으로 database에는 크게 관계형 데이터베이스(RDBMS)와 "No SQL"로 명칭되는 비 관계형(Non- relational) database가 있다.
관계형 데이터베이스(RDBMS, Relational DataBase Management System)
- 이름 그대로, 관계형 데이터 모델에 기초를 둔 데이터베이스 시스템을 말한다.
- 관계형 데이터란 데이터를 서로 상호관련성을 가진 형태로 표현한 데이터를 말한다.
- 모든 데이터들은 2차원 테이블(table)들로 표현된다.
- 각각의 테이블은 컬럼(column, 행)과 로우(row, 열)로 구성된다.
- 컬럼은 테이블의 각 항목을 말한다. 행으로 생각하면 된다.
- 로우는 각 항목들의 실제 값들을 이야기 한다. 열로 생각하면 된다.
- 각 로우는 저만의 고유 키 (Primary Key, PK)가 있다. 주로 이 PK를 통해서 해당 로우를 찾거나 인용(reference)하게 된다.
- 각각의 테이블들은 서로 상호관련성을 가지고 서로 연결될 수 있다.
- 테이블 끼리의 연결에는 크게 3가지 종류가 있다.
- 1 : 1
- 1 : Many
- Many : Many
- 테이블 끼리의 연결에는 크게 3가지 종류가 있다.
- 대표적인 관계형 데이터베이스에는 MySQL과 PostgreSQL (Postgres)가 있다.
1 : 1
- 테이블 A의 로우와 테이블 B의 로우가 정확히 일대일 매칭이 되는 관계를 one to one 관계라고 한다.
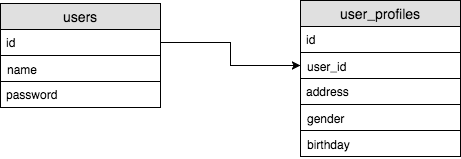
users and user_profiles - one to one
1 : Many
- 테이블 A의 로우가 테이블 B의 여러 로우와 연결이 되는 관계를 one to many 관계라고 함.
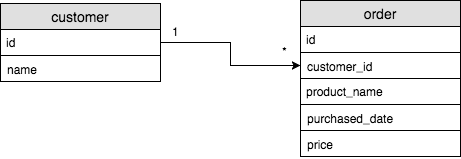
각 고객은 여러 제품을 구매할 수 있지만 구매된 제품의 주인은 오직 한 고객 뿐이다 - one to many
Many : Many
- 테이블 A의 여러 로우가 테이블 B의 여러 로우와 연결이 되는 관계를 Many to Many 라고함.

책은 여러 작가에 의해 쓰일 수 있고 작가들은 여러 책을 쓸 수 있다. - Many to Many
어떻게 테이블과 테이블을 연결하는가?
- Foreign Key (외부키, 외래키, FK)라는 개념을 사용하여 연결
- 앞서 예시인 1 : 1 에서 user_profiles 테이블의 user_id 칼럼은 users 테이블에 걸려있는 외부 키라고 지정한다.
- 즉 데이터베이스에게 user_id의 값은 user 테이블의 id 값이며 그러므로 users 테이블의 id 컬럼에 존재하는 값만 생성될 수 있다.
- 만일 users 테이블에 없는 id 값이 user_id에 지정되면 에러가 난다.
왜 테이블들을 연결하는가?
- 하나의 테이블에 모든 정보를 다 넣으면 동일한 정보들이 불필요하게 중복되어 저장된다.
- 이는 곧 더 많은 디스크를 사용하게 되고
- 잘못된 데이터가 저장 될 가능성이 높아진다.
- 예를 들어, 고객의 아이디는 동일한데 이름이 틀린 로우들이 있다면 어떻게 해야 하는가? 어떤 이름이 정확한 이름인가?
- 여러 테이블에 나누어서 저장한 후 필요한 테이블 끼리 연결 시키면 위의 두가지 문제가 사라진다.
- 중복된 데이터를 저장하지 않으로 디스크를 더 효율적으로 쓰고
- 서로 같은 데이터지만 부분적으로 틀린 데이터가 생기는 문제가 없어진다.
- 이것을
normalization (졍규화)라고 한다.
ACID (Atomicity, Consistency, Isolation, Durability)
- 원자성, 일관성, 고립성, 지속성
Atomicity - 원자성
- 트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장하는 능력
- 예를 들어, 자금 이체는 성공할 수도 실패할 수도 있지만 보내는 쪽에서 돈을 빼 오는 작업만 성공하고 받는 쪽에 돈을 넣는 작업을 실패해서는 안된다.
- 중간 단계 까지 실행되고 실패하는 일이 없도록 하는 것
Consistency - 일관성
- 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 데이터베이스 상태로 유지하는 것을 의미
- 무결성 제약이 모든 계좌는 잔고가 있어야 한다면 이를 위반하는 트랜잭션은 중단된다.
Isolation - 고립성
- 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것
- 트랜잭션 밖에 있는 어떤 연산도 중간 단계의 데이터를 볼 수 없음을 의미한다.
- 예를 들어, 은행 관리자는 이체 작업을 하는 도중에 쿼리를 실행하더라도 특정 계좌간 이체하는 양 쪽을 볼 수 없다.
- 공식적으로 고립성은 트랜잭션 실행내역은 연속적이어야 함을 의미한다.
- 성능관련 이유로 인해 이 특성은 가장 유연성 있는 제약 조건이다.
Durability - 지속성
- 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미한다.
- 시스템 문제, DB 일관성 체크 등을 하더라도 유지외어야 함을 의미한다.
- 모든 트랜잭션은 로그로 남고 시스템 장애 발생 전 상태로 되돌릴 수 있다.
- 트랜잭션은 로그에 모든 것이 저장된 후에만 commit 상태로 간주될 수 있다.
💡트랜잭션 (Transaction)
일련의 작업들이 마치 하나의 작업처럼 취급되어서 모두 다 성공하거나 아니면 모두 다 실패하는걸 이야기 한다.
NoSQL 데이터 베이스
- 비 관계형 타입의 데이터를 저장할때 주로 사용되는 데이터베이스 시스템
- 관계형 데이터베이스와 다르게 비관계형 이기 때문에 데이터들을 저장하기 전에 정의 할 필요가 없다.
👉 관계형 데이터베이스는 데이터들을 저장하기 전에 어디에 어떻게 저장할 것 인지를 정의해야 한다.
👉 즉, 테이블을 정의해야 한다. (테이블 이름, 테이블 관계, 각 컬럼의 타입 등...) - MongoDB, Redis, Cassandra 등이 가장 대표적인 NoSQL 데이터 베이스
💡 SQL(RDBMS) vs NoSQL
SQL
- 장점
- 데이터를 더 효율적으로 그리고 체계적으로 저장할 수 있고 관리 할 수있다.
- 미리 저장하는 데이터들의 구조(테이블 스키마)를 정의 함으로 데이터의 완전성이 보장된다.
- 트랜잭션
- 단점
- 테이블을 미리 정의해야 함으로 테이블 구조 변화 등에 덜 유연하다.
- 확장성이 쉽지 않다.
👉 테이블 구조가 미리 정의되어 있어 단순히 서버를 늘리는것 만으로 확장하기가 쉽지 않고
서버의 성능 자체도 높아야 한다.
👉 서버를 늘려서 분산 저장하는 것도 쉽지 않다.
👉 Scale up (서버의 성능을 높이는 것)으로 확장성이 된다.- 정형화된 데이터들 그리고 데이터의 완전성이 중요한 데이터들을 저장하는데 유리하다.
👉 전자상거래 정보, 은행 계좌 정보, 거래 정보 등등No SQL
- 장점
- 데이터 구조를 미리 정의하지 않아도 됨으로 저장하는 데이터의 구조 변화에 유연한다.
- 확장하기가 비교적 쉽다. 그냥 서버 수를 늘리면 됨 (Scale out)
- 확장하기가 쉽고 데이터의 구조도 유연하다 보니 방대한 양의 데이터를 저장하는데 유리하다.
- 단점
- 데이터의 완전성이 덜 보장된다.
- 트랜잭션이 안되거나 비교적 불안정하다.
👉 주로 비정형화 데이터 그리고 완전성이 상대적으로 덜 유리한 데이터를 저장하는데 유리하다. (ex. Log 데이터)

🤷♂️