[AWS] MSK
MSK란?
AWS MSK(Amazon Managed Streaming for Apache Kafka)는 Apache Kafka를 사용하여 스트리밍 데이터를 처리하는 애플리케이션의 구축 및 실행을 위해 사용할 수 있는 완전관리형 서비스
- 클러스터 생성, 업데이트, 삭제와 같은 컨트롤 플레인 작업을 제공한다.
따라서 데이터 생성 및 소비와 같은 Apache Kafka 데이터 영역 작업을 사용할 수 있다. - Apache Kafka의 오픈 소스 버전을 실행하기 때문에 Apache Kafka 커뮤니티의 기존 애플리케이션, 도구 및 플러그인이 지원되므로 애플리케이션 코드를 변경할 필요가 없다.
MSK를 사용하지 않으면?
Apache Kafka Cluster를 직접 구성해서 사용해야 한다.
보안 그룹 생성
MSK를 구축하기 위해서는 VPC와 보안 그룹을 생성해야 한다. VPC는 이전에 생성했으니 MSK 내부의 브로커들 간, Kafka Client와 MSK 간의 안전한 통신을 위해 보안 그룹을 생성해보자.
MSK 클러스터용 보안 그룹과 Kafka 클라이언트용 보안 그룹을 생성해야 한다.
1. MSK 클러스터용 보안 그룹 생성
보안 그룹 이름과 VPC만을 지정한다. VPC는 이전에 프로젝트에서 사용하기 위해 생성한 VPC로 지정한다.
보안 그룹 이름 : fms-msk-sg -> ID : sg-0b195764af64bdc85
VPC : fms-pipeline-cym-vpc
2. Kafka 프로듀서용 보안 그룹 생성
동일하게 보안 그룹 이름과 VPC를 지정한다.
보안 그룹 이름 : fms-client-sg -> ID : sg-077fd63c21ff04883
VPC : fms-pipeline-cym-vpc
3. Kafka 컨슈머용 보안 그룹 생성
동일하게 보안 그룹 이름과 VPC를 지정한다.
보안 그룹 이름 : fms-kafka-consumer-sg -> ID : sg-0e47230781dcabde9
VPC : fms-pipeline-cym-vpc
3. 클러스터용 보안 그룹에 인바운드 규칙 추가
카프카는 클라이언트와 브로커 간의 통신뿐만 아니라, 클러스터 내의 브로커들 간 통신에서 모두 TCP 프로토콜을 사용하기 때문에 클러스터 내외부의 통신을 위한 인바운드 규칙을 추가하자.
크게 다음 세가지 규칙이 필요하다.
-
클러스터 내부의 브로커들 간에 통신하기 위한 규칙
클러스터를 구성하는 여러 브로커 노드들이 서로 통신하기 위해 자기 자신(fms-msk-sg)을 소스로 모든 TCP 트래픽을 허용한다. -
카프카 프로듀서가 클러스터에 접속하는 것을 허용하기 위한 규칙
클라이언트용 보안 그룹(sg-077fd63c21ff04883)을 가진 Kafka 프로듀서는 SASL/SCRAM 방식을 통해 클러스터에 접속하므로 TCP 9096의 트래픽을 허용한다. -
카프카 컨슈머가 클러스터에 접속하는 것을 허용하기 위한 규칙
카프카 컨슈머용 보안 그룹(sg-0e47230781dcabde9)을 가진 Kafka 컨슈머는 IAM 방식을 통해 클러스터에 접속하므로 TCP 9098의 트래픽을 허용한다.
하지만 연이은 에러를 만나다보니 사진처럼 온갖 규칙을 지정하게 됐다.^^; (아래 사진에서 체크한 규칙만 필요하다고 생각하여 위에서 세 규칙만 언급했지만 더 필요할 수도 있다...)
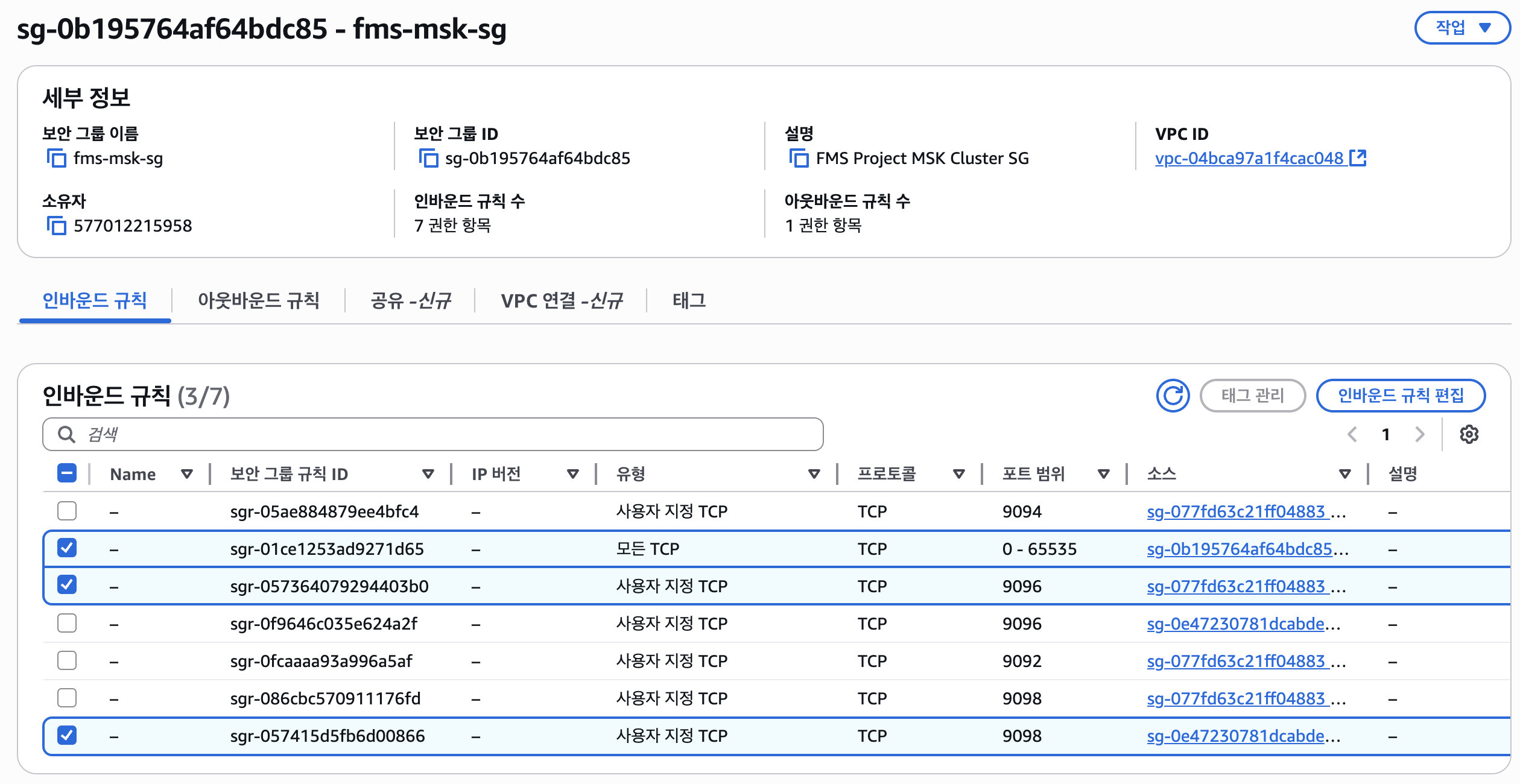
Kafka 프로듀서와 컨슈머가 MSK에 접근하는 것이므로 이들로 들어오는 인바운드 규칙은 지정할 게 없고, MSK 클러스터의 인바운드 규칙만을 지정한다.
MSK 클러스터 구축
이제 진짜 MSK 클러스터를 구축해보자. MSK 클러스터 생성은 크게 4단계로 나뉜다.
1. 클러스터 설정
각각의 세부적인 설정을 직접 할 것이므로 사용자 지정 생성 방식으로 클러스터를 생성한다.
클러스터 유형
프로비저닝됨은 사용자가 직접 브로커의 성능과 개수를 선택하고 그에 대한 비용을 시간당으로 지불하는 방식으로, 서버 자원을 미리 할당받아 사용하는 전통적인 클라우드 방식이다.
반면 서버리스는 AWS가 트래픽에 맞춰 자동으로 리소스를 할당하고 관리하는 방식으로, 클러스터 기본요금 + 실제 데이터 처리량(GB)으로 비용이 산정된다.
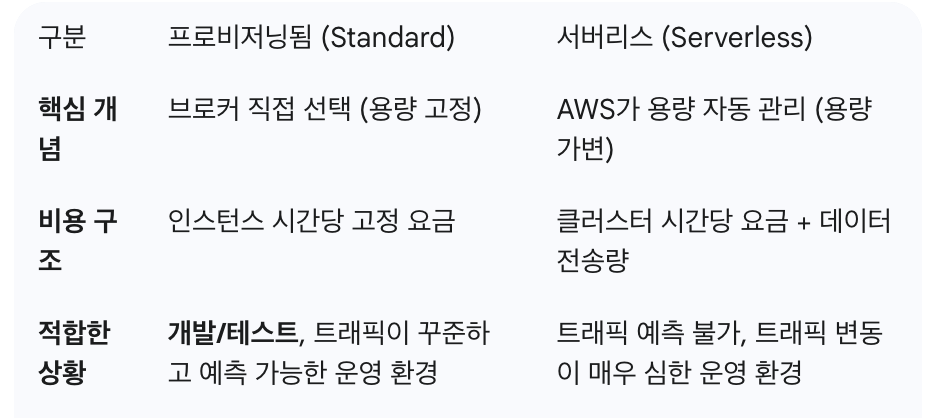
따라서 테스트 단계인 지금은 프로비저닝됨 옵션을 선택하고 추후에 운영 단계에서 서버리스 방식을 고려하려고 한다.
브로커
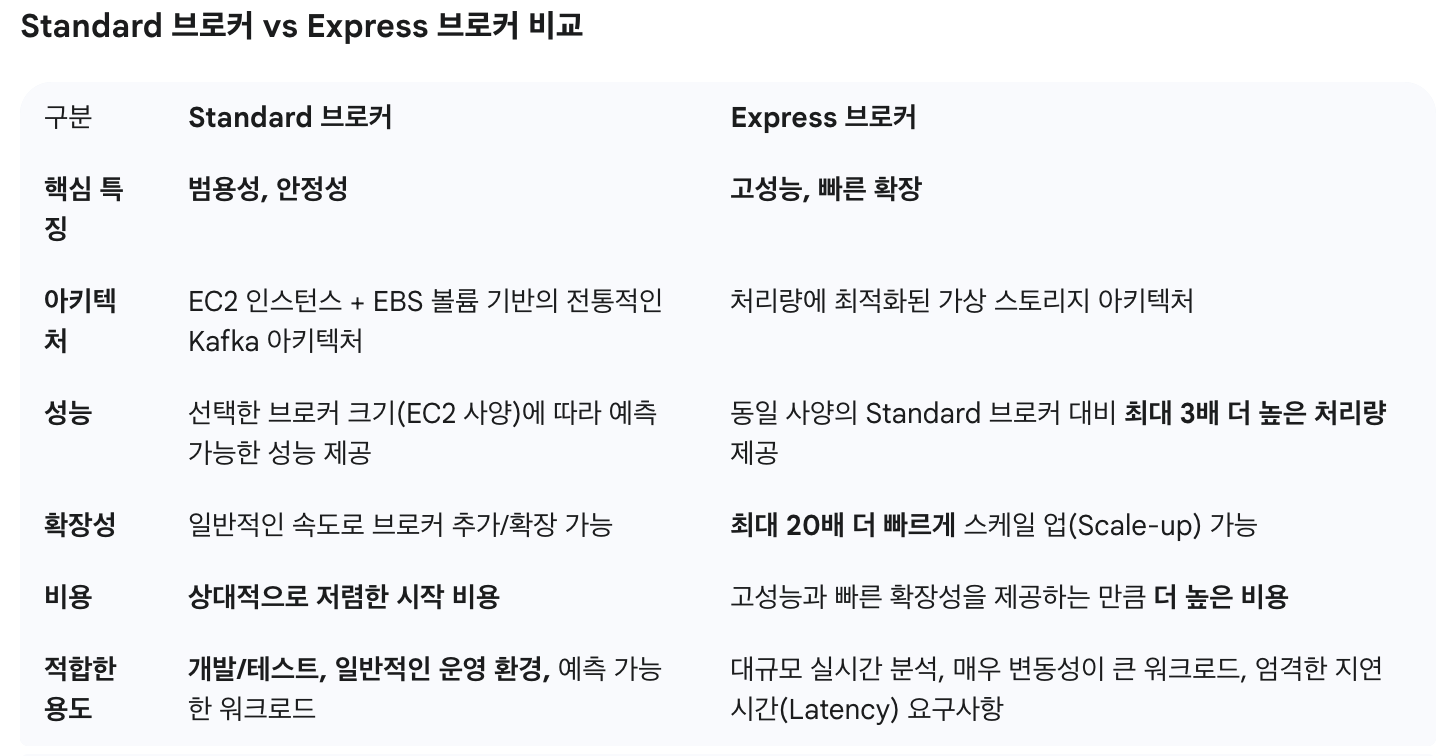
스토리지
스토리지 용량을 결정할 때 고려할 사항은 다음과 같다.
필요한 총 스토리지 = (하루에 들어오는 데이터 양) x (데이터 보관 기간) x (복제 계수) + (버퍼 여유 공간)
-
하루에 들어오는 데이터 양 (Throughput)
-
데이터 보관 기간 (Retention Period)
MSK에 들어온 데이터를 EKS 컨슈머와 Kafka Connect가 실시간으로 다른 저장소(Redis, S3)에 옮기는 프로젝트 구조상 Kafka는 장기 저장소가 아닌, 일시적인 버퍼 역할을 하므로 데이터를 Kafka에 오래 보관할 필요가 없다.
컨슈머나 커넥터에 장애가 발생하여 복구할 시간을 벌기 위해, 일반적으로 1일 ~ 3일이면 충분 -
복제 계수 (Replication Factor)
데이터 안정성을 위해 원본 데이터를 몇 군데에 복제해서 저장할지를 의미한다. 하나의 브로커에 장애가 생겨도 데이터가 유실되지 않도록 보통 3으로 설정합니다.
(즉, 실제 데이터 양의 3배의 공간이 필요한 것)
이 모든 것을 고려하여 스토리지 용량을 결정해야 하지만 현재는 테스트 단계이므로 프로비저닝된 스토리지를 사용하기 위한 최소 용량인 10Gib로 지정했다.
2. 네트워킹
