[25/04/30, 25/05/02 수업 정리본]
기초적인 내용들이어서 약간 지루했지만.. 파이썬으로 코테 보면서 매번 헷갈리던 문법들 정리할 수 있어서 좋았다!
- Literal : 프로그램 상에서 개발자가 직접 입력하는 값, 변수에 넣는 변하지 않는 값
a = 10에서 10이 literal
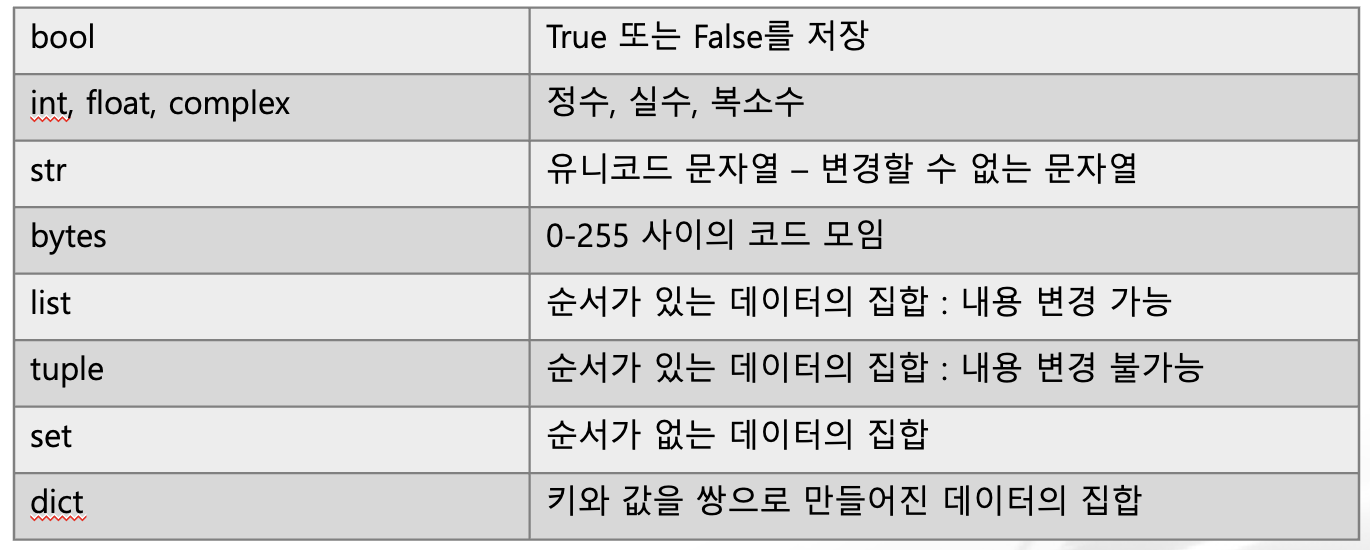
데이터 개수에 따른 분류
- Scala Data : 1개의 데이터
- Vector Data(Collection) : 0개 이상의 데이터
파이썬의 기본 자료형
Scala Data
int
- 문자열을 정수로 변환할 때는
int(문자열)또는int(문자열, 진법) int()안에 문자열 대신 실수를 대입하면 소수를 버림
float
- 파이썬에서는 실수를 지원하기 위해 부동 소수형을 제공한다.
(부동 소수형 : 소수점을 움직여서 소수를 표현하는 자료형) - 부동 소수형은 8바이트를 이용해서 표현하기 때문에 한정된 범위의 수만 표현이 가능하다.
- 디지털 방식으로 소수를 표현해야 하기 때문에 정밀도의 한계가 있다.
round(num, 소수점 이하 자릿수): 반올림(파이썬 내장함수)ceil(num): 올림(math모듈의 함수)floor(num): 내림(math모듈의 함수)
실수의 저장 오류
소수 중에는 정확하게 이진수로 표현할 수 없는 수가 있으므로 다음과 같이 실수 연산은 오차가 발생할 수 있다.
print('0.2 == (1.0-0.8):', (0.2 == (1.0-0.8)))
# >> 0.2 == (1.0-0.8): False
sum = 0
for i in range(0,1000):
sum += 1
print("정수 1을 1000번 더한 결과:" , sum)
# >> 정수 1을 1000번 더한 결과: 1000
sum = 0.0
for i in range(0,1000):
sum += 0.1
print("실수 0.1을 1000번 더한 결과:" , sum)
# >> 실수 0.1을 1000번 더한 결과: 99.9999999999986
Math 모듈의 함수
- pow(x, y) : x의 y승
- sqrt(x) : x의 제곱근
- factorial(x) : 팩토리얼
- fabs(x) : x의 절대값
- gcd(x, y) : x와 y의 최대공약수
Vector Data
sequential Type
객체를 순서대로 저장하는 자료형
종류
-
컨테이너 시퀀스
서로 다른 자료형의 항목들을 담을 수 있는 시퀀스로 list, tuple, collections.deque형이 여기에 포함된다. 객체에 대한 참조를 담고 있으며, 객체는 어떠한 자료형도 될 수 있다. -
균일 시퀀스
동일한 자료형의 데이터를 저장할 수 있는 시퀀스로 str, bytes, bytearray, memoryview, array.array형이 여기에 포함된다. 각 데이터의 크기가 다 동일하기 때문에 객체에 대한 참조 대신 자신의 메모리 공간에 각 항목의 값을 직접 담는다. 그래서 메모리를 더 적게 사용하지만 문자, 바이트, 숫자 등 기본적인 자료형만 저장할 수 있다.두 곳에 다 저장할 수 있다면 균일 시퀀스에 저장하는게 좋다!
ex컨테이너 시퀀스의 경우 : [’s’, ‘t’, ‘r’] → [s의 id, t의 id, r의 id]처럼 참조가 저장됨
ex균일 시퀀스의 경우 : ‘str’ → s, t, r처럼 실제 값이 저장됨 -
가변 시퀀스
list, bytearray, array.array, collections.deque, memoryview형 -
불변 시퀀스
tuple, str, bytes형
str
문자열 자료형
- 내부 데이터를 변경할 수 없다.
- 작업을 할 때 복사해서 수행
- ESCAPE code(제어문자) : 정해진 규칙에서 벗어난 문자를 만들기 위해 미리 정해둔 문자 조합으로 \다음에 하나의 문자를 추가한 형태로 사용한다.
- \n : 줄바꿈
- \t :수평 탭
- \ : 문자 "\"
- \’ :단일 인용부호(')
- \" : 이중 인용부호(")
- 문자열 앞에 r을 붙이면 raw 문자열을 생성할 수 있는데 이때는 escape 문자가 무시된다.
관련 메서드
s = ' nice TO meet you '
# 대소문자 변환 메서드
print(s.upper())
# >> NICE TO MEET YOU
print(s.lower())
# >> nice to meet you
print(s.swapcase())
# >> NICE to MEET YOU
print(s.capitalize())
# >> nice to meet you
print(s.title())
# >> Nice To Meet You
# 문자열 검색 메서드
print(s.count('e'))
# >> 3
print(s.find('e'))
# >> 4
print(s.find('e', 5)) # 5번째 인덱스부터 'e' 검색
# >> 10
print(s.index('e'))
# >> 4
print(s.find('x')) # find는 해당 문자열을 찾지 못했을 경우 -1 반환
# >> -1
print(s.index('x')) # index는 해당 문자열을 찾지 못했을 경우 에러 반환
# >> ValueError: substring not found
print(s.startswith(' '))
# >> True
print(s.endswith('n'))
# >> False
print(s.startswith('n', 5)) # 5번째 인덱스가 해당하는 위치가 'n'으로 시작하는지 검사
# >> False
# 문자열 편집과 치환 메서드
print(s.strip())
# >> nice TO meet you
# 문자열 분리와 결합 메서드
print(s.split())
# >> ['nice', 'TO', 'meet', 'you']
print(s.split('e'))
# >> [' nic', ' TO m', '', 't you ']
print(s.split(' ', 2)) # 문자열을 분리하는 데 2만큼만 분리해서 리스트로 반환
# >> ['', 'nice', 'TO meet you ']
multilines = '''firstline
secondline
thirdline'''
print(multilines.splitlines())
# >> ['firstline', 'secondline', 'thirdline']
print('_'.join(['a', 'b', 'c']))
# >> a_b_c
# 문자열 인코딩
print(ord('A'))
# >> 65
print(chr(65))
# >> Alist
순서를 갖는 객체의 집합으로 내부 데이터의 변경이 가능하다.
- 다른 객체를 직접 저장하지 않고 데이터의 참조만을 저장한다.
- 데이터를 수정할 때 연결된 데이터가 있다면 함께 수정된다.
생성
[ ]: 비어있는 리스트[데이터 나열]: 나열된 데이터를 갖는 리스트list(\__iter\__가 구현된 인스턴스)
항목 교체
리스트[인덱스] = 값리스트[시작위치:종료위치] = [데이터 나열]
데이터 삭제
- 리스트[시작위치:종료위치] = [ ]
- del 리스트[인덱스]
li = [0, 1, 2, 3, 4]
li[1:3] = [0, 0]
print("특정 범위 데이터 교체: ", li)
li[1:3] = []
print("특정 범위 데이터 삭제: ", li)
print ("리스트 결합:", li + li)
print ("리스트 반복:",li * 3)
li.append(5)
print("리스트에 값 추가: ", li)
li.insert(1, 1)
print("원하는 위치에 값 추가: ", li)
li.remove(3)
print("원하는 값 삭제: ", li)
li.pop()
print("마지막 데이터 삭제: ", li)
li.pop(1)
print("원하는 위치의 값 삭제: ", li)
li2 = [4, 4, 4]
li.extend(li2)
print("리스트 추가: ", li)정렬
list.sort() VS sorted(list)
sort()는 list 클래스의 메서드이고 데이터 자체를 정렬
sorted()는 파이썬의 내장 함수이고 원본 데이터는 그대로 두고 정렬된 결과를 반환
datas = ['hi', 'Hello', 'morning', 'afternoon']
datas.sort()
print(datas) # ['Hello', 'afternoon', 'hi', 'morning']
datas.sort(reverse=True)
print(datas) # ['morning', 'hi', 'afternoon', 'Hello']
# key에 설정된 함수를 가지고 데이터를 변환해서 정렬
datas.sort(key=str.upper, reverse=True)
print(datas) # ['morning', 'hi', 'Hello', 'afternoon']
# sorted 사용
print(sorted(datas)) # ['Hello', 'afternoon', 'hi', 'morning']
print(datas) # ['morning', 'hi', 'Hello', 'afternoon']list의 대안
1. 배열
많은 양의 실수를 저장해야 할 때에는 list보다 배열이 효율적이다. float 객체 대신 C 언어의 배열과 마찬가지로 기계가 사용하는 형태로 표현된 바이트값만 저장하기 때문이다.
2. deque
삽입과 삭제가 양방향 모두에서 가능한 양방향 큐로, 양쪽 끝에 계속 추가하거나 삭제하면서 FIFO 구조나 LIFO 구조를 표현할 때 사용하면 효율적이다.
양 끝 요소의 append와 pop이 압도적으로 빠르다.
- 리스트의 경우 : O(n)
- deque의 경우 : O(1)
## 개수가 한정된 리스트를 만들고 싶으면 maxlen을 지정한 deque 사용
from collections import deque
history = deque(maxlen=3)
history.append(1)
history.append(2)
history.append(3)
history.append(4)
print(history)
## deque([2, 3, 4], maxlen=3)3. queue
queue 모듈에서는 동기화된 queue, LifoQueue, PriorityQueue 클래스를 제공하는데, 이는 스레드 간에 안전하게 통신하기 위해 사용된다.
queue.Queue(maxsize): 선입 선출 큐 인스턴스 생성queue.LifoQueue(maxsize): 후입 선출 큐 인스턴스 생성(스택)queue.PriorityQueue(maxsize): 우선 순위 큐 인스턴스 생성, 입력되는 아이템의 형식은 (순위, 아이템)의 튜플로 입력되며 우선순위는 작을수록 높은 순위를 가짐
멀티 스레드 환경을 고려하여 작성되었기에 여러 스레드가 동시에 queue 모듈에 데이터를 저장하고 꺼내도 정상적으로 작동하는 것을 보장한다.
put_nowait(item): 블로킹(blocking)없이 큐 인스턴스에 아이템을 입력
큐 인스턴스가 꽉 차 있는 경우에는queue.Full예외 발생get_nowait(): 블로킹(blocking)없이 큐 인스턴스에 들어있는 아이템을 반환
큐 인스턴스에 아이템이 없는 경우에는queue.Empty예외 발생
import queue
li=['GD','대성','태양']
singer=queue.Queue()
#singer=queue.LifoQueue()
for x in li:
singer.put(x)
idx = 0
size = singer.qsize()
while idx < size:
print(singer.get(idx))
idx = idx + 1
# >> GD
# >> 대성
# >> 태양
# LifoQueue의 경우에 LFIO로 출력
# >> 태양
# >> 대성
# >> GD
# 우선순위 큐
singer=queue.PriorityQueue()
singer.put((37, 'GD'))
singer.put((37, '태양'))
singer.put((26, '대성'))
idx = 0
size = singer.qsize()
while idx < size:
print(singer.get(idx))
idx = idx + 1
# >> (26, '대성')
# >> (37, 'GD')
# >> (37, '태양')tuple
임의 객체들이 순서를 가지는 모임으로 리스트와 유사한 구조이며 접근 방법도 동일하다.
내부 데이터의 변경이 불가능
생성
(10, 20, 30)10, 20, 30괄호 없이 ,로 구분해서 데이터를 나열해도 튜플로 처리됨(10,)하나의 데이터를 가지고 생성할 때는 뒤에 ,를 붙여준다tuple(다른 순차형 데이터)
특징
- unpacking
list와 tuple은 데이터를 나누어서 저장하는 것이 가능하다.
데이터를 나눌 때 을 사용하면 이 없는 곳에 나누어지고 남은 데이터들은 list로 만들어서 대입한다. - 조건에 따라 다른 값 대입
(다른 2개의 데이터 나열)[조건]
조건이 True이면 뒤의 데이터가, False이면 앞의 데이터가 대입된다. - 함수의 리턴타입으로 사용하거나, 조작이 일어나서는 안되는 데이터를 분석할 때 많이 사용한다.
## 생성 ##
li = [1, 2, 3]
tu = (1, 2, 3)
li[0] = 4
# tu[0] = 4 # 튜플은 데이터 수정이 불가능
# >> TypeError: 'tuple' object does not support item assignment
# 괄호 없이 데이터를 나열하면 튜플 타입이 됨
withoutparentheses = 1, 2, 3
print(withoutparentheses)
# >> (1, 2, 3)
# 데이터가 하나인 튜플을 만들 때는 ,를 찍어주기
onlyone = (3,)
print(onlyone)
# >> (3,)
## unpacking ##
a, b, c = tu
print(c)
# >> 3
a, b = tu # ValueError: too many values to unpack (expected 2)
# 대입하지 않을 데이터는 _로 매칭
a, b, _ = tu
print(b)
# >> 2
# *은 나머지 전부를 list로 만들어줌
a, *b = tu
print(b)
# >> [2, 3]
## tuple을 if-else 문처럼 사용하기 ##
score = 80
result = ("합격", "불합격")[score < 60]
print(result)
# >> 합격- collections 모듈의
namedtuple()함수는 필드명과 클래스명을 추가한 튜플의 서브 클래스를 생성하는 함수로서 디버깅할 때 유용하다.- 속성을 객체마다 존재하는
__dict__에 저장하지 않으므로 일반적인 객체보다 메모리를 적게 사용한다. - 파이썬에서 DTO(Data Transfer Object)나 VO(Variable Object)를 만들 때 일반 클래스로 만들기도 하고 dict나 namedtuple을 이용하기도 한다.
- 속성을 객체마다 존재하는
# 일반적으로 DTO/VO를 만드는 형태
class DTO :
def __init__(self, num=0, name="noname", age=1):
self.num = num
self.name = name
self.age = age
dto = DTO(1, '철수', 25)
# tuple을 이용해서 DTO/VO 만들기
from collections import namedtuple
# 첫 번째 매개변수로 이 클래스의 설명 대입, 두번째 매개변수로 문자열로 필드명을 공백과 함께 나열
VO = namedtuple('VO', 'num name age')
vo = VO(1, '철수', 25)
print(vo.num)
print(vo.name)
print(vo.age)
# >> 1
# >> 철수
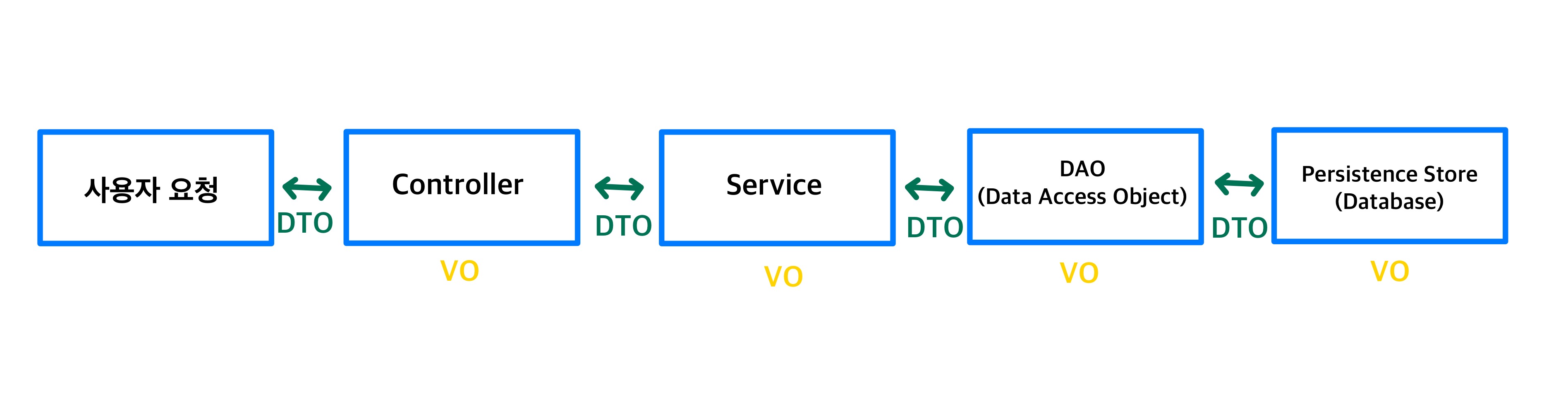
# >> 25🤔 DTO? VO?
애플리케이션에서 사용자 요청이 들어오면 Controller는 서비스 로직을 호출하고, 데이터 접근이 필요한 경우 Service는 DAO를 호출하는 등 계층 간 책임에 따라 로직을 처리한다.
이러한 구조에서 계층 간 데이터 전달을 위해 사용하는 객체가 DTO(Data Transfer Object)이며, 값 자체의 동일성과 의미를 표현하기 위한 불변 객체는 VO(Value Object)라 한다.
exController가 사용하는 VO, Service가 사용하는 VO
set
데이터를 순서에 상관없이 중복없이 저장하는 자료구조로, 내부 데이터를 변경할 수 있는 set과 변경할 수 없는 frozenset을 제공한다.
-
순서가 없는 set은 hash 함수를 통해 데이터의 저장 위치가 결정된다.
-
똑같은 앱이 2개 이상 깔릴 수 없고, 순서가 없는 스마트폰의 앱은 set으로 관리된다.
⭐️ 순서가 없는게 순서가 있는 것보다 빠르다!
ex43 / 333 / 53에 대해서 각각 %3 연산을 하면
[0] : 333
[1] : 43
[2] : 53
처럼 순서없이 저장되기 때문에 모든 데이터의 접근 속도가 동일한 것!
Q. 43이 있냐? 43 % 3 ⇒ 1, 1에 접근했는데 있군..
Q. 73이 있냐? 73 % 3 ⇒ 1, 1에 접근했는데 없군..
생성
set(): 비어있는 상태 ({ }이 아닌 set()으로 생성하는 이유는 dict와의 혼동을 방지하기 위함)set(데이터): 다른 자료형을 가지고 생성(튜플, 문자열, 리스트, 딕셔너리로부터 생성 가능){데이터 나열}: 기본 데이터를 가지고 생성
hashset = set()
print(hashset)
# >> set()
hashset = set('Hello World')
print(hashset)
# >> {'d', 'H', 'l', 'W', ' ', 'o', 'e', 'r'}관련 메서드
data1 = {1, 2}
data1.add(5)
print("데이터 추가 : ", data1)
# >> 데이터 추가 : {1, 2, 5}
data1.update([1, 2, 3, 4, 5])
print("데이터 업데이트 : ", data1)
# >> 데이터 업데이트 : {1, 2, 3, 4, 5}
data2 = data1.copy()
data1.discard(1)
print("수정한 원본 데이터 data1 : ", data1)
# >> 수정한 원본 데이터 data1 : {2, 3, 4, 5}
print("data1의 복사본 data2 : ", data2)
# >> data1의 복사본 data2 : {1, 2, 3, 4, 5}
data1.discard(1) # 삭제하려는 데이터가 없어도 에러 X
# data1.remove(1) # KeyError: 1
data1.pop()
print("데이터 1개 제거 : ", data1)
# >> 데이터 1개 제거 : {3, 4, 5}
a = {1, 2, 3, 4, 5}
b = {4, 5, 6, 7, 8}
print(a.union(b))
# >> {1, 2, 3, 4, 5, 6, 7, 8}
print(a.intersection(b))
# >> {4, 5}
print(a.difference(b))
# >> {1, 2, 3}
print(a.symmetric_difference(b))
# >> {1, 2, 3, 6, 7, 8}
a.intersection_update(b)
print("intersection_update : ", a)
'''
update(), intersection_update(), difference_update(),
symmetric_difference_update() 메서드는 호출하는 객체의 데이터를 업데이트한다.
'''dict
key와 value를 쌍으로 저장하는 자료형
생성
{ },dict(): 비어있는 상태{키:값, 키:값, …}: 데이터를 가지고 생성dict(zip(키의 리스트, 값의 리스트)): 키의 리스트(list, set, tuple)나 값의 리스트가 존재하는 경우
키를 이용해서 값 가져오기
딕셔너리[키] 또는 get 메서드 이용
딕셔너리[키]는 키가 존재하지 않는 경우 에러get(키, 기본값)은 키가 없으면 기본값을 리턴
데이터 삽입/수정
딕셔너리[키] = 값
없으면 생성되고 있으면 수정된다.
키가 set으로 만들어지기 때문에 키는 중복 생성이 X
관련 메서드
-
keys(),values(),items()메서드를 이용해서 키의 집합, 값의 집합, 키와 값을 튜플로 리턴 -
del 딕셔너리[키]: 데이터 삭제 -
popitem()마지막 하나의 데이터를 반환하고 제거 -
clear(): 모든 데이터 삭제
dict1 = {'num': 3, 'name': '철수', 'age': 25}
dict1['house'] = '강남'
print(dict1['name'])
# >> 철수
# 이 방식의 접근은 키가 없으면 에러
# print(dict1['name1']) # KeyError: 'name1'
# 이 방식의 접근은 키가 없으면 기본값을 리턴
print(dict1.get('email', '키가 없습니다.'))
# >> 키가 없습니다.
# dict는 순회를 하면 키의 값이 순차적으로 리턴됨
for k in dict1 :
print(k)
# >> num
# >> name
# >> age
# >> house
keys = ['one', 'two', 'three']
values = (1,2,3)
dic = dict(zip(keys, values))
for key in dic:
print(key,":", dic[key])
# >> one : 1
# >> two : 2
# >> three : 3MVC 패턴에서 유용한 dict
🤔 MVC 패턴?
Model: 실제 비즈니스 로직
View: 화면에 보여지는 부분
Controller: 둘 사이를 연결해주는 부분
⇒ 이 부분을 나눠서 구현하고 하나의 변화가 다른 하나에 영향을 거의 미치지 않도록 하는 프로그래밍 방식# java 방식 class DTO : def __init__(self, num=0, name="noname", age=1): self.num = num self.name = name # 이 부분(Model)을 self.irum으로 바꾸면 print문(View)도 dto.irum으로 수정해야 함 self.age = age dto = DTO(1, '철수', 25) print(dto.num) # >> 1 print(dto.name) # >> 철수 # >> self.ifum으로 수정하면 AttributeError: 'DTO' object has no attribute 'name' print(dto.age) # >> 25 # # python 방식 vo = {'num': 1, 'irum': '철수', 'age': 25} for key in vo : print(vo[key]) # >> 1 # >> 철수 # >> 25 # key 이름을 직접쓰지 않았기 때문에 key 이름을 수정해도 에러없이 출력됨 # # 간단하고 빠르게 만들기 위해서 파이썬을 많이 사용하는데 # 이유는 위처럼 Model의 수정이 잦아도 View에 끼치는 영향이 java보다 비교적 적기 때문
enumerate
인덱스와 원소를 동시에 접근하면서 루프를 돌릴 수 있도록 해주는 내장 함수
- list, set, tuple → 인덱스와 데이터 리턴
- dict → 인덱스와 키 리턴
for idx, element in enumerate(['A', 'B', 'C']):
print(idx, element)
# >> 0 A
# >> 1 B
# >> 2 C
for idx, key in enumerate({'name':'adam', 'address':'mokdong'}):
print(idx, key)
# >> 0 name
# >> 1 addresscomprehension
반복 가능한 객체(iteralbe)들을 이용해서 새로운 반복 가능한 객체(list, tuple, set, dict 등)를 축약한 형태로 생성하는 방법
li1 = ['군계일학', '쥬니', '헨리']
li2 = [nick for nick in li1]
print(li2)
# >> ['군계일학', '쥬니', '헨리']
# 이차원 lsit를 가지고 일차원 list를 생성
# map보다도 빠름
li3 = [['a', 'b', 'c'], ['!', '@', '#']]
li4 = [j+"K" for i in li3 for j in i]
print(li4)
# >> ['aK', 'bK', 'cK', '!K', '@K', '#K']
# comprehension에 if를 추가해서 filter 구현
li5 = [nick for nick in li1 if len(nick) >= 3]
print(li5)
# >> ['군계일학']collections 모듈
deque
Counter
데이터의 개수나 집계를 용이하게 해주는 클래스
data = ['참외', '수박', '수박', '토마토', '수박', '참외']
# Counter를 사용하지 않는 경우
counting = {}
for fruit in data :
cnt = counting.get(fruit, 0)
cnt = cnt + 1
counting[fruit] = cnt
print(counting)
# >> {'참외': 2, '수박': 3, '토마토': 1}
# Counter 사용해서 데이터 개수 세기
from collections import Counter
counter = Counter(data)
print(counter['참외'])
# >> 2
print(dict(counter))
# >> {'참외': 2, '수박': 3, '토마토': 1}
# 합계 구하기
portfolio = [('Google', 100, 490.1), ('IBM', 23, 89), ('Apple', 340, 400), ('Google', 13, 90)]
total = Counter()
for name, shares, price in portfolio :
total[name] += price
print(dict(total))
# >> {'Google': 580.1, 'IBM': 89, 'Apple': 400}
print(total.most_common(2)) # 상위 2개의 값까지만 리턴
# >> [('Google', 580.1), ('Apple', 400)]defaultdict
하나의 key에 여러 개의 데이터를 저장할 수 있는 dict
from collections import defaultdict
holdings = defaultdict(list)
for name, shares, price in portfolio :
holdings[name].append((shares, price))
for holding in holdings :
print(holding, " : ", holdings[holding])
# >> Google : [(100, 490.1), (13, 90)]
# >> IBM : [(23, 89)]
# >> Apple : [(340, 400)]orderedDict
dict와 동일하게 동작하지만 데이터가 추가된 순서를 기억해서 데이터를 순서대로 처리할 수 있도록 해주는 자료형
keys = ["one", "two", "three"]
values = (1, 2, 3)
dict = dict(zip(keys, values))
for key in dict :
print(key, " : ", dict[key])
# >> one : 1
# >> two : 2
# >> three : 3
from collections import OrderedDict
dict = OrderedDict(zip(keys, values))
for key in dict :
print(key, " : ", dict[key])
# >> one : 1
# >> two : 2
# >> three : 3
# 현재 예제는 결과가 같게 나왔지만 다르게 나올 수 있다!itertoosl 모듈
효율적인 루핑을 위한 이터레이터를 만드는 함수 패키지
https://docs.python.org/ko/3/library/itertools.html
조합형 이터레이터 함수
combinations(iterable, r): iterable에서 원소 개수가 r개인 조합 뽑기combinations_with_replacement(iterable, r): iterable에서 원소 개수가 r개인 중복 조합 뽑기product(*iterable, repeat=1): 여러 iterable의 데카르트곱 리턴permutations(iterable, r=None): iterable에서 원소 개수가 r개인 순열 뽑기
from itertools import combinations
from itertools import combinations_with_replacement
from itertools import permutations
from itertools import product
l = [1,2,3]
print("조합 :", end=" ")
for i in combinations(l, 2):
print(i, end=" ")
# >> 조합 : (1, 2) (1, 3) (2, 3)
print("중복 조합 :", end=" ")
l = ['A', 'B', 'C']
for i in combinations_with_replacement(l, 2):
print(i, end=" ")
# >> 중복 조합 : ('A', 'A') ('A', 'B') ('A', 'C') ('B', 'B') ('B', 'C') ('C', 'C')
print("순열 :", end=" ")
l = ['A', 'B', 'C']
for i in permutations(l): #r을 지정하지 않거나 r=None으로 하면 최대 길이의 순열이 리턴된다!
print(i, end=" ")
# >> 순열 : ('A', 'B', 'C') ('A', 'C', 'B') ('B', 'A', 'C') ('B', 'C', 'A') ('C', 'A', 'B') ('C', 'B', 'A')
l1 = ['A', 'B']
l2 = ['1', '2']
print("l1과 l2의 데카르트곱 :", end=" ")
for i in product(l1, l2, repeat=1): #l1과 l2의 모든 쌍을 지어 리턴한다
print(i, end=" ")
# >> l1과 l2의 데카르트곱 : ('A', '1') ('A', '2') ('B', '1') ('B', '2')
for i in product(l1, repeat=3): #product(l1,l1,l1,repeat=1)과 동일한 출력
print(i, end=" ")
# >> ('A', 'A', 'A') ('A', 'A', 'B') ('A', 'B', 'A') ('A', 'B', 'B') ('B', 'A', 'A') ('B', 'A', 'B') ('B', 'B', 'A') ('B', 'B', 'B')