Complex Network란
우리말로 복잡계로 해석할 수 있는데 구성요소와 구성요소 간의 상호작용으로 이루어져 있는 환경을 말할 수 있다.
간단히 말해서 인류는 각각의 개별 사람(구성요소)으로 이루어져있고 각각의 사람들은 다른 사람과 친분을 맺는다(상호작용).
또 다른 예시로는 사람이 상품을 구매한 내역이다.
각각의 사람과 상품(구성요소)는 그 사람이 어떤 상품을 샀는지에 대한 상호작용으로 이루어질 수 있다.
그래프 이론
우리는 이러한 구성요소와 상호작용을 각각 노드와 간선으로 하여 그래프를 그릴 수 있다.
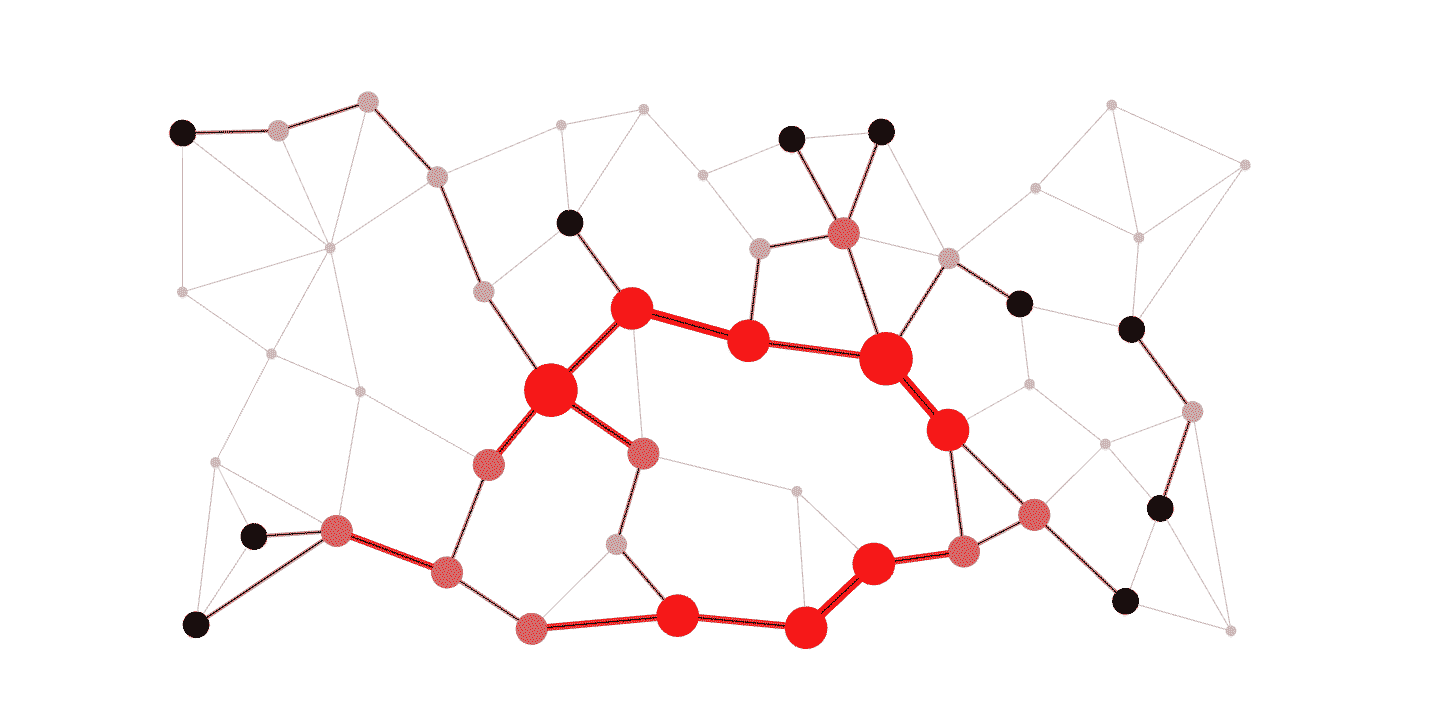
이러한 그래프 이론에는 크게 3가지 통계학적으로 중요한 속성이 존재한다
1. Scale-free
2. Transitivity
3. small world
1. Scale-free
우리가 위에서 정의하고 우리주변에서 볼 수있는 복잡계는 스케일이 없다
일반적으로 Scale이 있다고하면 간단히 우리가 어림잡을 수 있다 예측가능하다 정도인데 Scale-free라고 하면 예측하기 힘들다 정도로 생각하면 좋을 것 같다
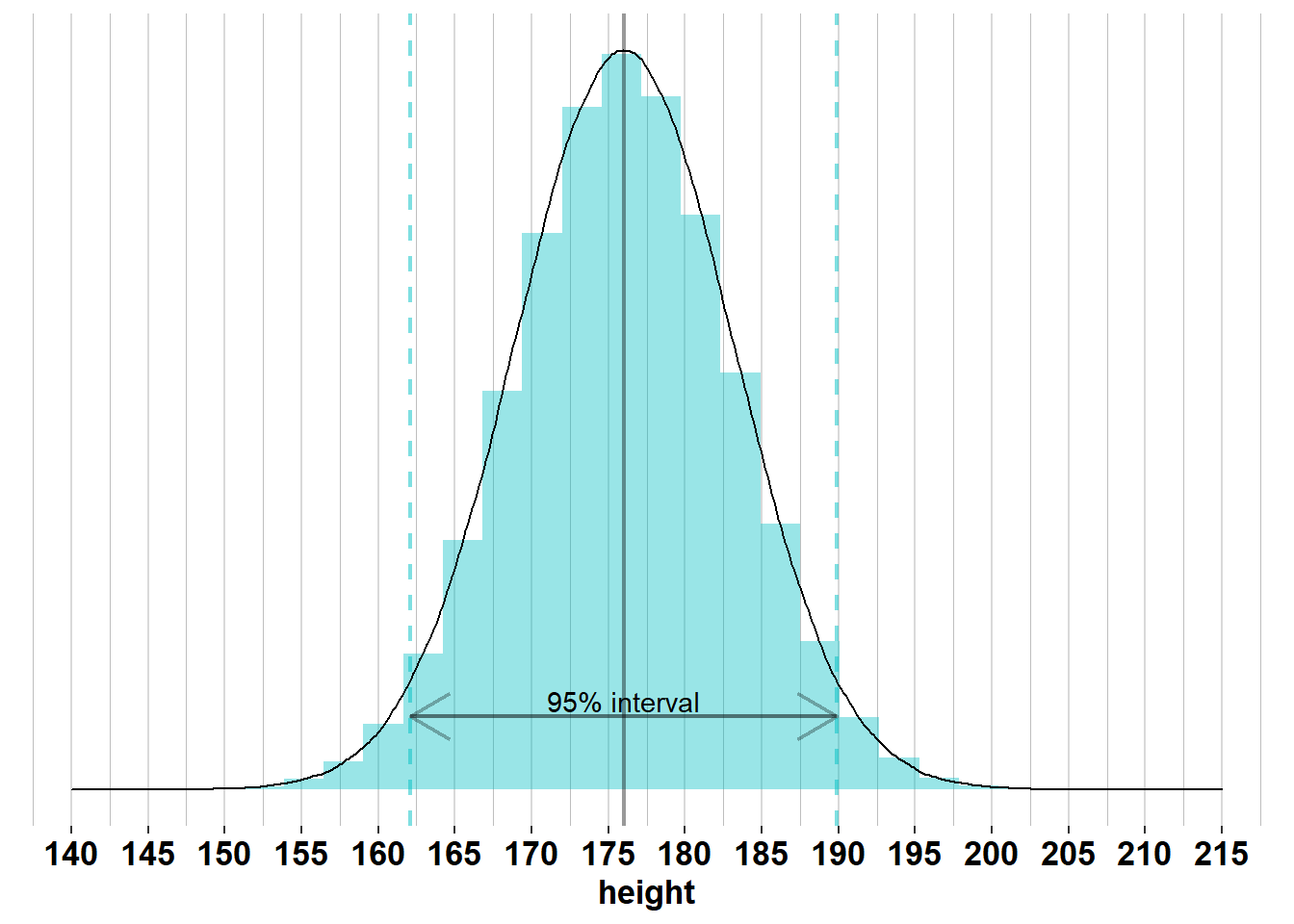
typical normal distribution
우리가 일반적으로 정규분포 혹은 가우스 분포라는 것을 알테이다.
우리 일상 생활에 쉽게 적용된다라는 특성을 가지고 있고 실제로 많은 분야에 적용가능하다.
대표적인 예시로 키, 몸무게가 될 것이다.
성인 남성을 기준으로 약 175에 평균이 위치할 것이고 그곳에서 멀어질수록 해당 값을 가지는 사람이 적어진다.
극단적으로 우리는 키가 50cm이거나 5m인 사람은 쉽게 찾아볼 수 없을 것이다.
여기서 알 수 있는 정규분포의 특징은 두드러진 평균이 존재하고, 평균에서부터 분산이 급격히 줄어들어 대부분의 값들은 평균에서 일정 내에 존재하게 된다.
Power Law Distribution
이와 다르게 Power law distribution이 존재한다.
이 분포는 흔히 우리에게 파레토 법칙, 롱테일 법칙으로 인해 잘 알려져있다.
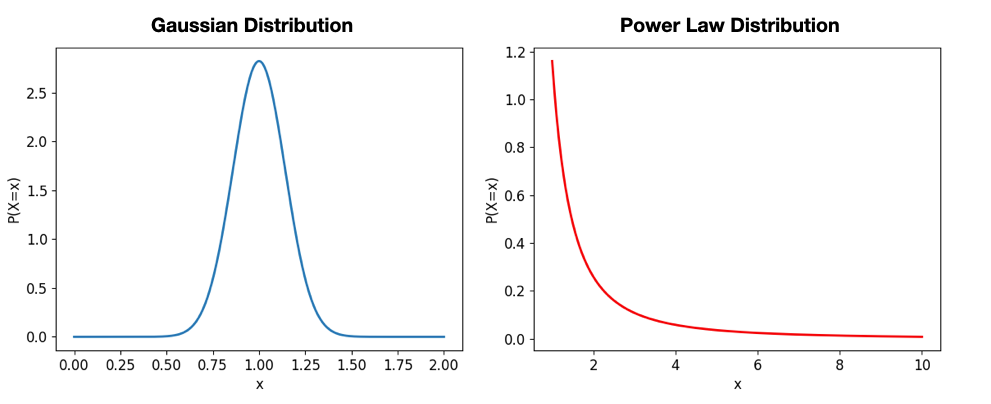
원점에서 시작하여 멀어질 수록 점점 줄어들며 꼬리가 긴 형태를 지니고 있다.
경제학이나 경영학에서는 이를 파레토, 롱테일 법칙으로 설명하지만 그래프 이론에서는 이를 Zip's Law로 설명한다
Zipf's Law (지프의 법칙)
한마디로 Rank와 빈도수는 반비례한다라는 법칙이다.
대표적인 예시를 들어보면 사람들이 대화하는 것에서 이 규칙을 찾아볼 수 있다.
영어권 사람들이 대화를 할 때 가장 많이 사용하는 단어는 무엇일까?
실험적으로 to, and, of, the 등의 전치사 혹은 관사가 많이 사용되는 것을 알 수 있었다.
예를 들어 총 10000개의 단어를 이야기했을 때 이 단어들을 약 1000번 씩 사용하였다고 가정하자.
그러면 남은 6000개의 단어는 어떤 단어였을까?
Coffee, Car, Phone 등 일상 단어라고 추측해보았을 때 이런 단어들은 10000 단어 내에 각각 1-2번 정도만 쓰였을 것이다.(이게 대화주제가 아니었다고 가정하면)
또한 이러한 단어들은 어림잡아 1000개는 있었을 것이다.
복잡하지만 정리하자면 다수의 단어는 많이 사용되지 않고 소수의 단어가 많이 사용될 것이다.
즉 여기서 Rank는 특정 사용된 횟수에 해당하는 단어의 수이고 빈도수는 사용된 횟수일 것이다
1번 사용된 단어의 수는 3000개 2번 사용된 단어의 수는 1000개 .... 1000번 사용된 단어의 수는 2개 이런 식으로 말이다.
이러한 법칙은 또다른 쉬운 예시에서도 발견할 수 있다.
SNS 친구 수에서 볼 수 있는데 대부분 사람들의 팔로워 수는 수십, 수백명일 것이다.
하지만 누군가는 1000만, 1억의 팔로워를 가질 수도 있다.
하지만 이러한 빈도 높은 경우에 해당하는 사람 수는 꽤나 소수(10명쯤?)일 것이다.
이처럼 다양한 상호작용이 있고 그래프로 표현이 가능한 상황에서는 지프의 법칙이 들어맞고 Power Law Distribution을 따르기에 Scale-free의 특성을 가진다.

이러한 현상이 나타나는 이유는 정확히는 알려져 있지 않지만 인간의 상호작용 과정에서 편향이 발생하기 때문이라고 볼 수 있다.
책 구매에 대해서 생각해보자.
우리는 이 책이 읽기 전까지 좋은지 안좋은지 알 수 없다.
하지만 현실은 잘팔리는 책만 잘팔린다. 특히 잘팔리는 작가의 책이 잘 팔린다.
우리는 내용은 모르지만 특정 작가의 이름만 보고 구매를 하는 경향이 있고 또 주변에 많은 사람들이 구매하면 구매하는 경향이 있다.
물론 책의 가치가 높을수도 있지만 낮더라도 이러한 현상은 나타나고 간단히 부익부현상으로 생각할 수 있다.
이에 반해 한 두권 팔리는 무명작가의 책들은 무지하게 많을 것이다.
이러한 판단과 현상들로 인해 많은 상호작용이 지프의 법칙을 따른다고 생각된다.
Power Law Distribution 수식
으로 나타낼 수 있고 위에서 본 것 같이 비선형 구조를 가진다.
여기서 는 감소의 정도를 나타내고, k는 빈도수를, f(k)는 해당하는 노드의 수 C는 상수이다.
이에 로그스케일을 취하면 선형 구조로 변환할 수 있다.
로 나타낼 수 있다.
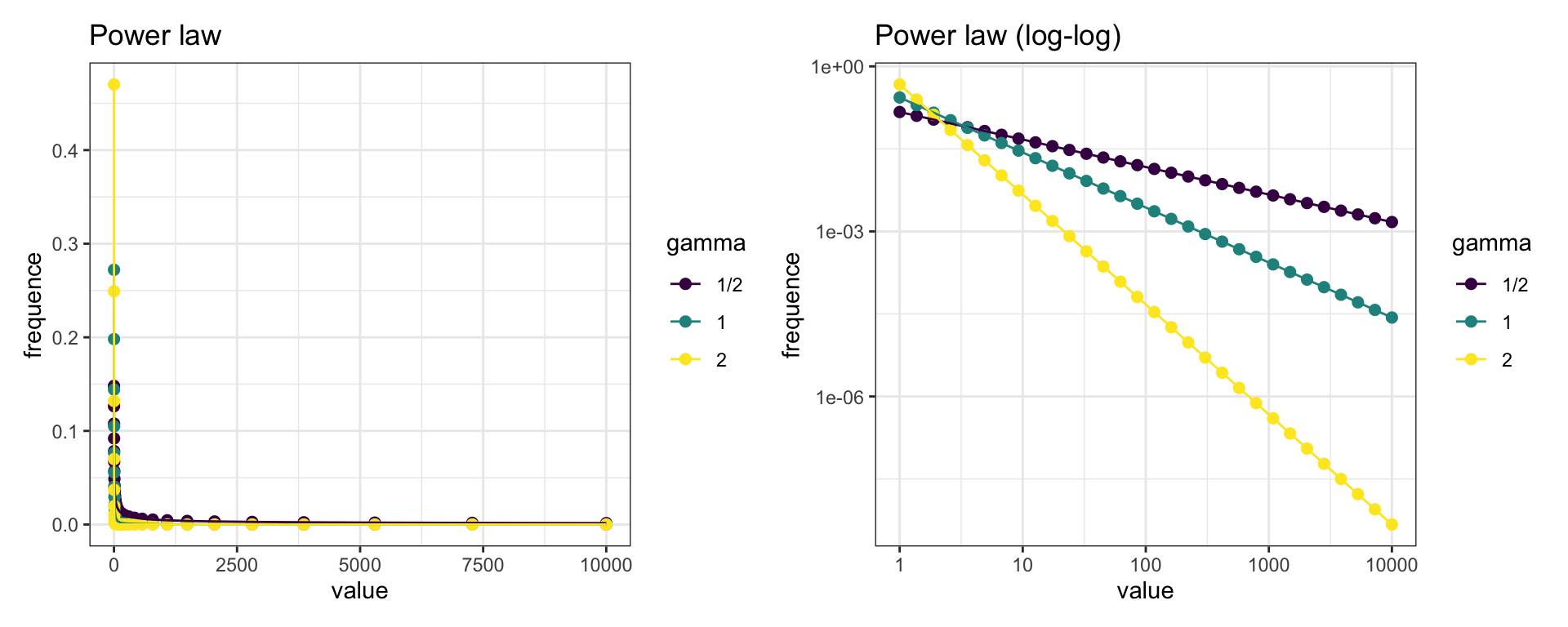
선형 구조로 변환함에 따라 서로 다른 그래프 간의 의 비교가 가능하게되고 선형적인 모델이기에 해석하는 것 또한 쉽게 된다
2. Transitivity
다음은 전이성이다
The Strength of Weak Ties라는 논문에서 기인 되었는데
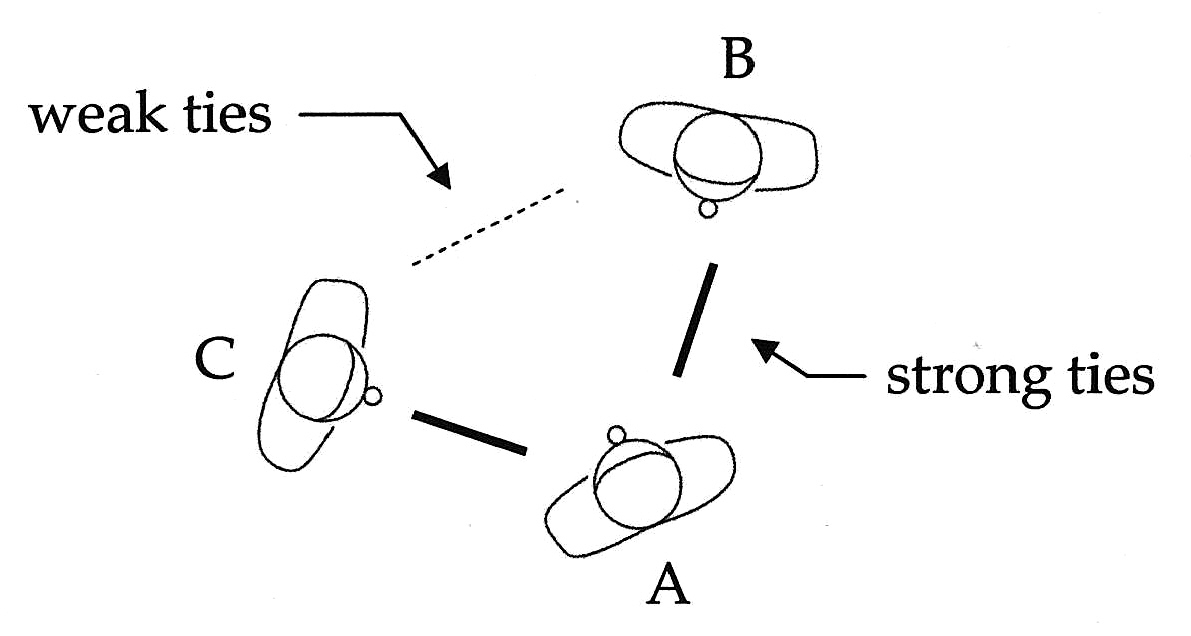
간단하게 A가 C,B와 모두 꽤 친하다면 B와 C가 친구일 가능성이 높다는 뜻이다.
물론 둘은 처음에 몰랐겠지만도 A를 통해 추후에 알게되었을 가능성이 높다라는 뜻이다.
이것 때문에 Social Network 구조에는 삼각형이 많고 이러한 삼각형을 구하는 공식으로 Clustering Coefficient을 구하면 일반적으로 꽤 높게 나온다.
즉 전이성을 바탕으로 서로 다른 두 정점이 공통 이웃이 있는 경우 공통 이웃을 통해 연결이 될 수 있고 군집이 형성될 수 있다
3. Small World
작은 세상이라는 것은 우리가 한번쯤은 들어봤을 것이다.
유명한 예시로 케빈 베이컨의 6단계 법칙이 있다.
즉, 내 지인을 통해 6다리만 거치면 전 세계사람을 알게된다라는 법칙이다.
이를 스탠리 밀그램이 실험적으로 증명하였는데 실험의 내용은 간단히 보스턴에 있는 누군가에게 편지를 전달하라는 것이 었다.
만약 내가 모른다면 그 사람을 가장 잘 알 것 같은 사람에게 편지를 써서 총 몇 다리를 거치는지 기록하라는 것이었다.
결과는 평균적으로 5.2다리를 거쳐서 목표에 도달할 수 있었다.
물론 이 실험은 공간이 미국 내부로 한정되었기에 이보다는 더 크겠지만 해당 시대는 1960년대이고 현재는 SNS의 발달로 더 빨라지지 않았을까 생각한다.
이를 간단한 이론적인 증명으로 표현해볼 수 있다.
여기서 d는 몇 다리를 거치는지, N은 만나는 총 사람의 수이다.
z는 내가 알고 있는 사람의 수라고 가정을 한다면
예를 들어 내가 5명의 지인이 있고 전세계 사람들이 각각 중복없는 5명의 지인이 있다고 가정하자
그럼 1다리에 5명 2다리에 25명 ... 5다리에 3125명을 알 수 있다.
내가 10명을 알고있다고 한다면 5다리만 거쳐도 10만 명을 알 수 있다.
위 법칙으로 내 지인이 40명이 있다고 한다면 6다리 내에 60억 인구를 모두 만날 수 있다.
물론 이론적인 것이지만 그만큼 이 세상을 작다!
라는 것을 증명해줄 수 있다.
정리
그래프 이론에 사용되는 중요한 이론 3가지를 살펴보았고 이 개념들은 우리가 일상생활에서 만나는 네트워크 모델들을 다룰 때 잊지 않아야할 것이다.
