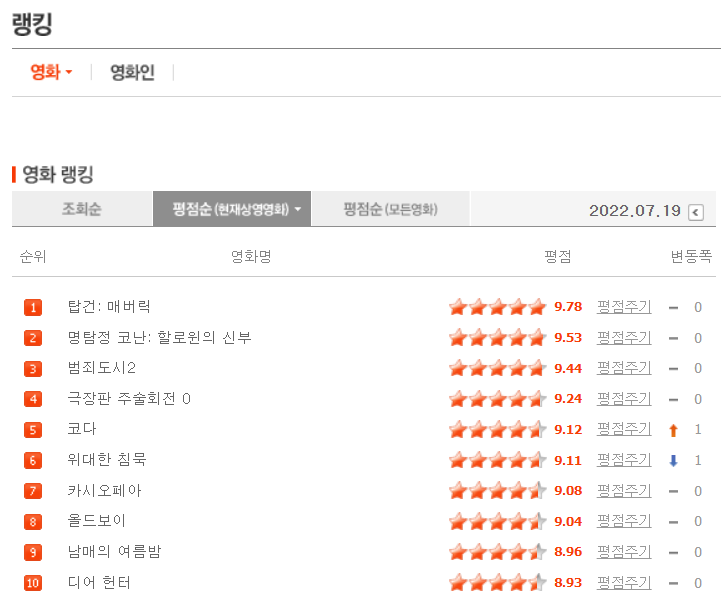
네이버 영화 평점 수집
학습 목표
1. 영화명과 평점을 수집한 후 데이터 프레임으로 만들기
2. 날짜별로 영화명과 평점 데이터 수집 후 데이터 프레임으로 만들기
우선 기본 코드는 아래와 같다.
import requests as req
import pandas as pd #데이터프레임을 만들 떄 사용.
from bs4 import BeautifulSoup as bs
import time #딜레이를 사용할 때
#요청하는 브라우저의 정보를 설정
header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
rate_url = 'https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur&date=20220719'
res = req.get(rate_url, headers=header)
html = bs(res.text, 'lxml')네이버 영화명, 평점, 수집 후 출력해보기
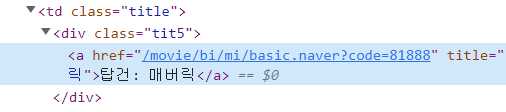
site의 html코드를 분석해보면, title은 'div.tit5 > a' 으로 식별이 가능하다.
영화 평점도 같은 방식으로 조사해 보면, 'td.point' 으로 식별이 가능하다.
movie_title_raw = html.select('div.tit5 > a')
movie_rate = html.select('td.point')
movieNmlist = []
ratelist = []
for i in range(len(movie_title_raw)):
# print(movie_title_raw[i].text.strip(), movie_rate[i].text.strip())
movieNmlist.append(movie_title_raw[i].text.strip())
ratelist.append(movie_rate[i].text.strip())
list의 값은 dictionary로 묶은 후, DataFrame으로 다시 변환한다.
mv_rate_dic = {
'영화명' : movieNmlist,
'평점' : ratelist
}
mv_rate_df = pd.DataFrame(mv_rate_dic)
print(mv_rate_df)날짜 생성하는 함수
- 방법1 start와 end를 넣는법
pd.date_range(start='2022-06-01', end='2022-06-30')- 방법2 period를 넣어서 하는 법.
dates = pd.date_range(start='2022-06-01', periods=30)
생성된 Data는 아래와 같이 이용할 수 있다.datelist = [] for i in range(len(dates)): datelist.append(dates[i].strftime('%Y%m%d'))['20220601', '20220602', '20220603', '20220604', '20220605', '20220606', '20220607', '20220608', '20220609', '20220610', '20220611', '20220612', '20220613', '20220614', '20220615', '20220616', '20220617', '20220618', '20220619', '20220620', '20220621', '20220622', '20220623', '20220624', '20220625', '20220626', '20220627', '20220628', '20220629', '20220630']
날짜를 생성하는 함수를 이용해서, 6/1 ~ 6/30 일까지 영화명화 평점을 가져오는 코드를 작성해 보도록한다.
from tqdm.notebook import tqdm as tn
header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
daylist = []
movieNmlist = []
ratelist = []
for date in tn(datelist):
rate_url = 'https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=cur'
res = req.get(rate_url, headers=header, params={'date':date})
html = bs(res.text, 'lxml')
movie_title_raw = html.select('div.tit5 > a')
movie_rate = html.select('td.point')
for i in range(len(movie_title_raw)):
movieNmlist.append(movie_title_raw[i].text.strip())
ratelist.append(movie_rate[i].text.strip())
daylist.append(date)
time.sleep(1)
mv_rate_dic = {
'날짜' : daylist,
'영화명' : movieNmlist,
'평점' : ratelist
}
mv_rate_df = pd.DataFrame(mv_rate_dic)
print(mv_rate_df)실행 결과

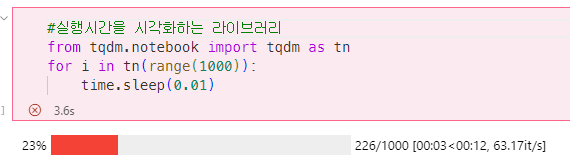
Python tqdm package 사용해보기
tqdm은 실행시간을 시각화하는 라이브러이다.#실행시간을 시각화하는 라이브러리 import time from tqdm.notebook import tqdm as tn for i in tn(range(1000)): time.sleep(0.01)실행결과
불리언 인덱싱으로 특정 날짜(6/1)의 Data로만 필터링 해보자
#불리언 인덱싱
check_date = mv_rate_df['날짜'] == '20220601'
mv_rate_df[check_date]실행결과,


Have a good one!