[논문리뷰] Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding

Neural-Symbolic VQA: Disentangling Reasoning from Vision and Language Understanding
본 논문은 NeurIPS 2018에 발표되었으며, spotlight을 받았습니다.
본 포스팅은 YAI 기민주, 전원석님의 보고서를 바탕으로 작성되었습니다.
참고자료
본 논문은 아래 그림과 같이 주어진 이미지를 인식해 질문에 적절한 답을 내놓아야 하는 Visual Question-Answering (VQA) 문제에 관해 다루고 있다. 이러한 태스크는 단순한 이미지 인식 (perception)을 넘어 추론 (reasoning)을 필요로 한다. 본 논문은 기존의 뉴럴넷 기반의 End-to-End 방식의 접근법들이 가지고 있는 한계점을 극복하고자, reasoning을 vision recognition과 language understanding으로부터 분리하고 symbolic program을 이용해 reasoning하는 방식을 제안한다.

저자들은 이렇게 symbolic structure를 prior로 삼을 경우 크게 다음의 세 가지 이점을 가진다고 주장한다.
- Symbolic program은 long program traces에 대해 더 강건하다.
- 데이터와 메모리 측면에서 효율적이다.
- Symbolic program execution은 reasoning 과정의 완벽한 투명성을 제공한다.
논문의 제목부터 지금까지 계속 symbolic이라는 단어가 등장하는데, 논문에서도 이에 대한 명확한 정의가 있지는 않습니다. 다만, 의미를 설명하자면 우리가 그 의도(또는 작동 원리)를 명확히 알 수 있는 일정 단위의 함수정도로 이해하고 읽으시면 됩니다. 논문 뒷부분까지 읽으면 보다 명확한 의미 파악이 될겁니다.ㅎㅎ
1. Introduction
기존의 대부분의 VQA 문제에 대한 접근법들은 end-to-end 방식으로 진행되었으며, 이러한 순수한 뉴럴넷 기반의 방식들은 어려운 reasoning 작업들에 대해 잘 작동하지 못했다. 대표적인 예로, 기존에 SOTA라고 여겨지던 VQA model들이 새로 제안된 CLEVR VQA dataset에 대해 좋은 성과를 내지 못했다.
저자들은 perception과 reasoning이 한군데에 뒤섞여있는 end-to-end 방식과 달리, 인간의 경우 VQA 작업에서 visual perception과 reasoning이 분리되어있고, reasoning 과정이 설명 가능하다는 점에서부터 문제를 제기한다.
비슷한 관점에서 최근에 Johnson et al. [2017b] 은 human language에 대한 사전 지식을 program으로 연결함으로써 reasoning을 학습할 수 있다는 것을 보였다. 특히, 질문으로부터 질문을 해결하기 위한 (내재된) program을 추론하는 program generator와 input image로부터 program을 수행하는 Attention-based executor를 결합해 문제를 해결했다. 이러한 방식은 좋은 성능을 냈고 일반화 측면에서도 좋은 모습을 보여줬으나, 저자들은 이들의 연구가 크게 다음의 두 가지 한계점이 있다고 지적한다.
- Program generator를 학습시키기 위해 많은 수의 annotated examples를 요구함.
- Attention-based neural executor의 행동을 설명하기 어려움.
여기서 program 이란, 주어진 질문 해결을 위한 추론 과정으로 미리 정의된 일련의 함수들로 구성된다고 생각하면 됩니다. 즉, 어떠한 추론과정이란 것은 몇 가지의 기본되는 program들의 조합으로 볼 수 있고, program generator는 질문에 적절한 답을 하기위한 추론과정 (program들의 조합)을 만듭니다.
Attention-based neural executor의 행동을 설명하기 어려운 이유는 무엇일까?
Attention이 기존의 신경망에 비해서는 설명력을 가진다고 알려져 있고, 실제로 Attention을 통해 현재 신경망이 어떤 입력에 반응을 하고 있는지 파악할 수는 있으나, 그 입력에 왜 반응하는지, 그리고 어떤 추론과정을 가지는지에 대해서는 여전히 설명하기 어렵기 때문이라고 생각합니다.
이러한 문제를 극복하고자 본 논문에서는 vision and language understanding을 reasoning으로 부터 분리한 neural-symbolic approach for visual question answering (NS-VQA)를 제안했다. 저자들은 신경망을 이미지로부터 scene representation을 추출하고 질문으로부터 program을 생성하는 역할로 사용하고, 이를 symbolic program executor를 사용해 실행함으로써 정답을 얻는 방식으로 접근했다.
이렇게 deep recognition model과 symbolic program executor를 결합함으로써 앞서 Abstract에서 설명한 세가지 장점을 얻을 수 있었다고 얘기하고 있다.
2. Related Work
Structural scene representation
저자들은 본 논문이 신경망을 이용해 interpretable, disentangled representation을 학습하는 연구들과 밀접한 관계를 가지고 있으며, 넓은 의미에서 "vision as inverse graphics"라는 분야와도 연관되어 있다고 한다. 본 논문에서 제안하는 NS-VQA model은 structural scene representation에 기반해 만들어졌으며, 이것이 어떻게 visual reasoning에 사용될 수 있는지에 대해 연구했다.
Program induction from language
최근 domain-specific language로부터 program search와 neural networks를 이용해 program을 복원해내는 방법들에 대해 연구들이 이루어지고 있으며, 이러한 연구들에 기반해 본 논문도 신경망을 활용해 질문 (언어) 으로부터 program을 만들어내는 과정을 학습한다.
Visual question answering
많은 연구가 진행된 text-based question answering 문제와 달리 visual question answering (VQA) 문제는 도전적이고 어려운 문제다. VQA 문제는 semantic과 visual 모두에 대한 이해를 필요로한다. 최근의 선도적인 연구들은 neural attention에 기반하고 있다. 그 외에도 image와 question으로부터 직접적으로 visual and text feature를 추출해 정답을 선택하기 위한 multi-class classifier를 학습시키는 방법도 제안된 바 있다. 본 논문은 기존의 연구들이 특정 dataset에 overfitting될 수 있다는 문제점에 주목하고 해결하고자 했다.
Visual reasoning
Johnson et al.은 CLEVR라 불리는 새로운 VQA dataset을 만들었으며, 후속 연구에서 CLEVR에서 우수한 성능을 내는 recurrent program generator와 attentive execution engine에 기반한 모델을 제안했다. 이후에도 다양한 attention 구조에 기반한 end-to-end neural model들이 여럿 제안됐었다.
보다 최근에는 reasoning task의 문법이나 논리 구조를 attentive network 구조와 직접적으로 결합해 reasoning 문제를 해결하려는 연구도 있었다. 이러한 구조에는 underlying functional programs, dependency trees 등이 있다.
그 외에도 여러 연구들이 시도되고 있고, 본 연구도 이러한 관점의 연장선에서 전체 scene을 object-based, structural representation으로 모델링하고 이를 투명하고 이해가능한 symbolic program executor와 결합해 문제를 해결했다.
3. Approach
3.1 Model Details
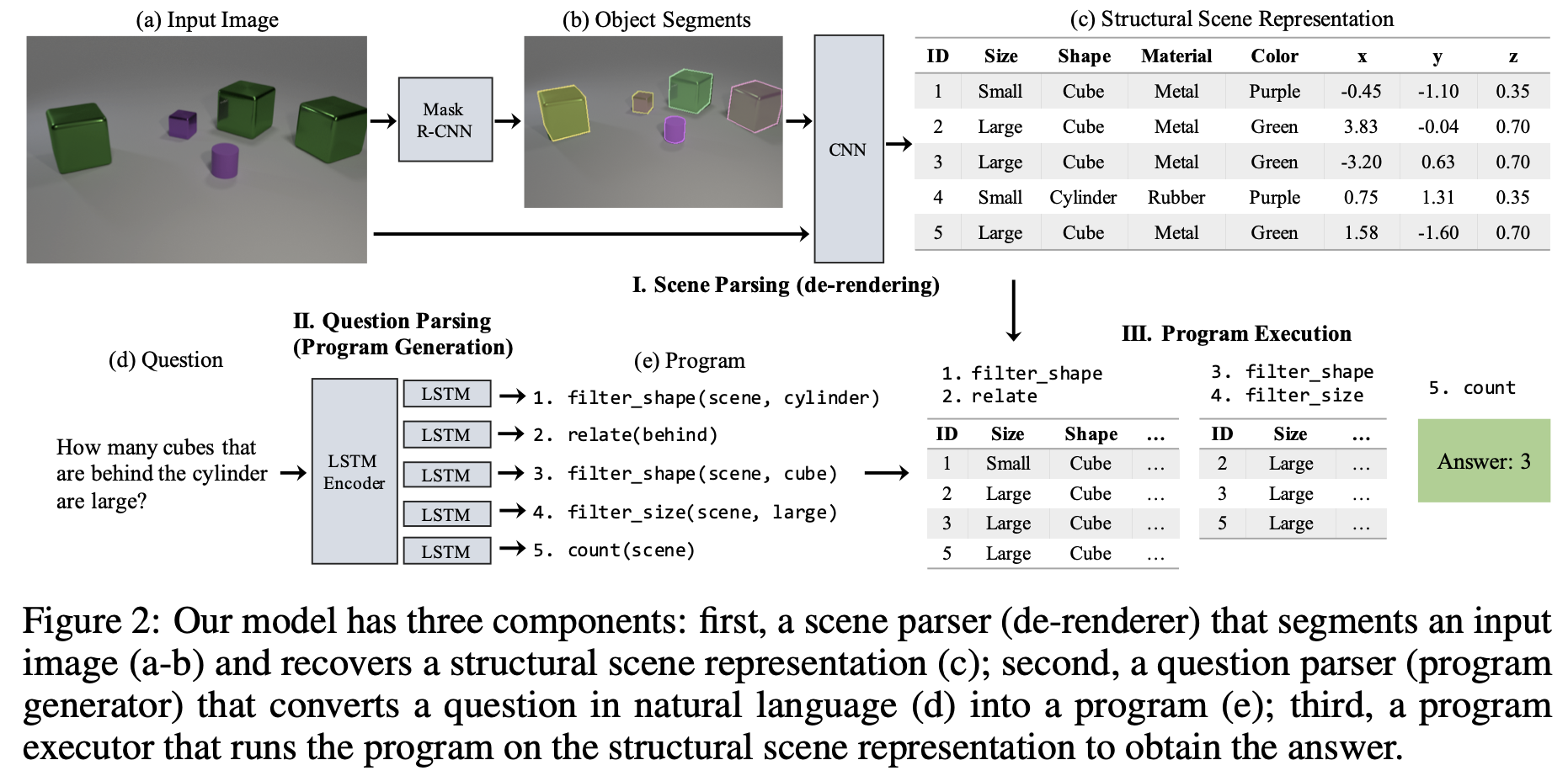
NS-VQA는 크게 다음의 세가지 요소로 구성된다.
- Scene parser (de-renderer)
- Image로 부터 structural scene representation을 얻는다.
- Question parser (program generator)
- question으로 부터 hierarchical program을 생성한다.
- Program executor
- 생성된 program을 추출한 scene representation을 이용해 실행
Scene parser는 크게 2 단계로 진행된다.
- 먼저 Mask R-CNN을 이용해 모든 Object들에 대한 segment proposal을 생성한다.
- 각각의 segment에 대해 색깔, 물성, 크기, 모양 등의 속성에 대해 예측한다.
Question parser는 자연어로 주어지는 question을 latent program으로 변환한다. 이러한 program은 functional module의 계층적 구조로 이루어져 있으며, 각 functional module은 scene representation에 대해 독립적으로 작동하게 된다. 이러한 hierarchical program은 compositionality와 generalization 성능을 자연스럽게 가져오게 한다.
question parser는 encoder-decoder 구조와 결합된 attention-based sequence to sequence 모델에 기반하고 있다.
Program executor는 dataset의 모든 질문에 대한 논리 수행이 가능하게끔 설계된 deterministic한 generic function module들로 구성되어 있다. 모든 module은 같은 input/output interface를 갖기 때문에 임의의 길이와 순서로 배치될 수 있다. 프로그램은 'scene' token으로 시작되며 이전의 출력을 입력으로 받아 순차적으로 실행되며 마지막 모듈은 답을 출력하게된다. 실행 중 연속된 두 모듈 사이의 입출력간에 type mismatch가 발생할 경우 'error' flag가 발생하게 되며 이럴 경우 마지막 모듈에서 가능한 모든 출력중 랜덤하게 답을 선택하도록 한다.
3.2 Training Paradigm
Scene parsing은 Mask R-CNN 기반의 object proposal network와 ResNet-50 FPN 기반의 feature extraction network로 구성되며 총 4000개의 CLEVR image를 이용해 학습했다.
Reasoning의 경우 두 단계로 학습이 진행된다. 먼저 적은 수의 question-program pairs를 training set으로 부터 선정하고 이를 이용해 direct supervision으로 pretrain을 진행한다. 그런 다음 이를 deterministic program executor와 결합해 REINFORCE 알고리즘으로 더 큰 question-answer pairs를 이용해 fine-tune 하는 과정으로 진행된다.
여기서 주목할 점은 pretrain은 적은 수의 question-program pairs를 이용해 supervised learning (지도학습)으로 진행된다는 것이고, 이후의 fine tuning은 더 큰 question-answer pairs를 이용해 정답 여부를 reward로 강화학습을 통해 진행된다는 것이다. 따라서 question을 풀기위한 program에 대한 Annotation은 가능한 적게 활용하면서 reasoning 과정을 학습한다는 것이다.
4. Evaluation
성능 평가 및 분석은 크게 다음의 두가지 관점에서 진행했다.
- state-of-the-art method들에 비해 적은 수의 학습 데이터만으로도 좋은 성능을 내며, latent program을 정밀하게 복원해낼 수 있는가?
- 다른 스타일의 질문, 속성 조합, visual context 에 대해서도 일반화된 성능을 보여줄 수 있는가?
4.1 Data-Efficient, Interpretable Reasoning
실험은 CLEVR dataset에 대해 진행했으며, structural scene representation은 각 object에 대해 shape, size, color, material, 3D coordinates 등을 특정한다. Pretraining에 사용된 ground-truth programs의 수와 REINFORCE에 사용된 question-answer pairs의 수를 변경해가며 validation set에 대해 성능을 평가했으며, IEP baseline [Johnson et al.]을 포함한 다른 SOTA method들과 성능비교를 진행했다. 또한 단순히 정답 여부만 평가하지 않고 underlying program을 얼마나 잘 복원했는지도 살펴봤다. Interpretable model은 정답뿐만 아니라 정확한 program 복원도 가능해야 하기 때문이다.
논문의 Table 1에서 SOTA method들과의 정량적인 성능비교를 확인할 수 있고, outperform하는 것도 확인할 수 있다.
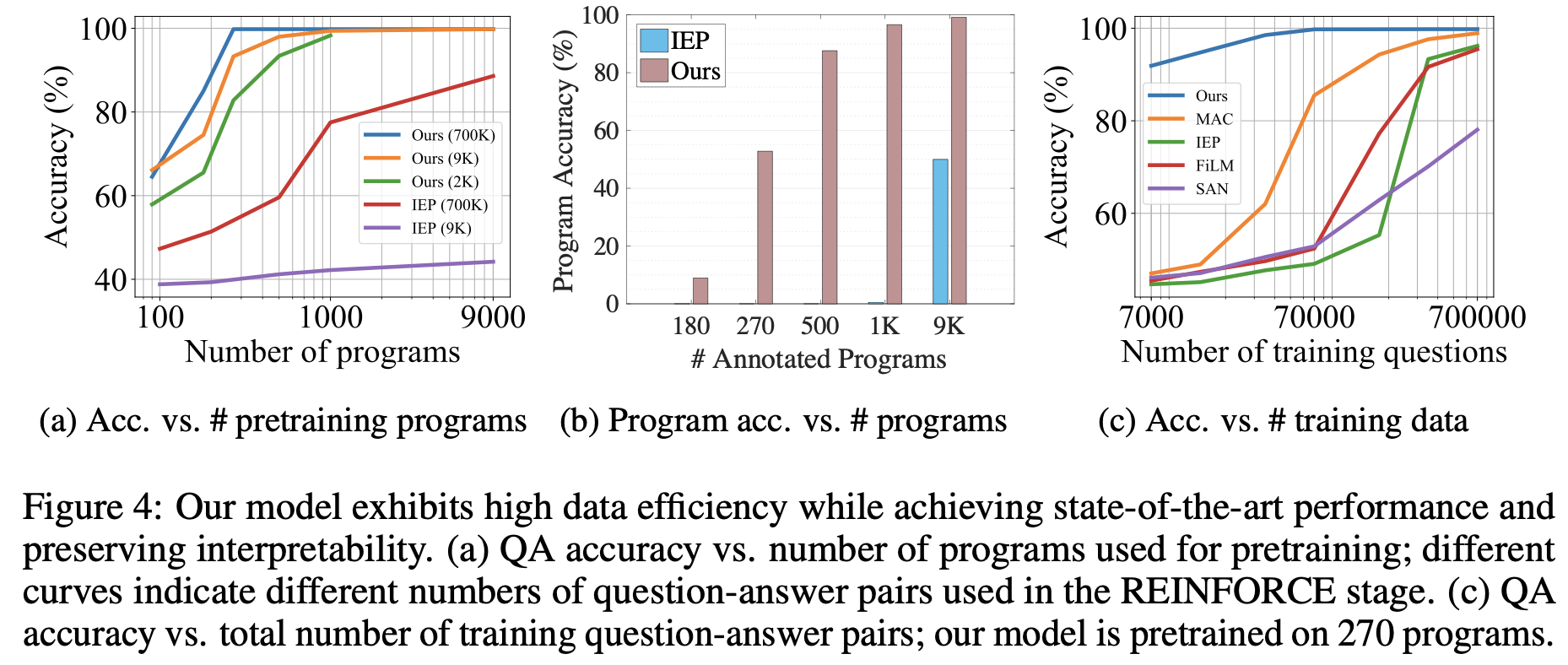
Data efficient에 대한 실험결과는 위의 Figure 4에서 확인할 수 있다. Figure 4a에서 볼 수 있듯이 다양한 조건에서 IEP 를 outperform하는 것을 볼 수 있으며, REINFORCE에서 적은 수의 question-answer pairs를 사용해도 99.8%에 달하는 정확도를 보여주는 것을 확인했다.
Figure 4b는 underlying program을 얼마나 정확히 복원해내는지에 대한 결과로 NS-VQA가 IEP에 비해 적은 수의 annotated program만 가지고도 효과적으로 복원해내는것을 확인할 수 있었다.
Figure 4c는 QA 정확도와 학습에 사용된 question-answer pairs의 수에 따른 결과로 훨씬 적은 수만을 가지고도 매우 정확한 결과를 내는 것을 볼 수 있다.
4.2 Generalizing to Unseen Attribute Combinations
처음보는 attribute combinations에 대한 일반화 성능을 알아보기 위해 CLEVR-CoGenT dataset을 이용해 실험을 진행했다. CLEVR-CoGenT dataset은 다음과 같은 두개의 split으로 구성되어 있다.
- Split A
- cubes with gray, blue, brown or yellow colors
- cylinders with red, green, purple or cyan colors
- Split B
- Split A와 색깔 조합을 서로 바꾼 Cubes, cylinders로 구성됨

실험결과는 위의 표와 같다. A에서 학습되고 B의 이미지 1000개에 대해 fine tune된 경우 A에 대해 성능이 많이 떨어지는 것을 알 수 있다. 이는 attribute recognition network이 물체의 모양을 색깔에 기반해 판단하게끔 잘못 학습되었기 때문이다. A, B 모두에 대해 fine tune한 경우의 성능을 보면 두 split 모두에 대해 좋은 성능을 내는 것을 확인할 수 있다.
또한 symbolic scene representation을 분리함으로써, question parser와 executor는 특정 split에 overfitting되지 않고 작동한다는 것도 확인할 수 있었다. 이를 위해 gray-scale image만으로 학습된 shape recognition network를 이용한 NS-VQA+Gray의 경우 split B의 이미지를 전혀 보지 않고도 잘 작동하는 것을 확인할 수 있었다. 또한 원래의 CLEVR dataset에 대해 학습된 NS-VQA+Ori의 경우도 B의 데이터를 전혀 보지 않고도 잘 작동하는 것을 확인할 수 있다.

좋은 정리 감사합니다! 많이 배우고 갑니다 ㅎㅎ