개념 리뷰 - Matching
가짜연구소 Causal Inference 팀에서 발표한 내용을 정리하였습니다.
생성일: 2023년 11월 3일 오후 5:59
발표자: 유정현
날짜: 2023년 11월 5일
상태: 완료
속성: causal inference
Summary
- 인과추론에서의 매칭은 관측된 데이터에서 인과 효과를 추정하기 위해 처리군과 대조군을 비슷하게 만드는 통계적 기법입니다.
- 인과 효과를 추정할 때는 유사한 공변량 분포를 가진 처리군과 대조군을 구하여, 가능한 무작위 실험을 가깝게 재현하는 것이 바람직합니다.
- Key idea는 일종의 교란요인 가 실험군과 대조군을 비교할 수 없도록 만들기 때문에, 각 실험군의 값을 유사한 대조군의 값과 일치시켜 비교할 수 있습니다. 처치를 받을 때마다, 처치받지 않은 쌍둥이를 찾는 개념과 비슷합니다. 이러한 비교를 통해, 처치된 것과 처치되지 않은 것을 다시 비교할 수 있습니다.
- RSM, CEM 등 Matching에 사용되는 방법과 장/단점을 알 수 있습니다.
- 인과 추론에서 Regression이나 Matching 모두 단독으로 사용하는 것을 권장하지 않습니다.
서론
Abstract
A/B Test처럼 통제된 환경을 조성한 뒤, 실험 결과를 확인하는 작업은 비용이 많이 투입됩니다.
또한, 게임이라는 산업은 여러 유관 부서의 이해관계가 얽혀있기 때문에 프로덕트(이하 게임)에 A/B Test를 설계 및 적용한다는 것은 대부분 투입 비용 대비 결과가 좋지 않습니다.
따라서, DiD 같은 준실험 방법, 회귀를 많이 사용합니다.
그러나, 회귀는 선형적이고 매개변수적이며, 분산이 큰 특성을 선호하며, 교란변수에 취약함
한 가지 예시를 들어보겠습니다.
음주가 간암에 영향을 미치는 정도를 알아보는 실험을 진행한다고 가정해봅시다.
- 참가자 1: 음주O | 20대 | 간염 이력 없음 | 매주 2시간씩 운동 | 집안에 간암 환자 있음
- 참가자 2: 음주X | 70대 | 간염 이력 있음 | 운동하지 않음 | 집안에 간암 환자 없음
위 참가자의 음주 여부만으로 간암에 미치는 영향을 계산할 수 있을까요? 단순 음주 외에도 나이, 간염 이력, 운동 시간도 암의 발생에 영향을 줄 수 있지 않을까요?
즉, 두 실험군은 동일한 조건이 아니기 때문에 음주가 간암에 영향을 주는 인과성을 설명하기에는 한계가 있을 것입니다.
이를 보완할 수 있는 Matching이라는 개념을 사용할 수 있습니다.
본론
1) Matching 개념
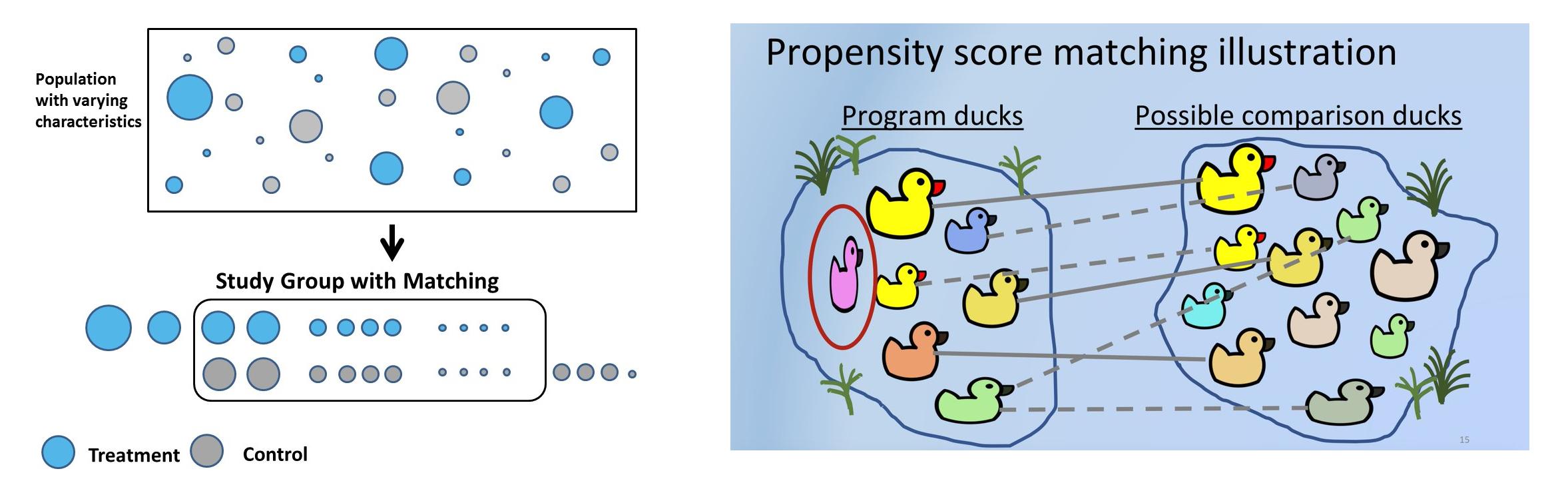
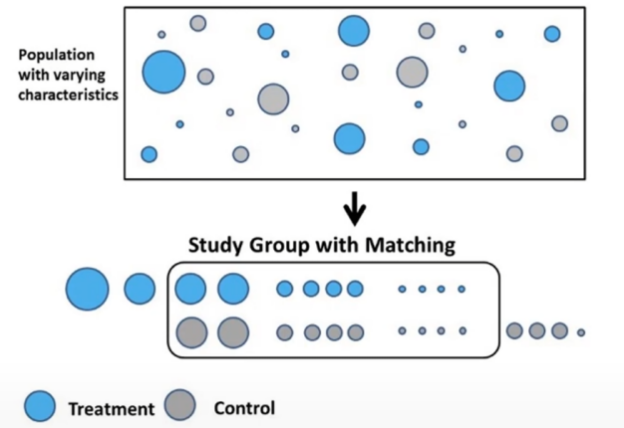
- 관찰 연구나 준실험에서 처리된 단위와 처리되지 않은 단위의 효과를 비교함으로써 처리의 효과를 평가하는 것을 의미함
- 매칭의 목표는 공변량(관찰된 변수)의 분포 면에서 처리Group과 유사한 대조 그룹을 찾는 것
**⇒ 처리 효과의 추정치에서 혼동 변수로 인한 편향을 줄이는데 기여함** - 아래 이미지 참고
2) Regression과 Matching 비교
| Regression | Matching | |
|---|---|---|
| 장점 | RCT, DID 등의 다양한 설정과 방법에 유연하게 확장 가능 | 연구 설계가 명확함 |
| 매칭과 비교하여 모든 관찰 변수를 유지함 | 그룹 간 균형을 쉽게 평가할 수 있음 | |
| 단점 | 회귀식에 민감함 | [PSM] 성향 점수 추정에 민감함 |
| 조건부 독립 가정을 평가하기 어려움 | [CEM] 샘플 크기가 작아지며, 이는 데이터의 분산을 증가시킬 수 있음 |
3) PSM(Propensity Score Matching) 방식 - Matching을 하는 방법
- 가장 많이 활용되는 방법
- 관찰된 공변량에 따른 처리를 받을 가능성을 기준으로 처리군과 비처리군을 매칭합니다.
관찰 가능한 변수 선택: 선택 과정에서의 성향 점수는 관찰된 변수를 사용하여 예측할 수 있음 - Selection on observables
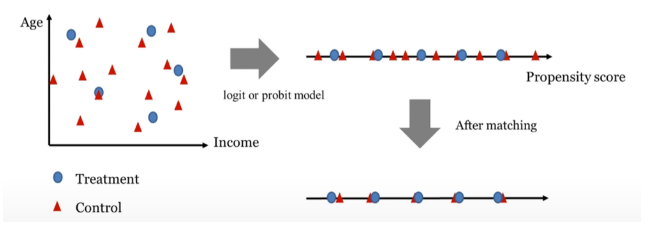
Binary모델에서 Logistic이나 Probit 모델로, Treatment를 Binary outcome, 나머지 변수로 분석을 진행할 수 있음
- PSM Options

- 이미 매칭된 유닛의 재활용 여부
- 계속 매칭시킬 것인지, 1:1로만 사용할 것인지
- KNN matching
- K 값이 성능에 영향을 미침
- Caliper matching
- 임계값 c보다 작은 거리를 가진 대조군만을 사용하여 NN매칭을 수행하는 방법
- 성향 점수의 차이가 임계값 c 이내인 대조군만을 고려 - 성향 점수가 유사한 대상간의 비교에 유용
- Radius matching
- 거리가 임계값 c보다 작은 모든 대조군을 매칭
- Kernel matching
- 처치 데이터를 기준으로 Control 데이터들의 거리에 Weight를 주는 방식
- Gaussian distribution 방식을 많이 사용: 정규분포 개념 차용
- IPW
- 역확률 가중치 방식
번외 1) PSM 구현 (최근접 이웃)
-
임의 생성한 데이터셋을 기반으로 PSM을 구현해 보겠습니다. 분류 모델로 각 클래스에 속할 조건부 확률을 사용하고, KDTree로 각 처리 그룹의 샘플에 가장 가까운 대조 그룹 샘플을 찾습니다.
- n=100, 공변량은 5개, 결과 변수는 ‘outcome’ 입니다.
import numpy as np import pandas as pd np.random.seed(0) n = 100 # 샘플 수 treatment = np.random.binomial(1, 0.5, size=n) # 처리 여부 covariates = np.random.normal(size=(n, 5)) # 공변량 outcome = treatment + covariates[:, 0] + np.random.normal(size=n) # 결과 변수 # 데이터셋 생성 df = pd.DataFrame(covariates, columns=['covariate1', 'covariate2', 'covariate3', 'covariate4', 'covariate5']) df['treatment'] = treatment df['outcome'] = outcomeb. 데이터셋은 아래와 같습니다.
성향 점수를 계산하겠습니다. 성향 점수를 계산하는데 사용한 알고리즘은 LR입니다.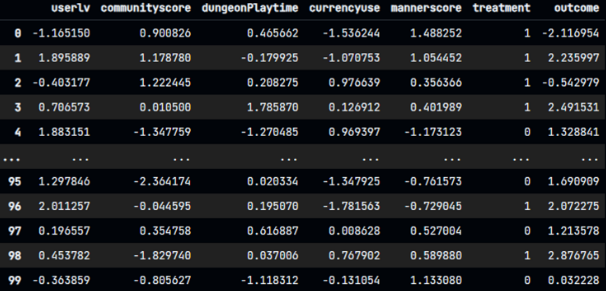
# 성향 점수 계산 from sklearn.linear_model import LogisticRegression propensity_model = LogisticRegression().fit(covariates, treatment) propensity_score = propensity_model.predict_proba(covariates)[:, 1] -
이후, KDTree를 사용하여, 최근접 이웃 매칭을 수행합니다.
from scipy.spatial import KDTree treated_idx = np.where(treatment == 1)[0] control_idx = np.where(treatment == 0)[0] tree = KDTree(propensity_score[control_idx].reshape(-1, 1)) _, match_idx = tree.query(propensity_score[treated_idx].reshape(-1, 1)) -
매칭된 샘플을 추출(concat)하여, 결과 값을 확인합니다.
# 매칭된 샘플 추출 matched_treated = pd.DataFrame({ 'treatment': treatment[treated_idx], 'outcome': outcome[treated_idx], 'propensity_score': propensity_score[treated_idx], }) matched_control = pd.DataFrame({ 'treatment': treatment[control_idx][match_idx], 'outcome': outcome[control_idx][match_idx], 'propensity_score': propensity_score[control_idx][match_idx], }) matched_data = pd.concat([matched_treated, matched_control]) matched_data출력 값은 아래와 같습니다. 임의로 생성한 정규분포 무작위 데이터이기 때문에, 2개의 데이터만 매칭되지 못하여 삭제되었군요. 성향 점수도 정규분포 형태를 띄고 있습니다.
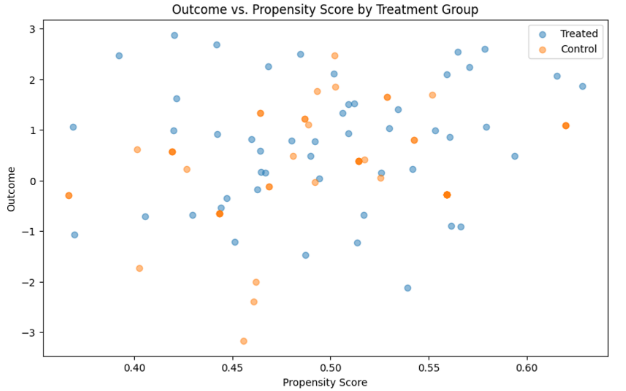
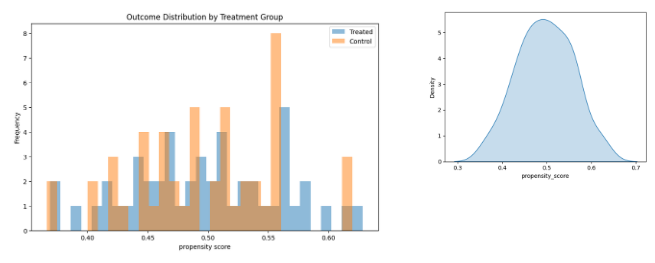
사실 causalinference 라이브러리를 사용하면, 7줄로 PSM을 구현할 수 있습니다.
Propensity Score Matching tutorial in Python
이후 평균 처리 효과를 추정할 수 있습니다.
ate = matched_data[matched_data['treatment'] == 1]['outcome'].mean() - matched_data[matched_data['treatment'] == 0]['outcome'].mean()
from scipy import stats
treated_outcome = matched_data[matched_data['treatment'] == 1]['outcome']
control_outcome = matched_data[matched_data['treatment'] == 0]['outcome']
t_stat, p_value = stats.ttest_ind(treated_outcome, control_outcome)
print(f"t-statistic: {t_stat}")
print(f"p-value: {p_value}")4) IPW(Inverse Probability Weighting)
- 처리를 받을 확률(성향 점수)을 처리군과 대조군 간에 균형을 맞추기 위해, 처리를 받은 단위에 처리의 역확률을 가중치로 주어 균형을 맞춤
- 비슷한 특성을 가진 단위를 필터링하는 대신, 모든 단위를 고려하여 처리의 효과를 주장할 수 있음
- ex) Treatment 단위 = Control의 역확률
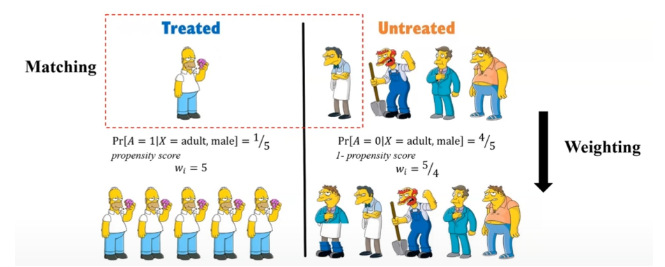
Solving Simpson’s Paradox with Inverse Probability Weighting
- Regression이나 Matching을 사용하기 어려운 경우라도, IPW는 사용할 수 있음
5) CEM(Coarsened Exact Matching)
- PSM를 보완할 수 있는가? - exact matching
- 벡터 거리의 유사성을 증가시킬 수 있지만, CEM은 불균형을 줄이는데 초점을 맟추고 있음
- 처리 그룹과 대조 그룹의 단위를 동일한 구간에 속하는 데이터로 매칭하는 방법
- 동일한 구간에 속하는 데이터에 대해 정확한 매칭을 적용
- CEM은 PSM보다 더 많은 관찰치(데이터)를 제외하는 경향이 있으므로, 분산이 더 높아질 수 있음. (Black et al. (2020))
- 충분한 관찰치를 유지할 수 있는 경우는 CEM이 더 선호됨
- PSM은 성향 점수의 균형뿐만 아니라, 공변량에 대한 다차원 균형을 추가 검증해야 하기 때문
⇒ 성향 점수가 같더라도, 개별 공변량의 수준은 다를 수 있기 때문임
⇒ 게임 숙련도와 과금액 두 가지 공변량을 고려한다고 가정했을 때, 성향점수가 같아도, 각 (feature의) 공변량은 다를 수 있음
- PSM은 성향 점수의 균형뿐만 아니라, 공변량에 대한 다차원 균형을 추가 검증해야 하기 때문
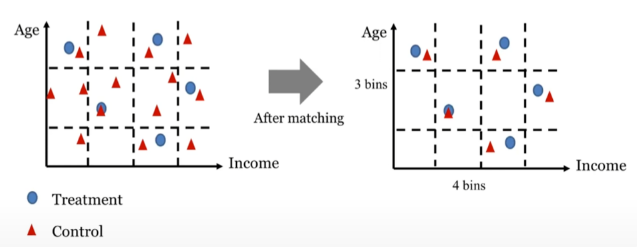
- 궁금한 점
CEM은 공변량을 ‘Coarsened’하게 만드는 것이 중요한데(위 이미지의 Grid처럼) Grid 범주를 얼만큼 설정하느냐에 따라서 PSM과 별 차이가 없지 않을까? 즉, parameter의 영향을 많이 받지 않을까?
6) Matching의 활용 - Extension
- 다중 처리 수준(Multiple levels of treatment) (Imai and van Dyk 2004)
- 처리가 두 개 이상의 범주로 나뉘는 것을 의미하며, 각 처리 수준에 대해 성향 점수를 별도로 계산하고, 다차원 성향 점수를 기반으로 관찰치를 matching할 수 있음
- 시즌 패스류 아이템들의 구매와, 구매하지 않은 유저들간의 Matching
- 해당 시즌에서 패스A와 패스B, 패스C가 있다고 가정함
- 단순히 공변량을 기준으로 매칭하면, 특정 패스 구매자들의 특성이 다른 패스 구매 집단에 영향을 미칠 수 있음. 즉, 패스A를 구매한 사람들이 패스B를 구매한 사람보다 과금액이 많다면, 패스A의 효과가 과대 추정될 수 있음
- 이러한 문제를 해결하기 위해, 다중 처리 수준에서는 각 치료군에 속할 확률을 추정하는 성향 점수를 사용할 수 있음
- Rolling Entry matching: 시간에 따라 변하는 데이터를 다룸
- 시간 t에서 처리 단위에 대한 공변량을 기반으로 성향 점수를 별도로 계산할 수 있음
- 시간 t에서 처리를 받는 단위와 모든 대조 단위를 대상으로 함
- 대조 단위가 시간 불변 특성과 변동 특성 모두에서 처리 그룹과 비교 가능성을 가지게 함
- 시간에 따라 변하는 특성(유저들의 플레이시간)과 시간이 변하지 않는 특성(과거 특정 아이템을 판매/판매종료한 시점) 모두를 고려할 수 있으며, 시간에 따라 변하는 데이터를 다루는 연구에서 유용하게 사용할 수 있을 것 같음
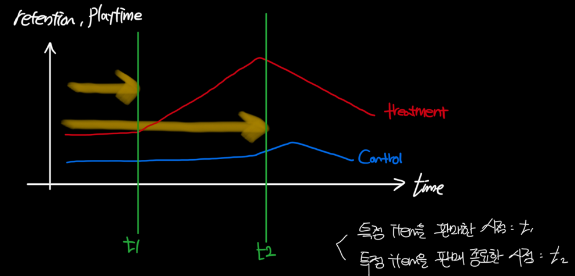
- Look-ahead matching (Bapna et al. 2018)
- 관찰되지 않은 변수-데이터에 대해, 특성이 유사한지 알 수 없는 문제를 해결
- 컨셉: 대조군과의 매칭이 아니라, 처치를 받은 그룹 내에서 매칭을 하는데, 그 시점의 차이를 이용해보고자 함
- 미래를 내다보고 분석 기간 이후의 treatment의 상태를 고려하여 matching하는 경우
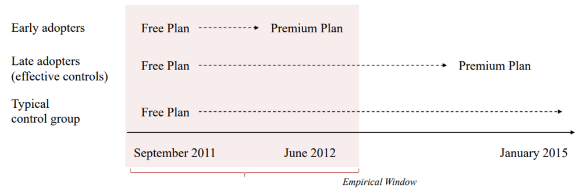
7) Matching의 한계
Regression과 Matching은 Selection observation에 대해 의존합니다.
즉, 선택 편향이 관찰 가능한 공변량에 의해 설명될 수 있다는 가정입니다.
- 관찰 가능한 변수에 대한 선택이 관찰 불가능한 변수에 대한 선택을 보장하지 않음
- 회귀분석과 매칭은 종종 다른 실험적 방법을 지원하기 위해서 활용됨
- 인과추론에서 최후의 수단으로써 사용되어야 한다.
- 단독으로 인과추론만을 위해 사용되기 보다는, 다른 실험을 지원하기 위해서 많이 활용됨
- 예를 들어, Control 변수를 추가한다거나.. 하는 방법들은 무작위 실험에 가깝게 만드는데 도움이 됨
- 당연한 이야기지만, Matching이나 Regression은 Variable Design이 가장 중요한 핵심이라고 함
- 번외로, 이는 Causal Graphs 이론으로 보완할 수 있음
- (개인적으로) Explainerable이 상대적으로 약하다..?
- 관찰된 변수를 사용하여 관찰되지 않은 변수를 통제할 수 있는지에 대한 설명이 부족할 수 있음
번외 2) Sensitivity Analysis to Omitted Variables
어쩔 수 없이, Regression과 Matching만을 사용할 수 밖에 없는 경우는 Omitted Variable Bias라는 Sensitivity Analysis(민감도 분석)이 굉장히 유용할 수 있다고 합니다.
예를 들어, 아래와 같이 X와 Y가 있고, C1과 C2라는 Control 변수가 있을 때, Regression으로 분석을 한다면, 아래와 같이 수식이 성립됩니다.
이 때, C1과 C2를 기반으로 PS(Propensive score)를 구할 수 있습니다. 이렇게 구한 PS를 기반으로, Matching을 통해서 Regression을 구할 수 있습니다.
여기서 우리는 C1과 C2만 고려하여, 분석을 하게 되는데, 가상의 관찰되지 않은 U가 있다고 한다면, 분석 결과는 어떻게 달라지는지 알아보는 개념입니다. 이미지와 수식은 아래와 같습니다.
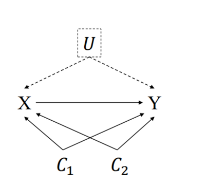
여기서 gamma1과 gamma2의 값을 0부터 늘려 나감으로써, 관찰되지 않은 변수의 효과를 측정합니다. 여기서 gamma 값이 매우 클 때만 정반대의 결과가 출력된다면, 관찰되지 않은 변수의 영향력은 작다고 추정할 수 있습니다.
8) Reference
