- Hadoop
분산 파일 시스템의 병렬처리 프레임워크에서 실행되는 플랫폼
-> 데이터의 양이 많아짐에 따라 분산해서 저장
why?
-> 한번에 큰 데이터를 한번에 저장하기 힘들기 때문에
-HDFS (Hadoop Distributed File System)
- 블록 파일 시스템과 디스크 블록과 같은 유형
- 마스터(데이터의 위치, 형식보관) - 슬레이브(실데이터 저장) 구조
- 슬레이브 노드의 쉬운 확장가능
- 신뢰성 보장 - 데이터 복제본 자동관리
- Block in Hadoop
-하나의 파일을 여러 개의 Block으로 저장한다.
process & thread
작업의 단위 / 흐름의 단위
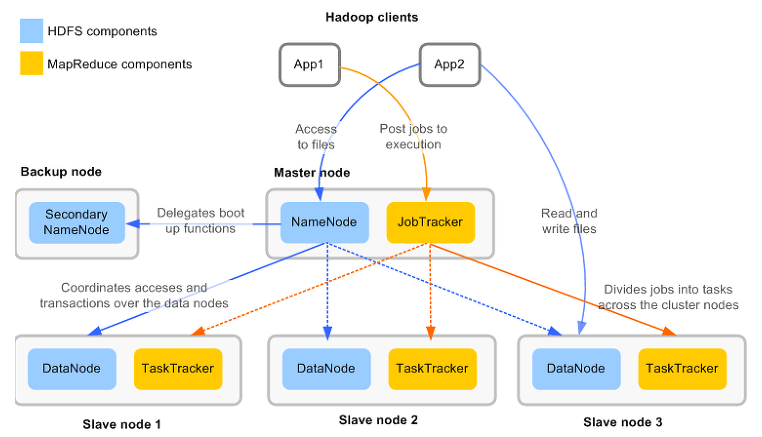
- NameNode (Master)
- 메타 데이터라고 부르는 파일 시스템의 전체 디렉터리 구조에 대해 스냅샷을 유지하고 클러스터에서 위치를 추적한다.
- HDFS 내의 모든 파일에 대한 블록과 해당 위치를 리스트한다.
-파일 시스템 이미지 파일 관리(fsimage)
-파일 시스템에 대한 Edit Log 관리(edits)
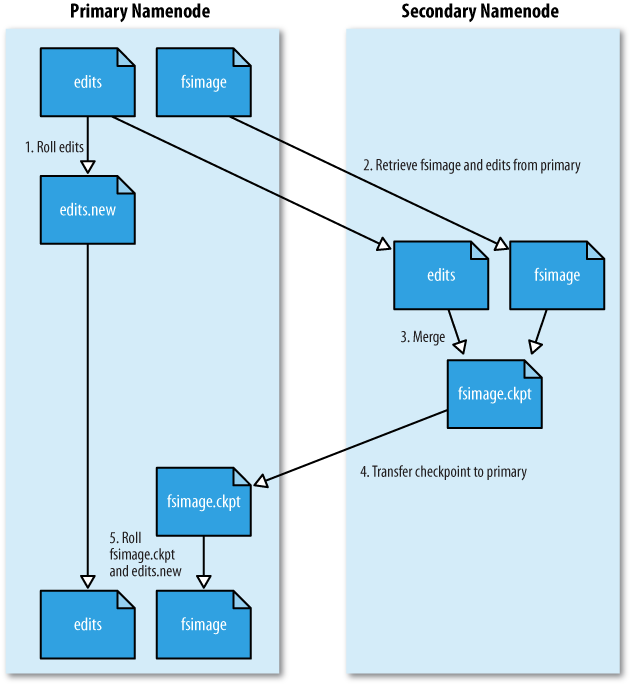
-Secondary NameNode
네임노드가 구동되면 Edits 파일이 주기적으로 생성되는데, 이는 디스크 부족문제 및 구동 시간 지연이 야기되는데 이를 해결하기 위한 방법이 SNN 이다.
주기적으로 머지하여 최신의 블록 상태를 유지하고 머지하면서 Edits 파일을 삭제하기 때문에 디스크 문제도 해결 할 수 있다.
- Data Node(Slave)
모든 데이터를 HDFS에 저장한다.
-파일 저장 & 업데이트
-Rack안에 Blocks 들이 존재
- JobTracker (Master)
Job을 관리 및 연산을 수행한다.
- TaskTracker (Slave)
그림과 같은 프로세스 과정이 진행된다.
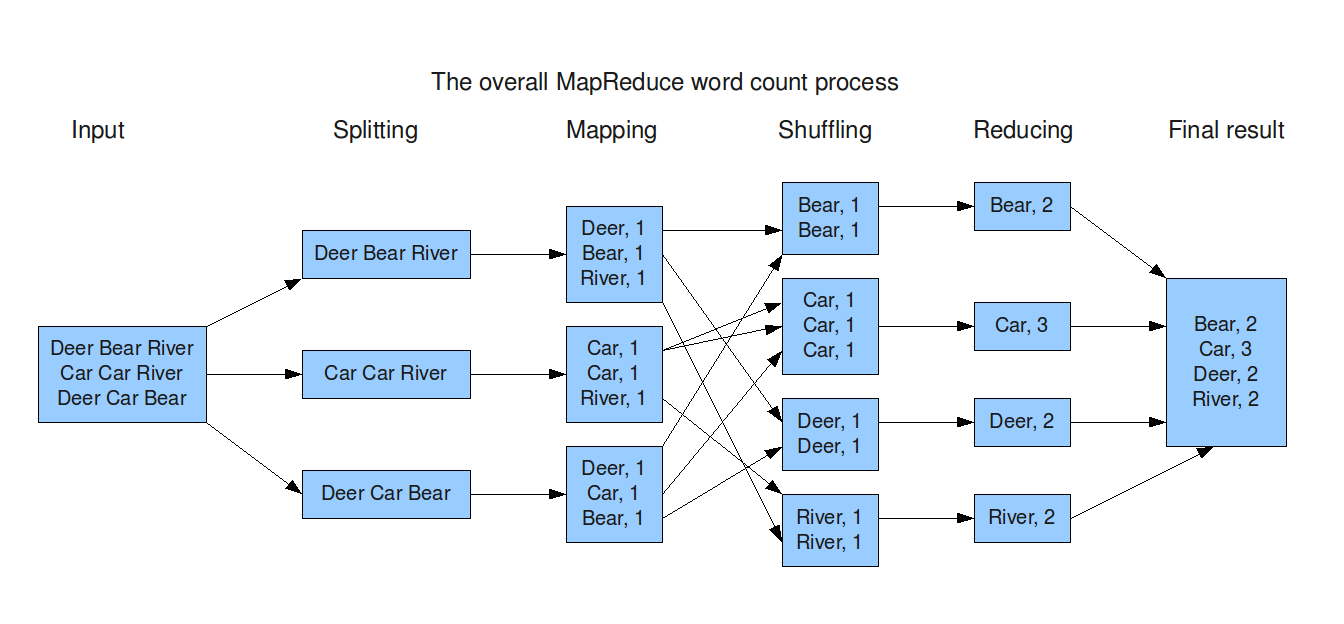
-MapReduce
HDFS에 분산 저장되어 있는 데이터를 병렬로 처리하여 취합하는 역할
Algorithm for Data Processing.
-Key,Value구조가 알고리즘의 핵심!
process : Map([key,value)] -> Merge & Sort -> Reduce [sum((key,value))]
-MapReduce's Component
-
Client : 구현된 mapreduce job을 제출하는 실행 주체
-
JobTracker : jon이 수행되는 전체 과정을 조정하고 job에 대해 Master 역할을 수행
-
TaskTracker : job에 대한 분할된 Task를 수행하며 실질적인 DataProcessing 주체.
-
HDFS : 각 단계 사이의 DataProcessing에서 발생하는 중간 파일들을 공유하기 위해 사용.
-
InputSplits : 물리적 Block들을 논리적으로 그룹핑한 개념.
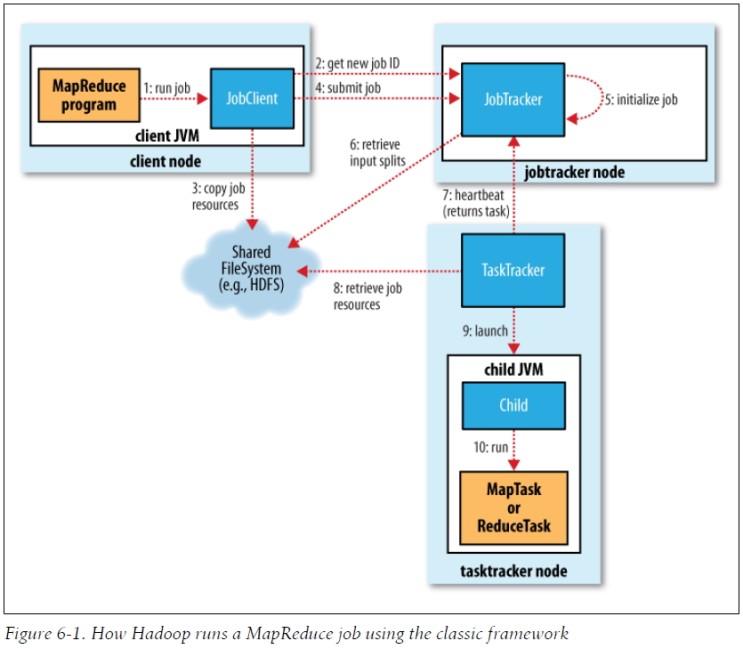
< MapReduce e.g>
Job 실행 -> 신규 Job id 할당 및 수신 -> Job Resource 공유 -> job 제출 & 초기화 -> Inputsplits 정보검색 -> TaskTracker에 Task할당 -> TaskTracker가 공유되어 있는 Job Resource를 Local로 복사 -> TaskTracker가 Child JVM 실행 -> MapTask or ReduceTask 실행
-YARN(Yet Another Resource Negotiator)
MapReduce에서 4,000 Node 이상의 클러스터 상에서 동작 시
병목현상 이슈가 발생하는데 이를 해결하고 보완하여 나온 것이 YARN
-
Resource Manager
-클러스터의 애플리케이션 작업 예약 및 리소스 모니터링을 담당 -
Node Manager
-컨테이너와 해당 리소스 사용량을 시작 및 모니터링 -> Resource Manager에 다시 보고 -
Container
-특정 리소스가 할당된 응용 프로그램 특정 프로그램을 실행 -
MapReduce
-google에서 도입한 분산 데이터 처리 알고리즘 , 대용량 데이터를 병렬로 처리하는 데 효과적.
YARN Flow
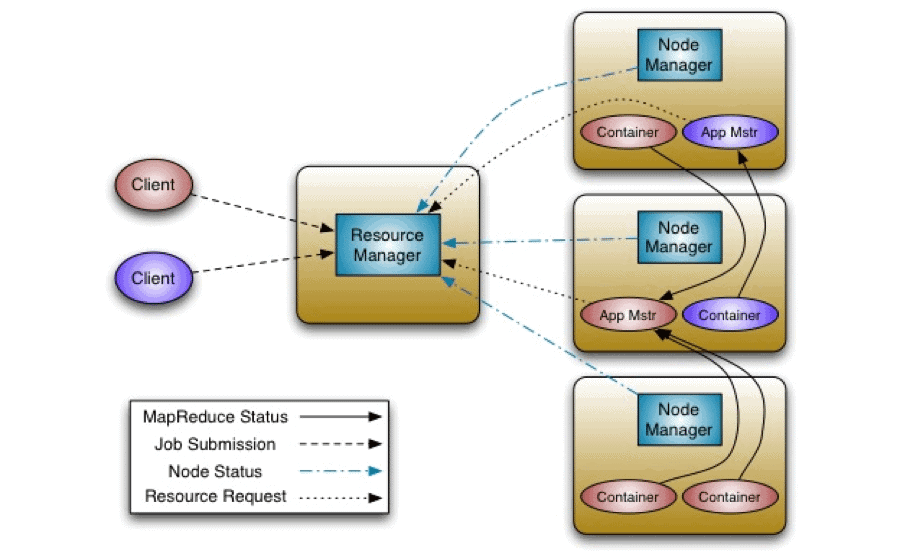
각각의 Node manager는 Resource manager에게 현재 상황에 대해서 지속적으로 Report를 해준다.
이때 Client에게 Job이 들어올 시, Report 받은 바탕으로 하여 가장 여유있는 Node에 해당하는,
App master에게 Job을 전달하고 해당 Job을 Container에서 수행한다.
