Spark
What is Spark?
인메모리 기반의 대용량 데이터 고속 처리 엔진으로 범용 분산 클러스터 컴퓨팅 프레임워크
-수평적 확장 가능
-속도가 느려도 많은 데이터의 연산이 가능 ( out of memory 발생 x )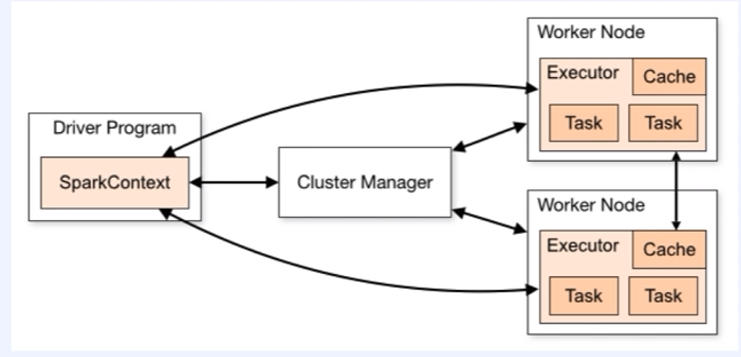 Driver program - Cluster manager - Worker node
Driver program - Cluster manager - Worker node
[프로세스 조직] - [소통구( 스케쥴링 / 자원관리 )] - [실제 연산 실행]
RDD(Resillient Distributed Dataset)
- 여러 분산 노드에 걸쳐 저장
- 변경이 불가
- 탄력적이고 불변하다.
- 노드가 에러가 날 시에 이전에 작성한 노드를 불러와서 복원 가능
- 탄력적이고 불변하다.
- Type-safe
- 컴파일시 Type을 판별 할 수 있기에 문제를 초기에 발견 가능
- Lazy evaluate
- 액션을 할때까지 변환하지 않는다.
- spark op = transfrom + action
- 여러개의 파티션으로 분리
ex) lines = sc.textFile(f"file:///{directory}/{filename}")
Data-Parallel
- 데이터를 여러개로 쪼개고
- 여러 쓰레드에서 각자 task적용
- 각자 만든 결과값을 합치는 과정
Distributed Data-Parallel
- 데이터를 여러개로 쪼개서 여러 노드로 보낸다
- 여러 노드에서 각자 독립적으로 task를 적용
- 각자 만든 결과값을 합치는 과정
Key-Value RDD
ex) 지역별 택시 운행수
- key: 지역ID
- value: 운행수
-
Reduction (요소를 모아서 합치는 작업)
- Reduce - Fold - GroupBy - Aggregate(zerovalue,seqOp,combOp) - 파티션에 누적할 시작 값, 타입 변경함수, 합치는 함수 - reduceByKey() : 키 값을 기준으로 테스크 처리 - groupByKey() : 키 값을 기준으로 value 묶기 - sortByKey() : 키 값을 기준으로 정렬 - keys() : 키 값 추출 - values() : value 값 추출
-
Join
- rightOuterJoin : 오른쪽에 있는 데이터 모두 출력 - leftOuterJoin : 왼쪽에 있는 데이터 모두 출력 - substractByKey :
Transformation
(결과 값으로 새로운 RDD를 반환 / 지연 실행 -> 메모리 최대 활용 ( in-memory))
-
narrow transformation
- 1:1 변환 - 정렬이 필요하지 않은 경우 - filter() : value를 포함하는지 안하는지를 활용하는 기능 - map() - flatmap() - sample() : 무작위로 value값을 추출하고자 할때 - ex) a.sample(True, .5 ,seed=n) - union() : value 합치기 -
wide transformaiton
- suffling : 여러노드에서 데이터를 합칠 때 발생함 ( 다른 요소 or RDD 참조할 때) -
Actions(결과 값을 연산하여 출력하거나 저장 / 즉시 실행)
- collect() : RDD 내의 value 값을 추출해준다 - countByValue() : value 값의 개수 카운트 - take() : head()와 같은 기능 - first(): 첫번째 value 값 - distinct() : unique() 같은 기능 - foreach()
Unstructure Data
- log file
- image
Semi Structure Data
- csv
- Json
- Xml
Structure Data
- Database

Concilio et Labore ( 지혜와 노력으로 )