[1] CASE문 활용
- CASE문이나 DECODE 함수를 활용하는 기법은 IFELSE 같은 분기조건을 포함한 복잡한 처리절차를 One-SQL로 구현하는 데 반드시 필요하다.
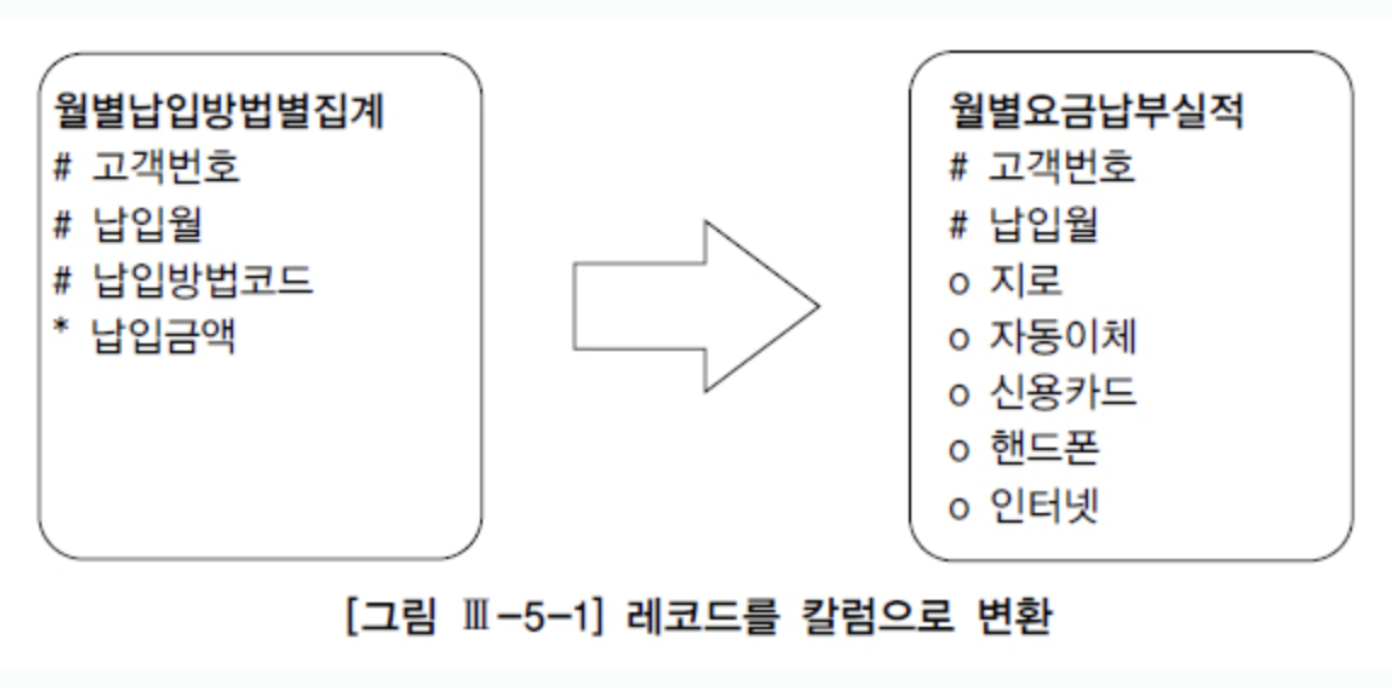
[예시] 왼쪽에 있는 월별 납입 방법별 집계 테이블을 읽어 오른쪽 월요금납부실적과 같은 형태로 가공.
- 동일 레코드를 반복 액세스하지 않고 얼마만큼 블록 액세스 양을 최소화할 수 있느냐에 달렸다.
-- 튜닝 후
INSERT INTO 월별요금납부실적 (고객번호, 납입월, 지로, 자동이체, 신용카드, 핸드폰, 인터넷)
SELECT 고객번호, 납입월 , NVL(SUM(CASE WHEN 납입방법코드 = 'A' THEN 납입금액 END), 0) 지로 ,
NVL(SUM(CASE WHEN 납입방법코드 = 'B' THEN 납입금액 END), 0) 자동이체 ,
NVL(SUM(CASE WHEN 납입방법코드 = 'C' THEN 납입금액 END), 0) 신용카드 ,
NVL(SUM(CASE WHEN 납입방법코드 = 'D' THEN 납입금액 END), 0) 핸드폰 ,
NVL(SUM(CASE WHEN 납입방법코드 = 'E' TJEM 납입금액 END), 0) 인터넷
FROM 월별납입방법별집계 WHERE 납입월 = '200903' GROUP BY 고객번호, 납입월 ;[2] 데이터 복제 기법 활용
- 전통적으로 많이 쓰던 방식
- 복제용 테이블(copy_t)을 미리 만들어두고 이를 활용한다.
- 이 테이블과 조인절 없이 조인(Cross Join)하면 카티션 곱이 발생해 데이터가 2배로 복제된다. 3배로 복제하려면 no <= 3 조건으로 바꿔주면 된다.
- Oracle 9i부터는 dual 테이블을 사용한다.
- dual 테이블에 start with절 없는 connect by 구문을 사용하면 두 레코드를 가진 집합이 자동으로 만들어진다.SQL> select rownum no from dual connect by level <= 2; SQL> select * from emp a, (select rownum no from dual connect by level <= 2) b;✅ connect by 절
- CONNECT BY 는 3개의 구문으로 구성된다.
WHERE : 데이터를 가져온 뒤 마지막으로 조건절에 맞게 정리한다.
START WITH : 어떤 데이터로 계층구조를 지정하는지 지정한다.- 가장 처음에 데이터를 거르는 플랜을 타게 되고, 따라서 이 컬럼에는 인덱스가 걸려있어야 성능을 보장받는다.
- CONNECT BY : 각 행들의 연결 관계를 설정한다.
- CONNECT BY 절의 결과에는 LEVEL 이라는 컬럼이 있으며, 이는 계층의 깊이를 의미한다.
- CONNECT BY 는 3개의 구문으로 구성된다.
[3] Union All을 활용한 M:N 관계의 조인
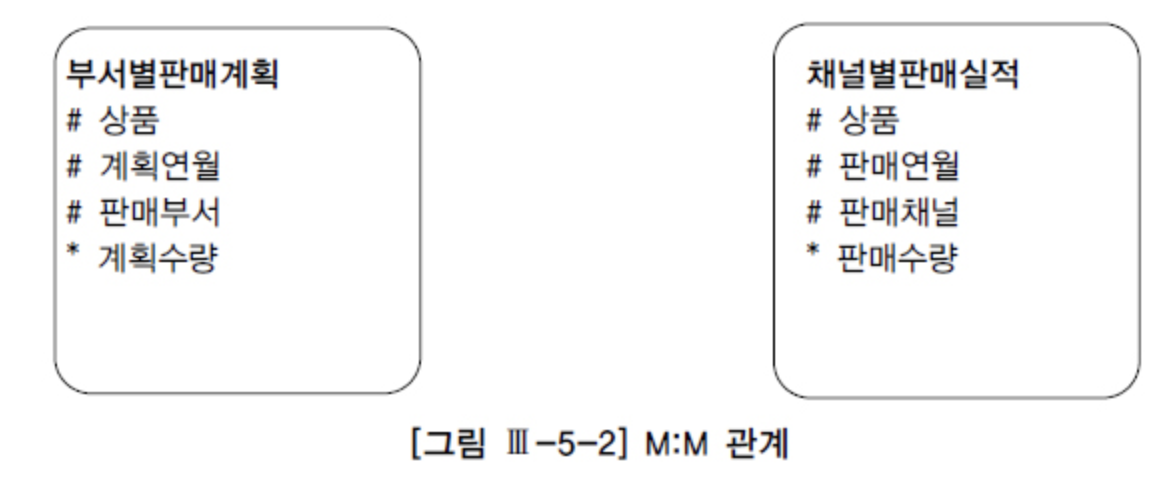
- 월별로 각 상품의 '계획' 대비 판매 실적을 집계 :: 상품과 연월을 기준으로 볼 때 두 테이블은 M:M 관계이므로 조인하면 카티션 곱이 발생한다.
- 상품, 연월 기준으로 group by를 먼저 수행하고 나면 두 집합은 1:1 관계가 되므로
Full Outer Join을 통해 원하는 결과집합을 얻을 수 있다. - Union All을 이용하면 M:M 관계의 조인이나 Full Outer Join을 쉽게 해결할 수 있다.
select 상품, 연월, nvl(sum(계획수량), 0) as 계획수량, nvl(sum(실적수량), 0) as 실적수량 from (select 상품 , 계획연월 as 연월 , 계획수량 , to_number(null) as 실적수량 from 부서별판매계획 where 계획연월 between '200901' and '200903' union all select 상품 , 판매연월 as 연월 , to_number(null) as 계획수량 , 판매수량 from 채널별판매실적 where 판매연월 between '200901' and '200903' ) a group by 상품, 연월; - 상품, 연월 기준으로 group by를 먼저 수행하고 나면 두 집합은 1:1 관계가 되므로
[4] 페이징 처리
(1) 일반적인 페이징 처리용 SQL
[예시] 관심 종목에 대해 사용자가 입력한 거래일시 이후 거래 데이터를 페이징 처리 방식으로 조회
- 첫 페이지만큼은 가장 최적의 수행 속도를 보인다.
- 대부분 업무에서 앞쪽 일부만 조회하므로 표준적인 페이징 처리 구현 패턴에 가장 적당.
- 만약 [종목코드 + 거래일시] 인덱스가 있으면 Sort 오퍼레이션 생략된다.
- 없더라도 TOP-N 쿼리 알고리즘 작동으로 SORT 부하 최소화 할 수 있다.
(2) 뒤쪽 페이지까지 자주 조회할 때
- 뒤쪽의 어떤 페이지로 이동하더라도 빠르게 조회되도록 구현하기 위해서는, 해당 페이지 레코드로 바로 찾아가도록 구현해야 한다.
- 뒤쪽 페이지까지 자주 조회할 때만약 사용자가 ‘다음’ 버튼을 계속 클릭해서 뒤쪽으로 많이 이동하는 업무라면 위 쿼리는 비효율적이다.
- 인덱스 도움을 받아 NOSORT 방식으로 처리하더라도 앞에서 읽었던 레코드들을 계속 반복적으로 액세스해야 하기 때문이다.
- 여기에 인덱스마저 없다면 전체 조회 대상 집합을 매번 반복적으로 액세스해야 한다.
- 뒤쪽의 어떤 페이지로 이동하더라도 빠르게 조회되도록 구현해야 한다면 앞쪽 레코드를 스캔하지 않고 해당 페이지 레코드로 바로 찾아가도록 구현해야 한다.
[예시] 첫 번째 페이지를 출력하고 나서 ‘다음’ 버튼을 누를 때
- 한 페이지에 10건씩 출력하는 것으로 가정한다.
- 첫 화면에서는 :trd_time 변수에 사용자가 입력한 거래일자 또는 거래일시를 바인딩한다.
- 사용자가 ‘다음(▶)’ 버튼을 눌렀을 때는 ‘이전’ 페이지에서 출력한 마지막 거래일시를 입력한다.
- COUNT(STOPKEY)는 [종목코드 + 거래일시] 순으로 정렬된 인덱스를 스캔하다가 11번째 레코드에서 멈추게 됨을 의미한다.
- ORDER BY 절이 사용됐음에도 실행계획에 소트 연산이 전혀 발생하지 않음을 확인
- 사용자가 ‘이전(◀)’ 버튼을 클릭했을 때에는 :trd_time 변수에는 이전 페이지에서 출력한 첫 번째 거래일시를 바인딩한다.
- ‘SORT (ORDER BY)’가 나타났지만, 'COUNT (STOPKEY)’ 바깥 쪽에 위치했으므로 조건절에 의해 선택된 11건에 대해서만 소트 연산을 수행한다.
- 인덱스를 거꾸로 읽었지만 화면에는 오름차순으로 출력되게 하려고 ORDER BY를 한번 더 사용한 것이다.
- 옵티마이저 힌트를 사용하면 SQL을 더 간단하게 구사할 수 있지만 인덱스 구성이 변경될 때 결과가 틀려질 위험성이 있다.
(3) Union All 활용
- 위의 설명한 2가지 방식은 사용자가 어떤 버튼(조회, 다음, 이전)을 눌렀는지에 따라 별도의 SQL을 호출하는 방식이다.
- Union All을 활용하면 하나의 SQL로 처리하는 것도 가능하다.
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM ( SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 시간별종목거래
WHERE :페이지이동 = 'NEXT' -- 첫 페이지 출력 시에도 'NEXT' 입력
AND 종목코드 = :isu_cd AND 거래일시 >= :trd_time
ORDER BY 거래일시 )
WHERE ROWNUM <= 11
UNION ALL
SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM ( SELECT 거래일시, 체결건수, 체결수량, 거래대금
FROM 시간별종목거래
WHERE :페이지이동 = 'PREV' AND 종목코드 = :isu_cd AND 거래일시 <= :trd_time
ORDER BY 거래일시 DESC )
WHERE ROWNUM <= 11
ORDER BY 거래일시[5] 윈도우 함수 활용
[예시] 장비측정 결과를 저장하는데 일련번호를 1씩 증가시키면서 측정값을 입력하고, 상태코드는 장비상태가 바뀔 때만 저장하려고한다. 조회시 상태코드가 NULL이면 가장 최근에 상태코드가 바뀐 레코드 값을 보여주려고 함.
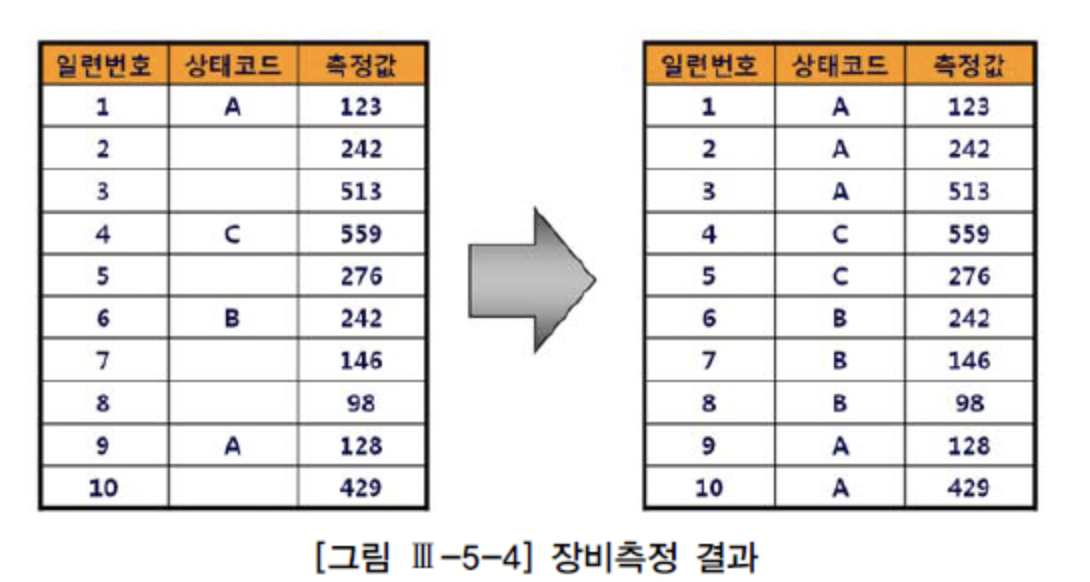
- 부분범위처리 방식으로 앞쪽 일부만 보다 멈춘다면 위 쿼리가 최적이다.
- 전체결과를 다 읽어야 한다면 윈도우 함수를 이용하는게 가장 쉽다.
- rows between unbounded preceding and current row 는 디폴트 값이므로 생략 가능하다.
select 일련번호 , 측정값
, last_value(상태코드 ignore nulls) over (order by 일련번호 rows between unbounded preceding and current row) 상태코드
from 장비측정
order by 일련번호[6] With 구문 활용
- With 절 처리 방식 : Oracle은 2가지 방식을 모두 지원하지만 SQL Server는 Inline 방식만 실행이 가능하다.
- Materialize 방식
- 내부적으로 임시 테이블을 생성함으로써 반복 재사용할 수 있다.
- 생성된 임시 데이터는 영구적인 오브젝트가 아니어서, With절을 선언한 SQL문이 실행되는 동안만 유지된다.
- 배치 프로그램에서 특정 데이터 집합을 반복적으로 사용하거나, 전체 처리 흐름을 단순화시킬 목적으로 임시 테이블을 자주 활용하곤 하는데, Materialize 방식의 With 절을 이용하면 명시적으로 오브젝트를 생성하지 않고도 같은 처리가 가능하다.
- Inline 방식
- 물리적으로 임시 테이블을 생성하지 않으며, 참조된 횟수만큼 런타임 시 반복 수행된다.
= Oracle의 경우 실행방식을 상황에 따라 옵티마이저가 결정하며 필요하다면 사용자가 힌트(materialize, inline)로써 지정이 가능하다.
- 물리적으로 임시 테이블을 생성하지 않으며, 참조된 횟수만큼 런타임 시 반복 수행된다.
- With절을 2개 이상 선언할 수 있으며, With절 내에서 다른 With절을 참조가 가능하다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’