✍️ 1번 : B*Tree 인덱스 구조
B*Tree 인덱스 구조
- 브랜치 블록의 각 로우는 하위 블록에 대한 주소값을 갖는다. 👉 ⭕️
- 리프 블록 각 로우의 키 값은 테이블 로우의 키 값과 일치한다. 👉 ⭕️
- 리프 블록끼리는 이중연결리스트(double linked list) 구조다. 👉 ⭕️
B*Tree 인덱스 구조 오답
- 브랜치 블록 각 로우의 키 값은 하위 블록 첫 번째 로우의 키 값과 일치한다. 👉 ❌
🍒 문제 해설
- 브랜치 블록의 각 로우는 하위 블록에 대한 주소값을 갖는다.
- 브랜치 블록 각 로우의 키 값은 하위 블록이 갖는 값의 범위를 의미한다.
- 리프 블록의 각 로우는 테이블 로우에 대한 주소값을 갖는다.
- 리프 블록 각 로우의 키 값과 테이블 로우의 키 값은 서로 일치한다.
- 리프 블록의 각 로우와 테이블 로우 간에는 1:1 관계다.
- 리프 블록끼리는 이중연결리스트(double linked list) 구조다.
🍋 기출 포인트
- 브랜치 블록 각 로우의 키 값은 하위 블록이 갖는 값의 범위를 의미한다.
- 리프 블록 각 로우의 키 값과 테이블 로우의 키 값은 서로 일치한다.
✍️ 2번 : 오라클 인덱스 ROWID를 구성하는 요소
오라클 인덱스 ROWID를 구성하는 요소
- 데이터파일 번호 👉 ⭕️
- 블록 번호 👉 ⭕️
- 블록 내 로우번호 👉 ⭕️
오라클 인덱스 ROWID를 구성하는 요소 오답
- 테이블스페이스 번호 👉 ❌
🍒 문제 해설
- ROWID는 「오브젝트 번호 + 데이터파일 번호 + 블록 번호 + 블록 내 로우번호로 구성된다.
🍋 기출 포인트
- 테이블스페이스는 인덱스 ROWID 구성요소가 아니다.
✍️ 3번 : B*Tree 인덱스 블록 액세스 순서
🍒 문제 해설
- 우선 수직적 탐색을 통해 40을 찾는다.
- 40이 없으면 그보다 큰 첫 번째 키 값을 찾는다.
- 수직적 탐색 과정에 1, 2, 6번 블록을 액세스한다.
- 6번 리프 블록에서 스캔을 시작해 8번 블록에서 61(60보다 큰 첫 번째 키 값)을 만나는 순간 스캔을 멈춘다.
🍋 기출 포인트
- B*Tree 인덱스를 탐색할 때는 우선 루트에서 리프 블룩까지 극적 탐색을 통해 스캔 시작 지점을 찾는다.
- 수직적 탐색을 통해 조건을 만족하는 첫번째 레코드를 찾았으면, 인덱스 리프 블록을 스캔하면서 찾고자 하는 데이터가 더 나타날 때까지 수평적 탐색을 진행한다.
✍️ 4번 : 인덱스 힌트 문법
[인덱스 구성]
고객_PK : 고객번호
고객_X1 : 가입일자 + 성별 + 고객명
SELECT /*+ */
FROM 고객 C
WHERE 고객명 = :CUST_NM
AND 가입일자 BETWEEN :ENT_DT1 AND :ENT_DT2;인덱스 힌트 문법
- INDEX (C) 👉 ⭕️
- INDEX ( C 고객_X1 ) 👉 ⭕️
- INDEX ( C (가입일자)) 👉 ⭕️
인덱스 힌트 문법 오답
- INDEX (C(가입일자, 고객명)) 👉 ❌
🍒 문제 해설
- 「가입일자 + 고객명」을 선두로 갖는 인덱스가 없으므로 4번 힌트는 무시된다.
- 힌트가 무시되어도 옵티마이저에 의해 고객_X1 인덱스가 선택될 수 있지만, Table Full Scan이 선택될 수도 있다.
- 힌트에서 컬럼명을 나열하는 경우 콤마(,)는 생략해도 된다.
🍋 기출 포인트
- 힌트에서 컬럼명을 나열하는 경우 컬럼 순서가 안 맞으면 힌트는 무시된다.
✍️ 5번 : SQL Server에서 원하는 조건으로 검색(SEEK)하도록 힌트 지정
[ 인덱스 구성 ]
고객_PK : 고객번호(클러스터형 인덱스)
고객_X1 : 고객명(비클러스터형 인덱스)
DECLARE @CUST_NO INT
SELECT 고객번호, 성별, 가입일자, 연락처
FROM 고객
WHERE 고객번호 = @CUST_NO ;SQL Server에서 원하는 조건으로 검색(SEEK)하도록 힌트 지정
- 👉 ⭕️
SELECT 고객번호, 성별, 가입일자, 연락처 FROM 고객 WITH(INDEX(1)) WHERE 고객번호 = @CUST_NO - 👉 ⭕️
SELECT 고객번호, 성별, 가입일자, 연락처 FROM 고객 WITH(INDEX(고객_PK)) WHERE 고객번호 = OCUST_NO - 👉 ⭕️
SELECT 고객번호, 성별, 가입일자, 연락처 FROM 고객 WITH(INDEX=고객_PK) WHERE 고객번호 = BCUST_NO
SQL Server에서 원하는 조건으로 검색(SEEK)하도록 힌트 지정 오답
1.👉 ❌
SELECT 고객번호, 성별, 가입일자, 연락처
FROM 고객
WHERE 고객번호 = OCUST_NO
OPTION (INDEX(고객_PK))🍒 문제 해설
-
WITH 절을 이용해 INDEX 힌트를 기술할 때는 일반적으로 2번 또는 3번을 사용한다.
-
WITH 절을 이용해 FORCESEEK 힌트를 기술하는 방법도 있다.
DECLARE @CUST_NO INT SELECT * FROM 고객 WITH FORCESEEK (고객_PK (고객번호))) WHERE 고객번호 = @CUST_NO; -
WITH 절을 이용해 FORCESCAN 힌트를 지정하면 고객번호로 검색(SEEK) 하지 않고 Full Scan한다.
DECLARE @CUST_NO INT SELECT * FROM 고객 WITH (FORCESCAN) WHERE 고객번호 = @CUST_NO -
WITH절에 INDEX(1)를 지정하면 고객번호로 클러스터형 인덱스를 검색한다.
-
클러스터형 인덱스가 없는 상황에서 WITH절에 INDEX (0)을 지정하면 테이블을 Full
Scan 하면서 조건절을 필터링한다.INDEX(1)을 지정하면 구문 오류가 발생한다. -
클러스터형 인덱스가 있는 상황에서 WITH절에 INDEX(0) 을 지정하면 클러스터형 인덱스를 Scan 하면서 고객번호를 필터링한다.
-
OPTION 절을 이용하려면 힌트를 아래와 같이 기술해야 한다.
DECLARE @CUST_NO INT SELECT * FROM 고객 WHERE 고객번호 = @CUST_NO OPTION (TABLE HINT(고객, INDEX(고객_PK)))
🍋 기출 포인트
- OPTION 절을 이용하려면 힌트를 아래와 같이 기술해야 한다.
SELECT *
FROM 고객
WHERE 고객번호 = @CUST_NO
OPTION (TABLE HINT(고객, INDEX(고객_PK)))- 클러스터형 인덱스가 없는 상황에서 WITH절에 INDEX (0)을 지정하면 테이블을 Full
Scan 하면서 조건절을 필터링한다.INDEX(1)을 지정하면 구문 오류가 발생한다.
✍️ 6번 : SQL Server에서 Full Scan 하면서 필터링하도록 유도
[인덱스 구성 ]
고객_PK : 고객번호(비클러스터형 인덱스)
고객_X1 : 고객명(비클러스터형 인덱스)
DECLARE @CUST_NM VARCHAR(10)
SELECT 고객번호, 성별, 가입일자, 연락처
FROM 고객
WHERE 고객명 = @CUST_NM ;SQL Server에서 Full Scan 하면서 필터링하도록 유도
- 👉 ⭕️
SELECT 고객번호, 성별, 가입일자, 연락처 FROM 고객 WITH (INDEX(0)) WHERE 고객명 = @CUST_NM - 👉 ⭕️
SELECT 고객번호, 성별, 가입일자, 연락처 FROM 고객 WITH ( FORCESCAN ) WHERE 고객명 = OCUST_NM - 👉 ⭕️
SELECT 고객번호, 성별, 가입일자, 연락처 FROM 고객 WHERE CONCAT(고객명, '') = OCUST_NM
SQL Server에서 Full Scan 하면서 필터링하도록 유도 오답
- 👉 ❌
SELECT 고객번호, 성별, 가입일자, 연락처 FROM 고객 WITH ( INDEX(고객_PK) ) WHERE 고객명 = OCUST_NM
🍒 문제 해설
- 클러스터형 인덱스가 없는 상황에서 WITH절에 INDEX(0) 을 지정하면 테이블을 Full Scan 하면서 조건절을 필터링한다. 참고로, INDEX(1)을 지정하면 구문 오류가 발생한다.
- 2번처럼 고객_PK 인덱스를 사용하도록 강제하면, 고객_PK 인덱스를 스캔하면서 얻은 RID로 테이블을 랜덤 액세스(=룩업)한다.
- 4번처럼 인덱스 컬럼을 가공하면 테이블을 Full Scan한다.
🍋 기출 포인트
- 2번처럼 고객_PK 인덱스를 사용하도록 강제하면, 고객_PK 인덱스를 스캔하면서 얻은 RID로 테이블을 랜덤 액세스(=룩업)한다.
✍️ 7번 : Index Range Scan
Index Range Scan
- B*Tree 인덱스의 가장 일반적이고 정상적인 형태의 스캔 방식이다. 👉 ⭕️
- 인덱스 루트에서 리프 블록까지 수직 탐색한 후에 리프 블록을 수평 탐색하는 방식이다. 👉 ⭕️
- 수평 탐색 범위는 인덱스 구성, 조건절 연산자에 따라 달라진다. 👉 ⭕️
Index Range Scan 오답
- Index Range Scan 하려면, 인덱스 선두컬럼에 대한 '=' 조건이 반드시 있어야 한다. 👉 ❌
🍋 기출 포인트
- Index Range Scan 하려면, WHERE 절에 인데 선두컬럼에 대한 조건이 반드시 있어야 하지만, '=' 조건일 필요는 없다. 부등호, WEEN, LIKE 등 모두 가능하다.
✍️ 8번 : Index Full Scan (그냥 풀스캔이 아님)
Index Full Scan
- 결과집합을 모두 출력한다면, 인덱스 리프 블록을 처음부터 끝까지 모두 스캔하게 된다. 👉 ⭕️
- 인덱스를 Full Scan 하면서 테이블 데이터를 액세스하는 방식으로 전체 결과집합을 추출해하는 상황이라면, 인덱스 필터 조건을 만족하는 데이터가 적을수록 효과적이다. 👉 ⭕️
- 인덱스를 Full Scan 하면서 테이블 데이터를 액세스하는 방식으로 전체 결과집합 중 앞쪽 일부만 스캔하고 멈출 수 있는(=부분범위 처리) 상황이라면, 인덱스 필터 조건을 만족하는 데이터가 많을수록 효과적이다. 👉 ⭕️
Index Full Scan 오답
- INDEX_FS 힌트로 유도한다. 👉 ❌
🍒 문제 해설
- 오라클은 INDEXFS 힌트를 제공하지 않는다. INDEX 힌트로 지정한 인덱스 선두 컬럼이 조건절에 없으면 _INDEX FULL SCAN이 자동 선택되므로 별도 힌트가 필요하지 않다.
- 인덱스 선두 컬럼이 조건절에 없으면 Index Range Scan이 불가능하다.이 때 테이블을 Full Scan해야 하는데 '컬럼이 많은 큰 테이블' 을 스캔하려면 블록 I/O가 많이 발생하므로 성능이 느리다. 그럴 때 컬럼이 적은 인덱스를 스캔하여 I/O 발생량을 줄인다.
- 단, 인덱스 필터 조건을 만족하는 데이터가 적어야 한다. 필터 조건을 만족하는 데이터가 많으면 테이블 랜덤 액세스도 그만큼 많이 발생하므로 테이블 전체 스캔보다 성능이 훨씬 더 느려진다.
- 필터 조건을 만족하는 데이터가 많더라도 결과집합 중 앞쪽 일부만 스캔하고 멈춘다면, 즉 ,부분범위 처리를 활용할 수 있다면, Index Full Scan이 효과적일 수 있다. 인덱스 앞쪽에서 조건을 만족하는 데이터를 빨리 찾을 수 있기 때문이다.
🍋 기출 포인트
- 오라클은 INDEXFS 힌트를 제공하지 않는다. INDEX 힌트로 지정한 인덱스 선두 컬럼이 조건절에 없으면 _INDEX FULL SCAN이 자동 선택되므로 별도 힌트가 필요하지 않다.
- 인덱스 선두 컬럼이 조건절에 없으면 Index Range Scan이 불가능하다.이 때 테이블을 Full Scan해야 하는데 '컬럼이 많은 큰 테이블' 을 스캔하려면 블록 I/O가 많이 발생하므로 성능이 느리다. 그럴 때 컬럼이 적은 인덱스를 스캔하여 I/O 발생량을 줄인다.
✍️ 9번 : 옵티마이저의 스캔 방식을 선택
select 상품ID, 주문수량, 주문가격, 할인률
from 주문상품
where 주문일자 = :ord_dt
and 고객ID = cust_id주문일자 + 고객ID + 상품 ID 순으로 구성된 주문상품_PK 인덱스를 사용할 때 옵티마이저가 사용하는 스캔 방식
- Index Range Scan 👉 ⭕️
스캔 방식 오답
- Index Unique Scan 👉 ❌
- Index Full Scan 👉 ❌
- Index Skip Scan 👉 ❌
🍋 기출 포인트
- 전체가 아닌 일부 컬럼으로 검색할 때는 Range Scan이 선택된다.
✍️ 10번 : Index Fast Full Scan
Index Fast Full Scan
- Multiblock I/O 방식을 사용한다. 👉 ⭕️
- 병렬 스캔도 가능하다. 👉 ⭕️
- 인덱스에 포함된 컬럼으로만 조회할 때 사용할 수 있다. 👉 ⭕️
Index Fast Full Scan 오답
- 리프 블록만 빠르게 스캔하므로 인덱스 정렬 순서대로 결과집합을 출력한다. 👉 ❌
🍋 기출 포인트
- Index Fast Full Scan 인덱스 리프 블록끼리의 논리적인 연결 순서를 따르지 않고 Table Full Scan처럼 HWM 아래 익스텐트 전체를 Multiblock I/O 방식으로 Full Scan 하므로 결과 집합의 순서를 보장하지 않는다.
✍️ 11번 : Index Skip Scan
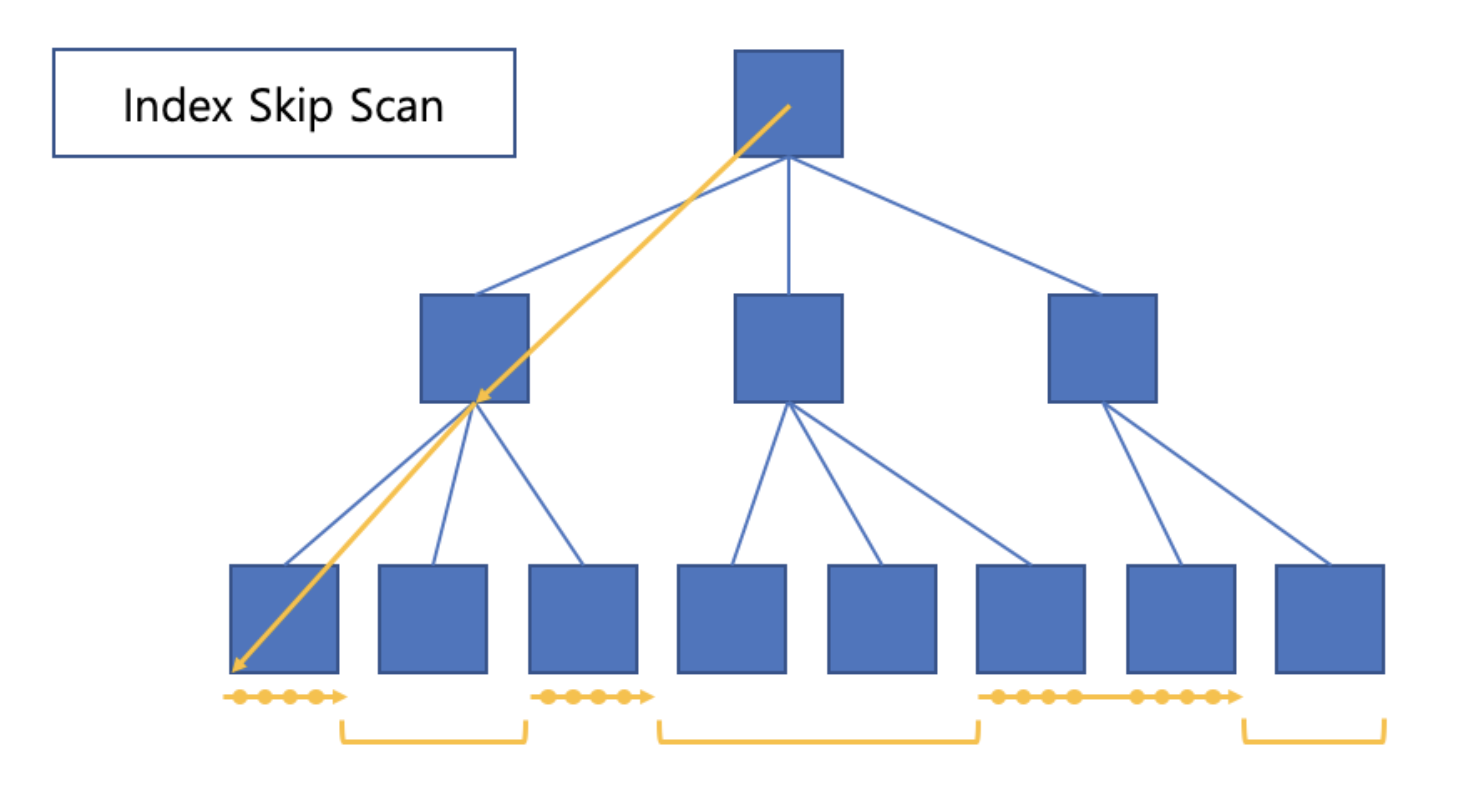
Index Skip Scan
- index_ss 힌트로 유도한다. 👉 ⭕️
- 인덱스 선두 컬럼이 조건절에 있을 때도 사용할 수 있다. 👉 ⭕️
- 인덱스 선두 컬럼이 조건절에 없을 때 사용할 수 있는 스캔 방식 중 하나다. 👉 ⭕️
Index Skip Scan 오답
- 조건절에 누락된 인덱스 선두 컬럼에 대한 IN 조건절을 옵티마이저가 추가해 줌으로써 IN-List Iterator 방식으로 인덱스를 스캔하는 방식이다. 👉 ❌
🍋 기출 포인트
- 조건절에 누락된 인덱스 선두 컬럼에 대한 IN 조건절을 추가해 주는 튜닝 기법과 용도는 비슷하지만, 인덱스 스캔 원리는 다르다.
✍️ 12번 : 활용 가능한 인덱스 스캔 방식
ALTER TABLE 고객 ADD CONSTRAINT 고객_PK PRIMARY KEY(고객번호);
CREATE INDEX 고객_X01 ON 고객(고객등급, 연령);
SELECT 고객번호, 고객명, 가입일시, 고객등급, 연령, 연락처
FROM 고객
WHERE 연령 BETWEEN 20 AND 40
ORDER BY 고객번호;활용 가능한 인덱스 스캔 방식
- INDEX FULL SCAN 👉 ⭕️
- INDEX SKIP SCAN 👉 ⭕️
활용 가능한 인덱스 스캔 방식 오답
- INDEX RANGE SCAN 👉 ❌
- INDEX FAST FULL SCAN 👉 ❌
🍋 기출 포인트
- 두 인덱스 모두 선두 컬럼이 조건절에 없으므로 Index Range Scan은 불
가능하다. - 고객등급의 NDV가 적을수록 Skip Scan이 유리하다.
- 인덱스에 없는 컬럼을 포함하므로 Index Fast Full Scan은 불가능하다.
✍️ 13번 : 활용 가능한 인덱스 스캔 방식
ALTER TABLE 고객 ADD CONSTRAINT 고객_PK PRIMARY KEY(고객번호);
CREATE INDEX 고객_XB1 ON 고객(연령, 고객명);
SELECT 고객번호, 고객명, 가입일시, 고객등급, 연령, 연락처
FROM 고객
WHERE 연령 BETWEEN 20 AND 40
AND 고객명 = '홍길동'
ORDER BY 고객번호;활용 가능한 인덱스 스캔 방식
- INDEX RANGE SCAN 👉 ⭕️
- INDEX FULL SCAN 👉 ⭕️
- INDEX SKIP SCAN 👉 ⭕️
활용 가능한 인덱스 스캔 방식 오답
- INDEX FAST FULL SCAN 👉 ❌
🍋 기출 포인트
- Index Skip Scan 도 가능하며, 고객 중 동명이인이 거의 없다면 Range Scan 보다 Skip Scan이 유리하다.
🍒 문제 해설
- 고객_PK를 사용하도록 힌트로 유도하면 고객번호가 조건절에 없으므로 Index Full Scan하게된다.
- 고객_XB1 를 사용하면 선두컬럼인 연령이 조건절에 있으므로 Index Range Scan이 가능하다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’