✍️ 14번 : Index Skip Scan 방식으로 실행되지 않는 SQL
CREATE INDEX 고객_X01 ON 고객(거주지역, 성별, 가입일자);
CREATE INDEX 고객_X02 ON 고객(고객등급, 생일);Index Skip Scan 방식으로 실행되지 않는 SQL
- 👉 ⭕️
SELECT * FROM 고객 WHERE 가입일자 BETWEEN '20210201' AND '20210228' ; - 👉 ⭕️
SELECT * FROM 고객 WHERE 거주지역 = '충청' AND 가입일자 BETWEEN '20210201' AND 20210228'; - 👉 ⭕️
SELECT * FROM 고객 WHERE 생일 = "0826" AND 고객등급 BETWEEN 'A' AND 'C'
Index Full Scan 오답
- 👉 ❌
SELECT * FROM 고객 WHERE 고객등급 IN ('A', 'B', 'C') AND 생일 = '0326'
🍋 기출 포인트
- ③번 처럼 IN 조건이 인덱스 액세스 조건일 때는 Skip Scan을 사용할 수 없다.
🍒 문제 해설
- ①번과 ②번은 고객_X01 인덱스를 Skip Scan 할 수 있다.
Index Skip Scan은 NDV가 적은 인덱스 선두 컬럼이 조건절에 없을 때 유용한 스캔 방식인데,①번처럼 NDV가 적은 두 개의 선두컬럼이 모두 조건절에 없는 경우에도 사용할 수 있다. - ②번 SQL처럼 선두 컬럼 (=거주지역)에 대한 조건절은 있고, 중간 컬럼(=성별)에 대한 조건절이 없는 경우에도 Skip Scan을 사용할 수 있다.Index Skip Scan을 사용한다면, 거주지역 = '충청'인 구간에서 가입일자가 '20210201'보다 크거나 같고 ‘20210228‘보다 작거나 같은 레코드를 '포함할 가능성이 있는 리프 블록만' 골라서 액세스할 수 있다.
- 만약 ②번 SQL에 Index Range Scan을 사용한다면, 거주지역 = '충청인 인덱스 구간을 '모두' 스캔해야 한다.
- 선두 컬럼이 부등호, BETWEEN, LIKE 같은 범위검색 조건일 때도 Index Skip Scan을 사용할 수 있다. Skip Scan을 사용한다면, 고객등급 BETWEEN 조건을 만족하는 인덱스 구간에서 생일 = '0326'인 레코드를 '포함할 가능성이 있는 리프 블록만 골라서 액세스할 수 있다.
- ④번 SQL에 고객_X02 인덱스를 Range Scan을 사용한다면, 고객등급 BETWEEN 조건을 만족하는 인덱스 구간을 '모두' 스캔해야 한다.
✍️ 15번 : B*Tree 인덱스에 생길 수 있는 현상
B*Tree 인덱스에 생길 수 있는 현상
- Index Skew 👉 ⭕️
- Index Sparse 👉 ⭕️
- Index Fragmentation 👉 ⭕️
B*Tree 인덱스에 생길 수 있는 현상 오답
- Unbalanced Index 👉 ❌
🍋 기출 포인트
- B*Tree 인덱스의 'B'는 'Balanced'의 약자로서, 인덱스 루트로부터 모든 리프 블록까지의 높이(height)가 항상 동일함을 의미한다. 따라서 인덱스 높이가 다른 불균형(Unbalanced) 현상은 절대 발생하지 않는다.
- 불균형은 생길 수 없지만 Index Fragmentation에 의한 Index Skew 또는 Sparse 현상이 생기는 경우는 종종 있고, 이는 인덱스 스캔 효율에 나쁜 영향을 미칠 수 있다.
🍒 문제 해설
- Index Skew는 인덱스 엔트리가 왼쪽 또는 오른쪽에 치우치는 현상을 말한다.예를 들어, 시계열적으로 증가하는 인덱스에서 과거 데이터를 일괄 삭제하고 나면 왼쪽 리프 블록들은 텅비는 반면, 오른쪽 블록들은 꽉 찬 상태가 된다.
- Index Sparse는 인덱스 블록 전반에 걸쳐 밀도(density)가 떨어지는 현상을 말한다.
- B*Tree 인덱스의 'B'는 'Balanced'의 약자로서, 인덱스 루트로부터 모든 리프 블록까지의 높이(height)가 항상 동일함을 의미한다. 따라서 인덱스 높이가 다른 불균형(Unbalanced) 현상은 절대 발생하지 않는다.
✍️ 16번 : 읽기 위주의 대용량 DW 환경에 가장 적합한 인덱스
읽기 위주의 대용량 DW 환경에 가장 적합한 인덱스
- 비트맵 인덱스 👉 ⭕️
읽기 위주의 대용량 DW 환경에 가장 적합한 인덱스 오답
- BTree 인덱스 👉 ❌
- 함수기반 인덱스 👉 ❌
- 리버스 키 인덱스 👉 ❌
🍋 기출 포인트
- 비트맵 인덱스는 주로 읽기 위주의 대용량 DW(특히 OLAP) 환경에 사용한다.
🍒 문제 해설
🍉 자꾸 자꾸 헷갈리는 비트맵 인덱스 정리
- 비트맵 인덱스의 기본 구조는 다음과 같다.
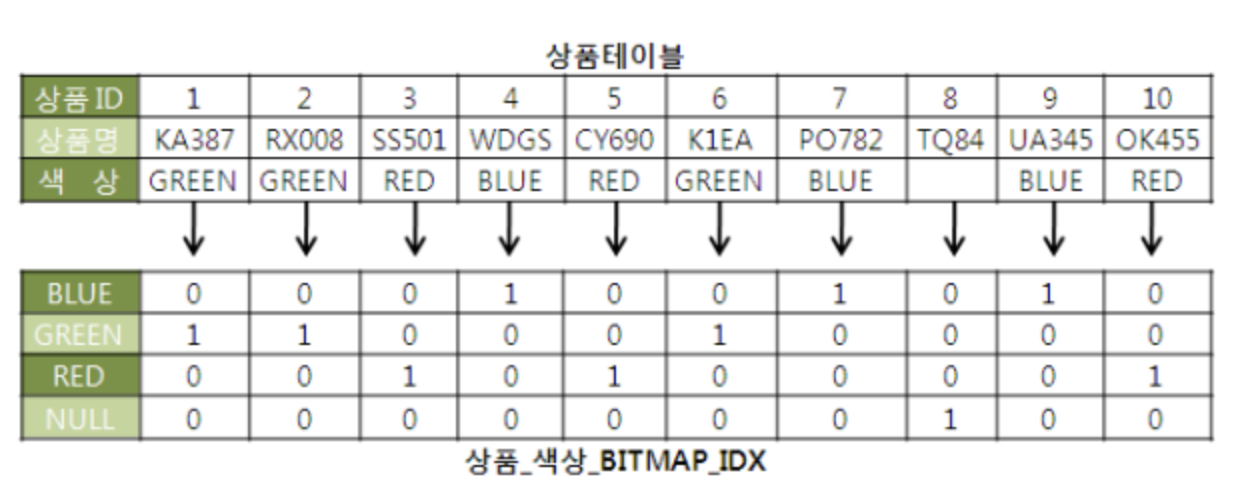

- 비트맵 인덱스는 여러 인덱스를 동시에 사용할 수 있다.
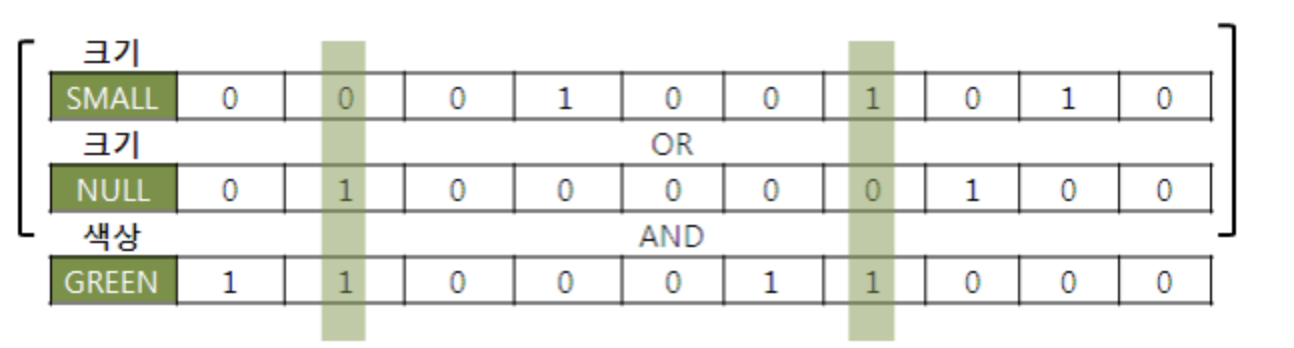
- 비트맵 인덱스의 키값이 많을 때는 다음과 같다.
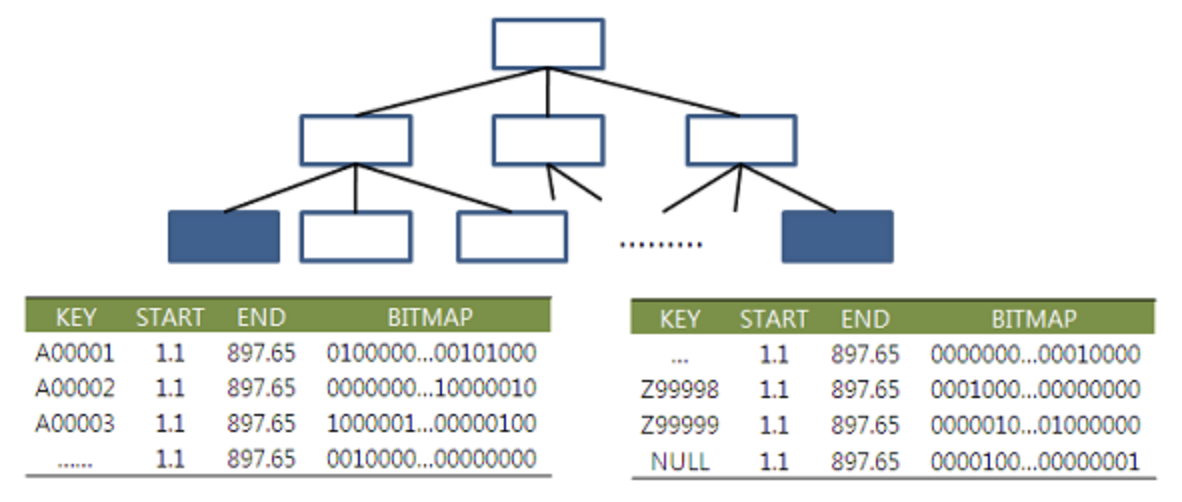
✅ 비트맵(Bitmap) 인덱스
- 비트맵 인덱스는 성별처럼 Distinct Value 개수가 적을 때 저장효율이 매우 좋다.
- 그런 컬럼이라면 B*Tree 인덱스보다 훨씬 적은 용량을 차지하므로 인덱스가 여러 개 필요한 대용량
테이블에 유용하다.- 주로 다양한 분석관점(Dimension)을 가진 팩트 (Fact) 테이블이 여기에속한다.
- 여러 개 비트맵 인덱스로 Bitwise연산을 수행함으로써 테이블 액세스량을 크게 줄일 수 있다면 극적인 성능 향상을 가져다준다.
= 따라서 다양한 조건절이 사용되는, 특히 정형화되지 않은 임의 질의(ad-hoc query)가
많은 대용량 DW/OLAP 환경에 적합하다.- 다만, 비트맵 인덱스는 Lock에 의한 DML 부하가 심한 것이 단점이다.
- 레코드 하나만 변경되더라도 해당 비트맵 범위에 속한 모든 레코드에 lock이 걸린다.
- OLTP성 환경에 비트맵 인덱스를 쓸 수 없는 이유가 바로 여기에 있다.
특정 테이블을 동시에 INSERT 하려는 다중 트랜잭션에 의해 인덱스 맨 우측(마지막) 리프 블록에 경
합이 발생하는 경우가 종종 있다. SQL 수정 없이도 인덱스 블록 경합을 해소하는 데 도움을 줄 수 있
는 인덱스를 고르시오.
✍️ 18번 : 인덱스 블록 경합을 해소하는 데 도움을 줄 수 있는 인덱스
특정 테이블을 동시에 INSERT 하려는 다중 트랜잭션에 의해 인덱스 맨 우측(마지막) 리프 블록에 경합이 발생하는 경우 SQL 수정 없이도 인덱스 블록 경합을 해소하는 데 도움을 줄 수 있는 인덱스
- 리버스 키 인덱스 👉 ⭕️
✅ 리버스 키(Reverse Key) 인덱스
일련번호, 입력일시, 변경일시 등 오름차순 한 방향으로만 값이 증가하는 컬럼에 인덱스
를 생성하면, 동시에 INSERT 하려는 다중 트랜잭션에 의해 맨 우측(마지막) 리프 블록에 경
합이 발생할 수 있다. 그럴 때 인덱스 키 값을 역으로(reverse) 변환해서 저장하면 신규로
INSERT하는 값들이 여러 리프 블록에 흩어지므로 경합도 자연스럽게 줄어든다.CREATE INDEX HOT_TABLE_R1 ON HOT_TABLE ( RIGHT_GROWING_COL ) REVERSE;
🍋 기출 포인트
- 리버스 키 인덱스는 Right Growing(=Right Hand) Index에 발생하는 블록 경합을 해소하는
데 도움을 줄 수 있다.
🍒 문제 해설
-
함수기반 인덱스를 활용해도 같은 효과를 얻을 수 있지만, SQL 조건절을 수정해야 한다.
CREATE INDEX HOT_TABLE_R1 ON HOT_TABLE (REVERSE(RIGHT_GROWING_COL)); SELECT * FROM HOT_TABLE A WHERE REVERSE(RIGHT_GROWING_COL) = REVERSE(KEYWORD);
✍️ 19번 : 인덱스를 이용한 테이블 랜덤 액세스의 부담을 줄이는 기능
인덱스를 이용한 테이블 랜덤 액세스의 부담을 줄이는 기능
- IOT(Index-Organized Table) 👉 ⭕️
- 클러스터 👉 ⭕️
- 테이블 파티션 👉 ⭕️
인덱스를 이용한 테이블 랜덤 액세스의 부담을 줄이는 기능 오답
- 리버스 키 인덱스 👉 ❌
🍋 기출 포인트
- IOT는 모두 인덱스 리프 블록에 저장하므로 테이블 랜덤 액세스가 전혀 발생하지 않는다.
- 클러스터는 값이 같은 레코드를 한 블록(데이터가 많을 경우 연결된 여러 블록)에 모아
서 저장한다. - 테이블 파티션은 특정 조건을 만족하는 데이터를 인덱스를 이용한 랜덤 액세스가 아닌 Full
Scan 방식으로 빠르게 찾을 수 있다.
🍒 문제 해설
- IOT는 테이블을 인덱스 구조로 관리한다. 일반 힙(Heap) 구조 테이블은 값을 무작위로
입력하지만, IOT는 지정한 키 값 순으로 정렬 상태를 유지한다. 키 값 이외의 컬럼도 모
두 인덱스 리프 블록에 저장하므로 테이블 랜덤 액세스가 전혀 발생하지 않는다. - 클러스터는 값이 같은 레코드를 한 블록(데이터가 많을 경우 연결된 여러 블록)에 모아
서 저장하므로 인덱스를 이용한 테이블 랜덤 액세스를 줄이는 데 도움을 준다. - 테이블 파티션은 사용자가 지정한 기준에 따라 데이터를 세그먼트 단위로 모아서 저장한
다. 따라서 특정 조건을 만족하는 데이터를 인덱스를 이용한 랜덤 액세스가 아닌 Full
Scan 방식으로 빠르게 찾을 수 있다.
✍️ 20번 : IOT(Index-Organized Table)의 용도
IOT(Index-Organized Table)의 용도
- PK를 구성하는 「사원번호 + 화면 ID + 사용일시」 이외에 일반 속성이 없는 화면 사용 로그 테이블 👉 ⭕️
- 테이블에 데이터가 일자 순으로 저장되지만, 주로 사원번호로 월간 또는 연간 실적을 조화하는 영업실적 테이블 👉 ⭕️
- 주로 한 달 이상의 넓은 범위로 조회하는 영업통계 테이블 👉 ⭕️
IOT(Index-Organized Table)의 용도 오답
- 주로 고객번호로 조회하는 고객 테이블 👉 ❌
🍋 기출 포인트
- 인덱스를 사용해아 함과 동시에 넓은 범위를 스캔해야할 때 랜덤 액세스 부하를 줄이기 위해 IOT(Index-Organized Table)를 사용한다.
- 일반 속성이 없고 PK가 「사원번호+ 화면ID + 사용일시 인 화면사용로그 테이블을 IOT로 구성하면, 별도 PK 인덱스를 생성하지 않아도 되므로 공간을 절약할 수 있고 Insert 성능도 높일 수 있다.
- 영업실적 테이블이 사원번호 순으로 정렬 되도록 IOT를 구성하면, 같은 사원의 영업실적끼리 모아서 저장하므로 사원번호로 조회하는 쿼리 성능을 높일 수 있다.
- 고객번호로 한 건씩 조회할 때는 데이터를 모아서 저장하는 데 따른 이점을 얻을 수 없
다.
🍒 문제 해설
- IOT는 PK 순으로 정렬 상태를 유지하는 테이블이다.
- 고객 테이블은 일반적으로 PK 이외 속성도 많으므로 이를 모두 IOT 리프 불
록에 저장할 경우, 인덱스 Depth가 증가하고 블록 I/O를 증가시킴으로써 테이블 랜덤 액
세스 감소 효과를 상쇄하고 만다. - 영업통계 테이블을 일자순으로 정렬되도록 IOT를 구성하면, 한 달 이상의 넓은 범위로
조회하더라도 테이블 랜덤 액세스가 전혀 발생하지 않아 빠른 조회가 가능하다.
✍️ 21번 : SQL Server 클러스터형 인덱스
SQL Server 클러스터형 인덱스
- 인덱스에서 테이블로의 랜덤 액세스 부하를 줄이는 용도로 개발되었다. 👉 ⭕️
- 클러스터형 인덱스는 한 개만 생성할 수 있다. 👉 ⭕️
- 클러스터형 인덱스를 생성하면, 다른 비클러스터형 인덱스들은 자동 재구성된다. 👉 ⭕️
SQL Server 클러스터형 인덱스 오답
- 클러스터형 인덱스를 생성하는 기준은 PK 컬럼어야 한다. 👉 ❌
🍋 기출 포인트
- SQL Server 클러스터형 인덱스는 PK가 아닌 컬럼으로도 IOT를 생성할 수 있다.
- 오라클의 IOT와 SQL Server의 클러스터형 인덱스는 데이터를 정렬하는 기준을 정의하는 기능이며 때문에 테이블에 한 개만 생성할 수 있다.
🍒 문제 해설
- 오라클은 PK 컬럼으로 IOT를 정의해야 한다.
✍️ 22번 : Index Range Scan이 가능한 SQL
Index Range Scan이 가능한 SQL
- SELECT * FROM 업체 WHERE 업체명 = NVL(:VAL, '대한')
Index Range Scan이 불가능한 SQL
- SELECT * FROM 업체 WHERE 업체명 LIKE '%대한%'
- SELECT * FROM 업체 WHERE 업체명 NOT LIKE '대한'
- SELECT * FROM 업체 WHERE SUBSTR(업체명,1,2) = '대한'
🍋 기출 포인트
- NVL은 INDEX RANGE SCAN이 가능하다.즉, 수직적 탐색이 가능하다.:VAL 변수에 값을 입력하면 그값으로, 입력하지 않으면 '대한'으로 인덱스를 탐색한다.
🍒 문제 해설
- 인덱스를 정상적으로 Range Scan 할 수 없는 이유는 인덱스 스캔 시작점을 찾을 수 없기 때문이다.
- 인덱스 액세스 조건 컬럼을 조건절에서 가공하는 경우 인덱스를 Range Scan 하지 못한다.인덱스에는 가공하지 않은 값이 저장되어 있기 때문이다.
- LIKE로 중간 값을 검색할 때도 인덱스를 Range Scan 하지 못한다.
✍️ 23번 : Index Range Scan이 불가능한 SQL

Index Range Scan이 불가능한 SQL
- SELECT * FROM 사원 WHERE 관리자번호 IS NULL;
Index Range Scan이 가능한 SQL
- SELECT * FROM 사원 WHERE 집전화번호 IS NULL;
- SELECT * FROM 사원 WHERE 집전화번호 IS NULL AND 부서번호 = 'Z123';
- SELECT * FROM 사원 WHERE 관리자번호 IS NULL AND 부서번호 = 'Z123';
🍋 기출 포인트
- 오라클은 구성 컬럼이 모두 NULL인 레코드는 인덱스에 저장하지 않는다. 따라서 단일 컬럼에 생성한 인덱스에 대한 IS NULL 조건으로는 Index Range Scan이 불가능하다.
🍒 문제 해설
- 구성 컬럼 중 하나라도 NULL이 아닌 레코드는 인덱스에 저장하기 때문에 2개 이상 컬럼으로 구성된 결합 인덱스에 대해서는 IS NULL 조건에 대한 Index Range Scan이 가능할 수 있다.
✍️ 24번 : Index Range Scan이 가능한 SQL

Index Range Scan이 가능한 SQL
- SELECT 계좌번호, 계좌명, 고객번호 FROM 계좌 WHERE 개설일시 IS NULL;
Index Range Scan이 불가능한 SQL
- SELECT 계좌번호, 계좌명, 고객번호 FROM 계좌 WHERE 계좌번호 LIKE :acnt_no|| '';
- SELECT 계좌번호, 계좌명, 고객번호 FROM 계좌 WHERE 지점코드 = 100;
- SELECT 계좌번호, 계좌명, 고객번호 FROM 계좌 WHERE 지점코드 IS NULL;
- SELECT 계좌번호, 계좌명, 고객번호 FROM 계좌 WHERE 고객번호 = 123456;
🍋 기출 포인트
- 개설일시를 선두로 갖는 계좌_X02 인덱스를 사용할 수 있다. 인덱스 구성 컬럼 중 고객
번호가 Null 값을 허용하지 않으므로 모든 테이블 레코드가 인덱스에도 존재한다.따라서 ‘개설일시 IS NULL'인 계좌를 인덱스를 사용해 검색해도 결과집합에 누락이 발생하지 않는다. - 지점코드가 VARCHAR2 컬럼인데 숫자형 값으로 검색하였다. 따라서 자동 형변환이 발생해 지점코드를 선두로 갖는 인덱스가 있어도 정상적인 Index Range Scan은 불가능하다.
🍒 문제 해설
- 숫자형과 문자형을 비교할 때는 숫자형 기준으로 문자형이 자동 변환되지만, 연산자가
LIKE일 때는 다르다. LIKE 자체가 문자열 비교 연산자이므로 이때는 아래와 같이 문자형
기준으로 숫자형 컬럼이 변환된다. - 숫자형과 문자형을 비교할 때는 숫자형 기준으로 문자형이 자동 변환된다.
- 두 컬럼 값이 모두 Null인 데이터는 인덱스에 저장되지않으므로 '지점코드 IS NULL'인 계좌를 검색하기 위해 인덱스를 사용하면 결과집합에 누락이 발생한다.
- 인덱스를 Range Scan 을 하려면 고객번호를 선두로 갖는 인덱스가 있어야 하는데, 현
재 그런 인덱스는 생성돼 있지 않다. 계좌_X02 인덱스를 Full Scan 해서 '고객번호 =
123456'인 계좌를 찾을 수는 있다.
②
✍️ 25번 : Index Range Scan이 가능한 SQL
인덱스 : 기준연도 + 과세구분코드 + 보고회차 + 실명확인번호Index Range Scan이 가능한 SQL
select * from TXA1234 where 기준연도 = :stdr_year and substr(과세구분코드, 1, 4) = :txtn_dcd and 실명확인번호 = :rnm_cnfm_no
Index Range Scan이 불가능한 SQL
select * from TXA1234 where 과세구분코드 = :txtn_dcd and 보고회차 = :rpt_tmrd and 실명확인번호 = rnm_cnfm_noselect * from TXA1234 where (:stdr_year is null or 기준연도 = stdr_year) and 과세구분코드 = txtn_dcd and 보고회차 = rpt_tmrdselect /*+ no_expand */* from TXA1234 where 기준연도 not between stdr_year1 and :stdr_year2 and 과세구분코드 = txtn_dcd 보고회차 = :rpt_tmrd
🍋 기출 포인트
- 조건절에서 인덱스 두 번째 컬럼인 과세구분코드를 가공했고 세 번째 컬럼은 누락했지만, 최선두 컬럼인 기준연도는 가공하지 않은 상태로 조건절에 기술했으므로 인덱스 Range Scan은 가능하다.
- 인덱스 선두 컬럼이 조건절에 있으나 OR 방식의 옵션조건으로 처리하였으므로 인덱스를
Range Scan 할 수 없다. - 부정형은 기본적으로 Index Range Scan 불가 조건이다.
🍒 문제 해설
- 하지만, NOT BETWEEN 조건인 경우, CONCATENATION(옵티마이저에 의한 UNION ALL 분기)이 일어나면 Index Range Scan이 가능하다.그런데 ④번 SQL에는 CONCATENATION을 방지하도록 NO_EXPAND 힌트를 사용하였으므로 Index Range Scan이 불가능하다. 참고로, CONCATENATION을 유도하려면 USE_CONCAT 힌트를 사용하면 된다.
✍️ 26번 : 힌트를 사용하지 않고도 Index Range Scan이 가능한 SQL
고객 PK : 고객번호
고객_X1 : 고객명 + 가입일자
고객_X2 : 휴대폰번호힌트를 사용하지 않고도 Index Range Scan이 가능한 SQL
select * from 고객 where (:opt = 'A' and 고객번호 = cust_no) or (:opt = 'B' and 휴대폰번호 = mobile_no)
힌트를 사용하지 않으면 Index Range Scan이 불가능한 SQL
select * from 고객 where 고객명 = cust_nm or 생년월일 = birthdayselect * from 고객 where 고객명 = cust_nm or 가입일자 = enter_noselect * from 고객 where cust_no is null or 고객번호 = cust_no
🍋 기출 포인트
- OR 조건은 기본적으로 Index Range Scan을 위한 액세스 조건으로 사용할 수 없다. OR 조건으로는 수직적 탐색을 통해 스캔 시작점을 찾을 수 없기 때문이다.
- 다만,CONCATENATION(옵티마이저에 의한 UNION ALL 분기)으로 처리했을 때 각각 수직 탐색을 위한 액세스 조건으로 사용할 인덱스가 있다면, Index Range Scan이 가능하다.
- UNION ALL 분기했을 때 한쪽 브랜치는 고객번호 조건으로, 다른 한쪽 브랜치는 휴대폰번호로 Index Range Scan 할 수 있다. opt 변수에 입력한 값에 따라 둘 중 한쪽 브랜치만 실행된다.
🍒 문제 해설
- UNION ALL 분기했을 때 고객명 조건으로는 Index Range Scan이 가능하지만, 생년월일 조건에 대해서는 테이블을 Full Scan을 피할 수 없다.생년월일을 포함한 인덱스가 없기
때문이다. 어차피 테이블을 Full Scan 해야 하므로 옵티마이저는 UNION ALL로 분기하지
않는다. - UNION ALL 분기했을 때 고객명 조건으로는 Index Range Scan이 가능하지만, 가입일자 조
건으로는 테이블 또는 인덱스를 Full Scan 해야 한다. 가입일자를 선두로 갖는 인덱스가
없기 때문이다. 어차피 Full Scan 해야 하므로 옵티마이저는 UNION ALL로 분기하지 않
는다. (※ USE_CONCAT 힌트로 UNION ALL 분기를 강제하면 고객명 조건절은 Index Range
Scan 한다.)

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’