✍️ 16번 : 소트 머지 조인 오라클 힌트
주문 테이블을 기준으로 고객 테이블과 소트 머지 조인하도록 유도하고자 할 때 빈칸에 들어갈 오라클 힌트
select /*+ ? */
o.주문번호, o.고객번호, c.고객명, c. 전화번호, o․주문금액
from 주문 o, 고객 c
where 0.주문일자 >= trunc(sysdate)
and c. 고객번호 = 0.고객번호 ; - ordered use_merge (c) 👉 ⭕️
🍋 기출 포인트
- 소트 머지 조인으로 유도할 때 use_merge 힌트를 사용한다.
✍️ 17번 : 소트 머지 조인 SQL Server 힌트
주문 테이블을 기준으로 고객 테이블과 소트 머지 조인하도록 유도하고자 할 때 빈칸에 들어갈 SQL Server 힌트를 기술하시오.
select o.주문번호, o.고객번호, c.고객명, c.전화번호, o.주문금액
from 주문 0, 고객 c
where 0.주문일자 >= trunc (sysdate)
and c. 고객번호 = 0. 고객번호
option ( ? )- force order , merge join 👉 ⭕️
🍋 기출 포인트
- FROM 절에 테이블을 나열한 순으로 조인하고자 할 때 force order 힌트를 사용한다.
- 소트 머지 조인으로 유도할 때 merge join 힌트를 사용한다.
✍️ 18번 : 소트 머지 조인 오라클 힌트
아래 실행계획이 나타나도록 옵티마이저 힌트를 기술하시오
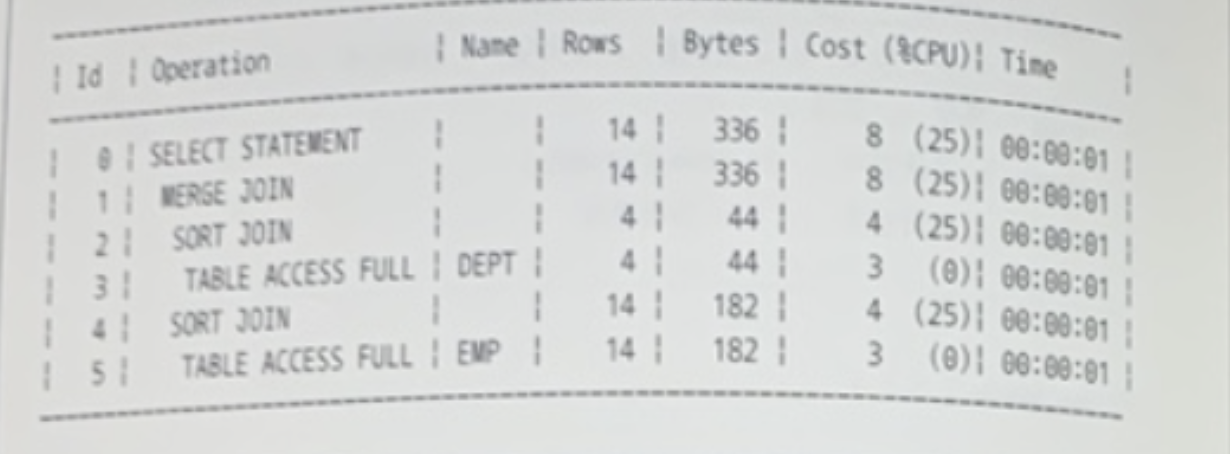
1. /+ leading(d) use_merge(e) / 👉 ⭕️
✍️ 19번 : 소트 머지 조인의 특징
소트 머지 조인의 특징
- ① 랜덤 액세스가 아닌 스캔 위주의 조인 방식이다. 👉 ⭕️
- ④ 두 테이블을 각각 읽어 조인 대상 집합을 줄일 수 있을 때 매우 효과적이다. 👉 ⭕️
- ① 양쪽 테이블 모두 조인 컬럼에 인덱스가 있으면 따로 정렬을 수행하지 않아도 되므로 매우 유리하다. 👉 ❌ (⭐️ 두번째 테이블은 무조건 따로 정렬을 수행해야함 !)
- ② 양쪽 집합을 개별적으로 읽어서 정렬하므로 조인 컬럼에 인덱스가 없어도 상관 없다. 👉 ⭕️
🍋 기출 포인트
- 소트 머지 조인이 빠른 이유는 첫 번째 집합을 기준으로 두 번째 집합을 반복 액세스할때는 버퍼캐시를 탐색하지 않고 PGA에서 데이터를 읽기 때문이다.
- ⭐️ 따라서 두 번째 집합은 반드시 정렬해서 PGA에 저장한 후에 조인을 시작한다.
- 첫 번째 집합도 일반적으로 PGA에 저장하지만, 조인 컬럼에 인덱스가 있어서 그것을 사용한다면 PGA 저장하지 않고 조인을 시작한다.
🍒 문제 해설
- 소트 머지 조인은 조인을 위해 실시간으로 인덱스를 생성하는 것과 다름없다.
- 정렬한 다음에는 NL 조인과 같은 방식으로 진행하지만, PGA 영역에 저장한 데이터를 이용하기 때문에 빠르다.
- 소트 부하만 감수한다면, 건건이 버퍼캐시를 경유하는 NL 조인보다 빠르다.
- NL 조인은 조인 컬럼에 대한 인덱스 유무에 크게 영향을 받지만, 소트 머지 조인은 영향을받지 않는다.
- 소트 머지 조인은 양쪽 집합을 개별적으로 읽고 나서 조인을 시작한다.조인 컬럼에 인덱스가 없는 상황에서 두 테이블을 각각 읽어 조인 대상 집합을 줄일 수 있을 때 아주 유리하다.
- 양쪽 소스 집합으로부터 조인 대상 레코드를 찾을 때 인덱스를 이용한다면 랜덤 액세스가 일어난다.
✍️ 20번 : 대량 데이터를 조인할 때 소트 머지 조인이 NL 조인보다 유리한 이유
대량 데이터를 조인할 때 소트 머지 조인이 NL 조인보다 유리한 이유
- 데이터를 PGA 영역에 읽어 들인 후 조인하기 때문이다. 👉 ⭕️
- Temp 테이블스페이스를 활용하기 때문이다. 👉 ❌
- NL 조인보다 더 빠른 조인 알고리즘을 사용하기 때문이다. 👉 ❌
- 조인 대상 집합을 버퍼 캐시에서 읽을 때 래치 획득을 생략하기 때문이다. 👉 ❌
🍒 문제 해설
- 소트 머지 조인은 Sort Area에 미리 정렬해 둔 자료구조를 이용한다는 점만 다를 뿐 조인'프로세싱 자체는 NL 조인과 같다.
- 대량 데이터 조인할 때 NL 조인보다 소트 머지 조인이 빠르다.
- 소트 머지 조인은 양쪽 테이블로부터 조인 대상 집합(조인 조건 이외 필터 조건을 만
족하는 집합)을 ‘일괄적으로' 읽어 PGA(또는 Temp 테이블스페이스)에 저장한 후 조인한다. - PGA는 프로세스만을 위한 독립적인 메모리 공간이므로 데이터를 읽을 때 래치 획득 과정이 없다.
✍️ 21번 : 소트 머지 조인의 장점
해시 조인과 비교할 때 소트 머지 조인의 장점
- 조인 조건이 '='이 아닐 때도 사용할 수 있다. 👉 ⭕️
- 양쪽 집합이 모두 대용량일 때 해시 조인보다 빠르다. 👉 ❌
- Temp 테이블스페이스를 적게 사용한다. 👉 ❌
- 메모리를 적게 사용한다. 👉 ❌
🍒 문제 해설
- 해시 조인과 비교한 소트 머지 조인의 가장 큰 장점은 조인 조건이 '='이 아닐 때, 심지어 조인 조건이 아예 없을 때도 사용할 수 있다는 점이다. 👉 장점
- 해시 조인은 둘 중 작은 쪽 집합만 읽어서 PGA에 해시 맵을 저장하는 반면, 소트 머지 조인은 양쪽 집합을 정렬해서 PGA에 저장하므로 더 많은 메모리를 사용한다. 👉 단점
- 상황에 따라 다르겠지만, Temp 테이블스페이스 사용량도 일반적으로 소트 머지 조인이 더 많다. 둘 중 하나만 대용량일 때 해시 조인은 Temp 테이블스페이스를 전혀 사용하지
않는 반면, 소트 머지 조인은 Temp 테이블스페이스를 사용한다. 양쪽 집합이 모두 다용
량일 때는 소트 머지 조인과 해시 조인 둘 다 양쪽 집합을 Temp 테이블스페이스에 저장
한다. 👉 단점 - 둘 중 어느 한쪽이 매우 작은 테이블일 때 해시 조인이 가장 극적인 성능 효과를 내는 것은 사실이지만, 둘 다 큰 테이블일 때도 일반적으로 해시 조인이 더 빠르다. 👉 단점
✍️ 22번 :해시조인 과정
(가) 작은 테이블을 읽는다.
(나) 큰 테이블을 읽는다.
(다) 해시 맵을 만든다.
(라) 해시 맵을 탐색한다.
(마) 조인에 성공한 데이터를 전송한다.- (가) -> (다) -> (나) -> (라) -> (마) 👉 ⭕️
🍋 기출 포인트
- 해시 조인은 크게 두 단계로 진행한다.
• 해시 맵 생성 (Build Phase) : 작은 테이블을 읽어서 해시 맵을 생성한다.
• 해시 앱 탐색(Probe Phase) : 큰 테이블을 스캔하면서 해시 맵을 탐색한다.
조인에 성공한 데이터는 클라이언트에 전송한다.
✍️ 23번 : 오라클 힌트
아래 실행계획이 나타나도록 유도하고자 할 때 빈칸에 들어갈 오라클 힌트로 가장 부적절한 것
select /*+ ? */d.deptno, d.dname, e.empno, e.ename
from emp e, dept d
where d. deptno = e.deptno ; 이지만, 따라서 두 테이블을 조인할 때는 굳이 swap_
join_inputs 힌트를 쓰지 않고도 실행계획을 쉽게 제어할 수 있다.
①번은
②번은
④번과 ④번은 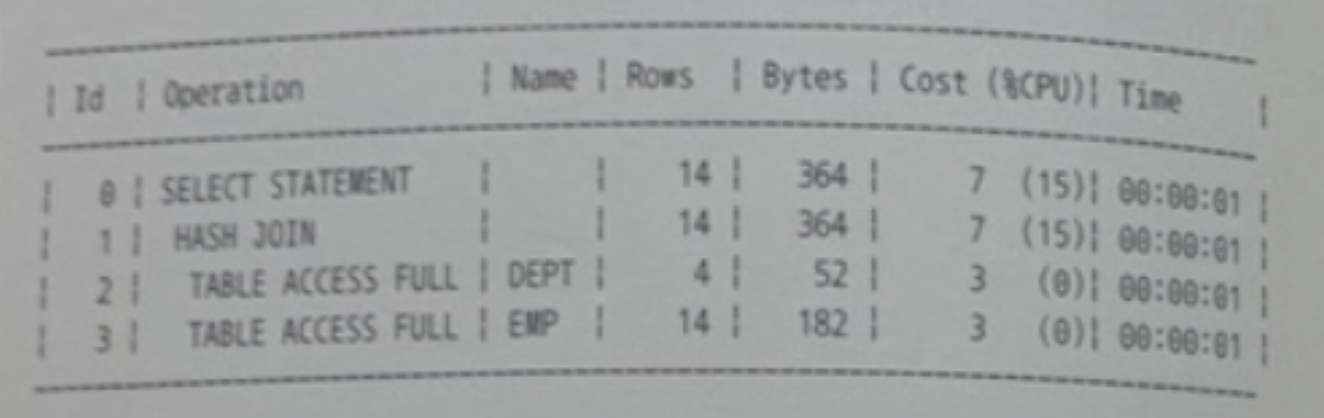
1. leading(d) use_hash(e) 👉 ⭕️
1. ordered use_hash(e) 👉 ❌
1. ordered use_hash(d) swap_join_inputs(d) 👉 ⭕️
1. use_hash(e d) swap_join_inputs(d) 👉 ⭕️
🍋 기출 포인트
- leading(d) 힌트를 쓰면 DEPT 테이블이 Build Input으로 선택된다.
- ordered 힌트를 쓰면 EMP 테이블이 Build Input으로 선택된다.
- 3번과 4번은 swap_join_inputs 힌트에 의해 DEPT 테이블이 Build Input으로 선택된다.
- Build Input을 명시적으로 선택하는 힌트가 swap_join_inputs 이지만, leading 또는 ordered 힌트에 의해 선택된 첫번째 테이블은 무조건 Build Input이 된다. 따라서 두 테이블을 조인할 때는 굳이 swap_join_inputs 힌트를 쓰지 않고도 실행계획을 쉽게 제어할 수 있다.
🍒 문제 해설
- HASH JOIN 오퍼레이션 바로 아래쪽 테이블이 Build Input이다.
- 해시조인시 leading 또는 ordered 힌트에 의해 선택된 첫번째 테이블은 무조건 Build Input이 된다.
- Build Input을 명시적으로 선택하는 힌트는 swap_join_inputs이다.
✍️ 24번 : SQL Server 힌트
SQL Server에서 주문 테이블을 기준으로 고객 테이블과 해시 조인하도록 유도하고자 할 때 빈칸에 들어갈 용어를 적으시오.
select o.주문번호, o.고객번호, c.고객명, c. 전화번호, o, 주문금액
from 주문 o
inner ? 고객 c on ( o.고객번호 = c.고객번호 )
where 0.주문일자 >= trunc(sysdate)
option (force order)- hash join 👉 ⭕️
✍️ 25번 : 해시 조인에 대한 설명
해시 조인에 대한 설명으로 가장 부적절한 것을 고르시오.
- 조인 컬럼에 인덱스가 없어도 성능에 미치는 영향은 없다. 👉 ⭕️
- 조인 조건 중 하나 이상이 '=' 조건일 때만 사용할 수 있다. 👉 ⭕️
- 조인하는 양쪽 집합 중 어느 한쪽이 다른 한쪽에 비해 현저히 작을 때 효과적인 조인 방식이
다. 👉 ⭕️ - 조인하는 양쪽 집합이 모두 대량 데이터일 때는 NL 조인이 유리하다. 단, 인덱스를 최적으로 구성해야 한다. 👉 ❌
🍋 기출 포인트
- 양쪽 모두 PGA 공간을 초과하더라도 대량 데이터를 조인할 때는 NL 조인보다 해시 조인이 빠르다.
🍒 문제 해설
- 해시 조인도 조인 프로세싱 자체는 NL 조인과 같지만, 건건이 Inner 집합을 버퍼캐시에서 탐색하지 않고 PGA에 미리 생성해 둔 해시 테이블(해시 맵)을 탐색하면서 조인한다는 점이 다르다. 해시 맵을 이용하므로 조인 컬럼에 인덱스가 없어도 상관 없다.
- 해시 맵을 PGA에 생성해야 하므로 둘 중 어느 한쪽이 PGA에 담을 수 있을 정도로 충분히 작을 때 가장 효과적이다.
- 해시 조인은 해시 알고리즘 특성 상 조인 조건 중 하나 이상이 '=' 조건일 때만 사용할 수 있다.
✍️ 26번 : 해시 조인과 소트 머지 조인 비교
조인하는 양쪽 집합 중 어느 한쪽이 다른 한쪽에 비해 현저히 작을 때 해시 조인이 소트 머지 조인보다 빠른 가장 핵심적인 이유
- 소트를 수행하지 않기 때문이다. 👉 ❌
- 조인 단계에 버퍼 캐시를 전혀 액세스하지 않기 때문이다. 👉 ❌
- 소트 알고리즘보다 해시 알고리즘이 더 빠르기 때문이다. 👉 ❌
- Temp 테이블스페이스를 전혀 활용하지 않을 가능성이 높기 때문이다. 👉 ⭕️
🍋 기출 포인트
- 해시 조인에서 사전 준비작업은 양쪽 집합 중 어느 한쪽을 읽어 해시 맵을 만드는 작업이
다. 둘 중 작은 집합조차도 Hash Area에 담을 수 없을 정도로 큰 경우가 아니면, 해시 조인
은 Temp 테이블스페이스, 즉 디스크에 쓰는 작업이 전혀 일어나지 않는다. - 소트 머지 조인에서 사전 준비작업은 '양쪽 집합을 모두 정렬해서 PGA에 담는 작업이다.PGA는 그리 큰 메모리 공간이 아니므로 두 집합 중 어느 하나가 중대형 이상이면, Temp 테이블스페이스, 즉 디스크에 쓰는 작업을 반드시 수반한다.
🍒 문제 해설
- Hash Area에 생성한 해시 테이블 (해시 맵)을 이용한다는 점만 다를 뿐 해시 조인도 조인 프로세싱 자체는 NL 조인과 같다.
- 해시 조인이 인덱스 기반의 NL 조인보다 빠른 결정적인 이유는, 소트 머지 조인이 빠른 이유와 같다.즉, 해시 테이블을 PGA 영역에 할당하기 때문이다.
- 해시 조인도 Build Input과 Probe Input 각 테이블을 읽을 때는 DB 버퍼캐시를 경유한다.이때 인덱스를 이용하기도 한다.
이 과정에서 생기는 버퍼캐시 탐색 비용과 랜덤 액세스 부하는 해시 조인이라도 피할 수 없다. - 해시 조인과 소트 머지 조인 두 조인 메소드의 성능 차이는 조인 오퍼레이션을 시작하기 전, 사전 준비작업에 기인한다.
✍️ 27번 : SQL 튜닝 방안
아래 SQL에 대한 튜닝 방안으로 가장 부적절한 것을 고르시오.
[데이터]
대리점 : 1,000개
상품판매실적 : 월평균 100만 건
[인덱스 구성]
대리점_PK : 대리점코드
상품판매실적_PK : 대리점코드 + 상품코드 + 판매일자
상품판매실적 X1 : 판매일자 + 상품코드
SELECT A, 대리점명, SUM(B.매출금액) 매출금액
FROM 대리점 A, 상품판매실적 B
WHERE A.대리점코드 = B.대리점코드
AND B. 상품코드 IN ('A1847', 'Z8413' )
AND B. 판매일자 BETWEEN '20210101' AND '20210331'
GROUP BY B.대리점코드, A. 대리점명
ORDER BY 1, 2 ;
- 상품판매실적_X1 인덱스를 상품코드 + 판매일자」 순으로 변경한다. 👉 ⭕️
- 조인 순서를 변경한다. 👉 ❌
- 판매일자 조건을 만족하는 상품판매실적을 대리점코드로 GROUP BY 한 후 대리점 테이블과 조인하도록 SQL을 변환한다. 👉 ⭕️
- 해시 조인으로 유도한다. 👉 ⭕️
🍋 기출 포인트
- SQL을 아래와 같이 변환하면, 조인 액세스를 대리점코드별로 한 번씩만 할 수 있어 성능 개선이 된다. 단, 인라인 뷰가 Merging 되면 쿼리가 원래 형태로 돌아가므로 반드시 실행계획을 확인하고, 필요하다면 NO_MERGE 힌트로 뷰 Merging을 방지해 줘야 한다.
SELECT A.대리점명, B. 판매금액 FROM 대리점 A (SELECT /*+ NO_MERGE */ 대리점코드, SUM(판매금액) 판매금액 FROM 상품판매실적 WHERE 상품코드 IN ('A1847', '20413') AND 판매일자 BETWEEN '20210101' AND '20210331' GROUP BY 대리점코드) B WHERE A.대리점코드 = B.대리점코드 ; - 해시 조인으로 유도하면 1,000 로우를 가진 대리점 테이블로 PGA에 해시맵을 만들어서
조인하게 되므로 SGA 버퍼 캐시를 반복해서 탐색하는 비효율을 제거할 수 있다. - 2021년 1~3월에 'A1847' 또는 '20413' 상품을 판매한 대리점은 30개뿐이다.
- 3개월 판매실적을 위해 300만 건 정도를 스캔했을 텐데 상품코드 IN 조건을 필터링한 결과는 9만 건이므로 스캔 비효율이 적지 않다.
🍒 문제 해설
- 상품판매실적_X1 인덱스가 판매일자 + 상품코드」 순으로 구성돼 있고, 선두 컬럼인
판매일자가 BETWEEN 조건이므로 상품코드는 필터 조건으로 사용된다. 3개월 판매실적을
위해 300만 건 정도를 스캔했을 텐데 상품코드 IN 조건을 필터링한 결과는 9만 건이므로
스캔 비효율이 적지 않다. 인덱스를 상품코드 + 판매일자, 순으로 변경한다면 성능
개선에 도움이 된다. - 대리점 테이블을 먼저 읽은 후 상품판매실적과 NL 조인한다면, 1,000번의 조인 액세스가 발생한다. 2021년 1~3월에 'A1847' 또는 '20413' 상품을 판매한 대리점은 30개뿐인데, 판매가 없는 나머지 978개 대리점의 판매실적까지 읽고 버리는 비효율이 크다. 게다가,
상품판매실적_PK 인덱스의 두 번째 컬럼인 상품코드가 IN 조건이므로 대리점별로 인덱스
를 두 번씩 탐색하는 부담도 있다.(조인을 위해 상품판매실적_X1 인덱스를 사용한다면
상품코드가 필터 조건이므로 인덱스를 두 번 탐색하진 않겠지만, 스캔 비효율이 매우 크
므로 결과는 훨씬 더 안 좋을 것이다.) - 현재 실행계획은 상품판매실적을 먼저 읽은 후 30개의 대리점코드에 대해 대리점 테이블을 각각 3,000번씩 반복해서 조인 액세스하고 있다.
✍️ 28번 : SQL 튜닝 방안
아래 SQL에 대한 튜닝 방안으로 가장 적절한 것을 고르시오.
[데이터]
상품 : 50만 rows
상품상세 : 500만 rows
상품변경이력 : 1,000만 rows
[인덱스 구성]
상품_PK : 상품코드
상품상세_PK : 상품코드 + 상품상세코드
상품상세_X1 : 등록일시 + 상품코드
상품변경이력_PK : 상품코드 + 변경일시
create table 상품상세_temp
nologging
as
select /*+ ordered use_hash(b) use_hash(c) swap_join_inputs(c) */ *
from 상품상세 a, 상품변경이력 b, 상품 c
where b.상품코드 = a.상품코드
and b. 변경일시 like substr(a. 등록일시, 1, 8) || '%'
and c.상품코드 = a. 상품코드 ;- ordered use_hash(b) 힌트를 leading(b) use_hash(a)로 수정한다. 👉 ❌
- use_hash(b) 힌트를 use_nl(b)로 수정한다. 👉 ❌
- 두 번째 조건절을 아래와 같이 수정한다. 👉 ⭕️
and substr(b. 변경일시, 1, 8) = substr(a, 등록일시, 1, 8) - 힌트 전체를 leading(c a b) use_hash(a) use_hash(b) swap_join_inputs(a)로 수정한다. 👉 ❌
🍋 기출 포인트
- 상품코드 하나당 평균 10개의 상품상세와 평균 20개의 상품변경이력이 있으므로 어느 쪽을 해시 맵으로 선택하더라도 해시 체인 하나에 여러 레코드가 달릴 수밖에 없는 구조다.
- 상품상세의 등록일시를 해시 맵을 구성하는 각 해시 체인으로 값을 분배하는 기준 키 값으로 사용할 수 있으면 같은 상품이더라도 여러 체인으로 흩어진다. 그런데 조인 조건이 LIKE 이므로 해시 맵 기준 키로 사용할 수 없다.
- 조인 조건을 아래와 같이 '=' 조건으로 바꿔주면, a. 상품코드와 substra. 등록일시, 1, 8) 두 개의 값으로 해시 맵을 구성할 수 있게 된다.
🍒 문제 해설
- 해시 알고리즘 특성상 한 체인에 여러 개 값이 연결될 수 있는 구조이며, 각 해시 체인에 연결된 값이 많을수록 해시 맵 탐색 효율은 나빠진다.
✅ 왜 해시 조인은 조인 조건이 '='일 때만 사용할 수 있을까?
이는 비단 해시 조인만의 특징은 아니다.
해시 클러스터도 '=' 검색일 때만 사용할 수 있고, 해시 파티션도 '=' 검색일 때만
Partition Pruning이 작동한다.[예시] 28개의 방을 가진 회사 연수원
연수원에 입소한 신입사원들을 주민등록번호 앞 6자리를 20으로 나눈 나머지 값으로 방을 배정했다.
이 상태에서 1998년 5월 29일에 출생한 사원이 어느 방에 있는지는 쉽게 찾을 수 있다.
모듈러 함수가 9번 방이라고 알려주기 때문이다.
=> mod(19988529, 28) = 9
반면, 1990년대에 출생한 사원(「주민등록번호 BETWEEN '19900101' AND '19991231′」 또는 「주민등록번호 LIKE '1996%)을 쉽게 찾는 방법은 없다.
모든 방을 다 둘러보는 수밖에 없다.
방금 든 예에서 20개의 방이 해시 체인에 해당하고, 방 배정에 사용한 모듈러 함수가
해시 함수에 해당한다.
해시 함수를 이용해 체인을 할당하고 값을 찾는 특성으로 인해 해시 조인은 조인 조건이
'='일 때만 사용할 수 있다.
더 정확히 표현하면, 조인 조건 중 하나 이상이 '=' 이어야 해시 조인할 수 있다.
✍️ 29번 : 해시 조인
해시 조인에 대한 설명으로 가장 부적절한 것을 고르시오
- 작은 집합을 해서 맵 Build Input으로 선택하는 것이 좋다. 👉 ⭕️
- 중복 값이 거의 없는 집합을 해서 맵 Build Input으로 선택하는 것이 좋다. 👉 ⭕️
- 수행 빈도가 매우 높은 쿼리는 해시 조인으로 유도하는 것이 좋다. 👉 ❌
- 모든 조인 조건이 '=' 이면 가장 좋고, 적어도 하나는 '=' 이어야 해시 조인할 수 있다. 👉 ⭕️
🍋 기출 포인트
- 해시 조인은 수행 빈도가 낮고 쿼리 수행 시간이 오래 걸리는 대량 데이터 조인할 때 사용하는 것이 좋다.
- 해시 맵 Build Input은 중복 값이 거의 없는 작은 집합일 때 가장 좋다.
- 모든 조인 조건이 '=' 조건이면 가장 좋고, 적어도 하나는 '=' 조건이어야 해시 조인이 가능하다.
✍️ 30번 : 해시 조인 사용기준
해시 조인의 사용기준으로 가장 부적절한 것을 고르시오
- 조인 컬럼에 적당한 인덱스가 없어 NL 조인이 비효율적일 때 사용한다. 👉 ⭕️
- 대량 데이터를 조인할 때 주로 사용한다. 👉 ⭕️
- 수행 빈도가 매우 높아 시스템 전체 성능에 미치는 영향도가 큰 쿼리에 사용한다. 👉 ❌
- DW/OLAP성 쿼리, BATCH 프로그램에 주로 사용한다. 👉 ⭕️
🍋 기출 포인트
- 수행시간이 짧으면서 수행빈도가 매우 높은 쿼리(→ OLTP성 쿼리의 특징이기도 함)를 해시 조인으로 처리하면 CPU와 메모리 사용률이 크게 증가한다.
- 결론적으로 해시 조인은 아래 세 가지 조건을 만족하는 SQL문에 주로 사용한다.
① 수행 빈도가 낮고
② 쿼리 수행 시간이 오래 걸리는
③ 대량 데이터 조인할 때 - 위 세 가지 조건은 배치 프로그램, DON, OLAP 쿼리의 특징이기도 하다.
🍒 문제 해설
- NL 조인에 사용하는 인덱스는 (DBA가 Drop하지 않는 한) 영구적으로 유지하면서 다양한 쿼리를 위해 공유 및 재사용하는 자료구조다.
- 해시 테이블은 단 하나의 쿼리를 위해 생성하고 조인이 끝나면 곧바로 소멸하는 자료구조다.
- 같은 쿼리를 100개 프로세스가 동시에 수행하면, 해시 테이블도 100개가 만들어진다.
- 해시 맵을 만드는 과정에 여러 가지 래치 경합도 발생한다.
- OLTP 환경에서도 해시 조인을 쓸 수 있지만, 이 세 가지 기준을 만족하는지 점검해 봐야 한다.
✍️ 31번 : 조인 순서에 가장 영향을 적게 받는 조인
조인 순서에 가장 영향을 적게 받는 조인 메소드를 고르시오.
- 소트 머지 조인 👉 ⭕️
- 해시 조인 👉 ❌
- NL 조인 👉 ❌
- 해시 아우터 조인 👉 ❌
🍋 기출 포인트
- 소트 머지 조인도 조인 순서에 따른 성능 차이가 나타나긴 하지만, NL 조인이나 해시 조인에 비하면 성능 차이가 크진 않다.
🍒 문제 해설
- NL 조인은 드라이빙 집합에 의해 전체 일량이 결정되므로 순서가 매우 중요하다.
- NL 조인은 일반적으로 작은 집합을 드라이빙하는 것이 유리하지만, 인덱스 구성에 따라서는 큰 집합을 드라이빙 하는 것이 유리할 수도 있다.
- 해시 조인은 Hash Area Build Input을 모두 채울 수 있느냐가 관건이므로 작은 쪽 테이블을 드라이빙하는 것이 유리하다.
✍️ 32번 : 해시조인 유도 옵티마이저 힌트
아래와 같은 실행계획이 생성되도록 옵티마이저 힌트를 기술하시오.
select a.주문번호, a․ 주문금액, b. 상품코드, c. 상품명, b. 주문수량, b. 할인률
from 주문 a, 주문상품 b, 상품 c
where b.주문번호 = a.주문번호
and c.상품코드 = b.상품코드 ; 
- leading(a b c) use_hash(b) use_hash(c) swap_join_inputs(c) 👉 ⭕️
🍋 기출 포인트
- ⭐️ 주문과 주문상품을 조인한 후에 상품과 조인하는 실행계획이다.따라서 leading 힌트의 인자는 a, b, c 순으로 나열한다.
- 상품(c)과 주문(a)이 Build Input이므로 각각 swap_join_inputs 힌트로 지정해 주면 된다.
- 주문은 leading 힌트의 첫 번째 인자로 지정했으므로 swap_join_inputs를 생략할 수 있다.
- leading 또는 ordered 힌트에 의해 선택된 첫 번째 테이블은 무조건 Build
Input으로 선택된다.
🍒 문제 해설
- ordered(a b c)는 없다.
✍️ 33번 : 해시조인 유도 옵티마이저 힌트
아래와 같은 실행계획이 생성되도록 옵티마이저 힌트를 기술하시오.
select a. 주문번호, a. 주문금액, b. 상품코드, c. 상품명, b. 주문수량, b.할인률
from 주문 a, 주문상품 b, 상품 c
where b. 주문번호 = a. 주문번호
and c. 상품코드 = b. 상품코드 ;
- leading(a b c) use_hash(b) use_hash(c) no_swap_join_inputs(c) 👉 ⭕️
🍋 기출 포인트
- 주문과 주문상품을 조인한 집합으로 상품과 조인할 때는 상품이 Probe Input이다. Probe Input을 명시적으로 선택할 때 no_swap_join_inputs 힌트를 사용한다.
✍️ 34번 : 해시조인 유도 옵티마이저 힌트
아래와 같은 실행계획이 생성되도록 옵티마이저 힌트를 기술하시오.
select a. 주문번호, a. 주문금액, b. 상품코드, c. 상품명, b. 주문수량, b. 할인
from 주문 a, 주문상품 b. 상품 c
where b.주문번호 = a.주문번호
and c.상품코드 = b.상품코드
1. leading(c, b, a) use_hash(b) use_hash(a) swap_join_inputs(a) 👉 ⭕️
🍋 기출 포인트
- 상품과 주문상품을 조인한 후에 주문과 조인하는 실행계획이다. 따라서 leading 힌트의 인자는 c, b, a 순으로 나열한다.
- 상품(c)과 주문(a)이 Build Input이므로 각각을 swap_join_inputs 힌트로 지정해 주면 된다.
- 상품은 leading 힌트의 첫 번째 인자로 지정했으므로 swap_join_inputs를 생략할 수 있다.
✍️ 35번 : 해시조인 유도 옵티마이저 힌트
아래와 같은 실행계획이 생성되도록 옵티마이저 힌트를 기술하시오.
select a. 주문번호, a.주문금액, b. 상품코드, c. 상품명, b.주문수량, b.할인률
from 주문 a, 주문상품 b, 상품 c
where b.주문번호 = a․주문번호
and c.상품코드 = b.상품코드 ;
- leading(c b a) use_hash(b) use_hash(a) no_swap_join_inputs(a) 👉 ⭕️
✍️ 36번 : 해시조인 유도 옵티마이저 힌트
아래와 같은 실행계획이 생성되도록 옵티마이저 힌트를 기술하시오.
[인덱스 구성]
계약_PK : 계약번호
계약_X1 : 계약일자
가입상품_PK : 계약번호 + 상품번호
가입상품_X1 : 가입일자
가입부가상품_PK : 계약번호 + 상품코드 + 부가상품코드
상품_PK : 상품코드
select a.계약번호, a․계약명, b. 상품코드, b. 가입일자, b. 할인률 ,
c.부가상품코드, d. 상품명
from 계약 a, 가입상품 b, 가입부가상품 c, 상품 d
where a. 계약일자 = :cntr_dt
and b. 계약번호 = a․ 계약번호
and b. 가입일자 = :cent_dt
and c. 계약번호 = b.계약번호
and c. 상품코드 = b. 상품코드
and c. 부가상품코드 like 'A%'
and d. 상품코드 = c.부가상품코드 ;
- leading(b a c d) use_hash(a) use_nl(c) use_hash(d) swap_join_inputs(d) index(b 가입상품_X1) index(a 계약_x1)
index(c 가입부가상품_PK) index(d 상품_PK) 👉 ⭕️
✍️ 37번 : 해시조인 유도 옵티마이저 힌트
아래와 같은 실행계획이 생성되도록 옵티마이저 힌트를 기술하시오.
[ 인덱스 구성 1 ]
계약_PK : 계약번호
계약_X1 : 계약일자
가입상품_PK : 계약번호 + 상품번호
가입상품_x1 : 가입일자
가입부가상품_PK : 계약번호 + 상품코드 + 부가상품코드
상품_PK : 상품코드
select a. 계약번호, a, 계약명, b. 상품코드, b.가입일자, b. 할인률
,c.부가상품코드, d. 상품명
from 계약 a, 가입상품 b, 가입부가상품 c. 상품 d
where a.계약일자 = :cntr_dt
and b. 계약번호 = a. 계약번호
and b. 가입일자 = :cent_dt
and c. 계약번호 = b. 계약번호
and c. 상품코드 = b. 상품코드
and c.부가상품코드 like 'A%'
and d. 상품코드 = c.부가상품코드;
- leading(b a c d) use_hash(a) use_nl(c) use_hash(d) no_swap_join_inputs(d) index(a 계약_X1) index(b 가입상품_x1)
index(c 가입부가상품_PK) index(d 상품_PK) 👉 ⭕️
