[1] 인라인 뷰 활용
- 1:M 관계인 테이블끼리의 조인 결과(1*M)를 1쪽 집합 단위로 그룹핑해야 할 때 M쪽 집합을 먼저 1쪽 단위로 그룹핑하고 나서 조인하는 방식
- 인라인 뷰 : M쪽 집합을 먼저 1쪽 단위로 그룹핑한 것
(1) 인라인뷰 적용
인라인뷰 적용 전
select min(t2.상품명) 상품명, sum(t1.판매수량) 판매수량, sum(t1.판매금액) 판매금액
from 일별상품판매 t1, 상품 t2
where t1.판매일자 between '20090101' and '20091231'
and t1.상품코드 = t2.상품코드 group by
t2.상품코드 ;- 일별상품판매 테이블로부터 읽힌 365,000개 레코드마다 상품 테이블과 조인 시도
- 730,002개의 블록 I/O가 발생, 총 소요시간 13.8초
인라인뷰 적용 후
select t2.상품명, t1.판매수량, t1.판매금액
from ( select 상품코드, sum(판매수량) 판매수량, sum(판매금액) 판매금액
from 일별상품판매
where 판매일자 between '20090101' and '20091231'
group by 상품코드) t1, 상품 t2
where t1.상품코드 = t2.상품코드 ;- 상품코드별로 먼저 집계한 결과건수가 1,000건이므로 상품 테이블과 조인도 1,000번만 발생
- 조인 과정에서 발생한 블록 I/O는 2,101개에 불과, 수행시간도 5.5초
[2] 배타적 관계의 조인
- 상호배타적(Exclusive OR) 관계 : 어떤 엔터티가 두 개 이상의 다른 엔터티의 합집합과 관계(Relationship) 갖는 것
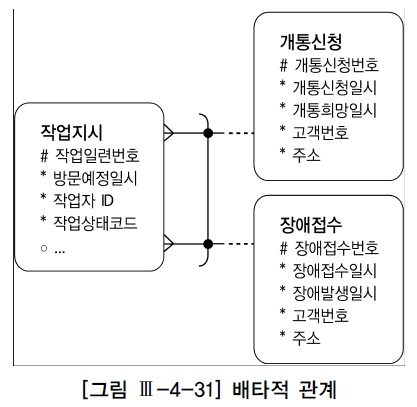
- 고객으로부터 개통이나 장애처리 요청을 받으면 작업기사에게 작업지시서를 발행한다.
- 개통신청과 장애접수는 관리하는 속성이 상당히 달라 별도의 테이블로 설계됨
- 작업지시는 개통신청이든 장애접수든 거의 같은 속성을 관리하므로 한 테이블로 설계함
- 한 테이블로 통합하더라도 개통신청이나 장애접수 중 어느 것과 관계를 갖는지 구분할 수 있어야 한다.
outer 조인
select /*+ ordered use_nl(b) use_nl(c) */
a.작업일련번호, a.작업자ID, a.작업상태코드 , nvl(b.고객번호, c.고객번호) 고객번호 , nvl(b.주소, c.주소) 주소, ……
from 작업지시 a, 개통신청 b, 장애접수 c
where a.방문예정일시 = :방문예정일시
and b.개통신청번호(+) = a.개통신청번호
and c.장애접수번호(+) = a.장애접수번호 union all
select x.작업일련번호, x.작업자ID, x.작업상태코드, y.고객번호, y.주소, ……
from 작업지시 x, 개통신청 y
where x.방문예정일시 = :방문예정일시 and x.작업구분 = '1' and y.개통신청번호 = x.접수번호
union all
select x.작업일련번호, x.작업자ID, x.작업상태코드, y.고객번호, y.주소, ……
from 작업지시 x, 장애접수 y
where x.방문예정일시 = :방문예정일시 and x.작업구분 = '2' and y.장애접수번호 = x.접수번호중복 액세스에 의한 비효율을 해소하는 법
select /*+ ordered use_nl(b) use_nl(c) */
a.작업일련번호, a.작업자ID, a.작업상태코드 , nvl(b.고객번호, c.고객번호) 고객번호 , nvl(b.주소, c.주소) 주소, ……
from 작업지시 a, 개통신청 b, 장애접수 c
where a.방문예정일시 = :방문예정일시
and b.개통신청번호(+) = decode(a.작업구분, '1', a.접수번호)
and c.장애접수번호(+) = decode(a.작업구분, '2', a.접수번호) - 인덱스 구성이 [작업구분+방문예정일시] 순일 경우
- 읽는 범위에 중복은 없음.
- 인덱스 구성이 [방문예정일시+작업구분] 순일 경우
- 인덱스 스캔범위에 중복
- [방문예정일시] : 작업구분을 필터링하기 위한 테이블 Random 액세스까지 중복해서 발생한다.
[3] 부등호 조인
(1) 윈도우 함수(Analytic Function)를 이용
- 윈도우 함수를 Oracle에서는 분석 함수(Analytic Function)라고 한다.
(2) 부등호 조인을 이용
- 윈도우 함수를 Oracle에서는 분석 함수(Analytic Function)라고 한다.
select t1.지점, t1.판매월, min(t1.매출) 매출, sum(t2.매출) 누적매출
from 월별지점매출 t1, 월별지점매출 t2
where t2.지점 = t1.지점 and t2.판매월 <= t1.판매월
group by t1.지점, t1.판매월
order by t1.지점, t1.판매월;[4] Between 조인
(1) 점이력과 선분이력
점이력’ 모델 : 이력의 시작시점만을 관리하는 것
‘선분이력’ 모델 : 시작시점과 종료시점을 함께 관리하는 것
1. 선분이력의 특징
- 쿼리가 간단해지며 성능상 유리하다.
- 과거/현재/미래 임의 시점을 조회
select 고객번호, 연체금액, 연체개월수 from 고객별연체금액
where 고객번호 = '123' and '20040815' between b.시작일자 and b.종료일자 ;- 현재 시점을 조회할 때는 ‘99991231’ 상수 조건을 이용해 아래와 같이 ‘=’ 조건으로 검색하는 것이 성능상 유리하다.
select 연체개월수, 연체금액
from 고객별연체금액
where 고객번호 = :cust_num
and 종료일자 = '99991231';- 점이력 쿼리
select 고객번호, 연체금액, 연체개월수 from 고객별연체금액 a
where 고객번호 = '123' and 연체변경일자 = (
select max(연체변경일자)
from 고객별연체금액
where 고객번호 = a.고객번호 and 변경일자 <= '20040815') ;(2) 선분이력 조인 : 미래 시점 데이터를 미리 입력하는 기능 여부
미래 시점 데이터를 미리 입력하는 기능 있음
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호
from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2
where c.고객번호 = :cust_num
and c1.고객번호 = c.고객번호
and c2.고객번호 = c.고객번호
and to_char(sysdate, 'yyyymmdd') between c1.시작일자 and c1.종료일자
and to_char(sysdate, 'yyyymmdd') between c2.시작일자 and c2.종료일자 ;미래 시점 데이터를 미리 입력하는 기능 없음
select c.고객번호, c.고객명, c1.고객등급, c2.전화번호
from 고객 c, 고객등급변경이력 c1, 전화번호변경이력 c2
where c.고객번호 = :cust_num
and c1.고객번호 = c.고객번호
and c2.고객번호 = c.고객번호
and c1.종료일자 = '99991231'
and c2.종료일자 = '99991231';(3) Between 조인 : 미지의 시점으로 조회할때
- 과거 20년 동안 당일 최고가로 장을 마친(종가=최고가) 종목을 조회할 떄 조인 연산자가 '=' 이 아니라 between이 되어야함
select a.거래일자, a.종목코드, b.종목한글명, b.종목영문명, b.상장주식수 , a.시가, a.종가, a.체결건수, a.체결수량, a.거래대금
from 일별종목거래및시세 a, 종목이력 b
where a.거래일자 between to_char(add_months(sysdate, -20*12), 'yyyymmdd') and to_char(sysdate-1, 'yyyymmdd')
and a.종가 = a.최고가
and b.종목코드 = a.종목코드
nd a.거래일자 between b.시작일자 and b.종료일자;- 현재(=최종) 시점의 종목명을 가져오는 것이 아니라 거래가 일어난 바로 그 시점의 종목명을 읽게 된다.
Between 조인
select a.거래일자, a.종목코드, b.종목한글명, b.종목영문명, b.상장주식수 , a.시가, a.종가, a.체결건수, a.체결수량, a.거래대금
from 일별종목거래및시세 a, 종목이력 b
where a.거래일자 between to_char(add_months(sysdate, -20*12), 'yyyymmdd') and to_char(sysdate-1, 'yyyymmdd') and a.종가 = a.최고가
and b.종목코드 = a.종목코드 and to_char(sysdate, 'yyyymmdd') between b.시작일자 and b.종료일자- 거래시점이 아니라 현재(=최종) 시점의 종목명과 상장주식수를 출력
[5] ROWID 활용
(1) ROWID 활용 안 한 경우
- 점이력을 이용한다.
- 찾고자 하는 시점(서비스만료일)보다 앞선 변경일자 중 가장 마지막 레코드를 찾을 경우
select a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.고객번호 = a.고객번호
and b.변경일자 = (
select max(변경일자)
from 고객별연체이력
where 고객번호 = a.고객번호
and 변경일자 <= a.서비스만료일) - 고객별 연체 이력을 두 번 액세스한다.
- 다행스럽게도 옵티마이저가, 서브쿼리 내에서 서비스만료일보다 작은 레코드를 모두 스캔하지 않고 인덱스를 거꾸로 스캔한다.
- 가장 큰 값 하나만을 찾는 실행계획(7번째 라인 first row, 8번째 라인 min/max)을 수립한다.
(2) ROWID 활용한 경우
- 만약 위 쿼리가 가장 빈번하게 수행되는 것이어서 단 한 블록 액세스라도 줄여야 하는 상황이라면 ROWID를 이용해 튜닝한다.
select /*+ ordered use_nl(b) rowid(b) */ a.고객명, a.거주지역, a.주소, a.연락처, b.연체금액, b.연체개월수
from 고객 a, 고객별연체이력 b
where a.가입회사 = 'C70'
and b.rowid = (
select /*+ index(c 고객별연체이력_idx01) */ rowid
from 고객별연체이력 c
where c.고객번호 = a.고객번호
and c.변경일자 <= a.서비스만료일
and rownum <= 1)
--Execution Plan
-------------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=835 Card=100K Bytes=5M)
1 0 NESTED LOOPS (Cost=835 Card=100K Bytes=5M)
2 1 TABLE ACCESS (BY INDEX ROWID) OF '고객' (Cost=825 Card=10 Bytes=410)
3 2 INDEX (RANGE SCAN) OF '고객_IDX01' (NON-UNIQUE) (Cost=25 Card=10)
4 1 TABLE ACCESS (BY USER ROWID) OF '고객별연체이력' (Cost=1 Card=10K Bytes=137K)
5 4 COUNT (STOPKEY)
6 5 INDEX (RANGE SCAN) OF '고객별연체이력_IDX01' (NON-UNIQUE) (Cost=2 Card=5K… )- a와 b간에 따로 조인문 기술이 불필요하다.
- 고객(a)에서 읽은 고객번호로 서브쿼리 쪽 고객별연체이력(c)과 조인하고, 거기서 얻은 rowid 값으로 고객별연체이력(b)을 곧바로 액세스한다.
- 고객별연체이력을 두 번 참조했지만, 실행계획 상에는 한 번만 조인한 것과 일량이 같다.
- 제대로 작동하려면 고객별연체이력_idx01 인덱스가 반드시 [ 고객번호 + 변경일자 ] 순으로 구성돼 있어야 한다.
SQL Server와 Oracle
- SQL Server는 Oracle처럼 사용자가 직접 ROWID를 이용해 테이블을 액세스(Table Access By User Rowid)하는 방식을 지원하지 않는다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’