[1] 병렬 처리 활용
- SQL문이 수행해야 할 작업 범위를 여러 개의 작은 단위로 나누어
여러 프로세스(또는 쓰레드)가 동시에 처리하는 것 - 여러 프로세스가 동시에 작업하므로 대용량 데이터를 처리할 때 수행 속도를 극적으로 단축
select /*+ full(o) parallel(o, 4) */
count(*) 주문건수, sum(주문수량) 주문수량, sum(주문금액) 주문금액
from 주문 o
where 주문일시 between '20100101' and '20101231';
select /*+ index_ffs(o, 주문_idx)) parallel_index(o, 주문_idx, 4) */
count(*) 주문건수
from 주문 o
where 주문일시 between '20100101' and '20101231';- parallel 힌트를 사용할 때는 반드시 Full 힌트도 함께 사용하는 습관이 필요하다.
- 옵티마이저에 의해 인덱스 스캔이 선택되면 parallel 힌트가 무시되기 때문이다.
- parallel_index 힌트를 사용할 때, 반드시 index 또는 index_ffs 힌트를 함께 사용하는 습관도 필요하다.
- 옵티마이저에 의해 Full Table Scan이 선택되면 parallel_index 힌트가 무시되기 때문이다.
(1) Query Coordinator와 병렬 서버 프로세스
1. Query Coordinator(이하 QC)
- 병렬 SQL문을 발행한 세션
- 병렬 서버 프로세스는 실제 작업을 수행하는 개별 세션들이다.
QC의 역할
select /*+ ordered use_hash(d) full(d) full(e) noparallel(d) parallel(e 4) */
count(*), min(sal), max(sal), avg(sal), sum(sal)
from dept d, emp e
where d.loc = 'CHICAGO' and e.deptno = d.deptno; - 병렬 SQL이 시작되면 QC는 사용자가 지정한 병렬도(DOP, degree of parallelism)와
오퍼레이션 종류에 따라 하나 또는 두 개의 병렬 서버 집합(Server Set)을 할당 - 우선 서버 풀(Parallel Execution Server Pool)로부터 필요한 만큼 서버 프로세스를 확보하고,
부족분은 새로 생성한다. - QC는 각 병렬 서버에게 작업을 할당한다.
- 작업을 지시하고 일이 잘 진행되는지 관리감독하는 작업반장 역할.
- 병렬로 처리하도록 사용자가 지시하지 않은 테이블은 QC가 직접 처리한다.
- QC는 각 병렬 서버로부터의 산출물을 통합하는 작업을 수행한다.
- 예를 들어 집계 함수(sum, count, avg, min, max 등)가 사용된 병렬 쿼리를 수행할 때,
각 병렬 서버가 자신의 처리 범위 내에서 집계(4번 단계)한 값을 QC에게 전송(3번 단계)하면
QC가 최종 집계 작업을 수행(1번 단계)한다.
- 예를 들어 집계 함수(sum, count, avg, min, max 등)가 사용된 병렬 쿼리를 수행할 때,
- QC는 쿼리의 최종 결과집합을 사용자에게 전송하며, DML일 때는 갱신 건수를 집계해서 전송해 준다.
- 쿼리 결과를 전송하는 단계에서 수행되는 스칼라 서브쿼리도 QC가 수행한다.
(2) Intra-Operation Parallelism과 Inter-Operation Parallelism
select /*+ full(고객) parallel(고객 4) */ *
from 고객
order by 고객명;1. Intra-Operation Parallelism
- 서로 배타적인 범위를 독립적으로 동시에 처리하는 것
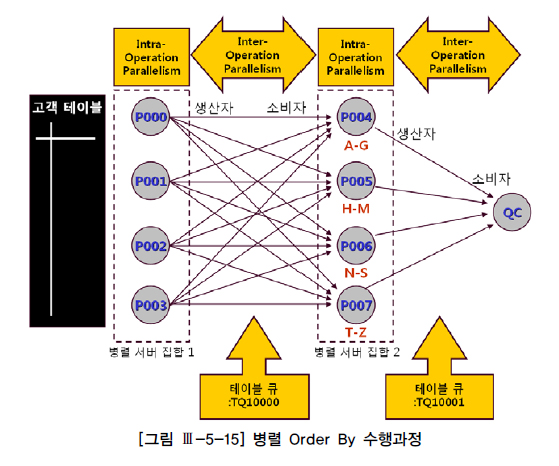
- 첫 번째 서버 집합(P000~P003)에 속한 4개의 프로세스가 범위를 나눠 고객 데이터를 읽는 작업
- 두 번째 서버 집합(P004~P007)이 첫 번째 서버 집합으로부터 전달받은 고객 데이터를 정렬하는 작업
- 한 병렬 서버 집합(Server Set)에 속한 여러 프로세스가 처리 범위를 달리하면서
병렬로 작업을 진행하는 것이므로 집합 내에서는 절대 프로세스 간 통신이 발생하지 않는다.
2. Inter-Operation Parallelism
- 같은 서버 집합끼리는 서로 데이터를 반대편 서버 집합에 분배하거나 정렬된 결과를 QC에게 전송하는 작업을 병렬로 동시에 진행하는 것.
- 이때는 항상 프로세스 간 통신이 발생한다.
- 메시지 또는 데이터를 전송하기 위한 통신 채널이 필요하다.
3. 테이블 큐
select /*+ ordered use_hash(e) full(d) noparallel(d) full(e) parallel(e 2) pq_distribute(e broadcast none) */ *
from dept d, emp e
where d.deptno = e.deptno
order by e.ename;
- Inter-Operation Parallelism에서 쿼리 서버 집합 간(P→P) 또는 QC와 쿼리 서버 집합 간(P→S, S→P)
데이터 전송을 위해 연결된 파이프 라인(Pipeline) - 각 테이블 큐에 부여된 :TQ10000, :TQ10001, :TQ10002와 같은 이름을 ‘테이블 큐 식별자(TQ Identifier)’라고 한다.
- 쿼리 서버 집합 간(P→P) Inter-Operation Parallelism이 발생할 때는 사용자가 지정한 병렬도(=2)의 배수(4개)만큼 서버 프로세스가 필요하다.
- 또한 테이블 큐(:TQ10001)에는 병렬도의 제곱(2^2=4)만큼 파이프 라인이 필요하다는 사실도 알 수 있다.
- 참고로 그림 Ⅲ-5-15를 보면, 병렬도가 4이므로 8(=4×2)개 서버 프로세스를 위해 16(=4^2)개의
파이프 라인이 형성되었다.
생산자 / 소비자 모델
- 테이블 큐에는 항상 생산자(Producer)와 소비자(Consumer)가 존재한다.
- 처음 dept 테이블을 읽어 분배하는 :TQ10000에서는 QC가 생산자고 서버 집합 1이 소비자다.
- 이어지는 두 번째 테이블 큐 TQ10001에서는 서버 집합 1이 생산자가 되고, 서버 집합 2가 소비자.
- 마지막으로, 정렬된 최종 결과집합을 전송하는 :TQ10002에서는 서버 집합 2가 생산자가 되고 QC가 소비자.
- select 문장에서의 최종 소비자는 항상 QC일 것.
- [그림 Ⅲ-5-16]에서 보듯 Inter-Operation Parallelism이 나타날 때, 소비자 서버 집합은 from절에 테이블 큐를 참조하는 서브(Sub) SQL을 가지고 작업을 수행한다.
4. IN-OUT 오퍼레이션
- S→P, P→S, P→P는 프로세스 간 통신이 발생한다.
S→P
- QC가 처리한 결과를 병렬 서버 프로세스에 전달
- 직렬(Serial) 오퍼레이션
P→S
- 병렬 서버 프로세스가 처리한 결과를 QC에 전달
- 병렬 오퍼레이션
P→P
- 두 개의 병렬 서버 프로세스 집합이 처리
- 지정한 병렬도의 2배 만큼의 병렬 프로세스 생성
- 병렬 오퍼레이션
PCWP와 PCWC
- 프로세스 간 통신이 발생하지 않음
- 각 병렬 서버가 독립적으로 여러 스텝을 처리할 때 나타난다.
- 하위 스텝의 출력 값이 상위 스텝의 입력 값으로 사용된다.
PCWP
- 병렬 서버 프로세스 집합이 현재 스텝과 그 부모 스텝을 모두 처리
- 병렬 오퍼레이션
PCWC
- 병렬 서버 프로세스 집합이 현재 스텝과 그 자식 스텝을 모두 처리
- 병렬 오퍼레이션
5. 데이터 재분배
병렬 서버 프로세스 간에 데이터를 재분배하는 방식
RANGE
- order by 또는 sort group by를 병렬로 처리할 때 사용된다.
- 두 번째 서버 집합 : 정렬 작업을 맡음
- 프로세스마다 처리 범위(예를 들어, A~G, H~M, N~S, T~Z)를 지정한다.
- 데이터를 읽는 첫 번째 서버 집합이 두 번째 서버 집합의 정해진 프로세스에게 “정렬 키 값에 따라”
분배하는 방식 - QC의 역할
- 각 서버 프로세스에게 작업 범위를 할당
- 정렬 작업에는 직접 참여하지 않음
- 정렬이 완료되고 나면 순서대로 결과를 받아서 사용자에게 전송
- P→P 뿐만 아니라 S→P 방식으로 이루어질 수도 있음
BROADCAST
- QC 또는 첫 번째 서버 집합에 속한 프로세스들
- 각각 읽은 데이터를 두 번째 서버 집합에 속한 “모든” 병렬 프로세스에게 전송하는 방식
- 병렬 조인에서 크기가 매우 작은 테이블이 있을 때 사용
- P→P 뿐만 아니라 S→P 방식으로도 이루어진다.
KEY
- 특정 칼럼(들)을 기준으로 테이블 또는 인덱스를 파티셔닝할 때 사용하는 분배 방식
ROUND-ROBIN
- 파티션 키, 정렬 키, 해시 함수 등에 의존하지 않고 반대편 병렬 서버에 무작위로 데이터를 분배할 때 사용
6. pq_distribute 힌트 활용
(1) pq_distribute 힌트의 용도
- 조인되는 양쪽 테이블의 파티션 구성, 데이터 크기 등에 따라 병렬 조인을 수행하는 옵티마이저의 선택이 달라질 수 있음
- 옵티마이저의 선택을 무시하고 사용자가 직접 조인을 위한 데이터 분배 방식을 결정
(2) pq_distribute 힌트 사용
- 옵티마이저가 파티션된 테이블을 적절히 활용하지 못하고 동적 재분할을 시도할 때
- 기존 파티션 키를 무시하고 다른 키 값으로 동적 재분할하고 싶을 때
- 통계정보가 부정확하거나 통계정보를 제공하기 어려운 상황
- 옵티마이저가 잘못된 판단을 하기 쉬운 상황에서 실행계획을 고정시키고자 할 때
- 기타 여러 가지 이유로 데이터 분배 방식을 변경하고자 할 때
(3) 사전 준비작업
- 병렬 방식으로 조인을 수행하기 위해서는 프로세스들이 서로 “독립적으로” 작업할 수 있도록 함
select /*+ ordered use_merge(e) parallel(d 4) parallel(e 4) pq_distribute(e hash hash) */ *
from dept d, emp e
where e.deptno = d.deptno ;- 먼저 데이터를 적절히 배분하는 작업이 선행
- 병렬 쿼리는 ‘분할 & 정복(Divide & Conquer) 원리’에 기초한다.
- 그 중에서도 병렬 조인을 위해서는 ‘분배 & 조인(Distribute & Join) 원리’가 작동함을 이해하는 것이 매우 중요
- 즉 , pq_distribute 힌트는 조인에 앞서 데이터를 분배(distribute) 과정에만 관여하는 힌트임을 반드시 기억!!
(4) pq_distribute 사용법
- pq_distribute(inner, none, none)
- Full-Partition Wise Join으로 유도할 때 사용
- 당연히, 양쪽 테이블 모두 조인 칼럼에 대해 같은 기준으로 파티셔닝(equi-partitioning) 돼 있을 때만 작동한다.
- pq_distribute(inner, partition, none)
- Partial-Partition Wise Join으로 유도할 때 사용
- outer 테이블을 inner 테이블 파티션 기준에 따라 파티셔닝하라는 뜻이다.
- 당연히, inner 테이블이 조인 키 칼럼에 대해 파티셔닝 돼 있을 때만 작동한다.
- pq_distribute(inner, none, partition)
- Partial-Partition Wise Join으로 유도할 때 사용
- inner 테이블을 outer 테이블 파티션 기준에 따라 파티셔닝하라는 뜻이다.
- 당연히, outer 테이블이 조인 키 칼럼에 대해 파티셔닝 돼 있을 때만 작동한다.
- pq_distribute(inner, hash, hash)
- 조인 키 칼럼을 해시 함수에 적용하고 거기서 반환된 값을 기준으로 양쪽 테이블을
동적으로 파티셔닝하라는 뜻이다. - 조인되는 테이블을 둘 다 파티셔닝해서 파티션 짝(Partition Pair)을 구성하고서 Partition Wise Join을 수행한다.
- pq_distribute(inner, broadcast, none)
- outer 테이블을 Broadcast 하라는 뜻이다.
- pq_distribute(inner, none, broadcast)
- inner 테이블을 Broadcast 하라는 뜻이다.
(5) pq_distribute 힌트를 이용한 튜닝 사례
- 통계 정보가 없거나 잘못된 상태에서 병렬 조인을 수행하면 옵티마이저가 아주 큰 테이블을
Broadcast 하는 경우가 종종 생김
튜닝전
SQL> INSERT /*+ APPEND */ INTO 상품기본이력 ( ... )
2 SELECT /*+ PARALLEL(A,32) PARALLEL(B,32) PARALLEL(C,32) PARALLEL(D,32) */ ......
3 FROM 상품기본이력임시 a, 상품 b, 코드상세 c, 상품상세 d
4 WHERE a.상품번호= b.상품번호
5 AND ...
INSERT /*+ append */ INTO 상품기본이력 ( *
1행에 오류:
ORA-12801: 병렬 질의 서버 P013에 오류신호가 발생했습니다
ORA-01652: 2- 임시 테이블을 많이 사용하는 야간 배치나 데이터 이행(Migration) 프로그램에서 그런 문제가 자주 나타나는데, 위는 데이터 이행 도중 실제 문제가 발생했던 사례다.
- 1시간 40분간 수행되던 SQL이 임시 세그먼트를 확장할 수 없다는 오류 메시지를 던지면서 멈춤
- 상품기본이력임시 테이블에 통계 정보가 없던 것이 원인.
- 실제 천만 건에 이르는 큰 테이블이었는데,통계 정보가 없어 옵티마이저가 5,248건의 작은 테이블로 판단한 것.
- 이 큰 테이블을 32개 병렬 서버에게 Broadcast하는 동안 과도한 프로세스 간 통신이 발생했고, 결국 Temp 테이블 스페이스를 모두 소진하고서 멈췄다.
튜닝후
pq_distribute 힌트를 이용해 데이터 분배 방식을 조정하고 나서 다시 수행해 본 결과, 아래와 같이 2분 29초 만에 작업을 완료하였다.
SQL> INSERT /*+ APPEND */ INTO 상품기본이력 ( ... )
2 SELECT /*+ ORDERED PARALLEL(A,16) PARALLEL(B,16) PARALLEL(C,16) PARALLEL(D,16)
3 PQ_DISTRIBUTE(B, NONE, PARTITION)
4 PQ_DISTRIBUTE(C, NONE, BROADCAST)
5 PQ_DISTRIBUTE(D, HASH, HASH) */ ......
6 FROM 상품기본이력임시 a, 상품 b, 코드상세 c, 상품상세 d
7 WHERE a.상품번호= b.상품번호
8 AND ...7. 병렬 처리 시 주의사항
- 병렬 쿼리를 과도하게 사용하면 시스템을 마비시킬 수도 있다.
- 적절한 사용 기준이 필요하다.
(1) 병렬 처리 기법을 사용하기 바람직할 때
- 동시 사용자 수가 적은 애플리케이션 환경(야간 배치 프로그램, DW, OLAP 등)에서 직렬로 처리할 때보다 성능 개선 효과가 확실할 때
- 이 기준에 따르면 작은 테이블은 병렬 처리 대상에서 제외됨
- OLTP성 시스템 환경이더라도 작업을 빨리 완료함으로써 직렬로 처리할 때보다 오히려 전체적인
시스템 리소스(CPU, Memory 등) 사용률을 감소시킬 수 있을 때- 수행 빈도가 높지 않음을 전제로 한다.
(2) 야간 배치 프로그램
- 야간 배치 프로그램에는 병렬 처리를 자주 사용하는데, 야간 배치 프로그램은 전체 목표 시간을 달성하는 것을 목표로 해야지 개별 프로그램의 수행속도를 단축하려고 필요 이상의 병렬도를 지정해선 안 된다.
- 업무적으로 10분 이내 수행이 목표인 프로그램을 5분으로 단축하려고 병렬 처리 기법을 남용하지 말라는 뜻
- 야간이더라도, 여러 팀에서 작성한 배치 프로그램이 동시에 수행되는 상황에서 특정 소수 배치 작업이 과도한 병렬 처리를 시도한다면 CPU, 메모리, 디스크 등 자원에 대한 경합 때문에 오히려 전체 배치
수행 시간이 늘어날 수 있다. - 병렬도를 높인다고 성능이 선형적으로 좋아지는 것도 아니다.
- 결론적으로, 성능개선 효과가 확실한 최소한의 병렬도를 지정하려는 노력이 필요
(3) 데이터 이행(Migration)
- 물론 시스템 리소스를 최대한 사용해야 할 때는 모든 애플리케이션을 중지시키고 이행 프로그램이 시스템을 독점적으로 사용하기 때문에 가능한 모든 리소스를 활용해 이행 시간을 최대한 단축하는 것을 목표로 삼는 것이 당연하다.
- 병렬 DML 수행 시 Exclusive 모드 테이블 Lock이 걸리므로 트랜잭션이 활발한 주간에 절대 사용해선 안 된다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’