p.8,9
데이터 모델링
2번
- 데이터 모델링은 데이터베이스만을 구축하기 위한 용도가 아니다.
데이터모델링 자체로서 업무를 설명하고 분석한다.
5번
- 개념적 데이터 모델링 : 추상화 / 업무중심 / 포괄적 / 전사적
- 논리적 데이터 모델링 : KEY / 속성 / 관계 / 재사용성
- 물리적 데이터 모델링 : 물리적 / 성능 / 저장
엔터티
- 발생 시점에 따른 분류 : 행중기(ㅋㅋ)
- 기본 엔티티 (키 엔터티)
- 사원 , 부서 , 고객 , 상품
- 중심 엔터티 : 기본엔터티로부터 발생. 업무에서 중심적인 역할
- 계약 , 주문 , 매출
- 행위 엔터티
- 주문 목록 , 사원 변경 이력
- 기본 엔티티 (키 엔터티)
- 유무형에 따른 분류 : 유사개(ㅋ큐ㅠ애쓴다)
- 유형 엔티티
- 사원 , 물품 , 강사
- 개념 엔터티 : 개념적 정보로 구분
- 부서 , 보험상품
- 사건 엔터티 : 업무 수행에 따라 발생되는 엔터티
- 주문 , 청구 , 미납
- 유형 엔티티
p.10
스키마
6번
- 외부 스키마
- 개념 스키마 : 통합 관점
- 내부 스키마
다이어그램 보는 법
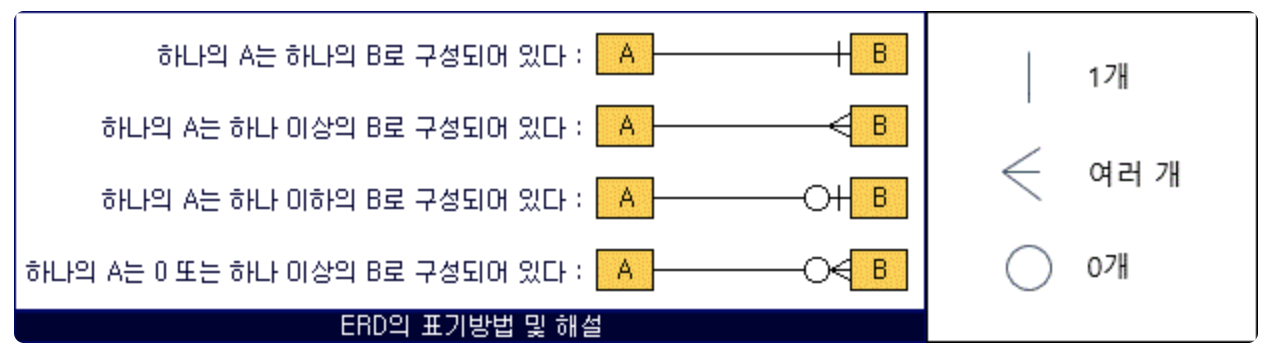

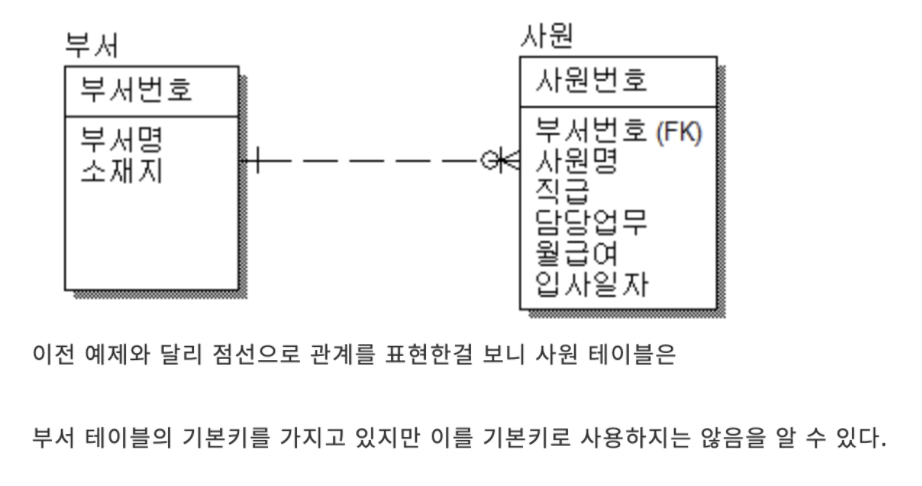
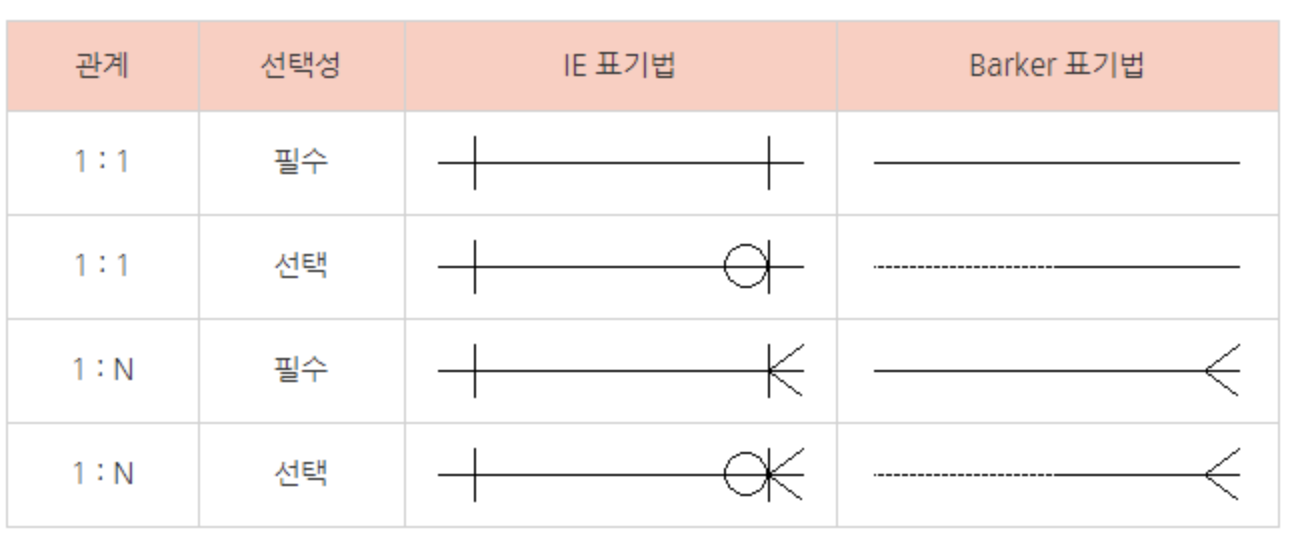
p.12,13
속성
15번
- 각각 속성은 하나의 속성값만 가진다.
- 속성도 집합이다.
16번
- 속성의 분류
- 기본 속성 : 이자 , 원금 , 예치기간 등
- 파생 속성 : 계산된 값 / 이자
- 설계 속성 : 예금분류
p.15 , 16
관계
22번
- 관계의 표기법
- 관계명
- 관계 차수
- 관계 선택 사양 (필수 / 선택)
식별자
식별자 구분
- 대표성
- 주 식별자 : 명칭 , 내역 , 이름 같은 것들은 가능하면 주식별자로 지정 안 함
- 보조 식별자
- 스스로 생성 여부
- 내부 식별자
- 외부 식별자
- 단일 속성 여부
- 단일 식별자
- 복합 식별자
- 의미 여부
- 본질 식별자 : 사번
- 인조 식별자
p.22
데이터모델링 순서
32번
- 정규화
- 용량산정
- 트랜잭션 유형 분석
- 반정규화
- PK/FK 조정 , 이력모델 조정, 슈퍼/서브 타입 조정
- 성능관점에서 모델 검증
p.23,24
정규화 종류
1차 정규화
- 37번 : 동일한 성격의 속성 반복 ( 속성의 원자성 위배 )
2차 정규화
- 35번 , 36번 : 함수 종속성 규칙
p.27
반정규화 종류
- 테이블 병합
- 1:1 관계 , 1:M 관계 , 슈퍼/서브 타입
- 테이블 분할
- 수직 / 수평 분할
- 테이블 추가
- 중복 테이블 추가
- 부분 테이블 추가 : 집중화된 칼럼을 별도로 모아두는 경우
- 이력 테이블 추가
- 통계 테이블 추가
- 중복 칼럼 추가
- 파생 칼럼 추가
- 이력 테이블 칼럼 추가 : 최신값을 처리하는 이력의 특성을 고려하여 이력 테이블에 기능성 칼럼을 추가하는 경우
- PK에 의한 칼럼 추가
- FK에 대한 속성을 추가하는 건 반정규화가 아니다.그냥 자연스러운 현상이다.
- 응용 시스템 오작동을 위한 칼럼 추가
p.40
- DCL : GRANT , REVOKE
- TCL : COMMIT , ROLLBACK (DCL로 분류하기도한다.)
p.42
CONSTRAINT 문법
CREATE TABLE T1 ( .. , CONSTRAINT T1_PK PRIMARY KEY (PROD_ID)); p.43
ALTER TABLE 문법 (sql server)
- 여러 컬럼 동시 수정 불가능
- 괄호 안에서 수정하는 거 불가능 (따로따로해야함)
- not null은 변화여부 상관없이 무조건 지정해야함
ALTER TABLE T1 **ALTER COLUMM** 분류명 VARCHAR(30) NOT NULL;
ALTER TABLE T1 **ALTER COLUMM** 등록일자 DATE NOT NULL;p.47
ALTER TABLE T1 DROP COLUMN COL1; (oracle)
p.48
테이블명 변경 : RENAME T1 TO T2;
p.49
(1) 참조 동작
Delete
- Cascade : 같이 삭제
- Set null
- Set Default
- Restrict : 자식에 없을 때만 삭제 가능
- No Action
insert
- Automatic : 마스터에 자동 생성
- Set null
- Set Default
- Dependent : 마스터에 있을 때만 insert 가능
- No Action
(2) INSERT 문법
- INSERT INTO T1 VALUES( a,b,c).. : 빠짐없이 넣어야함
- INSERT INTO T1 (COL1,COL2) VALUES (a,b); : 선택해서 넣을 수 있음
p.50
22번
- delete 참조 동작으로 set null을 설정했지만 해당 컬럼이 not null이면 삭제가 되지 않는다.
p.54
SAVEPOINT P1; ROLLBACK TO P1; (oracle)
SAVE TRANSACTION P1; ROLLBACK TRANSACTION P1;(sql server)
p.56
37번
- primary key는 모든 컬럼에 입력되어있어야한다.
- sql server는 ''로 입력된 값은 is null 로 비교할 수없다. ( = '' 로 비교함)
p.59
40번
- 1:M 관계의 두 테이블을 조인할 경우 M쪽의 다중행이 출력되므로 단일행 함수는 사용할 수 없다.
=> 사용할 수 있다. M쪽 행에 하나씩 단일행 함수를 적용해주면 된다.
p.61
단일행함수 문법
- COALESCE : 커미션을 1차 선택값으로, 급여를 2차 선택값으로 선택하되 두 칼럼 모두 NULL인 경우는 NULL로 표시 / 인수 숫자 한정없음
SELECT ENAME, COMM, SAL, COALESCE(COMM, SAL) COAL FROM EMP;- SUBSTR : 첫번째 글자의 index는 1이다.
SELECT SUBSTR('안녕하세요',3) FROM DUAL; -- 하세요
SELECT SUBSTR('안녕하세요',3,2) FROM DUAL; -- 하세- NULLIF : COL1 이 'A'이면 COL1을 널값으로 표시한다.
SELECT NULLIF(COL1,'A') FROM TBL_A;p.63
45번
- sql server에서는 ''값이 널값이 아니다.따라서 카운트하면 얘도 같이 카운팅된다.
- sql server에서는 nvl을 isnull로 쓴다.
p.82
조인
70번
- 조인할 때 USING절엔 ALIAS 못들어감 , 접두사 못붙임
USING A.ID = B.ID -- 틀림
USING(ID) -- 맞음- select 할 때도 A.ID , B.ID가 아니라 SELECT ID 라고 해야함
카타시안곱
- CROSS JOIN이라고 쓰면 된다.
FROM T1 CROSS JOIN T2⭐️ 아우터조인 조건절 조심 (72번)
FROM A LEFT OUTER JOIN B
WHERE A.ID in (1,2)
ON A.PID=B.PID와
FROM A LEFT OUTER JOIN B
ON A.ID in (1,2) AND A.PID=B.PID는 결과가 전혀 다르다.
p.86
76번
- between 1 and 3의 범위는 1,2,3이다.
p.95
계층형 질의
- 89번 : START WITH절은 WHERE절을 적용하지 않는다.
p.100
95번
- 복수행 비교 연산자 : IN
- 다중 컬럼 서브쿼리는 SQL Server에서 지원하지 않는다.
p.121 , 123
윈도우 함수
116번
- group by 절과 window함수가 같이 있을 땐 grouping된 결과집합에서 윈도우 함수 처리를 한다.
118번 : LAG 함수 , LEAD 함수
LAG(START_VAL) OVER(PARTITION BY ..) -- 현재 행으로부터 이전 START_VAL값
LEAD(START_VAL) OVER(PARTITION BY ..) -- 현재 행으로부터 이후 START_VAL값p.126
124번
- PL/SQL에서 DDL문을 사용하려면
execute immediate문을 써야한다.
트리거
125번 : 트리거의 용도
- 트리거의 용도는 데이터의 무결성과 일관성을 위해 사용자 정의 함수는 사용하는 것이다.
126번 : 트리거의 용도
- 트리거의 용도는 데이터의 무결성과 일관성을 위해 사용자 정의 함수는 사용하는 것이다.
p.160
32번
- 옵티마이저의 최적화 과정과 CALL 발생량은 좀 무관하다.
37번
- 서브쿼리 안에 ROWNUM을 쓰면 뷰 머징을 방지할 수 있다.
- 서브쿼리의 캐싱 효과를 늘 고려해야한다.
- 여기서는 상품코드가 PK이기 때문에 캐싱 효과가 없다고 판단한듯
- 따라서 뷰 머징이 안된 인라인뷰가 가장 성능이 좋다고 함
⭐️ 힌트 사용없이 뷰 머징 방지하기
- 집합 연산자 사용 : union , union all , intersect , minus
- connect by 절 사용
- ROWNUM 칼럼 사용
- select-list에 집계함수 사용 : avg , sum ...
- 뷰 안에 group by가 들어간거랑은 말이 다름 (이 때는 뷰 머징이 된다.)
- 41번 (p.164)
- 분석함수 사용
p.172
51번
- 인덱스 클러스터링 팩터 계산 : 테이블 액세스 횟수만큼 블록 I/O가 발생한거면 아주아주 나쁜거다.
52번
- 인덱스 설계 중요 선택 기준 순서
- 자주 사용하는지
- '=' 조건으로 자주 조회되는지
- 소트 생략이 가능한지
p.175,176
58번
- 스칼라 서브쿼리는 PGA에 캐싱된다.
59번 : 효율 비효율 문제
- 앞에 group by 해서 데이터 딱 나왔는데 그 후에 조인을 만족하는 데이터 양이 현저히 작으면 그건 비효율적인 것이다.
p.187
69번
- 이력 조회 효율적인 쿼리
- rank_over() 는 부분범위가 가능한듯??
- 함수 호출 부하 : 스칼라 서브쿼리 > 인라인 뷰
70번
- 아래 절 사용시 쿼리 안에 있는 모든 테이블이 다 Exclusive TM 락이 걸리며
트랜잭션에도 Exclusive TX 락이 걸린다.insert /*+ append */
p.194
81번
- redo 로그 생성 안 하는 법
- append 힌트 사용 + insert
- nologging CTAS
- parallel + insert
p.200
분석함수는 where로 데이터가 한 번 필터링 되고나서 실행된다.
즉, 대상 데이터가 이미 필터링을 거친 대상으로 분석함수가 실행되는 거임
p.201
union all 처리는 nvl로 구현하면 된다.
p.204
보통 파티션 된 테이블은 pruning 컬럼과 인덱리스 컬럼이 따로놀며 풀스캔을 처리하는 경우가 많다.
데이터 재분배 말고 use_hash()를 이용했는데 뭐가 맞는지 잘 모르겠다.
스칼라 서브쿼리의 캐싱 효과를 꼭 확인한다. 이 문제에는 캐싱 효과가 없어서 그냥 INDEX_FFS 처리 후 해시 조인으로 처리하였다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’