✍️ 1번 : 오라클에서 예상 실행계획을 출력하는 방법
explain plan for
select* from emp where enane a cename and deptno = deptno;
select * from table(dbms_xplan.display(null, null, "typical') );🍒 문제 해설
- explain plan for문을 사용하면 실행계획이 PLAN_TABLE에 저장된다.
- PLAN_TABLE에 저장된 정보를 읽어 분석하기 쉬운 형태로 포매팅하는 가장 쉬운 방법은 dbms_xplan.display 함수를 사용하는 것이다.
✍️ 2번 : SQL Server에서 예상 실행계획을 출력하는 방법
use pubs
go
set ? on
go
select * from dbo.employee;
go🍋 기출 포인트
- set showplan_text on 구문을 사용한다.
✍️ 3번 : 오라클 예상 실행계획에서 확인할 수 있는 정보
오라클 예상 실행계획에서 확인할 수 있는 정보가 아닌 것
- 예상 Cardinality 👉 ⭕️
- 예상 Cost 👉 ⭕️
- 조건절 정보(Predicate Information) 👉 ⭕️
- 예상 Sort 👉 ❌
🍒 문제 해설
- 오라클 예상 실행계획에서 기본으로 (dbms_xplan.display 함수 세 번째 인자에 'typical' 입력)을 설정한다.
1.이에 확인할 수 있는 정보는
Plan Hash Valve
오브젝트 액세스 방식(Operation)
오브젝트명
예상 Cardinality (Rows),
예상 데이터 크기(Bytes),
예상 Cost,
예상 CPU Time,
조건절 정보(Predicate Information) 등
🍋 기출 포인트
- 예상 Sort는 알 수 없다.
✍️ 4번 : 오라클 AutoTrace에서 확인할 수 있는 정보
오라클 AutoTrace에서 확인할 수 있는 정보가 아닌 것
- 예상 실행계획 👉 ⭕️
- 실제 사용한 CPU Time 👉 ❌
- 실제 디스크에서 읽은 블록 수 👉 ⭕️
- 실제 기록한 Redo 크기 👉 ⭕️
🍒 문제 해설
✅ 오라클 AutoTrace에서 확인할 수 있는 정보
- 예상 실행계획
- 실제 디스크에서 읽은 블록 수
- 실제 기록한 Redo 크기
- ⭐️ 오라클 AutoTrace에서 실제 사용한 CPU Time은 알 수 없다.

✍️ 5번 : 오라클 AutoTrace 옵션
SQL> set autotrace ?
SQL> select from enp where ename = 'SCOTT';오라클 AutoTrace 에서 SQL을 실제로 수행하지 않고 예상 실행계획만 출력하고자 할 때
- traceonly explain 👉 ⭕️
🍒 문제 해설
✅ AutoTrace에서 사용할 수 있는 옵션
[키워드 다섯가지를 조합하는 것이다.]
- 공통 문법 : set autotrace
- 선택 문법1(결과출력 여부)
- 결과 출력 : on
- 결과 미출력 : traceonly
- 선택 문법2(실행계획/실행통계)
- 실행계획 : explain
- 실행통계 : statistics
[결과 출력 O (당연히 SQL 실행)]
- set autotrace on
- SQL을 실행
- 결과집합 있음
- 예상 실행계획 및 실행통계를 출력
- set autotrace on explain
- SQL을 실행
- 결과집합 있음
- 예상 실행계획을 출력
- set autotrace on statistics
- SQL을 실행하고
- 결과집합 있음
- 실행통계를 출력
[결과 출력 X]
- set autotrace traceonly
- SQL을 실행하고
- 결과는 출력하지 않고
- 예상 실행계획과 실행통계 출력
- set autotrace traceonly explain
- ⭐️ SQL을 실제로 실행하지 않고
- 예상 실행계획만 출력
- set autotrace traceonly statistics
- SQL을 실행하고
- 결과는 출력하지 않고
- 실행통계만 출력
✍️ 6번 : 오라클에서 SQL 트레이스를 확인하기
오라클에서 SQL 트레이스를 확인하고자 할 때, 아래 빈칸에 들어갈 명령어
SQL> ?
SQL> select from emp where ename = 'SCOTT' ;답 : alter session set sql_trace='true'
✍️ 7번 : 오라클 트레이스 파일을 분석해서 리포트 파일을 생성해 주는 명령어
다음 중 를 고르시오
① parse_trace
① doms_xplan.display
③ dbms_xplan.display_cursor
③ - tkprof 👉 ⭕️
- parse_trace 👉 ❌
- doms_xplan.display 👉 ❌
- dbms_xplan.display_cursor 👉 ❌
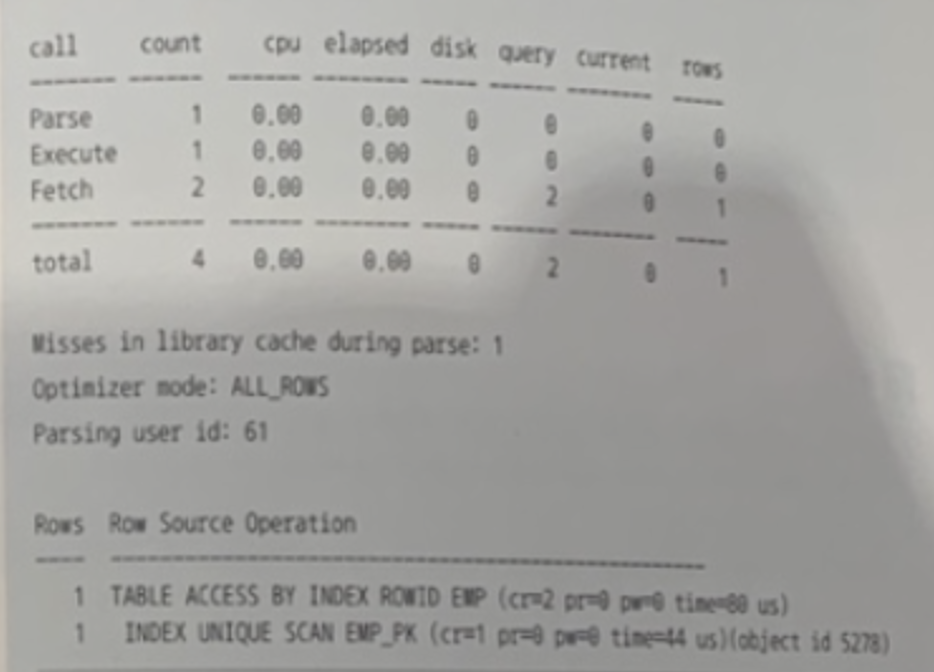
✍️ 8번 : 오라클의 기본 SQL 트레이스(10046 트레이스)에서 확인할 수 있는 정보
오라클의 기본 SQL 트레이스(10046 트레이스)에서 확인할 수 있는 정보가 아닌 것
- 하드파싱 횟수 👉 ⭕️
- 실제 디스크에서 읽은 블록 수 👉 ⭕️
- 실제 사용한 CPU Time 👉 ⭕️
- 실제 기록한 Redo 크기 👉 ❌
🍒 문제 해설
✅ 오라클 기본 Trace에서 확인할 수 있는 정보
- 예상 실행계획
- 실제 디스크에서 읽은 블록 수
- 실제 사용한 CPU Time
🍋 기출 포인트
- 오라클의 기본 SQL 트레이스(10046 트레이스)에서 실제 기록한 Redo 크기는 알 수 없다.
- autotrace에서는 실제 사용한 CPU Time을 알 수 없고 오라클의 기본 SQL 트레이스에서는 실제 기록한 Redo 크기를 알 수 없다.
✍️ 9번 : 오라클 AutoTrace 항목과 SQL 트레이스 항목 비교
오라클 AutoTrace 항목(좌측)과 SQL 트레이스 항목(우측)을 서로 매칭해 놓은 것으로 가장 부적절한 것
- consistent gets = query 👉 ⭕️
- SQL*Net roundtrips to/from client = fetch call count 👉 ⭕️
- rows processed = fetch rows 👉 ⭕️
- recursive calls = parse call count 👉 ❌
🍋 기출 포인트
- AutoTrace recursive calls'는 하드파싱 과정에 딕셔너리를 조회하거나 DB저장형 함수에 내장된 SQL을 수행할 때 발생한 Call 횟수를 표시한다.
✍️ 10번 : 오라클 SGA 메모리에 기록한 SQL 트레이스 정보를 출력하기
SQL> select /*+ ? */ count(*) from big_table;
SQL> select from table( ? (null, null, 'allstats last'));오라클 SGA 메모리에 기록한 SQL 트레이스 정보를 출력하고자 할 때, 아래 빈칸 ㉠과 ㉡에 들어갈 힌트와 함수명?
답 : gather_plan_statistics , dbms_xplan.display_cursor
🍋 기출 포인트
- SQL에 gather_plan_statistics 힌트를 지정하면, SQL 트레이스 정보를 서버 파일이 아닌 SGA 메모리에 기록한다.
- SGA 메모리에 저장된 트레이스 정보를 dbms_xplan.display_cursor 함수를 이용하면 분석하기 쉬운 형태로 포매팅해 준다.
✍️ 11번 : 오라클 SGA 메모리에 기록한 SQL 트레이스 정보를 출력하기
SQL> select /*+ gather_plan_statistics */ count(*) from big_table;
SQL> select * from table(dbms_xplan.display_cursor( [㉠] , [㉡], 'allstats last'));답 : sql_id , child_number
🍋 기출 포인트
- SGA 메모리에 기록한 트레이스 정보를 읽어 분석하기 쉬운 형태로 포매팅하고자 할 때
dbms_xplan.display_cursor 함수를 사용한다. - 첫 번째와 두 번째 인자에는 SQL 커서의 ID와 CHILD_NUMBER를 입력해야 한다.
- 첫 번째와 두 번째 인자에 null, null을 입력하면 바로 직전에 수행한 커서 ID와 CHILD_NUMBER를 내부에서 자동 선택해 준다.
✍️ 12번 : DBMS_XPLAN.DISPLAY_CURSOR 함수
DBMS_XPLAN.DISPLAY_CURSOR 함수로 SOL 트레이스 정보를 출력하기 전에 처리해야 할 사항과 관련이 없는 것
- SQL에 gather_plan_statistics 힌트 사용 👉 ⭕️
- statistics_level 파라미터를 all로 설정 👉 ⭕️
- _rowsource_execution_statistics 파라미터를 true로 설정 👉 ⭕️
- SQL에 monitor 힌트 사용 👉 ❌
🍋 기출 포인트
- monitor 힌트는 실시간 SQL 모니터링을 위해 사용하는 힌트다.
실시간 SQL 모니터링을 위한 리포트는 dbms_sqltune.report_sql_monitor 함수로 출력한다.
✍️ 13번 : DBMS_XPLAN.DISPLAY_CURSOR 함수로 추출한 SQL 트레이스 항목과 전통적인 파일 방식의 SQL 트레이스 항목 비교
다음 중 을 고르시오.
①
②
®
④ DBMS_XPLAN.DISPLAY_CURSOR 함수로 추출한 SQL 트레이스 항목(좌측)과 전통적인 파일 방식의 SQL 트레이스 항목(우측)을 서로 매칭해 놓은 것으로 가장 적절한 것
- Reads = pr 👉 ⭕️
- Starts = time 👉 ❌
- E-ROWS = rows 👉 ❌
- Buffers = current + pr 👉 ❌
🍒 문제 해설
✅ _DBMS_XPLAN.DISPLAY_CURSOR 함수를 통해 추출한 SQL 트레이스 정보
- Starts : 각 오퍼레이션 단계별 실행 횟수
- E-Rows : 옵티마이저가 예상한 Rows
- A-Rows : 각 오퍼레이션 단계에서 읽거나 갱신한 로우 수
- SQL 트레이스 항목에서는 rows
- A-Times : 각 오퍼레이션 단계별 소요시간
- SQL 트레이스 항목에서는 times
- Buffers : 캐시에서 읽은 버퍼 블록 수
- SQL 트레이스 항목에서는 query(=cr) , current
- Reads : 디스크에서 읽은 블록수
- SQL 트레이스 항목에서는 pr
✍️ 14번 : SQL Server에서 SQL 트레이스를 확인하기
SQL Server에서 SQL 트레이스를 확인하고자 할 때 아래 빈칸에 들어갈 옵션
use pubs
go
set statistics ? on
set statistics io on
set statistics time on
go
select * from dbo.employee;
go답 : profile
✅ SQL 트레이스를 확인하고자 설정하는 옵션
- 공통 문법 : set statistics ? on
- 선택 문법
- profile
- io
- time
- 선택 문법2(실행계획/실행통계)
- 실행계획 : explain
- 실행통계 : statistics
- set statistics profile on
- 각 쿼리가 일반 결과집합을 반환하고 그 뒤에는 쿼리 실행
- 프로필을 보여 주는 추가 결과집합을 반환
- 출력에는 다양한 연산자에서 처리한 행 수 및 연산자의 실행 횟수에 대한 정보도 포함
- set statistics io on
- Transact-SQL 문이 실행되고 나서 해당 문에서 만들어진 디스크 동작 양에 대한 정보를 표시
- set statistics time on
-각 Transact-SQL 문을 구문 분석, 컴파일 및 실행하는 데 사용 한 시간을 밀리초 (0.001초) 단위로 표시
|각 단계에서 읽거나 갱신한 건수
각 단계별 소요시간
캐시에서 읽은 버퍼 블록 수
디스크로부터 읽은 블록 수
✍️ 15번 : SQL Server에서 SQL 트레이스를 확인하기
SOL Server에서 아래와 같이 설정하고 SQL을 실행했을 때 확인할 수 있는 정보가 아닌 것
use pubs
go
set statistics profile on
set statistics io on
set statistics time on
go
select from dbo.employee
go- 구문 분석 및 컴파일 시간 👉 ⭕️
- 논리적/물리적 읽기 수 👉 ⭕️
- 각 오퍼레이션 단계별 실행 횟수 👉 ⭕️
- Fetch Call 횟수 👉 ❌
🍋 기출 포인트
- Fetch Call 횟수는 알 수 없다.
✍️ 16번 : 대기 이벤트(Wait Event)
대기 이벤트(Wait Event)에 대한 설명으로 가장 부적절한 것
- 프로세스가 CPU를 OS에 반환하고 수면(Sleep) 상태로 진입할 때 나타난다. 👉 ⭕️
- 프로세스가 필요로 하는 특정 리소스가 다른 프로세스에 의해 사용 중일 때 나타난다. 👉 ⭕️
- 프로세스가 할 일이 없을 때 나타난다. 👉 ⭕️
- 프로세스가 버퍼캐시, 라이브러리 캐시 등 공유 메모리에서 래치를 획득할 때마다 나타난다. 👉 ❌
🍋 기출 포인트
- 프로세스가 공유 메모리의 버퍼캐시, 라이브러리 캐시에서 정보를 읽으려면 래치를 반드시
획득해야 한다. - 래치를 획득하는 과정에 경합이 발생하면 대기 이벤트가 나타나지만, 경합없이 바로 읽으면 대기 이벤트가 나타나지 않는다.
✍️ 17번 : SQL 하드 파싱과 가장 관련이 깊은 대기 이벤트
SQL 하드 파싱과 가장 관련이 깊은 대기 이벤트
- latch: shared pool 👉 ⭕️
- library cache lock 👉 ❌
- free buffer waits 👉 ❌
- log file sync 👉 ❌
🍒 문제 해설
- library cache lock , library cache pin 대기이벤트는 주로 SOL 수행 도중 DDL을 수행할 때 나타난다.
- free buffer waits 대기 이벤트는 서버 프로세스가 버퍼 캐시에서 Free Buffer를 찾지못해 DBWR에게 공간을 확보해 달라고 신호를 보낸 후 대기할 때 나타난다.
- log file sync 대기 이벤트는 커밋 명령을 전송받은 서버 프로세스가 LGWR에게 로그 버퍼를 로그 파일에 기록해 달라고 신호를 보낸 후 대기할 때 나타난다.
- Latch: shared pool 대기 이벤트는 shared pool 래치를 할당받는 과정에 발생하는 경합과 관련 있으며, 하드 파싱을 동시에 심하게 일으킬 때 주로 나타난다.
🍋 기출 포인트
- Shared Pool에서 특정 오브젝트 정보 또는 SOL 커서를 위한 Free Chunk 할당받으려할 때 shared pool 래치를 할당받아야 한다.
- Latch: shared pool 대기 이벤트는 shared pool 래치를 할당받는 과정에 발생하는 경합과 관련 있으며, 하드 파싱을 동시에 심하게 일으킬 때 주로 나타난다.
✍️ 18번 : Response Time Analysis 성능관리 방법론
대기 이벤트를 기반으로 세션 또는 시스템 전체에 발생하는 병목 현상과 그 원인을 찾아
문제를 해결하는 방법 - 과정을 '대기 이벤트(Wait Event) 기반' 또는 ?
성능관리 방법론이라고 한다.답 : 응답 시간 분석(영어로는 Response Time Analysis)
✍️ 19번 : Response Time Analysis 성능관리 방법론
Response Time Analysis 성능관리 방법론'은 데이터베이스의 응답시간을 아래와 같이 정의한다.
Response Time= ? Time + Wait Time해답 : CPU 또는 Service
🍒 문제 해설
✅ Response Time
Service Time + Wait Time
= CPU Time + Queue Time
✍️ 20번 : AWR(Automatic Workload Repository)
AWR(Automatic Workload Repository)에 대한 설명으로 가장 올바른 것
- 오라클 91 버전까지 사용하던 성능관리 패키지 Statspack을 업그레이드해서 개발하였다. 👉 ⭕️
- AWR을 활용해 효과적으로 문제점을 찾아내려면 성능 이슈가 발생했던 시점을 전후해 가능한
한 긴 스냅샵 구간(하루 정도)에 대한 리포트를 출력해서 분석해야 한다. 👉 ❌ - 응답 시간 분석 방법론의 단점을 보완하기 위해 Ratio 기반 성능 분석 방법론을 도입하였다. 👉 ❌ 이건 Statspack이다.!
- 성능 자료를 수집해서 AMR에 저장할 때 'dba_hist'로 시작하는 각종 뷰를 이용한다. 👉 ❌
🍒 문제 해설
- 오라클은 전통적으로 사용하던 Ratio 기반 성능 분석 방법론에 응답 시간 분석 방법론을 더해 Statspack을 개발하였고 이를 확장 및 업그레이드해서 만든 것이 AWR이다.
- AWR 보고서를 활용해 성능 이슈를 해결하려면 peak 시간대 또는 장애 발생 시점을 전후 가능한 한 짧은 스냅샷 구간을 선택해야 한다.
- AWR은 뷰를 조회하지 않고 DMA(Direct Memory Access) 방식으로 SGA 공유 예모리를 직접 액세스해서 성능 정보를 수집하기 때문에 좀 더 빠르게 정보를 수집할 수 있다.
부하가 적기 때문에 Statspack 보다 더 자주 더 많은 정보를 수집할 수 있다.
과거에 사용하던 Statspack은 SQL로 딕셔너리를 조회해서 성능 정보를 수집했다. - AWR 보고서에 출력되는 항목들은 'dbahist'로 시작하는 각종 뷰를 이용해 사용자가 직접 조회할 수도 있다.
- AWR 보고서를 활용해 성능 이슈를 해결하려면 peak 시간대 또는 장애 발생 시점을 전후가능한 한 짧은 스냅샷 구간을 선택해야 한다.특정 시점에 시스템에 큰 부하가 발생했어도
하루 또는 일주일 보고서로 출력해서 보면 초당 부하 발생량과 대기 시간에 전혀 문제가 있
는 것처럼 평균 수치가 나타나기 때문이다.
🍋 기출 포인트
- AWR 보고서를 활용해 성능 이슈를 해결하려면 peak 시간대 또는 장애 발생 시점을 전후가능한 한 짧은 스냅샷 구간을 선택해야 한다.
✍️ 21번 : 오라클 AWR 보고서
오라클 AWR 보고서 맨 앞쪽의 보고서 요약(Report Summary)에 포함되지 않는 내용
- 부하 프로파일 (Load Profile) 👉 ⭕️
- 인스턴스 효율성(Instance Efficiency) 👉 ⭕️
- 최상위 대기 이벤트(Top N Events) 👉 ⭕️
- SQL 통계(SQL Statistics) 👉 ❌
🍋 기출 포인트
- SQL 통계는 보고서 요약에는 포함되지 않는다.
✍️ 22번 : 인스턴스 효율성 항목들
아래는 인스턴스 효율성 항목들이다. 이중 SQL 파싱과 관련 있는 항목만 골라서 알파벳 기호를 나열하시오.
A) Buffer Nowait %
B) Redo Nowait %
C) Buffer Hit %
D) Soft Parse %
E) In-memory Sort
F) Execute to Parse %
ㅎ) Latch Hit %
H) Parse CPU to Parse Elapsd %해답 : D , F , H
🍋 기출 포인트
- Soft Parse : 실행계획이 라이브러리 캐시에서 찾아져 하드파싱을 일으키지 않고 SQL 을수행한 비율이다. 구하는 공식은 아래와 같다.
(전체 Parse Call 횟수 - 하드파싱 횟수) / (전체 Parse Call 횟수)* 100 - Execute to Parse : Parse Call 없이 곧바로 SQL을 수행한 비율, 즉 커서를 애플리케이션에서 캐싱한 채 반복 수행한 비율이다.
- Parse CPU to Parse Elapsed : 파싱 총 소요 시간 중 CPU time이 차지한 비율이다. 파싱에 소요된 시간 중 실제 일을 수행한 시간 비율을 말하며, 이 값이 낮다면 파싱 도중 대기가 많이 발생했음을 의미한다.
✍️ 23번 : 세션 레벨 실시간 모니터링 기능(ASH)
Ratio 기반 성능 분석 방법론과 시스템 레벨 대기 이벤트 분석 방법론의 한계를 극복하기 위해
오라클 10g부터 지원하기 시작한 세션 레벨 실시간 모니터링 기능을 ? 라고 한다.해답 : ASH 또는 Active Session History
✍️ 24번 : 대기 이벤트와 동적 성능 뷰
현재 DBMS에 발생하고 있는 장애 원인을 분석한 결과, 평소보다 I/O 관련 대기 이벤트가 높게 나타나고 있다. 좀 더 상세한 원인을 찾기 위해 사용할 동적 성능 뷰와 가장 거리가 먼 것
- v$session_wait 👉 ⭕️
- v$active_session_history 👉 ⭕️
- v$sql 👉 ⭕️
- dba_hist_active_sess_history 👉 ❌
🍒 문제 해설
- v$session wait 뷰를 통해 문제의 대기 이벤트를 가장 많이 발생시키는 세션 목록을 확인할 수 있다.
- v$active_session_history 뷰를 통해 문제의 세션들이 어떤 SQL을 수행하고 있는지 확인할 수 있다.
- v$sql 뷰를 통해 문제 SQL의 전체 문장과 수행 통계(실행횟수, 평균 소요시간, 평균 블록 I/O 등)를 확인할 수 있다.
🍋 기출 포인트
- dba_hist_active_sess_history를 통해서는 AMR로 옮겨진 오래된 과거의 세션 히스토리 정보를 확인할 수 있다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’