✍️ 32번 : 인덱스 ROWID를 이용한 테이블 액세스
인덱스 ROWID를 이용한 테이블 액세스
- 인덱스 ROWID에 포함된 데이터 블록 주소는 데이터파일 상의 블록 위치를 가리킨다. 👉 ⭕️
- 데이터 블록 주소로 버퍼 캐시에서 블록을 찾을 때 해시 알고리즘을 이용한다. 👉 ⭕️
- 버퍼 캐시에서 블록을 찾는 과정에 Latch, Buffer Lock 등에 의한 경합에 생길 수 있다. 👉 ⭕️
인덱스 ROWID를 이용한 테이블 액세스 오답
- 인덱스 ROWID는 테이블 레코드에 대한 포인터로서 물리적으로 직접 연결된 구조다. 👉 ❌
🍋 기출 포인트
- 인덱스 ROWID는 테이블 레코드를 찾아가기 위한 위치 정보일 뿐 테이블 레코드와 물리적으로 직접 연결된 구조는 아니다.
🍒 문제 해설
- 블록을 매번 데이터파일에서 읽는다면 성능은 이루 말할 수 없이 느리기에 ROWID가 가리키는 블록을 버퍼캐시에서 먼저 찾아보고 못 찾을 때만 데이터파일에서 읽는다.
- 데이터파일에서 읽을 때에는 버퍼캐시에 적재한 후에 읽는다.
- 캐시에서 블록을 읽을 때는 읽고자 하는 데이터 블록 주소를 해시 함수에 입력해서 해시 체인을 찾고 거기서 버퍼 헤더를 찾는다.
- 캐시에 적재할 때와 읽을 때 같은 해시 함수를 사용하므로 버퍼 헤더는 항상 같은 해시 체인에 연결된다.
- 반면, 실제 데이터가 담긴 버퍼 블록은 매번 다른 위치에 캐싱되는데, 그 메모리 주소값을 버퍼 헤더가 가지고 있다.
- 버퍼캐시는 시스템 공유 메모리에 위치하므로 액세스를 직렬화하기 위한 Lock 메커니즘이
작동한다.따라서 버퍼캐시에서 블록을 읽을 때마다 Latch와 Buffer Lock을 획득해야 한다. - ⭐️동시 액세스가 심할 때는 Latch와 Buffer Lock에 대한 경합까지 발생하므로 인덱스 ROWID를 이용한 테이블 액세스는 생각보다 고비용 구조다.⭐️
✍️ 33번 : 인덱스 클러스터링 팩터
인덱스 클러스터링 팩터
- 인덱스 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여 있는 정도를 의미한다. 👉 ⭕️
- 통계정보의 일종으로서 인덱스를 경유해 테이블 전체 로우를 액세스할 때 읽을 것으로 예상되는 논리적인 블록 개수를 미리 구해 놓은 값이다. 👉 ⭕️
- 인덱스 성능은 클러스터링 팩터가 테이블 블록 수에 가까울수록 좋고, 테이블 레코드 수에 가까울수록 나쁘다. 👉 ⭕️
인덱스 클러스터링 팩터 오답
- 인덱스를 재생성(Rebuild)하면 클러스터링 팩터가 좋아진다. 👉 ❌
🍋 기출 포인트
- 인덱스를 아무리 재생성해도 클러스터링 팩터는 좋아지지 않는다. 클러스터링 팩터를 좋게
하려면, 인덱스 컬럼 순으로 정렬되도록 테이블을 재생성해야 한다.
✍️ 34번 : 인덱스 손익분기점
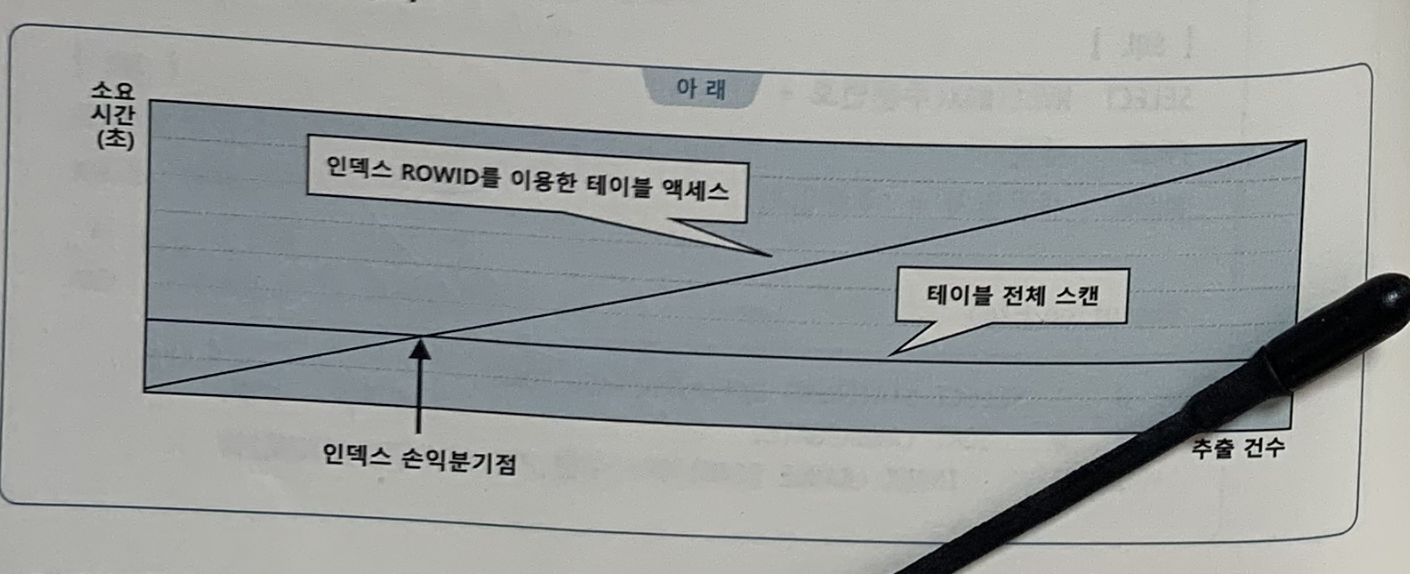
인덱스 손익분기점
- 인덱스 클러스터링 팩터가 좋을수록 손익분기점은 올라간다. 즉, 우측으로 이동한다. 👉 ⭕️
- Multiblock I/O 단위를 늘릴수록 좋을수록 손익분기점은 내려간다. 즉, 좌측으로 이동한다. 👉 ⭕️
- 일정량 이상의 데이터를 읽을 때 인덱스 효용성이 낮은 이유는 인덱스를 이용한 테이블 액세스가 랜덤 방식인 데다 Single Block I/O 방식으로 디스크 블록을 읽기 때문이다. 👉 ⭕️
인덱스 손익분기점 오답
- 데이터양이 늘수록 테이블 스캔 비용이 기하급수적으로 증가한다. 👉 ❌
🍋 기출 포인트
- 테이블 스캔 비용은 데이터양이 느는 만큼 선형적으로 증가하지만, 인덱스를 이용한 테
이블 액세스 비용은 데이터양이 늘고 추출 건수가 많아질수록 기하급수적으로 증가한다.✅ 인덱스를 통한 테이블 액세스시 추출 건수가 클수록 기하급수적으로 증가하는 이유
- 첫 번째 이유 , 데이터양이 늘수록 인덱스 CF(클러스터링 팩터)가 점점 나빠지기 때문이다.
예를 들어, 1,000건 이하인 테이블은 '값이 같은(인덱스에 나란히 정렬된)' 레코드들이 한 테이블'블록에 모여 있을 가능성이 매우 높지만, 1억 건 이상인 테이블이면 가능성이 매우 작다. - 두 번째 이유 , 버퍼캐시 히트율이 점점 낮아지기 때문이다.
버퍼캐시에 적재할 데이터가 많은데, 버퍼캐시 크기는 일정하다.
따라서 테이블이 커질수록 블록을 버퍼캐시에서 찾을 가능성은 작아진다.
- 첫 번째 이유 , 데이터양이 늘수록 인덱스 CF(클러스터링 팩터)가 점점 나빠지기 때문이다.
- 데이터양이 늘면 Full Scan 비용이 상승하므로 인덱스 손익분기점이 올라갈 것으로 생각하기 쉽지만, 오히려 그 반대이다.
- 클러스터링 팩터가 나빠지고 버퍼캐시 히트율이 낮아지면서 늘어나는 디스크 I/O Call 부하는 생각보다 크다.
🍒 문제 해설
- 인덱스 클러스터링 팩터(이하 CF)가 좋으면 테이블 액세스 과정에 발생하는 블록 I/O가
감소한다.따라서 같은 양의 데이터를 추출하더라도 CF가 나쁠 때보다 소요 시간이 줄어든다.
그래프에서 '인덱스 ROWID를 이용한 테이블 액세스'의 경사가 완만해지면서 인덱스 손익분기점이 올라간다(=그래프에서 우측으로 이동한다) - **CF가 나쁘면 '인덱스 ROWID를 이용한 테이블 액세스'의 경사가 가팔라지면서 인덱스 손익분기점은 내려간다(=그래프에서 좌측으로 이동한다).
- Multiblock I/O 단위를 늘릴수록 디스크 I/O Call 횟수가 줄고 테이블 전체 스캔 비용이낮아지므로 소요시간이 줄어든다. 따라서 인덱스 손익분기점이 내려간다(=그래프에서 좌
측으로 이동).
✍️ 35번 : 온라인 트랜잭션을 처리하는 프로그램과 배치(Batch) 프로그램의 성능 특성
온라인 트랜잭션을 처리하는 프로그램과 배치(Batch) 프로그램의 성능 특성
- 온라인 트랜잭션을 처리하는 프로그램에서는 인덱스와 NL 조인의 활용성이 높다. 👉 ⭕️
- 배치 프로그램에서는 Full Scan과 해시 조인의 활용성이 높다. 👉 ⭕️
- 배치 프로그램에서는 파티션과 병렬 처리의 효과성이 높다. 👉 ⭕️
온라인 트랜잭션을 처리하는 프로그램과 배치(Batch) 프로그램의 성능 특성 오답
- 배치 프로그램에서도 부분범위 처리를 잘 활용하면, 처리 성능을 높일 수 있다. 👉 ❌
🍋 기출 포인트
- 대량 데이터를 읽고 갱신하는 배치(Batch) 프로그램은 항상 전체범위 처리 기준으로
튜닝해야 한다. - 대량 데이터를 읽고 갱신하는 배치(Batch) 프로그램은 처리대상 집합 중 일부를 빠르게 처리하는 것이 아니라 전체를 빠르게 처리하는 것을 목표로 삼아야 한다.
- 배치(Batch) 프로그램에서 대량 데이터를 빠르게 처리하려면, 인덱스와 NL 조인보다 Full Scan과 해시 조인이 유리하다.
🍒 문제 해설
- 온라인 프로그램은 보통 소량 데이터를 읽고 갱신하므로 인덱스를 효과적으로 활용하는 것
이 무엇보다 중요하기에 조인도 대부분 NL 방식을 사용한다. - 온라인 프로그램은 인덱스를 이용해 소트 연산을 생략함으로써 부분범위 처리 방식으로 구현할 수 있다면, 온라인 환경에서 대량 데이터를 조회할 때도 아주 빠른 응답 속도를 낼 수 있다.
✍️ 36번 : 운영 리스크와 애플리케이션 영향도를 최소화 인덱스 변경
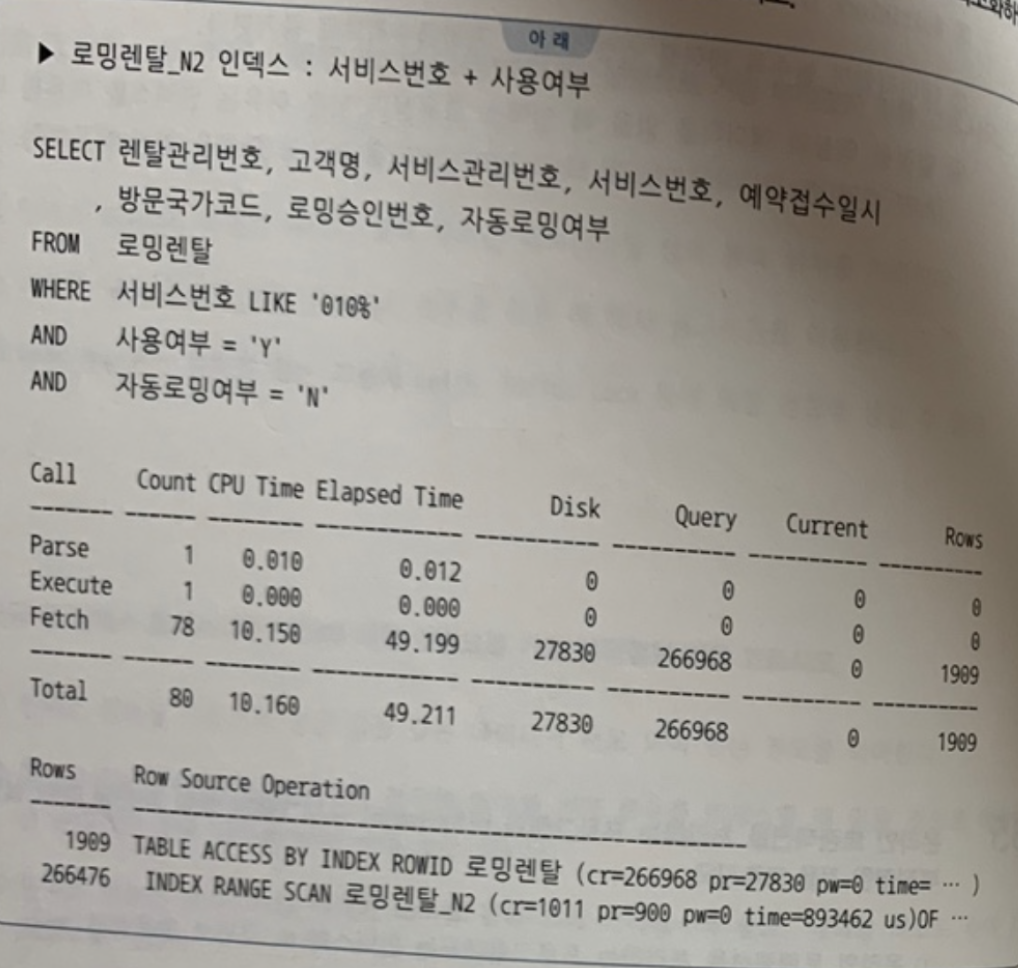
로밍렌탈_N2 인덱스 : 서비스번호 + 사용여부
SELECT 렌탈관리번호, 고객명, 서비스관리번호, 서비스번호, 예약접수일시
방문국가코드, 로밍승인번호, 자동로밍여부
FROM 로밍렌탈
WHERE 서비스번호 LIKE '010%'
AND 사용여부 = 'Y'
AND 자동로밍여부 = 'N';인덱스 구성 변경에 따른 운영 리스크와 애플리케이션 영향도를 최소화하면서도 쿼리 성능을 높이는 가장 합리적이고 현실적인 튜닝 방안
- 로밍렌탈_N2 인덱스 구성을 「서비스번호 + 사용여부 + 자동로밍여부」로 변경 👉 ⭕️
- 로밍렌탈_N2 인덱스 구성을 「사용여부 + 자동로밍여부 + 서비스번호」로 변경 👉 ❌
- 「사용여부 + 자동로밍여부 + 서비스번호」로 구성된 신규 인덱스 생성 👉 ❌
- 로밍렌탈_N2 인덱스 구성을 「사용여부 + 서비스번호」로 변경 👉 ❌
🍋 기출 포인트
- 테이블을 방문하고서 자동로밍여부 = 'N' 조건을 체크하는 과정에서 대부분 걸러진 것이다.
- 로밍렌탈_N2 인덱스에 자동로밍여부 컬럼을 추가하면 테이블 액세스는 정확히 1,909번만 발생하므로 총 블록 I/O는 인덱스 스캔 과정에 읽는 블록을 포함해 3,000여
개로 줄어들 것이다. - 따라서 성능을 크게 향상시킬 수 있는 경우가 아니면, 가급적이면 인덱스를 추가하지 않고 기존 인덱스를 활용해 성능을 높이는 방안을 우선해서 고려해야 한다.
🍒 문제 해설
- 「사용여부 + 자동로밍여부 + 서비스번호」로 변경하는 것이 쿼리 성능을 위해서는 가장 최적이지만, 선두 컬럼을 변경했으므로 로밍렌탈_N2 인덱스를 사용하던 쿼리를 모두 수집해서 성능 영향도를 검토해야만 한다.
- 로밍렌탈_N2 인덱스 구성을 「사용여부 + 서비스번호」로 변경하면 인덱스 스캔 효율은 다소 좋아지지만, 현재 가장 큰 문제인 테이블 랜덤 액세스를 줄이는 데는 전혀 도움이 되지 않는다.
- 「사용여부 + 자동로밍여부 + 서비스번호」로 구성된 신규 인덱스를 생성하는 방안도 고려해 볼 수 있으나, 인덱스 추가로 인해 DML 성능이 나빠지게 된다.
✍️ 37번 : 테이블 랜덤 액세스가 많아서 성능이 느린 경우에 고려할 방안
테이블 랜덤 액세스가 많아서 성능이 느린 경우에 고려할 방안
- 인덱스에 컬럼을 추가하는 방안을 검토한다. 👉 ⭕️
- IOT(인덱스 구조 테이블)로 변경하는 방안을 검토한다. 👉 ⭕️
- 인덱스 순으로 정렬되도록 테이블을 재생성하는 방안을 검토한다. 👉 ⭕️
테이블 랜덤 액세스가 많아서 성능이 느린 경우에 고려할 방안 오답
- 인덱스를 재생성(Rebuild)하는 방안을 검토한다. 👉 ❌
🍋 기출 포인트
- 인덱스를 재구성(Rebuild)하면 인덱스 스캔 비효율을 줄이는 데는 도움이 되지만, 테이블 액세스를 줄이는 데는 전혀 도움이 되지 않는다.
🍒 문제 해설
- 테이블 랜덤 액세스가 많을 때는 인덱스 컬럼 추가를 가장 우선해서 검토한다.
- IOT(인덱스 구조 테이블)가 테이블 랜덤 액세스를 없애는 데는 가장 효과적이다.다만,테이블 구조 변경에 따른 부담과 IOT 자체가 갖는 부작용이 적지 않으므로 운영 중에 적용하고자 할 때는 신중하게 검토해야 한다.
- 인덱스 순으로 정렬되도록 테이블을 재생성한다면, 클러스터링 팩터가 좋아져 테이블 랜덤 액세스를 줄이는 데 상당한 도움을 준다.
✍️ 38번 : 인덱스 뒤쪽에 컬럼을 추가했을 때 나타날 수 있는 현상
인덱스 뒤쪽에 컬럼을 추가했을 때 나타날 수 있는 현상
- 인덱스 높이가 증가한다. 👉 ⭕️
- 인덱스 사이즈가 증가한다. 👉 ⭕️
- 인덱스 리프 블록이 많아짐으로 인해 스캔 과정에 I/O 발생량이 증가한다. 👉 ⭕️
인덱스 뒤쪽에 컬럼을 추가했을 때 나타날 수 있는 현상 오답
- 인덱스 클러스터링 팩터가 좋아진다. 👉 ❌
🍋 기출 포인트
- 이때 뒤쪽에 컬럼을 추가하면 새로운 정렬 순서(기존컬럼 + 신규 컬럼 + ROWID)를 갖게 되므로 클러스터링 팩터가 나빠진다.
- 인덱스에 컬럼을 추가하면 인덱스 사이즈가 증가한다.
- 리프 블록 수가 증가하면 스캔 과정에 읽는 블록 I/O가 다소 증가하므로 스캔 효율이 약간 나빠진다.
- 선두 컬럼의 NDV가 많은 상황에서 컬럼을 추가하더라도 클러스터링 팩터가 좋아지지는 않는다.
🍒 문제 해설
- 값이 같은 인덱스 레코드는 ROWID 순으로 정렬하므로 선두 컬럼의 NDV가 적다면 클러스터링
팩터는 비교적 좋은 상태일 것이다.
✍️ 39번 : 실행계획이 옵티마이저에 의해 갑자기 변경될 때 나타날 수 있는 현상
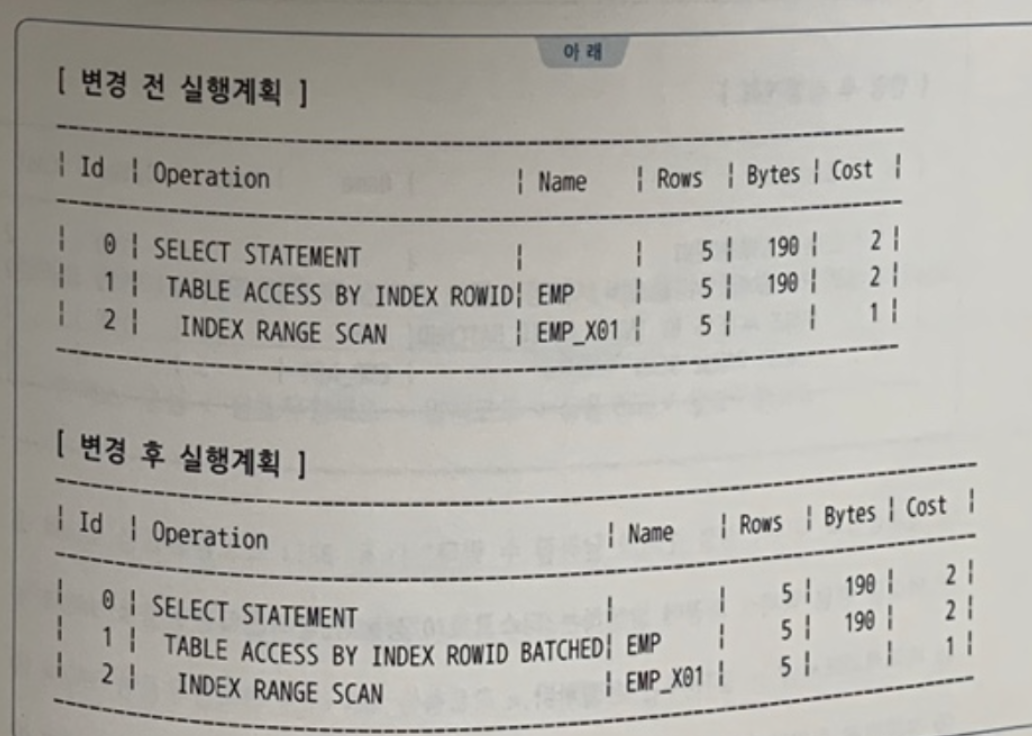
실행계획이 옵티마이저에 의해 갑자기 변경될 때 나타날 수 있는 현상
- 결과집합의 데이터 정렬 순서가 달라질 수 있다. 👉 ⭕️
- 디스크 I/O가 발생하지 않는다면 사실상 성능에는 차이가 없다. 👉 ⭕️
- 테이블 랜덤 액세스 과정에 발생하는 디스크 I/O 성능이 좋아진다. 👉 ⭕️
실행계획이 옵티마이저에 의해 갑자기 변경될 때 나타날 수 있는 현상 오답
- 부분범위 처리가 불가능해진다. 👉 ❌
🍋 기출 포인트
- 배치 I/O 기능이 작동하면 인덱스를 이용해서 출력하는 데이터 정렬 순서가 매번 다를 수
있다. - 테이블 블록을 모두 버퍼 캐시에서 찾을 때는(버퍼캐시 히트율 = 100%) 기존처럼 인덱스 키값 순으로 데이터가 출력되지만, 그렇지 않을 때(버퍼캐시*히트율 < 100%)
즉, 실제 배치 I/O가 작동할 때는 데이터 출력 순서가 인덱스 정렬 순서와 다를 수 있다. - 배치 I/O가 작동하더라도 실행계획에 'SORT ORDER BY' 오퍼레이션이 나타나지 않는 한, 부분범위 처리는 가능하다.
🍒 문제 해설
- 인덱스를 이용해 대량 데이터를 조회하면, 디스크 I/O 발생량이 증가하고 그만큼 성능이 나빠진다.
- 디스크 랜덤 1/0 성능을 높이기 위한 방안 중 하나로 오라클은 배치 I/O 기능을 활용한다.
- '실행계획'에 'BATCHED'라는 키워드가 추가되면 배치 I/O가 작동할 수 있다는 의미이다.
✅ 배치 I / O란?
- 인덱스를 이용해 테이블을 액세스하다가 버퍼 캐시에서 블록을 찾지 못하면 일반적으로 디스크 블록을 바로 읽는데,
이 기능이 작동하면 테이블 블록에 대한 디스크 I/0 Call을 미뤘다가 읽은 블록이 일정량 쌓이면 한꺼번에 처리한다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’