✍️ 41번 : 트레이스 결과 중 비효율(=결과에 비해 필요 이상의 많은 연산 수행)이 가장 적은 것

트레이스 결과 중 비효율(=결과에 비해 필요 이상의 많은 연산 수행)이 가장 적은 것
- 1 로우당 블럭 845개
- 1 로우당 블럭 392개
- 1 로우당 블럭 365개
- 1 로우당 블럭 0.3개 👉 ⭕️
🍋 기출 포인트
- 2번은 인덱스에서 얻은 결과 건수만큼 테이블을 10만 번 액세스한 후에 100개만 남았으므로 매우 비효율적이다.
✍️ 42번 : 인덱스 스캔 과정에서 비효율이 가장 큰 조건절
인덱스 구성 : 상품유형코드 + 업체코드 + 상품코드 + 할인구분코드- WHERE 상품유형코드 LIKE :a || '%'
👉 인덱스에서 상품유형코드 LIKE 조건에 일치하는 레코드만 정확히 스캔한다. - WHERE 상품유형코드 = a AND 업체코드 = :b
👉 인덱스에서 상품유형코드과 업체코드 조건에 일치하는 레코드만 정확히 스캔한다. - WHERE 상품유형코드 = :a AND 상품코드 = b AND 할인구분코드 = c
👉 인덱스에서 상품유형코드 조건에 일치하는 레코드를 모두 스캔하면서 상품코드, 할인구
분코드 조건을 필터링한다. 상품코드의 선행컬럼인 업체코드가 조건절에 없기 때문이다. - WHERE 상품유형코드 = :a AND 업체코드 = b AND 상품코드 LIKE :c | '%'
👉 '=' 조건이 아니더라도 그것이 인덱스 뒤쪽 컬럼일 때는 비효율이 없다. 따라서 ④번 조
건은 상품유형코드, 업체코드, 상품코드 조건에 일치하는 레코드만 정확히 스캔한다.
🍋 기출 포인트
- ⭐️ 핵심은
효율이라는 단어에 있다. 1번 선지는 원하는 결과의 값을 모두 필터링할 수 있기에 조건 검색중 낭비되는 데이터가 없겠지만 3번같은 경우는 선행컬럼이 중간에 비어 상품 유형 코드를 만족하는 데이터를 모두 스캔하게 되어 굳~이 스캔할 필요가 없는 데이터까지도 모두 체크해야하기 때문에비효율적이라고 판단할 수 있다. - 스캔하는 양이 많으면
비효율적, 적으면효율적이 절~대 아니다.
✍️ 43번 : 효과적인 튜닝 방안
▶ 인덱스 구성 : 할인구분코드 + 상품코드 + 업체코드 + 상품유형코드
SELECT 주문일자, 상태코드, 정상가, 할인가, 할인구분코드
FROM 상품공급
WHERE 상품유형코드 = 'A'
AND 업체코드 = '2956'
AND 상품코드 = 'A0113509056'
AND 할인구분코드 BETWEEN 'A' and 'C'
ORDER BY 주문일자 DESC효과적인 튜닝 방안
- 할인구분코드 조건절을 아래와 같이 변경한다.
AND 할인구분코드 IN ( 'A', 'B', 'C' ) 👉 ⭕️ - INDEX FAST FULL SCAN으로 유도한다. 👉 ❌
- INDEX SKIP SCAN으로 유도한다. 👉 ⭕️
- 조건절 나열 순서를 인덱스 구성에 따라 변경한다. 👉 ❌
🍋 기출 포인트
- INDEX SKIP SCAN으로 유도하면, 할인구분코드가 'A'와 'C' 사이에 속한 구간에서 나머지 상품코드, 업체코드, 상품유형코드 조건을 만족하는 데이터만 골라서 읽을 수 있다.
- 조건절 나열 순서는 SQL 성능에 영향을 주지 않는다.
🍒 문제 해설
- SQL이 인덱스에 없는 컬럼을 포함하므로 INDEX FAST FULL SCAN은 불가능할 뿐만 아니라 성능 향상에 도움이 되지도 않는다.
- 할인구분코드는 NDV가 적은 반면 상품코드는 NDV가 많으므로 INDEX SKIP SCAN이 매우 효과적인 상황이다.
- INDEX SKIP SCAN으로 유도하면, 할인구분코드가 'A'와 'C' 사이에 속한 구간에서 나머지 상품코드, 업체코드, 상품유형코드 조건을 만족하는 데이터만 골라서 읽을 수 있다.
- 지금처럼 선두 컬럼의 NDV 는 적고 후행 컬럼의 NDV는 많을 때 BETWEEN 조건의 인덱스 선두 컬럼을 IN 조건으로 변경하면 성능 향상에 큰 도움이 된다.
✍️ 44번 : 효과적인 튜닝 방안
▶ 데이터 분포
월별로 100만 개 레코드 저장
총 10년치 데이터 보관
판매구분코드가 'A'로 시작하는 데이터는 2%
▶ 인덱스 구성
월별고객별판매집계_IDX2 : 판매월 + 판매구분코드
SELECT COUNT(*)
FROM 월별고객별판매집계
WHERE 판매구분코드 LIKE 'A%'
AND 판매월 BETWEEN '202001' AND '202012'효과적인 튜닝 방안
- INDEX SKIP SCAN으로 유도한다. 👉 ⭕️
- 판매구분을 관리하는 코드 테이블을 이용해 조건절을 아래와 같이 변경한다.
WHERE 판매구분코드 IN
(SELECT 판매구분코드 FROM 판매구분 WHERE 판매구분코드 LIKE 'A8')
AND 판매월 BETWEEN '202001' AND '202012' 👉 ❌ - 판매월 BETWEEN 조건절을 IN-LIST로 변경한다. 👉 ⭕️
- 월별고객별판매집계_IDX2 인덱스를 「판매구분코드 + 판매월」 순으로 변경한다. 👉 ⭕️
🍋 기출 포인트
- 인덱스 선두 컬럼인 판매월이 BETWEEN 조건인 상황에서 판매구분코드를 IN 조건으로 처리하는 것은 성능 향상에 전혀 도움이 되지 않는다.
✍️ 45번 : Index Range Scan으로 처리되는 쿼리를 Index Skip Scan으로 유도했을 때의 성능 효과 - 일자와 일시 차이
<쿼리 1>
▶ 인덱스 : 승인요청일시 + 승인요청자ID
SELECT COUNT(*)
FROM 승인요청
WHERE 승인요청일시 >= trunc(sysdate - 6)
AND 승인요청자ID = :reqr_id ;
<쿼리 2>
▶ 인덱스 : 승인요청일자 + 승인요청자ID
SELECT COUNT(*)
FROM 승인요청
WHERE 승인요청일자 >= to_char(sysdate - 6, 'yyyymmdd')
AND 승인요청자ID = reqr_id ;Index Range Scan으로 처리되는 쿼리를 Index Skip Scan으로 유도했을 때의 성능 효과
- 쿼리2만 효과가 있다.
🍋 기출 포인트
- 쿼리 2에서 승인요청일자는 값 종류가 7개이고 매일 100만 건이 존재하는 상황이므로 각 일자 구간에서 특정 승인요청자ID의 데이터를 찾을 때는 Index Skip Scan이 큰 도움을 준다.
- 쿼리 1에서 하루는 86,400초이므로 7일간 승인요청일시로 가능한 값의 종류는 최대 684,888개다. 최대 684,800개 값 구간에 흩어진 특정 승인요청자ID의 데이터를 찾을 때
Index Skip Scan은 성능 향상에 전혀 도움이 되지 않는다.
✍️ 46번 : 가장 효과적인 인덱스
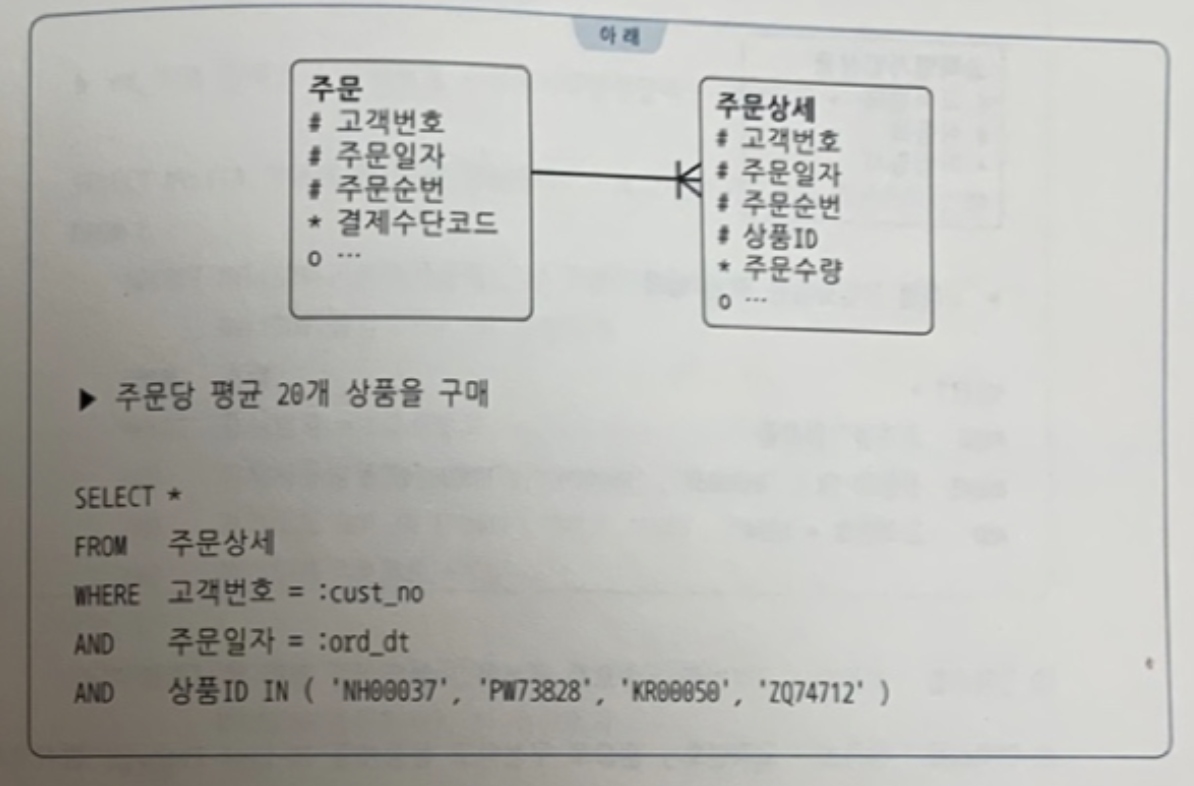
① 주문상세_PK : 고객번호 + 주문일자 + 주문순번 + 상품 ID·
② 주문상세_X1 : 상품ID + 고객번호 + 주문일자
③ 주문상세_X2 : 상품ID + 주문일자 + 고객번호
④ 주문상세_X3 : 주문일자 + 상품ID + 고객번호
주문상세 테이블에 보기와 같이 4개의 인덱스가 있을 때 아래 쿼리를 위해 가장 효과적인 인덱스를 고르기
르시오.
1. ① 주문상세_PK : 고객번호 + 주문일자 + 주문순번 + 상품 ID· 👉 ⭕️
🍋 기출 포인트
- ①번은 고객번호와 주문일자 조건을 만족하는 데이터를 스캔하면서 상품 ID 조건을 필터링한다. 한 고객이 주문당 평균 20개 상품을 구매하므로 주문상세 레코드는 20개에 불과하고,
하루에 3~5회 주문해도 60~100개에 불과하다. 인덱스 리프 블록 하나에 모두 담을 수 있는
양이므로 인덱스 높이가 3이면 3개 블록만 읽으면 된다. - 필터 조건이 꼭 액세스 조건보다 나쁜 건 아니다.액세스 조건은 수직 탐색이라는 비용이 들어가기 때문이다.
🍒 문제 해설
- 상품ID를 선두에 두면, 상품ID에 대한 IN 조건을 IN-List Iterator 방식으
로 풀어야 Index Range Scan이 가능하다. 그러면 인덱스 수직 탐색을 네 번 해야 하므로 인덱스 높이가 3이면 최소한 12개 블록을 읽어야 한다. - ④번은 상품ID에 대한 IN 조건을 IN-List Iterator 방식으로 풀면 최소 12개 블록을 읽어야한다. 상품ID IN 조건을 필터 방식으로 풀면, 인덱스에서 하루 치 주문상세를 모두 스캔하면서 상품 ID와 고객번호를 필터링해야 하므로 훨씬 많은 블록을 읽게 될 것이다.
✍️ 47번 : 가장 효과적인 튜닝 방안
고객별가입상품
# 고객번호
# 상품 ID
* 가입일시
▶ 고객별 가입상품은 평균 10개
SELECT *
FROM 고객별가입상품
WHERE 상품ID IN ( ‘NHOO837', 'NHO0041', 'NHO0050')
AND 고객번호 = 1234 ;가장 효과적인 튜닝 방안
- 인덱스를 「고객번호 + 상품ID』 순으로 구성하고 상품ID를 필터 방식으로 처리 👉 ⭕️
- 인덱스를 「고객번호 + 상풍ID』 순으로 구성하고 상품ID를 IN-List Iterator 방식으로 처리 👉 ❌
- 인덱스를 「상품ID + 고객번호」 순으로 구성하고 상품 ID를 IN-List Iterator 방식으로 처리 👉 ❌
- 인덱스를 「상품ID + 고객번호」 순으로 구성하고 상품 ID를 필터 방식으로 처리 👉 ❌
🍋 기출 포인트
- 필터 조건이 꼭 액세스 조건보다 나쁜 건 아니다.액세스 조건은 수직 탐색이라는 비용이 들어가기 때문이다.
🍒 문제 해설
- IN-List Iterator 방식으로 처리하면 인덱스 수직 탐색을 세 번 하므로 인덱스 높이가 3일 경우 최소한 9개 블록을 읽어야 한다.
- 고객당 가입상품은 평균 10개이므로 아래 그림처럼 인덱스 리프 블록 하나에 모두 담을 수 있는 양이다.
✍️ 48번 : 인덱스 추가를 통한 튜닝 & SQL 변경을 통한 튜닝

인덱스 추가를 통한 튜닝
증서번호 + 투입인출구분코드 + 이체사유발생일자(+ 거래코드)
또는
투입인출구분코드 + 증서번호 + 이체사유발생일자(+ 거래코드)
- 거래코드 NOT IN 조건을 만족하는 데이터가 적다면, 거래코드를 인덱스 뒤쪽에 추가하는
것이 좋다. 테이블 랜덤 액세스를 그만큼 많이 줄여주기 때문이다. - 거래코드 NOT IN 조건을 만족하는 데이터가 대다수라면 굳이 인덱스에 추가하지 않는 것이 좋다.
인덱스 사이즈를 줄이고, DML 성능을 좋게 하기 위해서다.
SQL 변경을 통한 튜닝
SELECT (G_기본이체금액 + G_정산이자) - (S_기본이체금액 + S_정산이자)
FROM (
SELECT NVL(SUM(CASE WHEN 투입인출구분코드 = 'G' THEN 기본이체금액 END), 0) G_기본이체금액
NVL(SUM(CASE WHEN 투입인출구분코드 = 'G' THEN 정산이자 END), 0) 6_정산이자
NVL(SUM(CASE WHEN 투입인출구분코드 = 'S' THEN 기본이체금액 END), B) S_기본이체금액
NVL(SUM(CASE WHEN 투입인출구분코드 = 'S' THEN 정산이자 END), B) S_정산이자
)
FROM 거래
WHERE 증서번호 = :증서번호
AND 이체사유발생일자 <= :일자
AND 투입인출구분코드 IN ( 'G', 'S' )
AND 거래코드 NOT IN ('7411','7412', '7503','7584')✍️ 49번 : 옵션조건을 LIKE로 처리할 때의 장단점
SELECT * FROM 거래
WHERE ID LIKE :CUST_ID || '%'
AND 거래일자 BETWEEN :DT1 AND :DT2;고객ID에 대한 옵션조건을 아래와 같이 LIKE로 처리할 때의 장단점
- 고객ID가 NULL 허용 컬럼일 때 결과집합에 오류가 발생할 수 있다. 👉 ⭕️
- 고객ID 길이가 가변적일 때 결과집합에 오류가 발생할 수 있다. 👉 ⭕️
- 고객ID가 숫자형 컬럼일 때 고객ID가 인덱스 선두 컬럼이면 Index Range Scan이 불가능하고, 거래일자가 선두 컬럼이면 인덱스 스캔 비효율이 발생한다. 👉 ⭕️
- 고객ID가 문자형 컬럼이고 고객ID가 인덱스 선두 컬럼이면 Index Range Scan이 가능하므로 해
우 효과적인 옵션조건 방식이다. 👉 ❌
🍋 기출 포인트
- 고객ID가 문자형 컬럼일 때는 인덱스를 어떻게 구성하든 Index Range Scan은 가능하다.
- 하지만 고객ID가 선두 컬럼인 인덱스를 Range Scan 하는 실행계획이 수립되었을 때 :CUST_ID 변수에 값을 입력하지 않으면 인덱스에서 '모든' 거래 데이터를 스캔하는 불상사가 생긴다.
- ⭐️ 대용량 테이블일 때 인덱스 선두 컬럼에 대한 옵션조건을 LIKE로 처리하면 안 되는 이유다.
- 차라리 거래일자가 인덱스 선두 컬럼이었다면 거래일자 BETWEEN 구간만큼만 스캔하겠지만, 이때는 반대로 :CUST_ID 변수에 값을 입력한 경우에 발생하는 스캔 비효율이 문제다.특정 고객의 거래를 조회하고 싶은데도 거래일자 BETWEEN 구간에 속한 모든 거래 데이터를 스캔하면서 고객ID 조건을 필터링하기 때문이다.
🍒 문제 해설
- 거래일자 조건을 만족하는 모든 거래를 조회하고 싶을 때 :CUST_ID 변수에 NULL을 입력하므로 조건절은 「고객ID LIKE ||'%'」가 된다. 「NULL LIKE || '%’」은 공집합이다.
따라서 고객ID가 NULL인 거래는 거래일자 조건을 만족하더라도 결과집합에서 누락된다. - 고객ID가 숫자형 컬럼이면, 자동 형변환이 일어나므로 고객ID는 무조건 필터 조건으로 사용된다. 고객ID가 인덱스 선두 컬럼이면 Index Range Scan이 불가능하고, 거래일자가 선두 컬럼이면 인덱스 스캔 비효율이 발생한다.
- 123번 고객을 찾기 위해 :CUST_ID에 123을 입력하면, 고객번호가 123으로 시작하는 모든 고객이 출력된다.
✍️ 50번 : iBatis 프레임워크에서 Static SQL로 구현하기
iBatis 프레임워크에서 고객ID에 대한 옵션 조건을 아래와 같이 Dynamic 방식으로 처리하였다. 이를 Static SQL로 구현하고자 할 때 가장 효과적인 방식 (단, 고객ID는 NOT NULL 컬럼임)
<select id="..." parameterClass="..." resultClass="...." >
SELECT * FROM 거래
WHERE 거래일자 BETWEEN #DT1# AND #DT2#
<isNotEmpty prepend="AND" property="cust_id">
고객ID = #CUST_ID#
</isNotEmpty>
</select>- ⭕️
SELECT * FROM 거래 WHERE 고객ID = NVL(#CUST_ID#, 고객ID) AND 거래일자 BETWEEN #DT1# AND #DT2# - ❌
SELECT * FROM 거래 WHERE (#CUST_ID# IS NULL OR 고객ID = #CUST_ID#) AND 거래일자 BETWEEN #OT1# AND #DT2# - ❌
SELECT * FROM 거래 WHERE 고객ID LIKE #CUST_ID# || '%' AND 거래일자 BETWEEN #OT1# AND #DT2# - ❌
SELECT * FROM 거래 WHERE 고객ID = (CASE WHEN #CUST_ID# IS NULL THEN 고객ID ELSE #CUST_ID# END) AND 거래일자 BETWEEN #DT1# AND #DT2
🍋 기출 포인트
- 옵션조건에 NVL이나 DECODE 함수를 사용하면 아래와 같은 UNION ALL 형태로 쿼리변환이 작동하므로 고객ID처럼 변별력이 좋은 컬럼에 매우 효과적으로 사용할 수 있다.
SELECT * FROM 거래 WHERE :CUST_ID IS NULL AND 거래일자 BETWEEN :DT1 AND :DT2 UNION ALL SELECT * FROM 거래 WHERE :CUST_ID IS NOT NULL AND 고객ID = CUST_ID
🍒 문제 해설
- OR 방식을 사용하면 고객ID가 인덱스 선두 컬럼이어도 Index Range Scan 할 수 없다.
- LIKE 조건으로 구현한 옵션조건에 고객ID가 선두 컬럼인 인덱스를 Range Scan 하는 실행 계획이 수립되면, #CUST_ID 변수에 값을 입력하지 않았을 때 인덱스에서 '모든' 거래 데이터를 스캔하는 불상사가 생긴다.
- 옵션조건에 CASE 문을 사용하면 UNION ALL 형태로 쿼리변환이 일어나지 않는다.\
✍️ 51번 : 인덱스를 설계할 때 고려하는 판단 기준
인덱스를 설계할 때 고려하는 판단 기준
- SQL 수행 빈도 👉 ⭕️
- SQL의 업무상 중요도 👉 ⭕️
- 데이터양과 DML 발생 빈도 👉 ⭕️
인덱스를 설계할 때 고려하는 판단 기준 오답
- SQL 조건절 순서 👉 ❌
🍋 기출 포인트
- 조건절 나열 순서는 SQL 성능과 무관하다.
🍒 문제 해설
- SQL 수행 빈도는 인덱스를 생성하는 매우 중요한 판단 기준이다.
- 수행 빈도가 낮더라도 업무상 중요한 SQL이라면 인덱스 생성을 고려할 수 있다.
- 데이터양이 많고 DML 발생 빈도가 높은 테이블에는 인덱스를 가급적 최소화해야 한다.
✍️ 52번 : 가장 효과적인 인덱스 구성
SELECT 이름, 성별, 전화번호, 부서
FROM 사원
WHERE 성별 = '남자'
AND 이름 = '홍길동' ;가장 효과적인 인덱스 구성
- 성별과 이름 두 컬럼으로 구성하되, 어떤 컬럼을 앞쪽에 두든 성능은 똑같다. 👉 ⭕️
🍋 기출 포인트
- 두 조건절의 연산자가 모두 '=' 이므로 어떤 컬럼이 선두이든 성능은 똑같다.
✅ 결합 인덱스 구성을 위한 두 가지 선택 기준
Index Range Scan이 가능하려면 인덱스 선두 컬럼을 조건절에 반드시 사용해야 한다.
따라서 결합 인덱스를 구성할 때 첫 번째 기준은, 조건절에 항상 사용하거나, 자주 사용하는 컬
럼을 선정하는 것이다.
두 번째 기준은, 그렇게 선정한 컬럼 중 '=' 조건으로 자주 조회하는 컬럼을 앞쪽에 두어야
한다는 것이다.

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’