✍️ 26번 : 쿼리 변환
쿼리 변환에 대한 설명으로 가장 부적절한 것을 고르시오.
- 옵티마이저 내장 엔진 중 Query Transformer가 담당한다. 👉 ⭕️
- 옵티마이저가 다양한 쿼리 변환을 시도할수록 SQL 최적화 시간은 늘어난다. 👉 ⭕️
- SQL문에 쿼리 변환과 관련한 힌트를 지정하면, 옵티마이저는 그것을 우선해서 적용한다. 👉 ⭕️
- 결과만 보장된다면 옵티마이저는 무조건 쿼리를 변환하고, 변환한 쿼리를 기준으로 가능한 후보군 실행계획 중 하나를 선택한다. 👉 ❌
🍋 기출 포인트
- 쿼리를 변환했을 때 항상 더 나은 성능을 보장하는 일부 경우를 제외하고는 대부분 비용기반 쿼리 변환으로 동작한다. 따라서 '변환 전 쿼리'에 대한 후보군 실행계획과 '변환 후 쿼
리'에 대한 후보군 실행계획을 비교해서 그중 가장 비용이 낮은 것을 선택한다.
✅ 쿼리 변환(Query Transformation)
- 옵티마이저가 SQL을 분석해 의미적으로 동일(→ 같은 결과집합을 생성)하면서도 더 나은 성능이 기대되는 형태로 재작성하는 것을 말한다.
- 휴리스티(Heuristic) 쿼리 변환 : 결과만 보장된다면 무조건 쿼리 변환 수행하는 것
- 비용기반(Cost-based) 쿼리 변환 : 예상 비용(Cost)이 낮을 때만 변환된 쿼리를 사용하는 것
✍️ 27번 : 서브쿼리 Unnesting
SQL의 수행방식에 대한 설명으로 가장 부적절한 것을 고르시오.
select c.고객번호, c. 고객명
from 고객 c
where c. 가입일시 > trunc(add_months(sysdate, -1), 'm㎜')
and exists (
select 'x'
from 거래
where 고객번호 = c. 고객번호
and 거래일시 = trunc(sysdate, 'm㎜')
);- 고객과 거래 테이블을 조인하면 결과집합이 거래 단위로 변하므로 서브쿼리를 Unnesting 할 수 없다. 👉 ❌
- 서브쿼리를 Unnesting 하지 않으면, 고객을 기준으로 거래 테이블과 NL 방식으로 조인한다. 👉 ⭕️
- 서브쿼리를 Unnesting 하지 않으면, 서브쿼리에 대한 캐싱 기능이 작동한다. 👉 ⭕️
- 서브쿼리를 Unnesting 하지 않으면, 메인 쿼리와 서브쿼리를 각각 최적화한다. 👉 ⭕️
🍋 기출 포인트
- 내부적으로 서브쿼리 캐싱 기능을 적용하므로 서브쿼리에서 리턴할 수 있는 값의 종류 수가 적을 때는 성능이 크게 나쁘지 않을 수 있다.
- 서브쿼리를 Unnesting 하면 고객을 먼저 드라이빙할 수도 있고, 거래를 먼저 드라이빙할 수도 있다.
- 고객을 먼저 드라이빙하는 경우 결과집합이 M 집합인 거래 단위로 변하지 않도록 세미(Semi) 조인 방식을 사용한다.
- 거래를 먼저 드라이빙하는 경우 SORT UNIQUE 연산을 통해 고객 단위의 Unique 한 집합을 생성한 후 고객 테이블과 조인한다.
🍒 문제 해설
- 서브쿼리에는 인라인 뷰, 중첩된 서브쿼리, 스칼라 서브쿼리가 있다.
- 옵티마이저는 쿼리 블록 단위로 최적화를 수행하므로 서브쿼리를 그대로 두면 최적화를 위해 선택할 수 있는 대안이 줄어든다.
- 중첩된 서브쿼리를 Unnesting 하지 않으면 메인 쿼리를 기준으로 서브쿼리를 반복 실행하는 필터 방식으로 처리할 수밖에 없다. 이는 NL 조인과 같은 방식이므로 대용량 데이터를 처리할 때 매우 불리하다.
- 하지만 내부적으로 서브쿼리 캐싱 기능을 적용하므로 서브쿼리에서 리턴할 수 있는 값의 종류 수가 적을 때는 성능이 크게 나쁘지 않을 수 있다.
- 내부적으로 서브쿼리 캐싱 기능을 적용하므로 서브쿼리에서 리턴할 수 있는 값의 종류 수가 적을 때는 성능이 크게 나쁘지 않을 수 있다.
✍️ 28번 : 서브쿼리 Unnesting
아래 SQL에 대한 실행계획으로 부적절한 것을 고르시오.
select c.고객번호, c.고객명
from 고객 c
where c. 가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and exists (
select 'x'
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(sysdate, ‘mm')
)- ⭕️
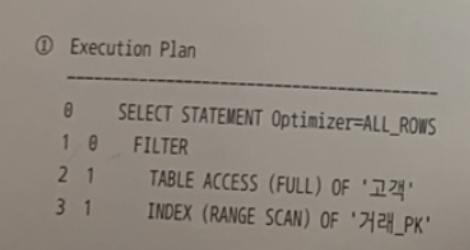
- 서브쿼리를 Unnesting 하지 않았을 때의 실행계획이다.
- ❌

- 서브쿼리를 Unnesting 하지 않으면, ②번처럼 거래를 먼저 드라이빙할 수 없다.
- 항상 메인 쿼리의 고객을 기준으로 서브쿼리의 거래 테이블과 NL 방식으로 조인한다.
- ⭕️
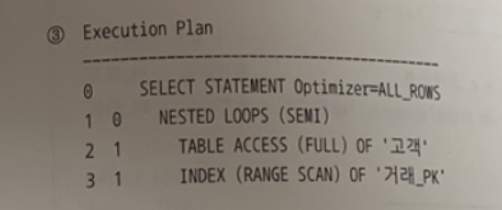
- 서브쿼리를 Unnesting 한 후 고객을 기준으로 거래 테이블과 NL 세미조인할 때의 실행계획이다.
- ⭕️

- 서브쿼리를 Unnesting 한 후 고객 단위 집합으로 가공한 거래 데이터를 기준으로 고객 테이블과 조인할 때의 실행계획이다.
✍️ 29번 : 서브쿼리 Unnesting 힌트
아래 실행계획이 나오도록 하고자 할 때 빈칸에 입력할 옵티마이저 힌트를 적으시오.
select c.고객번호, c.고객명
from 고객 C
where c. 가입일시 = trunc(add_months(sysdate, -1), 'mm')
and exists (
select /*+ (ㄱ) */
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(sysdate, 'mm')
) ; 
답 : NO_UNNEST
🍋 기출 포인트
- 서브쿼리를 Unnesting 하지 않았을 때 나타나는 실행계획이다.
- 캐싱 기능을 이용하기 위해 항상 이 방식으로 실행하도록 강제하려면 no_unnest 힌트를 사용하면 된다.
🍒 문제 해설
- 필터는 기본적으로 NL 조인과 같은 방식이다. 따라서 대용량 데이터를 처리할 때 매우 불리하다.
- 다만, 내부적으로 서브쿼리 캐싱 기능을 적용하므로 서브쿼리에 입력할 수 있는 값의 종류 수가 적을 때는 성능이 크게 나쁘지 않을 수 있다.
✍️ 30번 :
아래 실행계획이 나오도록 하고자 할 때 빈칸에 입력할 옵티마이저 힌트를 적으시오.
select c.고객번호, c.고객명
from 고객 C
where c. 가입일시 > trunc(add_months(sysdate, -1), 'm㎜')
and exists (
select /*+ (ㄱ) */
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(sysdate, 'mm')
)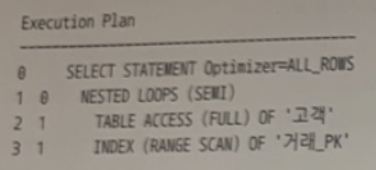
답 : UNNEST NL_SJ
🍋 기출 포인트
- 실행계획을 이 방식으로 유도하려면, 우선 서브쿼리가 Unnesting 되지 않도록 unest 힌트를 사용해야 한다. 그리고 NL 세미 조인으로 유도하는 ni_sj 힌트를 사용하면 된다.
🍒 문제 해설
- 서브쿼리를 Unnesting 했을 때 나타날 수 있는 여러 실행계획 중 하나다.
- Unnesting 하면 NL 조인뿐 아니라 해시 조인, 소트 머지 조인으로도 처리할 수 있다.
✍️ 31번 : 서브쿼리 Unnesting 힌트
아래 실행계획이 나오도록 하고자 할 때 빈칸에 입력할 옵티마이저 힌트를 적으시오.
select /*+ (ㄱ) */ c.고객번호, c.고객명
from 고객 C
where c. 가입일시 > trunc(add_months(sysdate, -1), 'm㎜')
and exists (
select /*+ qb_name(subq) */ 'x'
from 거래
where 고객번호 = c.고객번호
and 거래일시 >= trunc(sysdate, 'm㎜')
)
답 : UNNEST(@subq) LEADING(거래@subq) use_nl(c)
🍋 기출 포인트
- 실행계획을 이 방식으로 유도하려면, 우선 서브쿼리가 Unnesting 되도록 unnest 힌트를 사용해야 한다.
그리고 거래 테이블이 드라이빙 되도록 leading 힌트를 추가하고, NL 조인으로 유도하는 use_nl 힌트를 추가하면 된다.
🍒 문제 해설
- unnest 힌트의 대상 서브쿼리 블록을 명시하고, 서브쿼리 내에 위치한 거래 테이블을 leading 힌트에서 명확히 참조하기 위해 사용하였다.
✍️ 34번 : 인라인 뷰 Merging과 부분범위처리
SQL의 수행방식에 대한 설명으로 가장 부적절한 것을 고르시오.
🥺 아무 생각없이 풀면 반드시 틀리는 문제...
select c.고객번호, c.고객명, t․평균거래, t. 최소거래, t.최대거래
from 고객 C
,(select 고객번호
avg(거래금액) 평균거래, min(거래금액) 최소거래, max(거래금액) 최대거래
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
group by 고객번호) t
where c. 가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and t.고객번호 = c.고객번호 ; - 인라인 뷰를 Merging 하지 않으면, 메인 쿼리와 인라인 뷰를 각각 최적화한다. 👉 ⭕️
- 인라인 뷰를 Merging 하지 않은 상태에서 인라인 뷰 집합을 기준으로 고객과 NL 조인하는 방식은 (고객별 거래량이 많거나 가입일시 조건을 만족하는 데이터가 많을 때보다) 고객별 거래량이 적고 가입일시 조건을 만족하는 데이터가 적을수록 유리하다. 👉 ❌
- 인라인 뷰를 Merging 하지 않은 상태에서 고객을 기준으로 인라인 뷰 집합과 NL 조인할 때,최신 오라클 옵티마이저는 부분범위 처리 가능한 방식으로 처리하기도 한다. 👉 ⭕️
- 인라인 뷰를 Merging 하면 부분범위 처리가 불가능하다. 👉 ⭕️
🍋 기출 포인트
- 부분범위 처리를 이용해서 빠른 응답 속도를 내고 싶다면, ⭐️ 뷰를 Merging 하지 않은 상태에서 고객을 기준으로 인라인 뷰 집합과 NL 방식으로 조인 ⭐️하면 된다.
- 그러면 '전월 이후 가입한 고객'만을 대상으로 고객번호를 건건이 뷰 안으로 밀어 넣으면서 각 고객별 당월 거래 데이터만 읽어서 Group By 결과를 출력할 수 있다.
- 이 기능을 '조인 조건 Pushdown'이라고한다.이 기능은 NL 조인을 수행하는 도중에 멈출 수 있다는 데 있다. 즉, 부분범위 처리가 가능하다.
🍒 문제 해설
✅ 뷰 Merging과 push_pred 조인조건
- 최적화 단위가 쿼리 블록이므로 옵티마이저가 뷰(View) 쿼리를 변환하지 않으면 뷰 쿼리 블
록을 독립적으로 최적화한다. 만약 이 쿼리에서 뷰를 독립적으로 최적화하려면 당월
거래 전체를 읽어 고객번호 수준으로 Group By 한 후 고객 테이블과 조인해야 한다.- 문제는, 고객 테이블에서 '전월 이후 가입한 고객'을 필터링하는 조건이 인라인 뷰 바깥에
있다는 사실이다. 이 조건을 만족하는 데이터가 대다수라면 상관 없지만, 대개는 극소수일
것이며 이 때 인라인 뷰 안에서 당월에 거래한 '모든' 고객의 거래 데이터를 읽어야 하
므로 비효율적이다.- 따라서 그럴 때 뷰를 Merging 해서 고객을 기준으로 거래와 조인한 후에 Group By 한다면 '전월 이후 가입한 고객'이 당월에 일으킨 거래 데이터만 읽을 수 있어 효과적이다.
⭐️ 단, 이 경우 부분범위 처리는 불가능하다. ⭐️ Group By 이후에 데이터를 출력해야 하기 때문이다.
✍️ 35번 : ⭐️ 34번과 같은 맥락 !! push_pred 헷갈림
아래 SQL에 대한 실행계획으로 가장 부적절한 것을 고르시오.
[인덱스 구성 ]
고객 PK : 고객번호
고객 X1 : 가입일시
거래_PK : 거래번호
거래_X1 : 거래일시
거래_X2 : 고객번호 + 거래일시
select c.고객번호, c.고객명, t, 평균거래, t,최소거래, t,최대거래
from
고객 c
(select 고객번호 , avg(거래금액) 평균거래, min(거래금액) 최소거래, max(거래금액) 최대거래
from 거래
where 거래일시 = trunc(sysdate, 'm')
group by 고객번호) t
where c. 가입일시 >= trunc(add_months(sysdate, -1), 'mm')
and t.고객번호 = c.고객번호 ; - ⭕️
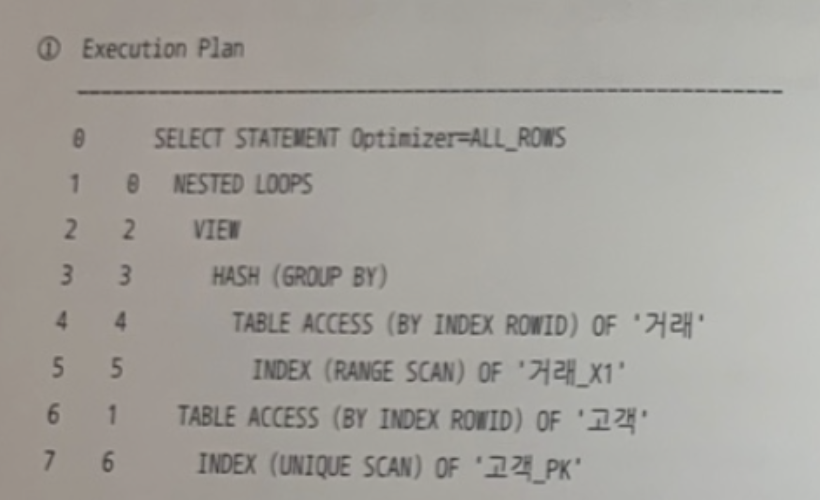
- no_merge(VIEW가 있으므로) ★ 거래 테이블에서 거래_X1을 통해 고객번호별로 집계한 후 > 고객 테이블과 NL조인한다. 👉 가능
- ⭕️

- 해당 실행계획은 ★ no_merge push_pred 처리된 것 ★
- 뷰를 머징하지 않은 상태(no_merge)에서 NL조인한다면 거래_X2(고객번호+거래일시)의 '고객번호'를 따로 조건절로 사용할 수 없다.
- 고객 테이블에서 고객_X1(가입일시)을 통해 조회 후 > 거래 테이블의 거래_X2(고객번호+거래일시)와 NL조인한다. 👉 ⭐️ 불가능 ⭐️
- 실행 계획에
VIEW PUSHED PREDICATE가 나와야한다.
- 실행 계획에
- ❌

- merge ★ 고객 테이블 조회 후 build input으로 놓은 뒤 거래 테이블과 해시조인한 후 그룹핑한다.
- ⭕️

- 해당 실행계획은 ★ no_merge push_pred 처리된 것 ★
- 고객 테이블을 고객_X1(가입 일자)를 통해 조회한 후 > 거래 테이블의 거래_X2(고객번호+거래일시)와 NL조인한다.
- 실행 계획에
VIEW PUSHED PREDICATE가 나와야한다.
- 실행 계획에
🍋 기출 포인트
- 뷰를 머징하지 않은 상태(no_merge)에서 NL조인한다면 바깥 조건절을 따로 사용할 수 없다.ㅍ
- no_merge 되었다면 테이블 액세스 후 view 오퍼레이션이 있어야 한다.
- merge는 쿼리블록을 풀어 합치는 것이다.(따라서 실행계획에 VIEW가 없다.)
✍️ 36번 : 뷰 no_merge 실행계획
아래 실행계획이 나오도록 하고자 할 때 빈칸에 입력할 옵티마이저 힌트를 정확히 모두 적으시오.
select /*+ ? */ c. 고객번호, c.고객명, t. 평균거래, t.최소거래, t.최대거래
고객 C,(
select 고객번호 , avg(거래금액) 평균거래, min(거래금액) 최소거래, max(거래금액) 최대거래
from 거래
where 거래일시 >= trunc(sysdate, 'mm')
group by 고객번호)t
where c. 가입일시 >= trunc(add_months(sysdate, -1), 'm㎜')
and t. 고객번호 = c.고객번호;
[정리]
- 거래 테이블을 거래_X1을 통해 조회한 뒤 고객번호로 그룹핑한다. > 고객번호로 고객 테이블을 하나씩 NL 조인한다.
답 : LEADING(t) NO_MERGE(t) USE_NL(c)
🍋 기출 포인트
- NL조인과 VIEW가 보인다면 NO_MERGE 형태의 서브쿼리가 있을 가능성이 농후 !
🍒 문제 해설
- 실행계획에 'VIEW' 오퍼레이션이 나타난다는 것은 Merging 하지 않았다는 뜻이다.
✍️ 37번 :
아래 실행계획이 나오도록 하고자 할 때 빈칸에 입력할 옵티마이저 힌트를 정확히 모두 적으시오.
select /*+ ? */ c. 고객번호, c.고객명, t, 평균거래, t.최소거래, t.최대거래
from 고객 c
,(select 고객번호
,avg(거래금액) 평균거래, min(거래금액) 최소거래, max(거래금액) 최대거래
from 거래
where 거래일시 >= trunc(sysdate, 'm㎜')
group by 고객번호) t
where c. 가입일시 >= trunc(add_months(sysdate, -1), '㎜')
and t. 고객번호 = c.고객번호
[정리]
- VIEW가 없으니 MERGE된 것이다.
- 두 테이블이 NL조인되어 완전히 합쳐지고 그 후에 그룹핑되었다.
답 : **MERGE(t) LEADING(c) USE_NL(t) 또는 MERGE(t) LEADING(c) USE_NL(t.거래)
🍋 기출 포인트
- SQL에 뷰를 사용했는데 실행계획에 'VIEW' 오퍼레이션이 나타나지 않은 것은 뷰를 Merging
했다는 뜻이다.
🍒 문제 해설
- push_pred를 쓰지 않는 이상 쿼리 변환이 안되는건가??
- 뷰를 Merging 해서 고객을 기준으로 거래와 조인한 후에 Group By 하는 실행계획이다.
- 이 방식으로 조인하면 전월 이후 가입한 고객'이 당월에 일으킨 거래 데이터만 읽을 수 있어
효과적이다. - no_merge 방식으로 조인하게 된다면 밖에 있는 조건절이 서브쿼리에 적용되지 못하므로 모든 고객의 거래 데이터를 읽어야 한다.
- 단, 이 경우 부분범위 처리는 불가능하다. Group By 이후에 데이터를 출력해야하기 때문이다.
✍️ 38번 :
아래 실행계획이 나오도록 하고자 할 때 빈칸에 입력할 옵티마이저 힌트를 정확히 모두 적으시오.
select /*+ ? */ c. 고객번호, c.고객명, t, 평균거래, t.최소거래, t.최대거래
from 고객 c
,(select 고객번호
,avg(거래금액) 평균거래, min(거래금액) 최소거래, max(거래금액) 최대거래
from 거래
where 거래일시 >= trunc(sysdate, 'm㎜')
group by 고객번호) t
where c. 가입일시 >= trunc(add_months(sysdate, -1), '㎜')
and t. 고객번호 = c.고객번호
[정리]
- VIEW가 있으므로 NO_MERGE 처리된 서브쿼리가 있다.
- 바깥의 조건절이 서브쿼리에 적용되었다.
- 고객_X1을 먼저 조회하였다.(가입일시)
- 고객_X1에서 거래_X2로 NL 조인을 건건이 수행하였다.(고객번호 + 거래일시)
[답]
NO_MERGE(t) PUSH_PRED(t) LEADING(c) USE_NL(t) INDEX(고객 고객_X1)
INDEX(t.거래 거래_X2)
✍️ 40번 : 뷰 merge
아래 실행계획을 보고 어떤 쿼리 변환이 작동했는지 선택하시오.
[인덱스 구성 ]
주문_PK : 주문번호
주문_X1 : 주문일자
주문_X2 : 고객번호 + 주문일자
SELECT 고객번호, 주문금액
FROM (SELECT 고객번호, SUM(주문금액) 주문금액
FROM 주문
WHERE 주문일자 BETWEEN :DT1 AND :DT2
GROUP BY 고객번호)
WHERE 고객번호 = :CUST_NO
Execution Plan
답 : 뷰 merging
🍋 기출 포인트
- 인라인뷰 사용에 VIEW가 없으므로 MERGE 된 것이다.
- 뷰 머징이 작동되면 조건절 pushdown은 일어나지 않는다.
✍️ 41번 : 조건절 pushdown
아래 실행계획을 보고 어떤 쿼리 변환이 작동했는지 선택하시오.
[인덱스 구성 ]
주문_PK : 주문번호
주문_X1 : 주문일자
주문_X2 : 고객번호 + 주문일자
SELECT 고객번호, 주문금액
FROM (SELECT 고객번호, SUM(주문금액) 주문금액
FROM 주문
WHERE 주문일자 BETWEEN :DT1 AND :DT2
GROUP BY 고객번호)
WHERE 고객번호 = :CUST_NO
Execution Plan
[풀이]
- 인라인 뷰에 VIEW가 있다. 👉 NO_MERGE
- 주문 테이블을 조회하는데 주문_X2(고객번호 +주문일자) 인덱스가 사용되었다.
- 심지어 그룹핑하는데에 SORT 연산이 쓰이지 않았다 👉 선두컬럼으로 '고객번호'를 사용했다.
- 바깥의 조건절을 사용했으므로 조건절 push_down이 일어났다.
[답] 조건절 Pushdown
🍋 기출 포인트
- 인라인 뷰를 사용했는데 실행계획에 View가 나타나면 뷰 Merging이 작동하지 않은 것이다.
- 인라인 뷰 조건절은 주문일자이므로 주문_X1 인덱스가 사용됐어야 하는데 주문_X2 인덱스가 사용된 이유는 '조건절 Pushdown' 쿼리 변환이 작동했기 때문이다. 즉, 바깥 쪽 고객번호 조건절을 인라인 뷰 안쪽으로 밀어 넣은 것이다.
✍️ 42번 : 조건절 Transitive
아래 실행계획을 보고 어떤 쿼리 변환이 작동했는지 선택하시오.
[인덱스 구성 ]
고객_PK : 고객번호
주문_PK : 주문번호
주문_X1 : 고객번호 + 주문일자
주문_X2 : 주문일자
SELECT *
FROM 고객 C, 주문 O
WHERE C.고객번호 = 1234
AND O.고객번호 = C.고객번호
AND O.주문일자 BETWEEN :ORD_DT1 AND :ORD_DT2;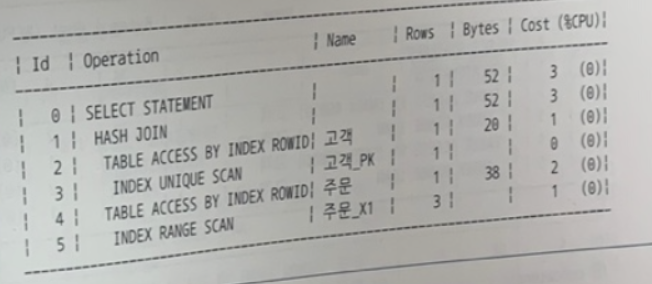
[나의 풀이]
- 고객이 해시조인의 build input이 되었고 조회에는 고객_PK가 사용되었다.(고객번호)
- 주문 테이블 조회시 주문_X1(고객번호+주문일자)이 사용되었는데 선두컬럼으로 고객번호가 사용된 것으로 보아 ....뭐지???? 고객 테이블에서 주문 테이블로 '고객번호'로 찌르는 형국이다. C의 조건절을 같이 나눠쓰는 기능이 따로 있나보다.
- 맞았다!
🍒 문제 해설
✅ 조건절 이행 (Transitive Predicate Generation, Transitive Closure)
- 「(A = B)이고 (B = C)이면 (A = C)이다」는 추론을 통해 새로운 조건절을 내부적으로 생성해 주는 쿼리 변환이다.
- A 테이블에 사용된 필터 조건이 조인 조건절을 타고 반대편 B 테이블에 대한 필터 조건으로 이행될 수 있다. 한 테이블 내에서 두 컬럼간 관계정보를 이용해 조건절이 이행되기도 한다.
답 : 조건절 Transitive
✍️ 43번 :
아래 실행계획이 나타나도록 유도하는 힌트를 고르시오.
[인덱스 구성 ]
고객_PK : 고객번호
고객_X1 : 주민번호
고객_X2 : 전화번호
고객_X3 : 고객명
SELECT *
FROM 고객
WHERE 주민번호 LIKE :REG_NO || '%'
AND (고객명 = :CUST_NM OR 전화번호 LIKE :PHONO_NO || '%') ;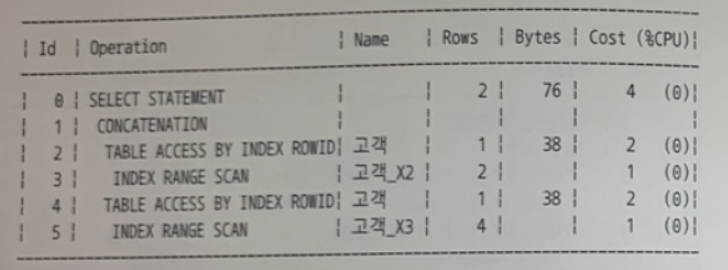
[나의 풀이]
[사용 인덱스]
고객_X2 : 전화번호
고객_X3 : 고객명
SELECT *
FROM 고객
WHERE 주민번호 LIKE :REG_NO || '%'
AND 전화번호 LIKE :PHONO_NO || '%'
UNION
SELECT *
FROM 고객
WHERE 주민번호 LIKE :REG_NO || '%'
AND 고객명 = :CUST_NM
;- 다음과 같이 사용되면서 인덱스 2개가 같이 사용된 모양이다.
- 다만 두 쿼리는 결과 집합이 겹칠 수 있다. => 그럼에도 불구하고 CONATENATION이 실행계획에 뜰 수 있는건가 ??
- 어쨌든 UNION 처리가 되었기 때문에 쿼리 블록이 나눠져 인덱스를 2개 사용할 수 있게 되었다고 생각했다. 그래서 내 생각은 USE_CONCAT 힌트를 쓰지 않았을까?함 ㅇㅇ
🍒 문제 해설
- ‘CONCATENATION' 오퍼레이션을 통해 OR Expansion이 작동한 사실을 알 수 있다.
- OR 조건을 이 방식으로 실행하도록 유도하고자 할 때 use_concat 힌트를 사용한다.
- 이 기능을 방지하기 위해서는 no_expand 힌트를 사용한다.
- OR Expansion은 OR 조건을 분해해서 UNION ALL 형태로 변환해 주는 기능이다.
=> 겹치는 게 있어도 되나보다 !
✍️ 44번 : NVL 또는 DECODE 함수에서의 OR Expansion
아래 두 가지 실행계획이 나타나도록 유도하는 힌트를 순서대로 적으시오. (쿼리 변환 관련 힌트만 적을 것)
[인덱스 구성 ]
고객_PK : 고객번호
고객_X1 : 주민번호
고객_X2 : 고객명
[SQL]
SELECT *
FROM 고객
WHERE 주민번호 LIKE :REG_NO ! '%'
AND 고객명 = NVL(:CUST_NM, 고객명);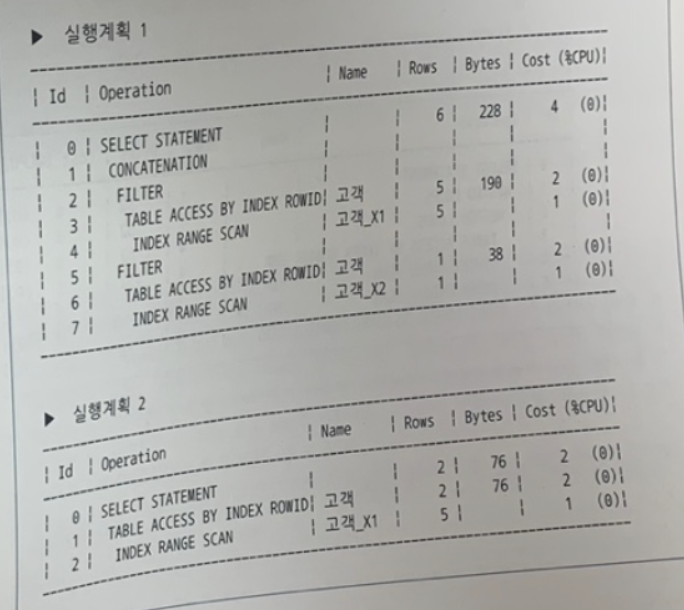
[나의 풀이]
1. 첫 번째 실행계획
- AND 조건절을 분해해서 고객 테이블을 고객_X1(주민번호)를 통해 조회하고 고객_X2(고객명)을 통해 조회했다.
- CONCATENATION을 통해 OR EXPAND가 된 것을 알 수 있다.
- 꼭 OR 조건이 아니더라도 USE_CONCAT을 쓸 수 있나??
- 아 ~ NVL 조건에 따라 나눠진 것이다.그럼 아래와 같이 되겠다.
SELECT * FROM 고객 WHERE 주민번호 LIKE :REG_NO ! '%' AND :CUST_NM IS NOT NULL AND 고객명 = :CUST_NM UNION ALL SELECT * FROM 고객 WHERE 주민번호 LIKE :REG_NO ! '%';
- 아 ~ NVL 조건에 따라 나눠진 것이다.그럼 아래와 같이 되겠다.
- 어쨌뜬 or expand가 실행됐으므로 내가 생각한 해답은 use_concat이다.
2. 두 번째 실행계획
- 고객 테이블을 고객_X1(주민번호)를 통해 수직으로 액세스하고 나머지 조건절인 고객명은 수평 액세스로 하여금 필터링을 거친다.
- 위와같이 OR EXPAND가 쓰이지 않았다.
- 내가 생각한 해답은 NO_EXPAND 이다.
🍋 기출 포인트
- NVL 또는 DECODE 함수에 대해서도 OR Expansion 기능이 작동한다.
🍒 문제 해설
- NVL 또는 DECODE 함수에 대해서도 OR Expansion 기능이 작동한다.
관련 히든 파라미터는 '_or_expand_nvl_predicate' 이며, 기본 설정은 TRUE다. - 하지만 Coalesce 함수나 CASE 문을 사용하면 OR Expansion이 작동하지 않는다.
✅ COALESCE 함수
- COALESCE(exp1, exp2, exp3, exp4 ...) 의 모양으로 사용한다.
- 널이 아닌 첫번째 값을 리턴한다.
✍️ 45번 :
쿼리 변환 기능이 약한 DBMS 버전을 사용한다고 가정하고, 아래와 같은 오라클 실행계획이 나타나도록 SQL을 변환하시오.
[인덱스 구성 ]
DEPT_PK: DEPTNO
DEPT_X1 : LOC
EMP_PK : EMPNO
EMP_X1: JOB + DEPTNO
EMP_X2: MGR + JOB
[SQL]
SELECT *
FROM EMP E, DEPT D
WHERE (E.DEPTNO = D. DEPTNO AND E.JOB = 'CLERK' AND D. LOC = 'DALLAS')
OR
(E.DEPTNO = D.DEPTNO AND E.JOB = 'CLERK' AND E. MGR = 7782)
SELECT *
FROM EMP E, DEPT D
WHERE E.DEPTNO = D. DEPTNO
AND E.JOB = 'CLERK'
AND D. LOC = 'DALLAS'
AND E. MGR = 7782;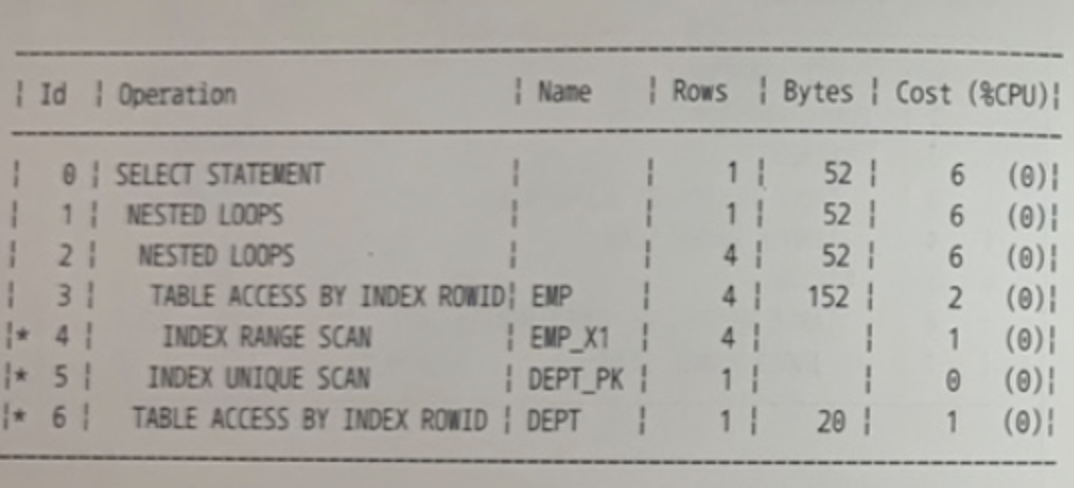
[나의 풀이]
- 드라이빙 테이블로 EMP_X1(JOB + DEPTNO) 를 통해 EMP 테이블이 스캔되었다.
- EMP 테이블에서 DEPT 테이블을 DEPT_PK(DEPTNO)를 통해 건건이 NL조인한다.
- 따라서 조건절 LOC과 MGR은 인덱스를 사용하지 않고 테이블 액세스와 동시에 필터링된다.
- EXPAND가 일어나지 않았다.
- E.JOB = 'CLERK'은 한 번만 비교된다.
[해답]
SELECT *
FROM EMP E, DEPT D
WHERE E.DEPTNO = D. DEPTNO
AND E.JOB = 'CLERK'
AND (D. LOC = 'DALLAS' OR E. MGR = 7782);🍒 문제 해설
- 공통 표현식 제거
같은 조건식이 여러 곳에서 반복 사용될 경우, 해당 조건식이 각 로우당 한 번씩만 평가되
도록 변환하는 것을 '공통 표현식 제거(Common subexpression elimination)'라고 한다. - '공통 표현식 제거' 쿼리 변환이 작동하지 않았다면 문제 SQL OR-Expansion을 실행하는 실행계획이 나타났을 것이다.
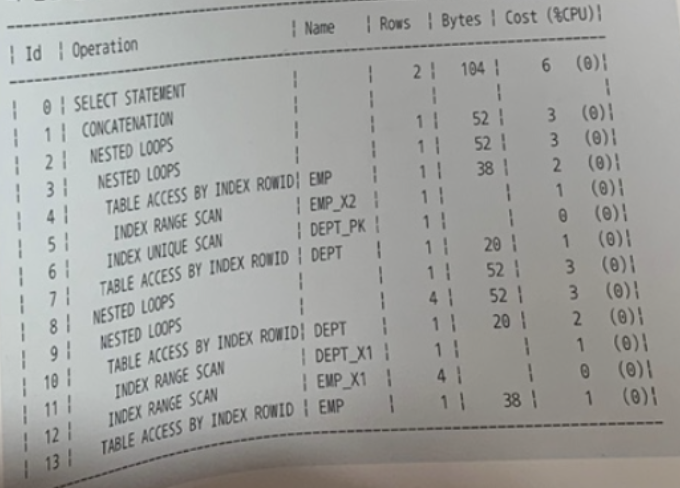
✍️ 37번 :
코드를 입력하세요- **** 👉 ⭕️
- **** 👉 ⭕️
- **** 👉 ❌
- **** 👉 ❌
🍋 기출 포인트
🍒 문제 해설

도광양회(韜光養晦) ‘빛을 감추고 어둠속에서 힘을 기른다’