
목차
- 영속성 컨텍스트
- Entity 캐시
- 생명주기
- 트랜잭션 매니저
1. 영속성 컨텍스트
이번 챕터에는 이론적인 내용을 학습할 것이다. Persistent context : 스프링의 빈들을 모두 로딩하고 관리하고 하는 일련의 작업들은 spring context 위에서 활용된다. 즉 Persistent Container가 관리하고 있는 내용들이 Persistent Context이다.
Persistence ( 영속화 ) 는 사라지지 않고 지속적으로 접근할수 있다는 의미이다. 보통 메모리에 존재하는 데이터는 서비스 종료시 사라진다. 이런 데이터를 사라지지 않고 지속적 처리 위해는 파일저장 or DB 저장해야 한다. JPA도 Java persistence Api로 데이터 영속화하기 위한 api인것이다. 영속성 컨텍스트의 가장 주최적인 클래스는 Entity Manager라는 빈이다.
EntityManager
영속성 컨텍스트의 가장 중요한 클래스이다. xml파일을 로딩하여 영속성 컨텍스트의 설정을 사용한다.
MySQL 연동
다운로드 참고 설명
터미널에서 mysql 서버를 실행시킨다. ( cmd를 관리자 권한으로 열고 net start mysql80 을 입력하여 실행한다. 관리자권한이여야 서버를 실행할수있다. 이후 mysql접속은 mysql-u root-p를 통해 진행한다.
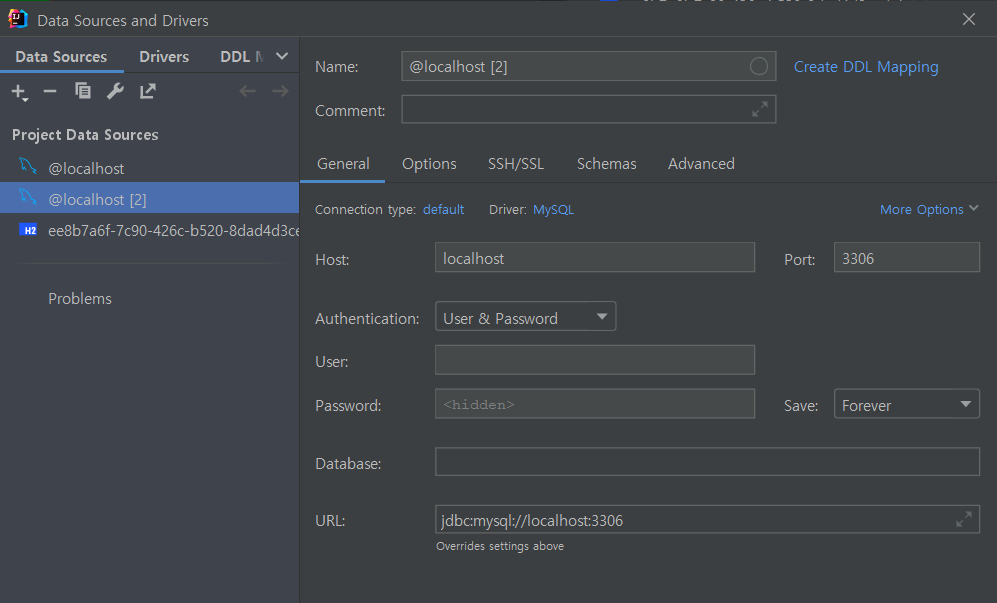
Intellij에 mysql 등록

오른쪽의 DataBase의 를 눌러 확장한후 왼쪽위의 +버튼을 눌러 mysql을 추가하여 준다. 이후 밑의 사진 처럼 창이 뜨면 host와 port,user,password를 내가 데이터베이스에서 설정해준 내용으로 지정한 후 테스트 커넥션을 진행하면 연결이 된것을 확인할 수 있으며, 콘솔창을 열어서 데이터베이스를 조작할 수 있다. 쿼리의 실행은 Ctrl+Enter로 수행한다.
JPA Context 연결[application.yml 설정]
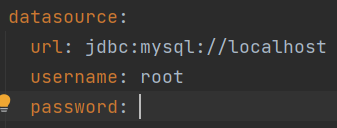
application.yml에서 spring.datasource.url과 username과 password를 밑과 같이 작성해준다. ( 초기 password는 공백이다. 나는 이미 설정하였음 ) url에는 jdbc:mysql: 뒤 내가 사용하는 db port번호/데이터베이스이름으로 작성해준다. 예시) jdbc:mysql:3036/book_manager
- initialization-mode: always : 스키마.sql , data.sql을 로딩하여 해당 파일을 실행해주기 위한 옵션이다.
- spring.jpa.generate-ddl:true 로 지정하여 자동으로 entity에서 활용하는 테이블을 생성해주는 옵션을 실행시킨다.
- spring.jpa.hibernate.ddl-auto:create-drop : 테이블을 생성하고 persistent context 종료시 자동으로 drop을 해주는 옵션이다.update시 실제 스키마와 entity 클래스 비교하여 변경 부분만 반영한다.create는 persist context를 띄울때 앞에서 drop을 하고 create를 한다. none 은 ddl옵션 실행하지않는다. validate 는단순 비교 작업만 한다. 다르면 오류를 발생한다.

generate-ddl과 ddl-auto의 차이점?
- 현업에서 두가지를 분리하여 사용하지 않는다. h2 db 는 별도의 설정이 없어도 알아서 작성해준다. 상용 DB 는 자동화 ddl구문은 리스크가 있으므로 실제로는 none과 false의 조합으로 모든것을 막아버린다. generate-ddl은 jpa의 하위속성이다. 구현체와 상관없이 자동화된 ddl을 사용할 수 있도록 설정한다. ddl-auto가 설정되는 경우에는 generate-ddl옵션을 무시한다. ddl-auto가 우선이다. hibernate에서 제공하는 세밀한 옵션이라고 생각하면 된다.
- H2 DB 는 임베디드 디비의 일종이므로 createdrop이 자동으로 동작했다고 생각하면 된다.
의존성 주입
build.gradle에 database연결을 위한 의존성을 주입하여 준다.
runtimeOnly 'mysql:mysql-connector-java' 작성후 갱신해준다.
실행시 로그에 Using dialect: org.hibernate.dialect.MySQL8Dialect가 보이면 mysql에 잘 연결이 된것을 확인할 수 있다.

위의 설정들은 자주 사용하지 않는다. 프로젝트에서 처음 개발시 제작하고 복사하여 쓰는 경우가 대부분이다. ( 뭔소리람 , )
2. Entity 캐시
컨텍스트는 생성되고 조회되고 지워진다. 가장 중요한 객체는 EntityManager 이다. 실제로 처리 과정에서 캐시를 사용한다. 이를 알아볼 것 이다. 해당 객체는 spring의 빈으로 관리되어 주입받아 사용할 수 있다.
entityManager객체를 이용하면 JPQL jpa에서 사용하는 쿼리를 사용하여 디비를 조작할 수 있다. Jpa에서는 이런 엔티티매니저를 사용하지 않고 편리하게 DB를 조작할 수 있도록 mapping하여 기능을 제공한다.즉 , 내부의 실제 동작은 EntityManager가 사용된다. jpa 에서 제공하지 않는 기능을 사용하고 싶거나 , 성능 이슈로 커스터 마이징을 원하는 경우에는 entity manager를 직접 사용하면 된다.
System.out.println(entityManager.createQuery("select u from User u").getResultList() ); 이러한 EntityManager는 영속성 Context내에서 Entity Cache를 가진다. 이러한 캐시는 실제 DB와 영속성 Context사이의 차이가 생기게 한다.
@Transactional
해당 클래스가 전체 Transaction으로 동작하게 해주는 기능이다. 해당 어노테이션을 붙이면 클래스전체가 하나의 transaction 이 된다.
@Transactional을 붙이지 않은 경우에는 하위의 클래스에 있는 Transaction으로 수행된다. 쿼리 조회 등의 메서드는 내부에서 자체적으로 @Transactional 을 가지고 있으므로 해당 메서드가 호출된곳을 하나의 transaction 으로 처리했던 것이다. 즉, 각 save,findById등의 메소드 하나가 transaction 하나 였다.
전체 클래스에 @Transactional을 붙여서 하나의 transaction 으로 만들어줄 경우 Entity Cache를 사용하게 된다.
Entity Cache
하나의 트랜잭션안에서는 쿼리를 매번 실행하지 않고 특정 지점에서만 쿼리를 실행하여 디비에 반영한다. 이렇게 되면 영속성 Context와 DB 사이에서 일종의 갭이 발생하게 된다. ( 둘이 다르다. )
findById와 같은 메소드 실행시 매번 쿼리로 데이터베이스를 조회하는 것이 아닌 엔티티 1차 캐시에서 조회를 수행한다. 이 캐시는 map의 형태로 key값으로 id를 value 값으로 엔티티를 가지고 있다. 즉, 여러번 findById를 사용하여 동일한 값을 호출할경우 해당 값을 바로 캐시에서 가지고 올수 있는 기능을 제공한다. ( jpa내부에서 id조회가 빈번히 일어나므로 1차 캐시를 사용하여 하나의 트랜잭션안에서 사용함으로 성능 저하를 방지한다. )
그럼 이때 영속성 컨텍스트를 디비에 반영하기 위하여는 어떻게 해야 할까. 영속성 컨텍스트에 쌓여있는 데이터는 EntityManager가 자동으로 영속화를 해준다. 하지만 이 시점이 개발자가 원하는 시점이진 않다. 그럼 언제 반영이 될까.
동기화 시점
- flush()메소드를 실행하는 순간 : 개발자가 의도적으로 영속성 캐시를 디비에 반영한다.
- transaction 종료시 : 해당 쿼리가 commit되는 시점이다. --> 마지막 문장이후 transaction 이 종료된다. ( test에서는 commit이 일어나지 않고 roll back 이 수행된다. )
- 복잡한 조회 조건인 jpql 쿼리가 실행 될 때 : auto flush()가 실행된다. 복잡한 조회 일 경우 디비와 영속성 캐시중에 더욱 최신에 변경이 된 값을 비교하여 가지고 와야 한다. 하지만 이때 데이터를 직접 비교하기란 어려울 것이다. 그때문에 복잡한 조회 쿼리가 발생하는 경우에는 flush()를 통해 디비와 동기화를 해준후 다시 조회 쿼리를 실행하여 값을 가지고 오는 것이다.
3. Entity 생애주기 [Life Cycle]
비영속상태(new), 영속상태(managed),준영속상태(detached),삭제상태(removed)
비영속상태
영속성 컨텍스트가 해당 엔티티객체를 관리하지 않는 상태이다. @Transient 를 사용하여 해당 필드를 영속화에서 제외하겠다는 의미이다. transient상태라고도 하며 entity 를 new한 상태와 같아서 new상태라고도 한다. 단순한 자바 오브젝트로 취급이 된다.

영속상태
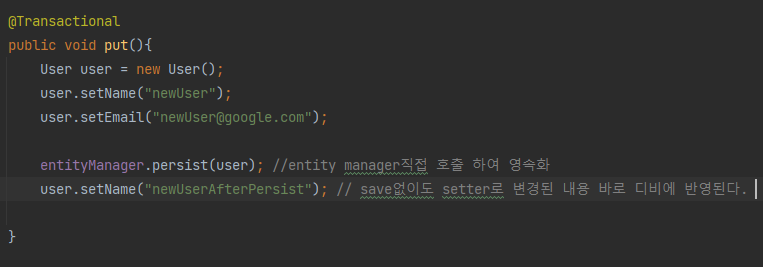
해당 엔티티가 영속성 컨테스트의 관리하에 존재하는 상태이다. 객체의 변화를 별도로 처리하지 않아도 디비에 반영하게 된다. 영속성 컨텍스트가 해당 엔티티를 관리하게 되면 해당 엔티티 객체는 계속해서 연결되어 변화가 이루어지는 즉각적으로 변경이 반영되게 된다. 즉 , setter를 통해 정보 변경시 transaction 완료되는 시점에 save메소드 없이도 DB와 맞쳐주게 된다.
준영속상태
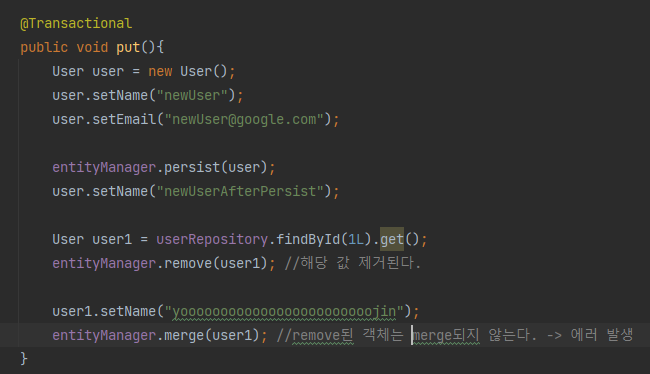
detached상태이다. 원래 영속화 되었던 객체를 분리하여 영속성 컨텍스트 밖으로 꺼내는 동작이다. detach할 경우 변화에 대한 디비의 반영이 이루어지지 않는다. 명시적으로 save할 경우에는 디비에 반영이 가능하다. clear나 close 메소드도 동일하게 사용이 된다. detach보다는 조금더 파괴적인 방법이다.

삭제 상태
remove상태이다. 딱히 특별한 것은 없다. remove시 해당 엔티티는 더이상 사용하지 못하는 상태가 된다.
영속성 컨텍스트의 관리 하에 엔티티는 조회,더티체크 등을 위해 1차 캐시를 지원하고 쓰기 지연 등의 처리를 통해 개발자가 신경쓰지 않아도 되는 편의성을 제공한다. 하지만 신경쓰지 않았던 부분에서 발생하는 개발자가 의도하지 않은 동작을 수행하곤 한다. 이 때문에 위의 내용을 학습해야 한다.
4. Transaction 활용
Transaction 매니저와 @Transactional 어노테이션에 대해 설명한다. Transaction 은 database에서 다루는 개념이다. 디비의 명령어들의 논리적인 묶음이다. 논리적으로 하나의 트랜잭션의 처리가 가능하다. (주문과 결제의 관계 -> 하나의 트랜잭션으로 처리하여 둘다 처리되거나 둘다 처리되지 않거나)
트랜잭션의 특성
ACID라고한다.
1. Automicity : 원자성이다. 원자성이라는 것은 부분적인 성공을 허용하지 않는다는 의미이다. 예 ) 돈의 송금 - 내가 돈을 보내면 상대방도 돈을 받는다는 것이다.
2. Consistency : 일관성이다. 송금의 성공을 하려면 내계좌의 잔액이 0보다 커야 한다. 성공시 계좌는 0또는 0보다 더 많은 잔액이 있어야 한다. 상대방의 잔액은 0보다 많은 잔액이 존재해야한다. 즉 데이터의 정확성을 맞추는 것이다.
3. Isolation: 독립성이다. 다른 트랜잭션으로부터 독립적인 속성을 갖는다. 내가 친구에게 돈을 보내는 중에 즉, 송금 트랜잭션 미완료시에 친구통장에서 돈이 먼저 인출되면 안된다. (내가 송금 -> 친구 통장 입금 -> 내 통장 차감 -> 친구 먼저 인출 -> 내 통장 금액 차감시 오류발생 원자성 근거 하여 송금 취소 원함 -> 친구이미 인출됨 -> 문제 발생 )
4. Durability: 지속성이다. 데이터는 영구적으로 보관된다. 송금 성공시 시간이 지나도 그 금액이 계속 존재해야 한다.
Jpa의 트랜잭션 설정
@Transactional어노테이션을 작성한다. 쿼리들은 하나의 트랜잭션으로 묶여서 실행된다. 모든 쿼리들은 트랜잭션 완료시점에서 커밋하고 디비에 반영을 하게 된다. 해당 어노테이션을 붙인 메소드의 시작이 트랜잭션의 시작이 되고 끝이 트랜잭션의 종료가 된다. 어노테이션이 달려있지 않은 경우 내부의 메소드에 존재하는 트랜잭션이 동작하게 된다. 오류가 발생하면 하나의 transaction안의 쿼리는 모두 실행되지 않는다. (원자성)
트랜잭션의 잘못된 사용
-
Checked Exception의 사용 : test를 위해 checked excpetion을 사용하였다. 실제로는 이렇게 만들지 않는다. 여러가지 복잡한 로직으로 Checked/Uncheck exception을 모두 사용하게 된다. Checked 예외 발생하였음에도 디비에 쿼리가 모두 적용이 된다. ( runTime Exception은 반영내역이 rollback이 되지만 Checked 예외는 해당 변경내역이 commit이 된다. -> 개발자가 모든 책임을 가지게 된다. ) CheckedExeption의 경우 RollBack을 하고 싶은 경우에는 Transactional의 rollbackFor을 지정하면 된다.
@Transactional(rollbackFor = Exception.class)--> 이를 지정하면 오류발생시 rollback이 된다. ( CheckedException임에도 ) -
빈 클래스내부의 @Transational의 호출 : 같은 class내에서 호출되는 메소드가 @Transactional이 있음에도 exception발생시 롤백이 일어나지 않고 commit되어 디비에 반영된다. @Transactional이 있음에도 매번 커밋된다. Spring Container는 빈 진입시 위의 어노테이션을 확인한다. 이미 빈 내부로 진입한 이후에는 빈 이후의 다른 메서드를 호출시 @Transactional 어노테이션이 무시가 된다. 즉, 같은 클래스내에서 transaction 가 붙은 메소드를 호출하여도 처리되지 않는다.

@Transactional의 속성
isolation [격리]
트랜잭션 격리 단계이다. 동시 발생하는 트랜잭션간의 데이터 접근을 어떻게 처리할지를 결정하는 것이다.
- Default : database의 기본 격리 상태를 따라간다. mysql-repeateable_read
- Read_uncomitted : commit되지 않은 데이터를 읽을수있는 단계 , 다른 트랜직션의 커밋되지 않은 데이터를 읽을 수 있다. dirty read라고 한다. (깨끗하지 않은 데이터이지만 읽는다. ) --> rollback을 했는데도 쿼리가 실행되는 일이 발생할수 있다. 이를 방지하기 위해서는 엔티티 클래스위에 @DynamicUpdate 를 붙여준다. 현업에서 일반적으로 많이 사용하지 않는다.
- Read_committed : commit된 데이터만 읽어오겠다는 의미이다. read_uncommitted 에서 발생하는 dirty read현상이 없어진다. 중간에 commit을 하여도 쿼리에 적용이 안되는 경우가 발생할 수 있다.unrepeateable_read상태가 된다. 조회값이 달라질수도 있는 현상이다. 영속성 캐시에 의한 현상이면 이는 엔티티매니저의 clear()로 정리해줌으로써 해결이 가능하다.
- Repeateable_read : 위를 해결하기위한 상태이다. 트랜잭션에서 반복해서 값을 조회하더라도 항상 같은 값을 조회하는 것을 보장한다. 다른 트랜잭션에서 커밋한 값이 발생하더라도 해당 상태에서는 커밋된값을 직접 가져오는 것이 아닌 자기 트랜잭션이 수행시 저장해놓았던 처음의 정보를 리턴해준다. 팬텀니드라는 현상이 발생한다. 데이터가 보이지 않는데 처리가 되는 경우이다.
- Serializable : 팬텀니드를 해결해주는 상태이다. commit이 실행되어야만 추가적인 로직 작업을 수행한다. 데이터 변경하려고 하면 다른쪽 transaction이 끝나는 것을 기다린후 진행한다. 대기가 길어져서 성능이 떨어질 수 있다.
위로 갈수록 성능은 향상되나 데이터의 정확성을 보장하지 못한다. 순서대로 level0-3이라고 한다. 아래쪽으로 갈수로 격리단계가 강력해지고 데이터의 정확성을 보장해주는 대신에 동시처리하는 수행성능이 떨어진다. 일반적으로 read_committed또는 repeateable_read를 주로 사용한다.
Propagation [전파]
트랜잭션의 메소드 내에서 다른 트랜잭션의 메소드를 호출하는 경우 현재 트랜잭션과 다른 트랜잭션 간의 처리를 결정하는 것이다.
- Required : 가장 일반적으로 사용한다. 기본값이다. 기존의 트랜잭션이 있다면 그 트랜잭션을 사용하며 없다면 새로운 트랜잭션을 생성하여 사용한다는 의미이다. 가장 직관적인 전파 속성이다. 있으면 재활용, 없으면 만들겠다라는 것이다. 예로 jpaRepository 의 save메소드가 있다. save를 호출한 메소드에 transaction이 있으며 그것을 아니면 save의 transaction이 사용이 되는 것이다.
- Supports : 호출하는 쪽에서 transaction이 있다면 재활용한다. 하지만 없다면 굳이 새로 생성하지 않고 트랜잭션없이 처리를 하게 된다.
- Mandatory : 필수적으로 트랜잭션이 존재해야 한다. 이미 생성된 트랜잭션이 반드시 있어야하며 없는 경우 오류를 발생한다.
- Requires_new : required의 경우에는 트랜잭션을 재활용하지만 requires_new는 무조건 새로운 트랜잭션을 생성한다. 호출하는 쪽의 롤백,커밋과는 관계없이 자체적으로 진행하겠다는 의미이다. 서로완전히 독립적인 트랜잭션을 사용한다.
- Never : 트랜잭션이 없어야 한다. 이미 트랜잭션이 존재시 오류가 발생한다.
- Nested : 별도의 트랜잭션을 생성하는 것이 아닌 호출하는 쪽에서 생성한 트랜잭션을 그대로 활용한다. 약간 분리되어 동작을 시킬 수 있다. 종속적이지만 상위에 영향을 주진 않는다. save point까지는 보장을 한다. JPA에서는 nested를 사용하지 않는다.
- NOT_supported : 호출하는 쪽에 트랜잭션이 있으면 잠시 멈춘다. 실행 완료후 수행된다.
주로 사용하는 것은 required나 requires_new를 주로 사용한다. 현업에서는 거의 required를 사용하며 다른 방법에 대해 사용을 지양한다.
