
목차
- 필요성, Embedded, Embeddable, 속성의 재정의
- N대1 이슈
- 영속성 컨텍스트로 인한 이슈
- 배치 쿼리 성능 이슈
1. 필요성, Embedded , Embeddable, 속성의 재정의
JPA 에서 Embedded 활용하기
open source등 최근의 코드는 가독성이 높은 코드를 작성하는 것이 중요한 트렌드가 되었다. @Embedded @Enbedable 어노테이션을 학습한다.
주문시에 가격필드를 예시로 든다. 가격은 공급가,부과세,총가격 등의 세트는 상품도메인,주문 도메인 등의 여러개의 도메인에서 묶음으로 활용된다. 임베디드 타입을 사용하기에 적합하다.
주소 정보 또한 단순히 address문자열 하나에 전부 저장하는 것이 아닌 도,시,군,구 상세 주소 또는 우편번호등으로 컬럼을 나누어 처리하는 경우가 많다. ( 특히, 해외 쇼핑몰 등에서 주소 기입을 위해 여러 인풋 박스를 사용한다. )
User 도메인의 주소 필드
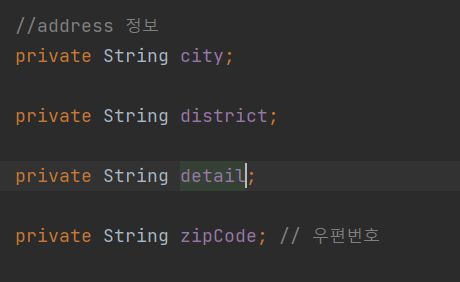
위의 코드는 임베디드를 사용하지 않은 방법이다. 해당 필드들을 user와 userHistory 모두에 작성한다. 이럴 경우 dry법칙인 dont repeat yourself 에 어긋난다. 코드는 최대한 복붙을 지양하고 객체화 하여 사용하는 것을 추천한다. 임베드 타입을 활용하여 변경해본다.
각 주소 필드들을 enum타입으로 생성하는 것도 좋은 방법이다. ( 예) city - 서울,대구,... )
임베드 타입으로 사용할 클래스를 새로 생성한다. ( address 클래스 ) @Embeddable 어노테이션은 임베드를 할 수 있는 클래스를 표시하는 어노테이션으로 해당 어노테이션이 붙은 클래스는 엔티티 내부에 표시를 할 수 있게 된다.
@Data
@AllArgsConstructor
@NoArgsConstructor
@Embeddable
public class Address {
private String city; //시
private String district;//구
private String detail; //상세주소
private String zipCode; //우편번호
}위의 클래스를 포함한 엔티티 내부에서는 밑의 코드와 같이 @Embedded 어노테이션을 해당 필드위에 붙여준다.
@Embedded
private Address address;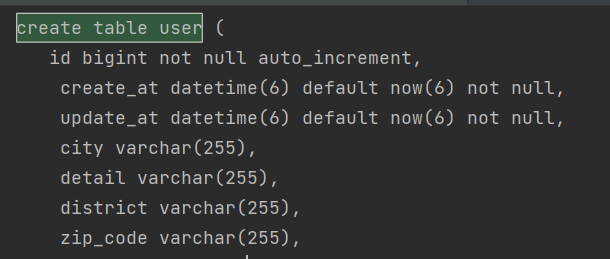
위의 그림과 같이 ddl에서 city,detail,district,zip_code와 같은 필드가 포함이 된 것을 확인 할 수 있다.
Embedded속성 내부에서도 기존의 @Column 어노테이션을 통하여 컬럼 속성을 재정의 할 수 있다.
@Column(name = "address_detail")
private String detail; //상세주소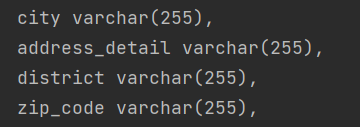
더 명시적인 컬럼의 이름으로 수정이 되었다.
임베드도 결국엔 자바의 객체이다. new 생성자를 통하여 객체의 생성이 가능하다. ( @AllArgsConstructor 를 작성하였으므로, 모든 인자를 받는 생성자가 존재한다. )
user.setAddress(new Address("서울시","강남구","강남대로 364 유진빌딩","06241"));
userRepository.save(user);이렇게 여러 컬럼을 한번에 묶어서 사용이 가능하다. 다른 엔티티에서도 언제든지 재활용하여 구성이 가능하다.
Embed 타입의 유용성
은행,신용카드 등의 회원가입시 주소는 여러개가 존재 할 수 있다. 만약, 임베드 클래스가 없다면 각 주소별로 여러 필드를 선언해주어야 한다. ( 핵 불 편 ) 하지만 임베드 클래스가 존재하는 경우 재활용이 가능해진다.

위와 같이 필드를 각각 동일한 address 객체로 생성을 해주면 동일한 여러줄의 코드가 아닌 간단한 코드 두줄로 회사,집의 주소를 작성할 수 있게 된다.
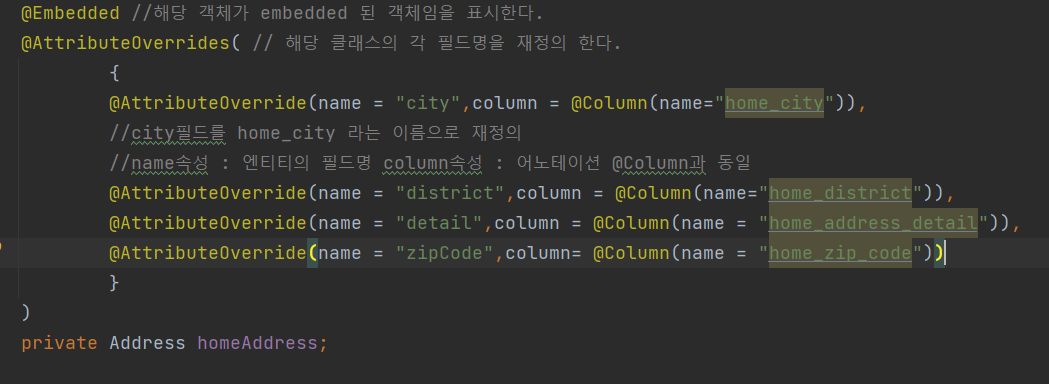
에러발생 : address를 두번씩 선언하여서 내부의 컬럼 들이 두번씩 선언이 되었다. 디비에서 한 테이블에 컬럼명은 일반적으로 중복을 허용하지 않는다. --> @AttributeOverride 어노테이션을 사용한다. 동일한 클래스를 사용하지만 해당 어노테이션을 사용하여서 해당 속성값들을 재정의하겠다는 의미이다. ( 계속 반복적으로 사용이되므로 지저분,,
뭐가 좋다는 거지 !)
임베드 클래스의 NULL ?
임베드 클래스가 null일 경우에는 어떻게 되는지 코드를 통해 배워본다.
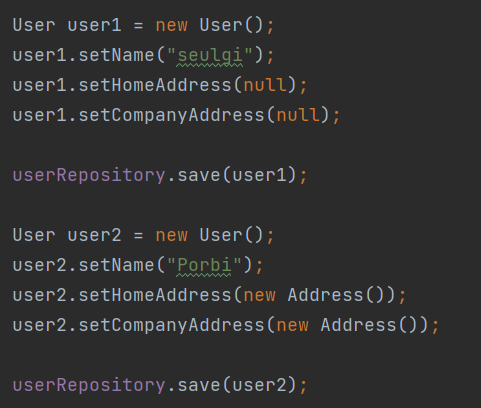
위의 코드와 같이 작성을 한 경우 위의 null을 바로 넣은 것은 각 필드가 null로 표시되며 밑의 new Address()의 널을 넣은 경우 address객체의 필드가 null로 표된다. 두가지는 데이터베이스에 동일하게 모든 필드들이 null로 들어간다. ( 출력은 다르다 why? - 영속성 컨텍스트가 제공하는 캐시 때문 ! 영속성 컨텍스트의 캐시로 인해 차이가 벌어진다. )
entityManager.clear(); //영속성 컨텍스트 캐시 제거
임베드된 객체가 null로 지정된다.
2. N+1 이슈
JPA 사용시 주의해야 할 점에 대해 배워본다. 첫번쨰는 N+1 이슈이다. 해당 문제를 학습하기 위해 밑의 내용을 먼저 학습한다.
우리가 만드는 엔티티에는 또다른 엔티티에 대한 릴레이션을 가지고 있다. ( 엔티티가 관계를 맺고 있다. )
Eager 패치
엔티티 객체 호출시 바로 모든 릴레이션의 쿼리를 실행하는 것을 eager패치라고 한다. 처음에 엔티티를 조회하는 시점에 각각의 관계를 맺은 모든 필드들을 조회를 함께 실행한다.
Lazy 패치
엔티티를 호출할때 필요한 시점에만 쿼리를 실행하려면 lazy 패치이다. 예로 User를 호출할때마다 UserHistory 라는 릴레이션은 항상 필요하진 않다. UserHistory 는 필요한 시점에만 쿼리를 실행하면 된다. 실제로 필요한 시점을 알수 있는 것은 getter에 대한 호출이다. 즉 User객체를 가져오기 위해 쿼리가 실행된다. 그러고 나서 만약 user객체의 이력이 필요한 경우 user.getUserHistory 를 하는 시점에 쿼리가 실행되어 userHistory 를 가져오는 것이 lazy 패치이다. Get이 없으면 쿼리 실행되지 않는다. 쿼리성능에 이점을 가진다.
단 lazy 패치는 세션이 열려있을 때 가능하다. ( 영속성 컨텍스트가 엔티티를 관리하고 있는 라이프사이클의 주기, 즉 Transation이 열려있을 때 )
could not initalize proxy - no Session에러 --> @Transational이나 eager패치로 변경하여 해결한다.
ToString 문제
여러가지 속성을 각 엔티티들이 가진다. 이때, 필드들을 출력하기 위해서 getter를 사용하게 되며 그럴 경우 lazy 패치임에도 불구하고 불필요한 쿼리가 발생하게 된다. ( + 순환참조로 stack overflow 발생 가능 ) ToString.EXCLUDE 를 통하여 관계를 맺은 필드를 ToString에서 해당 getter의 호출을 막는다.
Rest Api 의 결과값은 최근에는 json형태로 출력된다. ( getter를 활용함 ) -> 엔티티의 모든 필드를 호출하여 출력한다. ToString.EXCLUDE를 하지 않으면 lazy로딩의 장점을 모두 잃는다. 항상 엔티티 호출시마다 릴레이션의 쿼리를 실행하므로 불필요한 쿼리가 발생한다.
@OneToMany 는 LAZY, @OneToOne은 Eager, @ManyToMany 는 Lazy, @ManyToOne 은 Eager이다. OneToMany와 ManyToOne은 기본 패치타입이 다르다.
N+1 이슈
쿼리가 한개가 실행되고 N개가 실행이 되는 문제
reviewRepository 의 findAll을 통해 review 쿼리 한개를 실행하였다. 그러면 한개의 쿼리가 조인을 통하여 comment 값까지 조회할수 있을 것이라 예상한다. 하지만, JPA에서는 하나의 리뷰쿼리에 커멘트쿼리가 N개(커멘트갯수)가 실행이 된다.즉, N대1관계에서 1측을 쿼리를 통해 값을 받아오려고 할때, 예상은 한번의 쿼리를 통해 관계를 맺은 N측의 값 또한 모두 조회할수 있을 것이라 생각하지만, 실제 JPA에서는 N측의 값을 N번의 쿼리를 통해 조회하게 된다.
이를, Eager타입으로 해결을 할 수 있을 것이라 예상하지만, Eager와 lazy 는 쿼리하는 시점의 문제이지 N+1이라는 쿼리 횟수에 영향을 끼치진 않는다. 그러므로 밑의 두가지 방법을 사용하여 N+1문제를 해결한다.
- @Query를 통하여 패치조인 쿼리를 커스텀으로 만든다. : jpql을 사용하여 패치조인을 실행한다.select 쿼리의 조인쿼리가 실행된다. --> 한번의 쿼리로 모든 값을 조회한다. ( distinct : 중복 제거 )

- entity 그래프 어노테이션 : 쿼리메소드에 적용가능
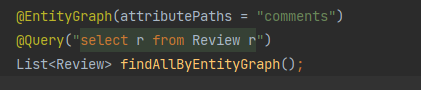
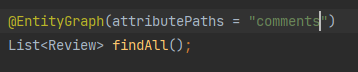
3. 영속성 컨텍스트로 인한 이슈
JPA가 어떤방식으로 쿼리를 만드는지 알아두면 더욱 능숙하게 사용이 가능하다.
영속성컨텍스트가 가진 캐시로 인한 디비와의 불일치 문제를 학습한다. 디비에 저장하기 전에 영속성 컨텍스트의 캐시에 미리 저장을 해둔다. clear()메소드를 통하여 영속성 컨텍스트를 비울 수 있다. 디비 데이터와 불일치하는 부분이 생기면서 데이터가 틀어지는 경우가 발생할 수 있다.
현업에서 오토 ddl을 사용하는 경우는 드물다. 이때 만약 datetime의 scale이 다른 경우 문제가 발생한다. 영속성 캐시를 날리고 수행을 하는 경우 데이터베이스에 접근하여 값을 가지고 오지만 영속성 캐시를 날리지 않은 경우에는 캐시에 접근하여 값을 가져오므로 데이터베이스의 값과 캐시의 값이 달라서 서로 다른값(예상하지않은 값)을 가지고 올 수 있다. 영속성 캐시를 clear하는 경우에는 캐시에서가 아닌 데이터베이스에서 직접 값을 조회한다. 캐시와 데이터베이스가 다른경우 문제가 발생할 가능성이 있다. 그래서, 실제 값과 캐시간의 차이가 생기지 않도록 캐시를 잘 관리하여야 한다.
@DynamicInsert 해당 어노테이션이 붙은 엔티티는 insert시 dynamic하게 동작한다. inser시 해당 필드를 set해주지 않은 경우 해당 필드를 제 insert에서 제외한다. ( 기본값을 설정할시 기본값으로 값이 insert되게 된다. )
4. DirtyCheck와 성능이슈
@DynamicUpdate 영향을 받은 필드에 대해서만 update가 실행되어 쿼리가 간단해 진다.
영속성 컨테스트내에는 dirtyCheck라는 기능이 존재한다. 영속성 관리 중에 일어난 변경은 별도의 save메서드 호출 없이도 db데이터에 영속화를 시켜준다. 영속성 컨테스트가 관리하는 범위인 세션(트랜잭션) 내에서는 dirty check 를 지원한다.( 변경본 발생시 save없이 디비에 변경되는 쿼리가 동작) 단, 이미 관리하고 있어야 함 ( select )
dirtyCheck의 기능은 save하지 않았지만 update를 지원해주는 예외적인 상황을 발생시키며 , 성능 이슈가 발생하게 된다. 즉, Transaction내에서 데이터 참조를 위해 select를 한 엔티티에 대해서는 일일히 dirtyChecking과정이 들어가게 된다. 수십건 수백건의 경우에는 문제가 되지 않지만 수만건등의 배치 로직의 경우에는 시간이 눈에 띄게 많이 늘어난다. 이런 경우에 dirty Checking을 하지 않고 데이터를 조회하기 위해서는 @Transactional(readOnly = true)를 달아준다.
