
문자열을 가공하던 차에, trim을 해서 앞 뒤 공백만 지우려고 했었다.
대부분이 알고 있듯이, trim은 앞뒤 공백을 지우는 String 클래스의 메소드이다.
하지만 실제로 사용해보니 공백'만' 제거하는 것이 아니었다!
1. String.trim
public String trim() {
String ret = isLatin1() ? StringLatin1.trim(value)
: StringUTF16.trim(value);
return ret == null ? this : ret;
}trim 메소드를 확인하면, 먼저 Latin1인지 아닌지를 확인하고
문자열의 특성에 따라 각 다른 trim 메소드를 이용한다.
2. ISO-8859-1(Latin-1)
문자 집합으로 영어랑 유럽권 언어를 포함한다고 한다.
위키 참고! https://ko.wikipedia.org/wiki/ISO/IEC_8859-1
영어랑 유럽권 언어는 쓰는 문자 수가 많지 않기 때문에 1byte로 표현할 수 있다.
3. String에서는 byte[]? char[]?
byte[]로 문자열 값을 저장한다고 한다.
내가 생각하는 이유는,
영어나 유럽권 문자의 경우 한 바이트로 표현할 수 있기 때문에 굳이 char로 표현하면 불필요하게 1byte나 더 써야 된다. 그래서 byte[]로 저장하는 게 아닌가 싶다!
3. StringLatin1.trim(value)
public static String trim(byte[] value) {
int len = value.length;
int st = 0;
while ((st < len) && ((value[st] & 0xff) <= ' ')) {
st++;
}
while ((st < len) && ((value[len - 1] & 0xff) <= ' ')) {
len--;
}
return ((st > 0) || (len < value.length)) ?
newString(value, st, len - st) : null;
}비트 연산을 수행한 후, 0~255까지의 값들 중 ' '값보다 작거나 같은 문자를 제거하는 로직이다.
사실상 범위를 줄여서 새로운 문자열을 만들어낸다고 보면 된다.
byte는 -128~127까지 표현할 수 있기 때문에 부호 연산을 하지 않으면, ' '보다 작은 수로 나타나지는 경우가 있어서 비트 연산이 필수적이다.
4. StringUTF16.trim(value)
public static String trim(byte[] value) {
int length = value.length >> 1;
int len = length;
int st = 0;
while (st < len && getChar(value, st) <= ' ') {
st++;
}
while (st < len && getChar(value, len - 1) <= ' ') {
len--;
}
return ((st > 0) || (len < length )) ?
new String(Arrays.copyOfRange(value, st << 1, len << 1), UTF16) :
null;
}
위와 동일한 로직이다. UTF-16과 관련된 처리가 포함되어있다.
5. 결론
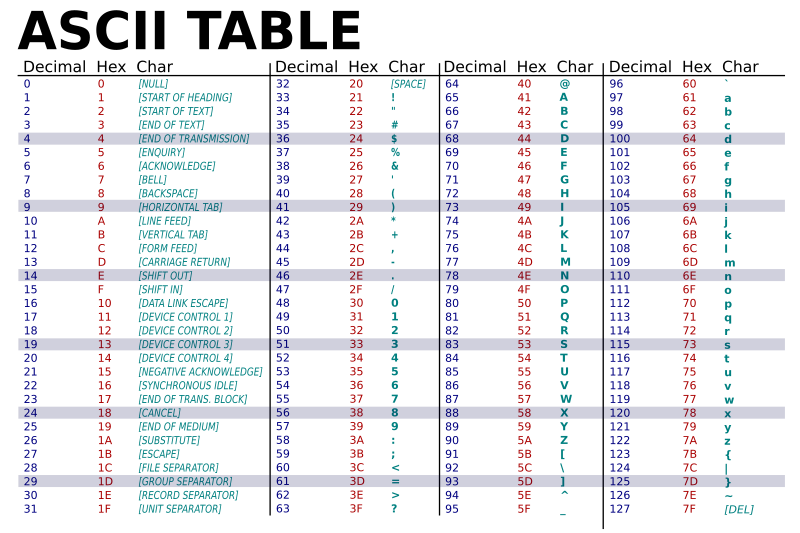
' ' 공백 문자는 32로, 32 이하는 다 제어문자로 출력이 필요없어서 앞뒤로 다 제거된다. 결론적으로 trim 메소드를 사용해서 앞, 뒤 공백 문자만 제거되는 것이 아니라 제어 문자가 제거되는 것이다!
해당 내용을 정리하면서 내가 부족한 부분에 대해 알게 되었다.
비트 연산과 byte에 대한 개념이 부족하고,
유니코드에 대해 알고는 있지만, 아직까지 부족한 부분이 많이 보인다.
유니코드와 byte의 관계를 정확하게 모르는 것 같다. +인코딩도
단순히 String의 trim 메소드를 알아보려고 했던 것이었는데 부족한 부분을 새롭게 알게 되는 계기가 되었다~! 연휴에 공부해야지...
