네트워크 전송 과정의 전반적인 흐름에 대하여 (feat. DB Connection pool의 생성비용이 도대체 뭘까?)
📉 어플리케이션 데이터에서 전기 신호까지 (하향식으로 가자..)
전체적인 과정을 요약하면
1. 어플리케이션에서 목적지 서버에 무언가를 요청해야한다는 판단을 한다. (데이터 요청이든 전송이든)
2. url에 있는 서버 주소를 DNS(UDP)를 통해 ip로 변환한다.
3. TCP에서, 데이터를 자르고 tcp 헤더를 붙인다. tcp 헤더에는 수신포트, 송신포트 등의 정보를 가지고 있다. (단위: 세그먼트)
4. 각 세그먼트에, 2번에서 수행했던 ip 주소를 붙인다. ip 헤더에는 수신ip, 송신 ip 등의 정보를 가지고 있다. (단위: 패킷)
5. 4번의 패킷에 현재 서브넷에서 ip에 접근할 수 있는 라우터 MAC 주소(nic 주소) or 같은 서브넷의 서버 MAC 주소를 붙인다. (단위: 프레임)
6. 최종적으로 프레임을 전기 신호로 바꿔 물리 계층으로 전송한다. (케이블이나 wifi를 통해 전송)
1. 어플리케이션 계층에서 서버에 요청을 하기로 한다.
POST http://yoojkim.ai:80/image
POST /image HTTP/1.1
User-Agent: PostmanRuntime/7.43.0
Accept: */*
Cache-Control: no-cache
Postman-Token: b5d38134-1b21-4927-b4e7-2894235e089c
Host: yoojkim.ai:80
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Content-Type: multipart/form-data; boundary=--------------------------694085170543766494928141
Content-Length: 73159
----------------------------694085170543766494928141
Content-Disposition: form-data; name="image"; filename="carbon (14).png"
<carbon (14).png>
----------------------------694085170543766494928141--위와 같은 형태로 Http request message를 작성한다. 요청시 보낼 데이터와, 해당 데이터의 정보, 사용자의 정보를
2. url에 있는 서버 주소를 DNS를 통해 ip로 변환한다.
yoojkim.ai이라는 서버 주소를 DNS를 통해 ip로 변환한다.
이때, DNS는 TCP가 아닌 UDP 프로토콜을 사용한다.
데이터의 양이 많지 않기 때문에 -> 한 개의 패킷으로 가능하다. 간단한 통신을 수행하기 때문에 TCP 같이 접속, 연결에 대한 오버헤드가 없는 UDP 채택. 회신이 오지 않으면 단순히 데이터를 한 번 더 보내준다.
](https://www.cloudns.net/blog/wp-content/uploads/2022/03/UDP-vs-TCP-1-1024x357.png)
TCP는 연결 단계가 있지만, UDP는 연결 단계가 존재하지 않는다. 데이터 전송, 요청과 같이 중요한 작업이 아닌 DNS 확인과 같은 간단한 작업을 UDP로 하는 이유!
3. TCP에서 데이터를 세그먼트로 가공한다.
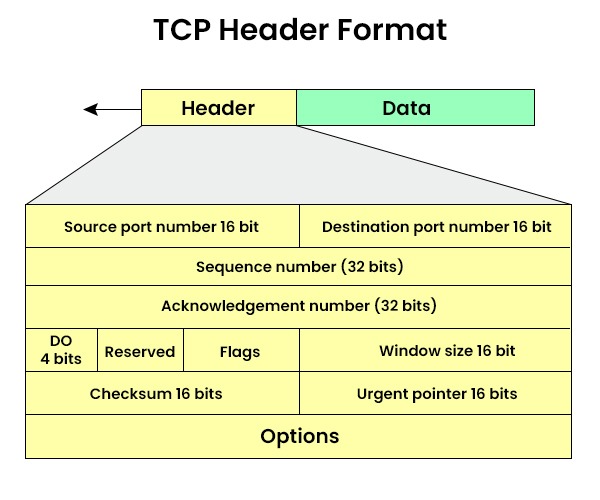
보낼 데이터를 쪼개 여러 개의 세그먼트로 만든다. 이후, 각 세그먼트마다 TCP 헤더를 붙여준다.
TCP 헤더에서 제일 중요한 것은 포트 번호이다. TCP 헤더는 ip, mac 주소가 아닌 포트 번호를 식별하기 위해 존재한다고 해도 과언이 아니다.
소켓은 4개의 정보로 고유하게 식별된다.
*예시는 Spring 서버와 MySQL 서버가 TCP/IP 통신을 하는 과정을 나타낸다.
| 구분 | 내용 |
|----------------|--------------------------------------|
| 서버 IP | MySQL 서버 IP 주소 |
| 서버 포트 | MySQL 서버 포트 (예: 3306) |
| 클라이언트 IP| Spring Boot 애플리케이션 IP 주소 |
| 클라이언트 포트| 클라이언트가 임시로 할당받은 포트 (ephemeral port) |
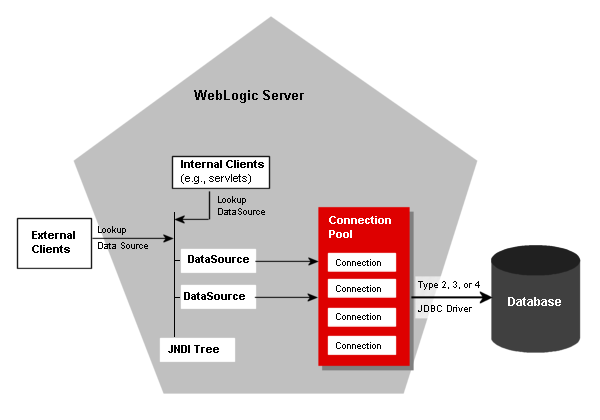
최근 사용했던 mySQL을 보면, DB와 현재 어플리케이션을 연동하는 connection을 수행한다.
public static Connection getConnection() throws SQLException {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("password", PASSWORD);
return DriverManager.getConnection(URL, properties);
}TCP는 3-way handshake 과정을 통해 연결을 설정하기 때문에, 이 과정에서 발생하는 연결/연결 확인 비용(TCP 연결 오버헤드) 이 존재한다.
이를 줄이기 위해 서버 개발에서는 커넥션 풀(Connection Pool)을 사용한다.
한 번 연결 확인을 거친 커넥션(TCP 소켓)을 여러 개 유지해두고, 필요할 때마다 재사용하는 방식이다.
이때 모두 mySQL 서버의 3306 포트와 클라이언트의 아무 빈 포트로 소켓 연결을 수행한다. 그래서 다 다른 고유한 소켓이 존재하게 되는 것이다.
우리는 TCP/IP 통신을 해야하고, 각 계층을 내려가면서 포트/ip/mac주소에 대한 정보를 담아 통신을 위한 초석을 다지는 과정을 거친다고 이해하면 좋을 것 같다!
4. IP에서 세그먼트를 패킷으로 가공한다.
IP 계층에서는 이렇게 받은 세그먼트에 IP 헤더를 추가한다.

IP 계층에서는 단순히 송신자의 ip주소, 수신자의 ip주소 외 부가 정보가 담긴 ip헤더를 더해준다.
](https://www.rfwireless-world.com/images/Segment-vs-Packet-vs-Frame.webp)
현재 ip 헤더에서 패킷의 순서 등을 기재하지 않는 이유는 ip 계층에서는 딱히 그걸 관리하지 않기 때문이다. 그건 TCP의 영역일 뿐이다. 개인적으로 ip 계층이 좀 애매하다고 생각한다. 그리고 완전히 계층적으로 나누기 어렵다고도 느꼈다.
5. 이더넷에서 패킷을 프레임으로 가공한다.
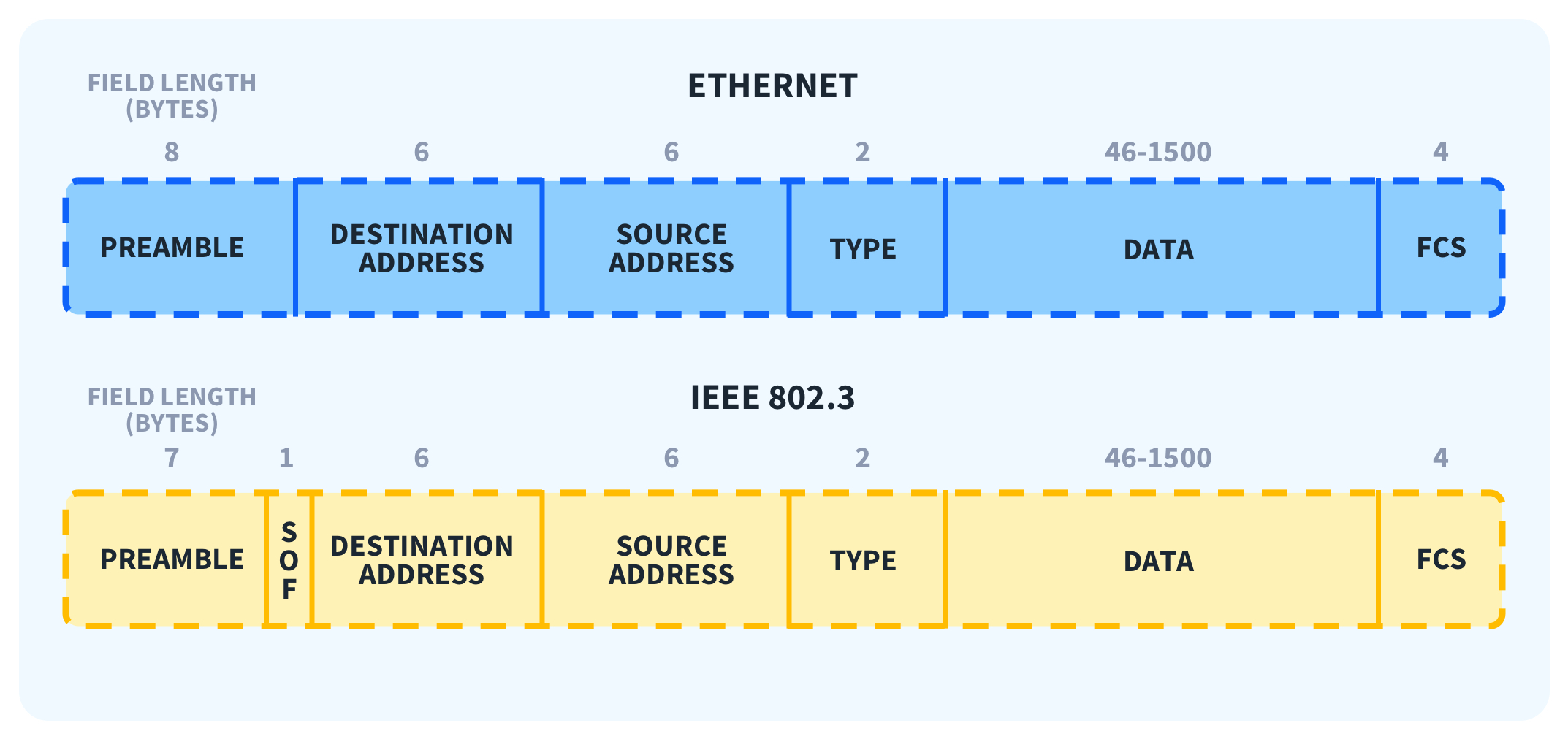
이더넷에서 가장 중요한 부분은 address를 붙이는 부분이다. 여기서 말하는 address는 MAC 주소이다.
사실상 ip주소로는 해당 서버로 전기 신호가 갈 수 없다. 실제 주소를 알아야 한다.
실제 주소에 해당하는 것이 MAC 주소이다. 실제 주소를 알기 위해서는 서버의 MAC 주소를 받으면 좋겠지만 딱히 의미도 없다. 거기까지 여러 라우터를 거쳐서 도달해야 하기 때문이다. 여기서 ARP 라는 개념이 도입된다.
만약 서버가 현재 네트워크와 다른 서브넷에 존재한다면, 우리는 해당 서버의 MAC주소를 한 번에 찾을 수 없다. 다른 네트워크(다른 서브넷)로 넘어가야 한다. 이때 현재 이더넷 헤더에 서버 MAC 주소에 해당하는 (목적지 MAC)부분을 현재 서브넷의 라우터(게잍트웨이)로 설정한다.
만약 같은 서브넷 네에 존재하면 라우터 테이블을 확인하면 된다. 혹은 브로드캐스팅해서 목적지를 알아낼 수도 있다.
이렇게 서브넷을 거쳐서 목적지의 MAC 주소를 확인하는 과정을 ARP라고 한다.
이미 한 번 요청을 성공적으로 수행했던 서버라면 (그리고 시간이 얼마 되지 않음) ARP 캐시에서 ARP를 수행하지 않고 MAC 주소를 얻을 수 있다.
arp -a 명령어를 이용하면 된다.
6. 최종적으로 프레임을 전기 신호로 변경하여 전송을 시작한다. (여태까지는 다 가공)
1~5까지의 모든 과정은 통신을 할 수 있나 검증하고 이를 구성하는 단계였다.
서버까지 도달할 수 있는지, 서버의 실제 주소를 알 수 있는지 등을 조사했다.
이후, 프레임을 전기 신호로 변경하여 케이블 혹은 무선 랜을 통해 전송하면 모든 과정을 다 설명할 수 있게 된다. 하지만 아직 케이블 이후부터 허브 등등 LAN 기기들을 아직 다루지는 않았다 ㅎㅎ;
7. 느낀점
평소에 DB Connection pool에 대해 생성 비용이 비싸서... 라고 들었고 그냥 그런가보다 했다. 아무래도 뭔가 DB 연결이니 비싸겠지; 했는데 정말로 많은 과정이 들어가고 통신 초기 과정에서도 네트워크 통신이 들어가기 때문에 사용자 서비스를 만드는 데 매번 수행한다고 하면 불필요한 오버헤드가 클 것 같다.
References
성공과 실패를 결정하는 1%의 네트워크 원리
