
암호화 로직을 짜다가 인코딩을 마주쳤는데...
제가 유니코드, 인코딩 이런 개념을 아예 모른다는 사실을 깨달았습니다...
그래서 정리할 겸 블로그를 쓰게 되었어요...
그래서 유니코드가 뭔데?
유니코드를 알기 위해선 유니코드가 생겨난 역사를 알면 정말 바로 이해가 된다.
그래서 다시 역사를.. 거슬러 올라가보아요
🚨🚨 그리고 공부하면서 느낀건데 인코딩/디코딩 개념이 너무너무 헷갈렸다. 그래서 말하기 전까지 그냥 인코딩/디코딩 UTF-8 이런 것들은 생각하지 않는 게 더 나음. 실제로 언급하기 전까지 별 필요없기도 함. 🚨🚨
컴퓨터의 근원은 이진수
우리는 맨 처음에 컴퓨터로 많은 걸 하지 않았기에 2진수로 나타내면 그만이었다. 단순 연산 같은 경우 뭐 더 할 게 있나?
아스키코드로 문자를 정의함으로써 해결?
그러다가 컴퓨터로 문자를 표현해야 하는 상황이 왔다.
이때는 알파벳을 쓰는 나라에서만 컴퓨터를 사용했기 때문에 영어, 숫자, 몇 개의 특수문자만 정의하면 됐다. 그래서 7bit에 모든 문자를 정의하기로 했다.
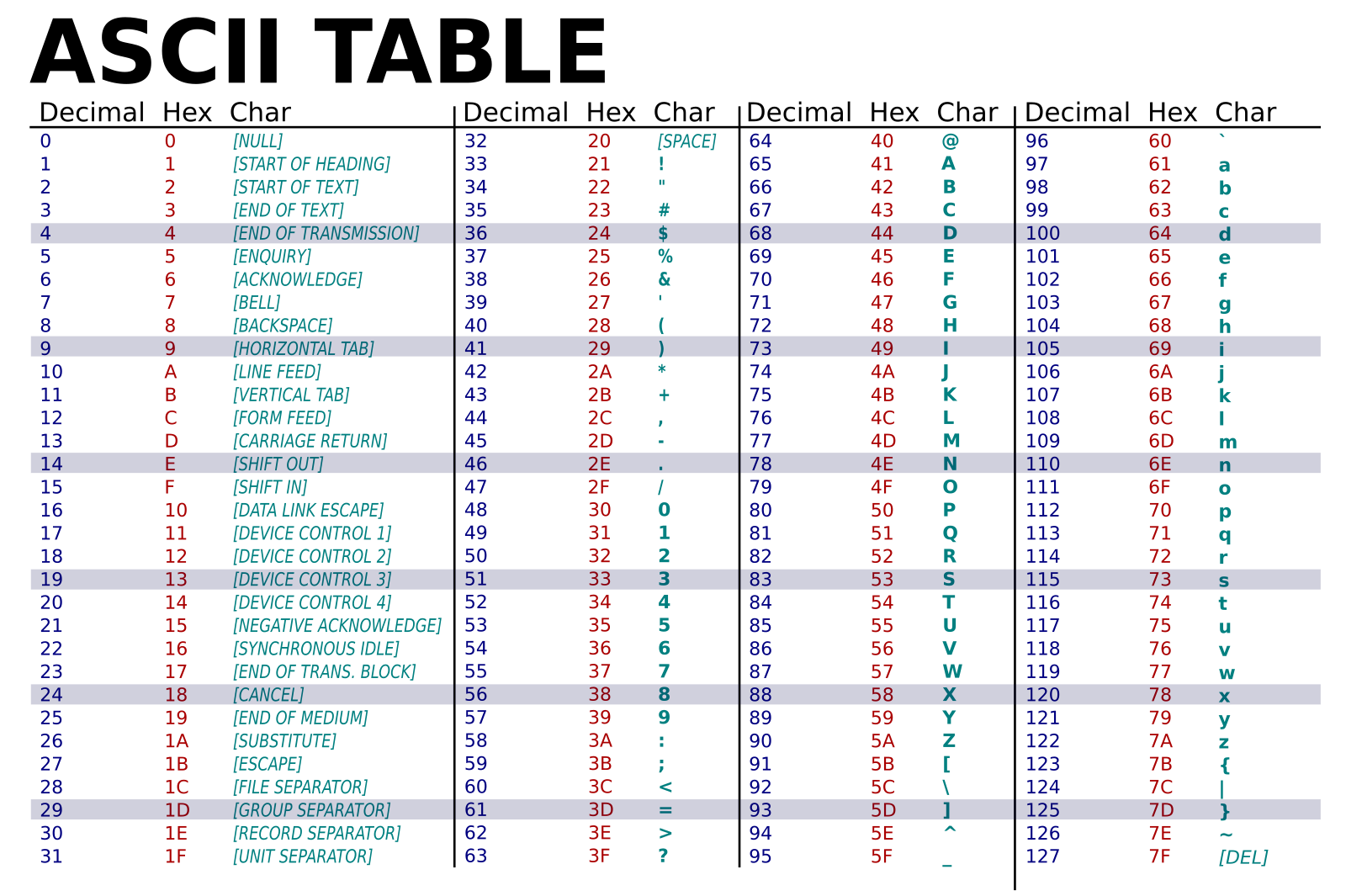
아스키 코드 표를 보면 7bit로 나타내기 때문에 2^7 = 128개
총 0번부터 127번까지 128개의 문자가 정의되어 있다.
근데 왜 7bit지 보통 1byte(8bit) 단위로 나누는데?
1bit는 패리티 코드를 위한 공간이다. 패리티 코드는 오류 검출을 위한 코드로, 7bit로 문자를 표현하고 1bit로 오류를 검출한다.
컴퓨터의 세계화
컴퓨터가 세계 각국으로 전해지면서, 영어(알파벳) 말고도 다른 문자를 표현해야됐다. 아스키코드 128개 가지고는 절대 할 수가 없었다.
그래서 만든 게 유니코드 였다.
유니코드가 뭔데 그래서?
유니코드는 단순히 한 문자를 코드 포인트로 정의한 것이다.
코드 포인트란?
만약에 '갑' 이라는 한글 문자가 있으면
유니코드로 U+AC11 이다.
이렇게 어떠한 문자에 유니코드를 부여한 것이다.
"안녕하세요" 라는 문장이 있다면?
안, 녕, 하, 세, 요 각각 다 유니코드가 있는 것임
근데 잘 모르겠어...
근데 솔직히 저렇게 말해도 잘 안 와닿는다.
원래 우리가 아스키코드를 7bit로 정의했었다.
근데 이걸로 다 정의가 안되니까 2byte(16bit)에 다 정의를 하자! 라는 게 유니코드의 출발 지점이었다.
2byte에 모든 유니코드를 다 넣자!
위에서 갑 이라는 문자를 유니코드로
U+AC11
로 표현했었다.
U+는 그냥 유니코드라는 걸 알려주는 부분이고 실제 문자는 AC11이다.
여기서 알 수 있 듯이 AC11은 각각 4bit씩 사용하는 16진수다.
A (16진수, 4bit) -> 1010
C -> 1100
1 -> 0001
1 -> 0001
위와 같이 1010 1100 0001 0001로 총 16bit로 표현됨.
근데 왜 16진수를 쓰지?
16진법은 장점이 매우 많은 진법이다.
16진수는 0~15까지 표현할 수 있고 즉 자릿수 하나가 16개의 수를 표현할 수 있다.
그럼 자릿수 2개를 사용하면 2^4 * 2^4로 즉 2^8(256개)을 표현할 수 있다는 것이다.
FF(16) = 1111 1111(2) = 255(10)
근데 2byte로는 무리야...
16진수 4개로 정의한다고 하면
4bit x 4 x 4 x 4 = 2^16 = 65536개로 대략 6만개의 문자를 나타낼 수 있는데
세상에 문자가 너무너무 많아서 이걸로 부족함!
그래서 우리는 유니코드를 4byte로 정의하기로 했어
그래서 유니코드는 최대 32bit이고 총 경우의 수를 다 따지면 2^32 (bit니까 0, 1 중 한 가지가 오기 때문) => 유니코드는 총 42억개 정의 가능!
근데 42억개는 또 너무 많음... 그래도 4byte로 정의했기 때문에 아직 남아있는 유니코드 코드포인트가 많다고 한다~ 인류 멸망할 때까지 다 안 채워질 듯 (42억개니깐...)
대부분의 문자는 위에서 말한 2byte로 가능하다.
여기서 BMP, SMP 등등 새로운 개념이 나옴.
BMP란?
위에서 말한 2byte까지의 유니코드가 BMP이다.
2byte(16bit)니까 2^16 = 65536
그니까 0~65535(0xFFFF)까지의 유니코드는 BMP에 속한다.
BMP(Basic Multilingual Plane)으로
기본적인 문자가 여기 다 할당됨
한국어도 여기 할당됨
BMP에 들어가지 않는 유니코드는?
SMP, SIP 등등 여러 Plane으로 정의된다. 유니코드는 평면(Plane)이라는 개념으로 정의됨. 궁금하면 위키 ㄱㄱ 아무튼 이모지나 뭐 약간 특수한 언어? 문자들은 BMP 이외의 평면에 정의된다.
그래 그래서 유니코드를 한번에 정리하면
세계 각국의 문자를 표현하기 위해서
최대 4byte를 할당하는 코드 포인트 모음 이라고 생각하면 된다.
대부분의 문자는 2byte로 다 정의 가능하고 (0~0xFFFF)
추가 문자들은 3byte, 4byte 내에 다 정의하고 있다.
그럼 인코딩은 뭐야?
위에서 계속 말한 유니코드를 그대로 4byte로 저장해서 사용해도 된다. 안되는 건 아님. 어차피 4byte로 정의했으니까, BMP(2byte로 정의 가능한 유니코드)도 그냥 4byte로 패딩 채워서 쓰면 된다.
-> 근데 그러면 메모리 사용량도 늘고 효율이 엄청 떨어짐
그래서 문자 인코딩이라는 개념이 생겼다.
유니코드랑 인코딩과의 관계
유니코드는 단순히 코드 포인트를 정의한 것이지 저장과는 딱히 상관이 없다.
🚨 이 유니코드를 어떻게 메모리에 저장하고 / 어떻게 네트워크로 전송할 지를 정의한 규칙이 바로 인코딩
고정 길이 인코딩
UTF-32가 고정 길이 인코딩이다.
위에서 내가
위에서 계속 말한 유니코드를 그대로 4byte로 저장해서 사용해도 된다. 안되는 건 아님. 어차피 4byte로 정의했으니까, BMP(2byte로 정의 가능한 유니코드)도 그냥 4byte로 패딩 채워서 쓰면 된다.
라고 한 게 사실 UTF-32 인코딩이다. 그냥 그 길이 그대로 쓴다고 해서 고정 길이 인코딩이라고 한다.
가변 길이 인코딩
만약에 "A"라는 문자를 유니코드로 표현하면 U+0041이다.
(16진수로 41이면 10진수로 65임. 아스키코드 'A'가 10진수로 65)
얘를 UTF-32로 인코딩한다면?
00000041(16진수)이다.
그럼 쓸데없이 패딩값으로 0000(2byte)를 갖고 있는 셈이다.
왜 그래야 되지?
=> 가변 길이 인코딩이 생겼다!
문자를 정의하는 데 필요한 크기를 매번 조절할 수 있게 되었다.
가변 길이 인코딩에 UTF-8/UTF-16이 있는데 자세한 변환 알고리즘은 따로 찾아보는 것이 좋을 듯하다...
GPT한테 물어봄
UTF-8
UTF-8: 1바이트에서 최대 4바이트까지 문자의 크기를 조절하는 가변 길이 인코딩 방식
ASCII 문자(예: 영어 알파벳, 숫자)는 1바이트만 사용해 표현돼.
자주 쓰이는 다른 문자들은 2바이트나 3바이트로 표현되고, 덜 자주 쓰이는 복잡한 문자는 최대 4바이트를 사용해 표현돼.
장점: 메모리와 전송 공간을 절약할 수 있어. 영어와 같은 문자들은 1바이트로 충분하니까 효율적이고, 문자 범위가 넓어지면 더 많은 바이트를 할당하는 방식이야.
예: 'A'는 U+0041 → 41(1바이트), '한'은 U+D55C → ED 95 9C(3바이트).
UTF-16
UTF-16: 문자마다 2바이트 또는 4바이트를 사용해 저장하는 방식
기본적으로 2바이트로 문자를 저장하지만, 유니코드 코드 포인트가 0xFFFF를 넘는 경우 4바이트로 저장해.
장점: 아시아권의 많은 문자들이 2바이트로 저장 가능해. 하지만 여전히 일부 문자는 4바이트가 필요할 수 있어.
UTF-8 vs. UTF-16 vs. UTF-32
UTF-8: 가변 길이(1~4바이트), ASCII와 호환, 저장 효율이 좋음.
UTF-16: 가변 길이(2 또는 4바이트), BMP 문자는 2바이트로 저장, 아시아 문자에 유리.
UTF-32: 고정 길이(4바이트), 모든 문자를 4바이트로 표현, 메모리 낭비가 있을 수 있음.
