SQL syntax
SQL commads
- DDL(Data Definition Language)
- 데이터 정의 언어 : 관계형 데이터베이스를 구조(테이블, 스키마)를 정의(생성, 수정 및 삭제)하기 위한 명령어
- ex) CREATE, DROP, ALTER
- DML(Data Manipulation Language)
- 데이터 조작 언어 : 데이터를 조작(추가, 조회, 변경, 삭제) 하기 위한 명령어
- ex) INSERT, SELECT, UPDATE, DELETE
- DCL(Data Control Language)
- 데이터 제어 언어 : 데이터의 보안, 수행제어, 사용자 권한 부여 등을 정의하기 위한 명령어
- ex) GRANT, REVOKE, COMMIT, ROLLBACK
[DDL INDEX]
[CREATE TABLE]

데이터 타입 종류
- NULL
- NULL value
- 정보가 없거나 알 수 없음을 의미
- INTEGER
- 정수
- 크기에따라 0,1,2,3,4,6 또는 8바이트 같은 가변 크기를 가짐
- REAL
- 실수
- 8바이트 부동 소수점을 사용하는 10진수 값이 있는 실수
- TEXT
- 문자 데이터
5.BLOB(Binary Large Object)
- 입력된 그대로 저장된 데이터 덩어리(대용타입 없음)
- 바이너리 등 멀티미디어 파일
- ex) 이미지 데이터
- Boolean type
- SQLite에는 별도의 Boolean 타입이 없음
- 대신 정수 0(False)와 1(True)로 저장됨
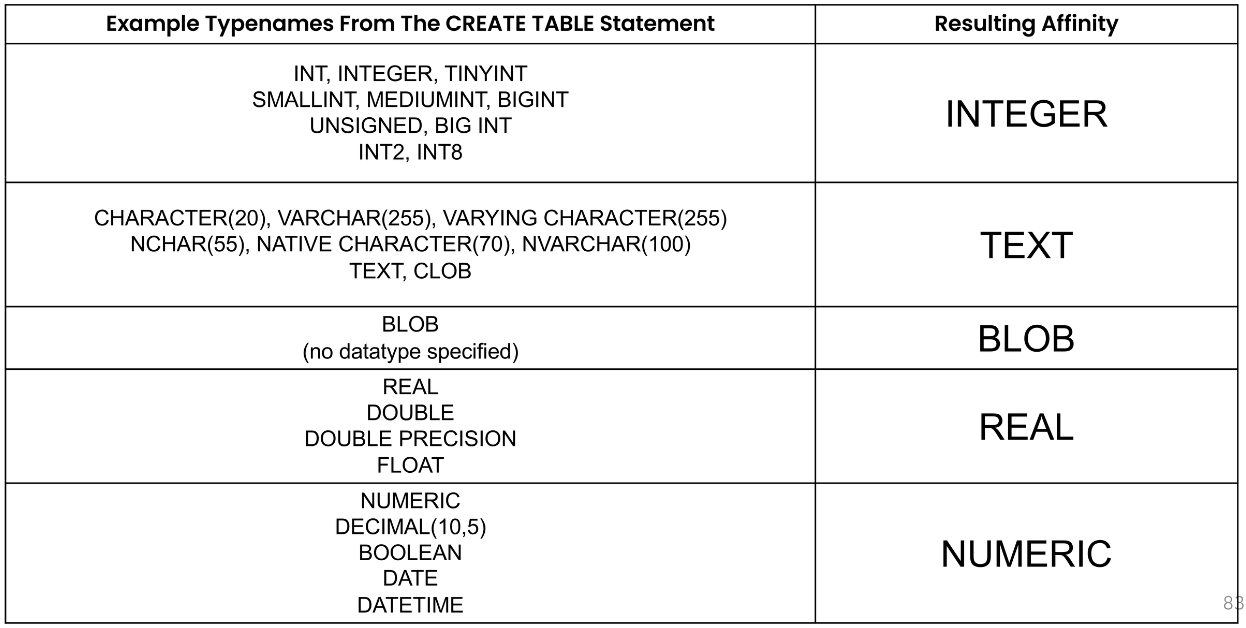
타입 선호도(Type Affinity)
- 특정 컬럼에 저장된 데이터에 권장되는 타입
- 데이터 타입 작성 시 SQLite의 5가지 데이터 타입이 아닌 다른 데이터 타입을 선언한다면, 내부적으로 각 타입의 지정된 선호도에 따라 5가지 선호도로 인식됨
- INTEGER
- TEXT
- BLOB
- REAL
- NUMERIC
- 다른 데이터베이스 엔진 간의 호환성을 최대화
- 정적이고 엄격한 타입을 사용하는 DB의 SQL문을 SQLite에서도 작동하도록 하기 위함
제약조건(Constraints)
- 입력하는 자료에 대해 제약을 정함
- 제약에 맞지 않다면 입력이 거부됨
- 사용자가 원하는 조건의 데이터만 유지하기 위한 즉, 데이터의 무결성을 유지하기 위한 보편적인 방법으로 테이블의 특정 컬럼에 설정하는 제약
- 데이터 무결성이란? DB내의 데이터에 대한 정확성, 일관성을 보장하기 위해 데이터 변경 혹은 수정 시 여러 제한을 두어 데이터의 정확성을 보증하는 것
Constraints 종류
- NOT NULL
- 컬럼이 NULL 값을 허용하지 않도록 지정
- 기본적으로 테이블의 모든 컬럼은 NOT NULL을 명시하지 않는 경우 NULL 값을 허용
- UNIQUE
- 컬럼의 모든 값이 서로 구별되거나 고유한 값이 되도록 함
- PRIMARY KEY
- 테이블에서 행의 고유성을 식별하는 데 사용되는 컬럼
- 각 테이블에는 하나의 기본 키만 있음
- 암시적으로 NOT NULL 제약조건이 포함되어있음
- AUTOINCREMENT
- 사용되지 않은 값이나 이전에 삭제된 행의 값을 재사용하는 것을 방지
- INTEGER PRIMARY KEY 다음에 작성하면 해당 rowid를 다시 재사용하지 못하도록 함
rowid의 특징
- 테이블을 생성할 때마다 rowid라는 암시적 자동 증가 컬럼이 자동으로 생성됨
- 테이블의 행을 고유하게 식별하는 64비트 부호있는 정수 값
- 테이블 새 행을 삽입할 때마다 정수 값을 자동으로 할당
- 값은 1에서 시작
- 데이터 삽입 시에 rowid 또는 INTEGER PRIMARY KEY 컬럼에 명시적으로 값이 지정되지 않은 경우, SQLite는 테이블에서 가장 큰 rowid보다 하나 큰 다음 순차 정수를 자동으로 할당(AUTOINCREMENT와 관계없이)
- 만약 INTEGER PRIMARY KEY 키워드를 가진 컬럼을 직접 만들면 이 컬럼은 rowid 컬럼의 별칭(alias)이 됨
[ALTER TABLE]
- 기존 테이블의 구조를 수정
- RENAME a table
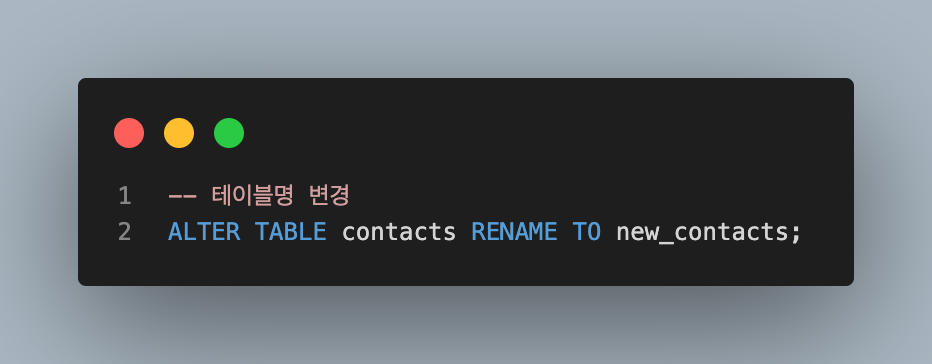
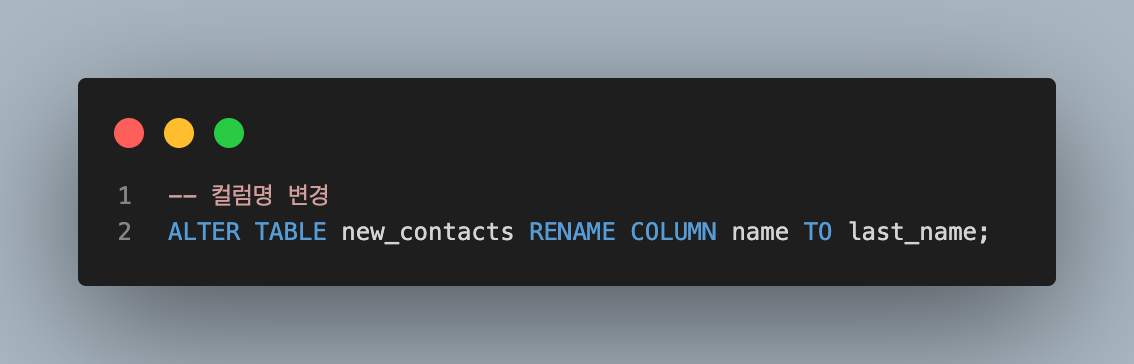
- RENAME a column
- ADD a new column to a table
- DELETE a column
RENAME a table
RENAME a column
ADD a new column to a table
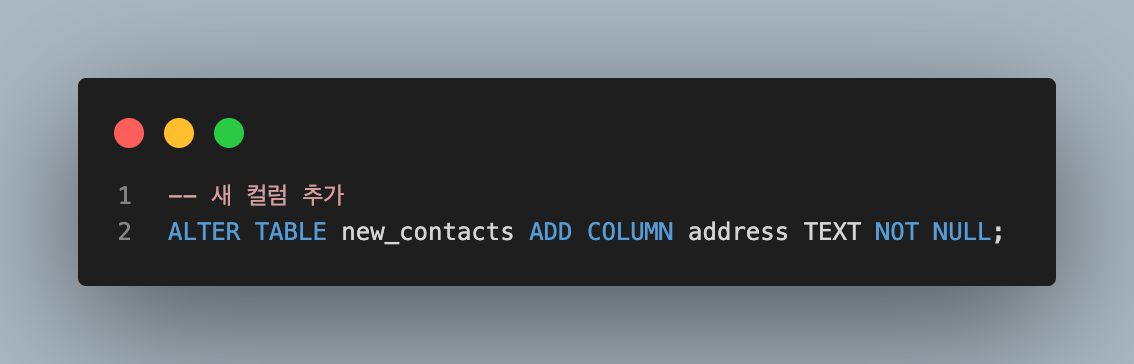
- 만약 테이블에 기존 데이터가 있을 경우 다음과 같은 에러가 발생함
Cannot add NOT NULL column with default value NULL- 이미 이전에 저장된 데이터들은 새롬게 추가되는 컬럼에 값이 없기 때문에 NULL이 작성됨 ➡️ 그런데 새로 추가되는 컬럼에 NOT NULL 제약조건이 있기 때문에 기본 값 없이는 추가될 수 없다는 에러
- 위의 경우 다음과 같이 DEFAULT 제약 조건을 사용하여 해결 할 수 있음
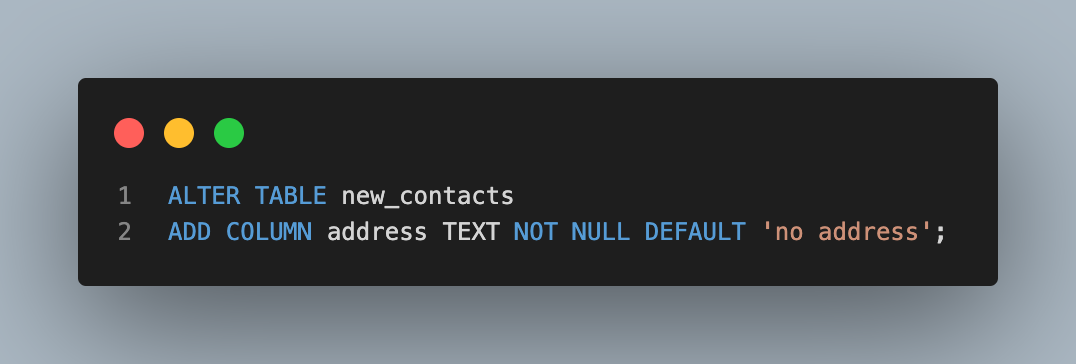
- 이러면 address 컬럼이 추가되면서 기존에 있던 데이터들의 address 컬럼 값은 'no address'가 된다.
DELETE a column
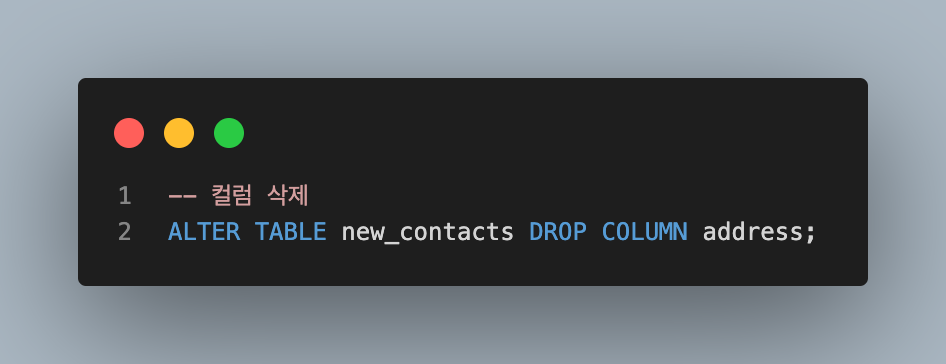
아래와 같은 경우 삭제하지 못함
- 컬럼이 다른 부분에서 참조되는 경우(FK 제약조건에서 사용되는 경우)
- PK인 경우
- UNIQUE 제약조건이 있는 경우
[DROP TABLE]

- 한 번에 하나의 테이블만 삭제 사능
- DROP TABLE문은 실행 취소하거나 복구할 수 없음
[DML]
csv 파일 데이터를 테이블로 넣는 작업
- csv 파일 속 데이터 형식과 맞게 테이블 생성

- 데이터베이스 파일 열기
$ sqlite3 mydb.sqlite3 # mydb부분에 원하는 파일 이름- 모드를 csv로 설정
$ .mode csv- .import 명령어 사용하여 csv데이터를 테이블로 가져오기
$ .import users.csv users- .import (csv파일 명) (테이블 명)
[Simple query]
- SELECT문을 사용해 단일 테이블 데이터 조회
- 다양한 절과 함께 사용할 수 있다.(ORDER BY, DISTINCT, WHERE, LIMIT, LIKE, GROUP BY)
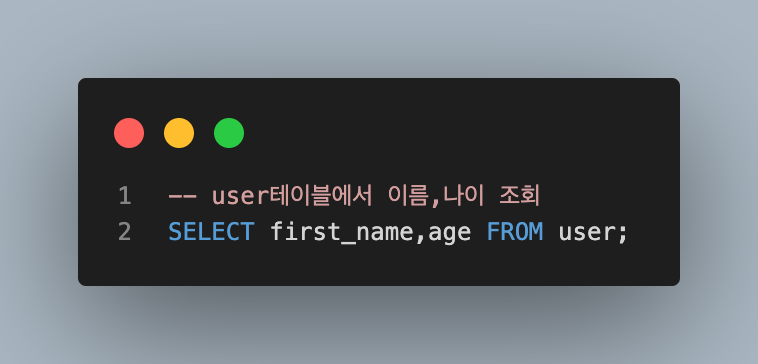
사용 예시
- 이름과 나이 조회
- 전체 데이터 조회

[Sorting rows]
- ORDER BY 절을 사용하여 쿼리의 결과를 정렬하기
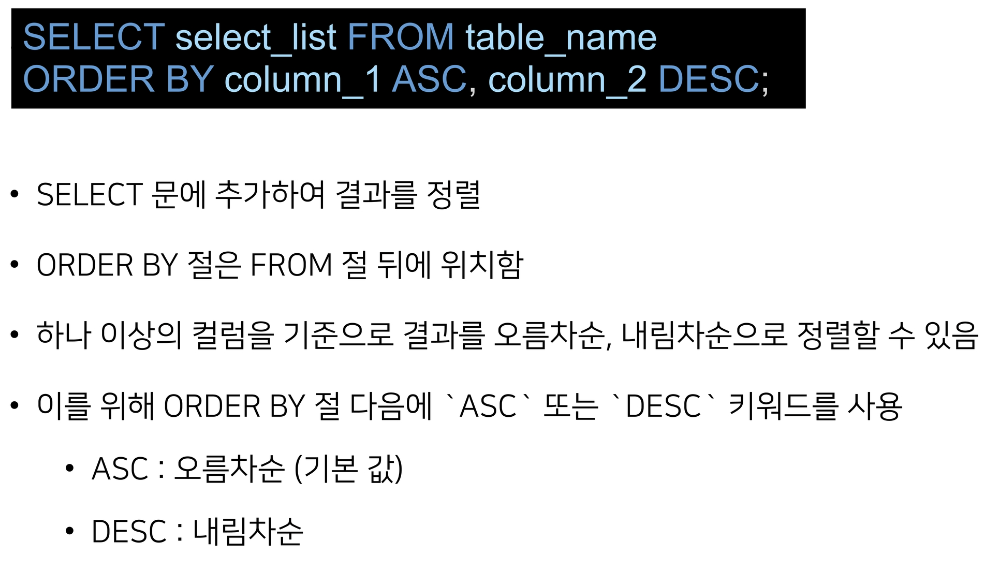
사용 예시
- 이름과 나이를 나이가 어린 순서대로 조회
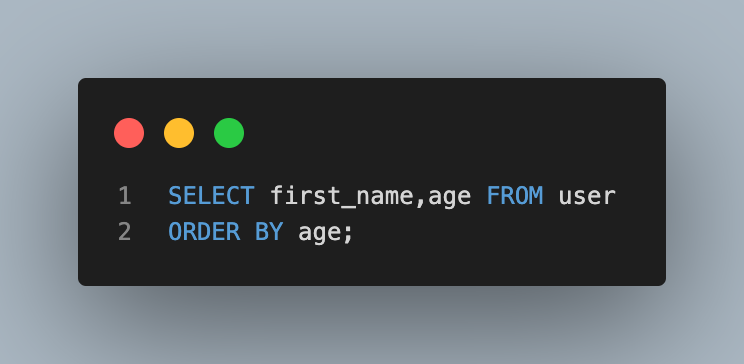
- ORDER BY의 default가 오름차순이라 아무것도 쓰지 않아도 괜찮다. (뒤에 ASC를 붙여도 무방함)
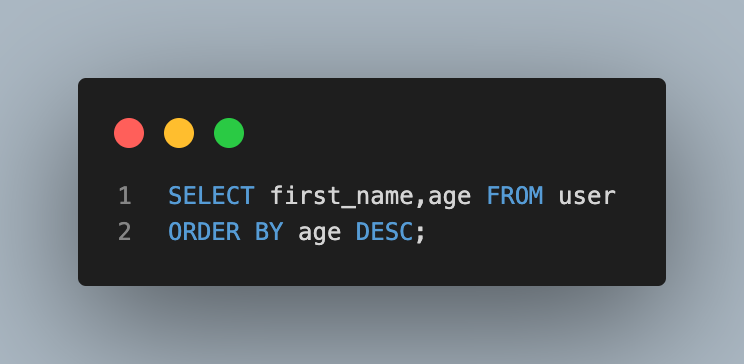
- 이름과 나이를 나이 많은 순서대로 조회(내림차순)
- 이름,나이,계좌 잔고를 나이가 어린 순으로, 만약 같은 나이라면 계좌 잔고가 많은 순으로 정렬해서 조회
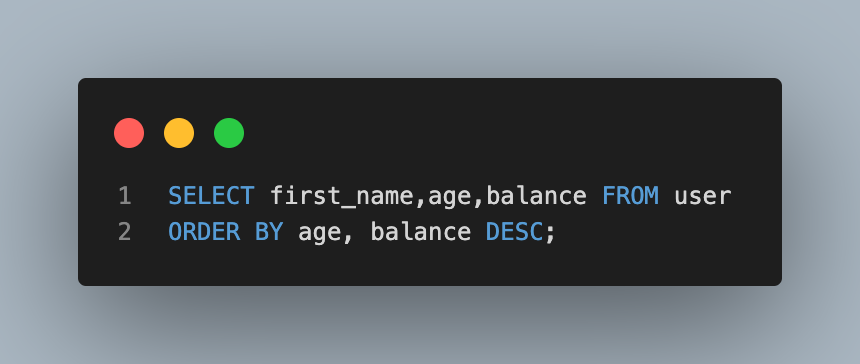
- 먼저 나오는 순서대로 정렬 우선순위를 가짐
NULL의 정렬 방식
- 정렬과 관련하여 SQLite는 NULL을 다른 값보다 작은 것으로 간주
- 즉, ASC를 사용하는 경우 결과의 시작 부분에 NULL이 표시되고, DESC를 사용하는 경우 결과의 끝에 NULL이 표시됨
[Filtering data]
- Clause
- SELECT DISTINCT
- WHERE
- LIMIT
- Operator
- LIKE
- IN
- BETWEEN
SELECT DISTINCT
- 조회결과에서 중복된 행을 제거
- DISTINCT 절은 SELECT 에서 선택적으로 사용할 수 있는 절
- DISTINCT절은 SELECT 키워드 바로 뒤에 나타나야 함 & DISTINCT 키워드 뒤에 컬럼 또는 컬럼 목록을 작성
사용 예시
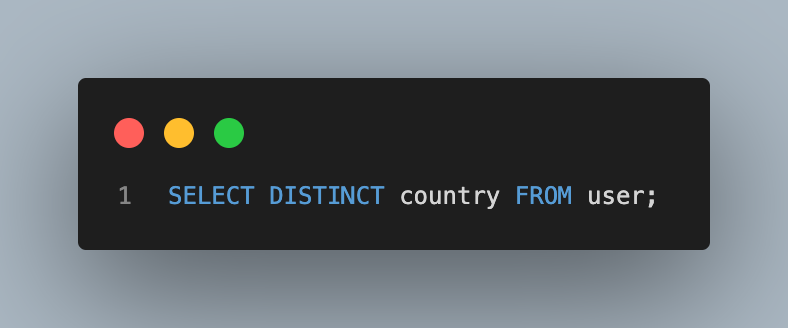
- 중복 없이 모든 지역 조회
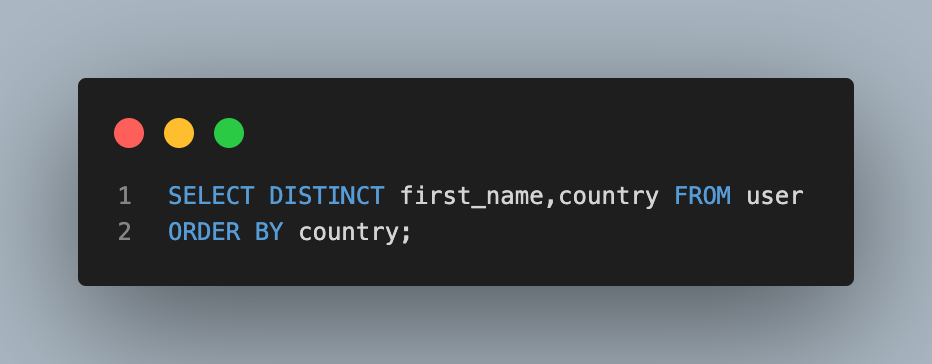
- 이름과 지역 중복 없이 지역순으로 오름차순 정렬하여 모든 이름과 지역 조회하기
WHERE
- 조회 시 특정 검색 조건을 지정
- WHERE 절은 SELECT, UPDATE, DELETE 문에서 선택적으로 사용 할 수 있는 절
- FROM 절 뒤에 작성


사용 예시
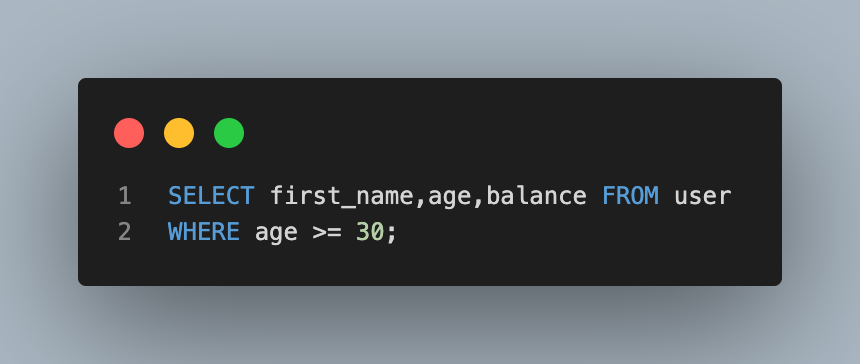
- 나이가 30살 이상인 사람들의 이름, 나이, 계좌 잔고 조회
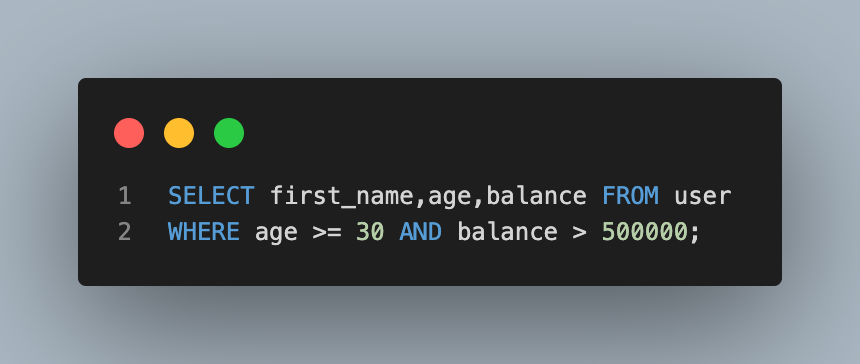
- 나이가 30살 이상이고 계좌 잔고가 50만원 초과인 사람들의 이름,나이,계좌 잔고 조회
LIKE
- 패턴일치를 기반으로 데이터를 조회
- WHERE 절에서 사용
- 기본적으로 대소문자는 구분하지 않음
- SQLite는 패턴 구성을 위한 두개의 와일드카드를 제공
- % (percent)
- 0개 이상의 문자가 올 수 있음을 의미

- _ (underscore)
- 단일(1개) 문자가 있음을 의미

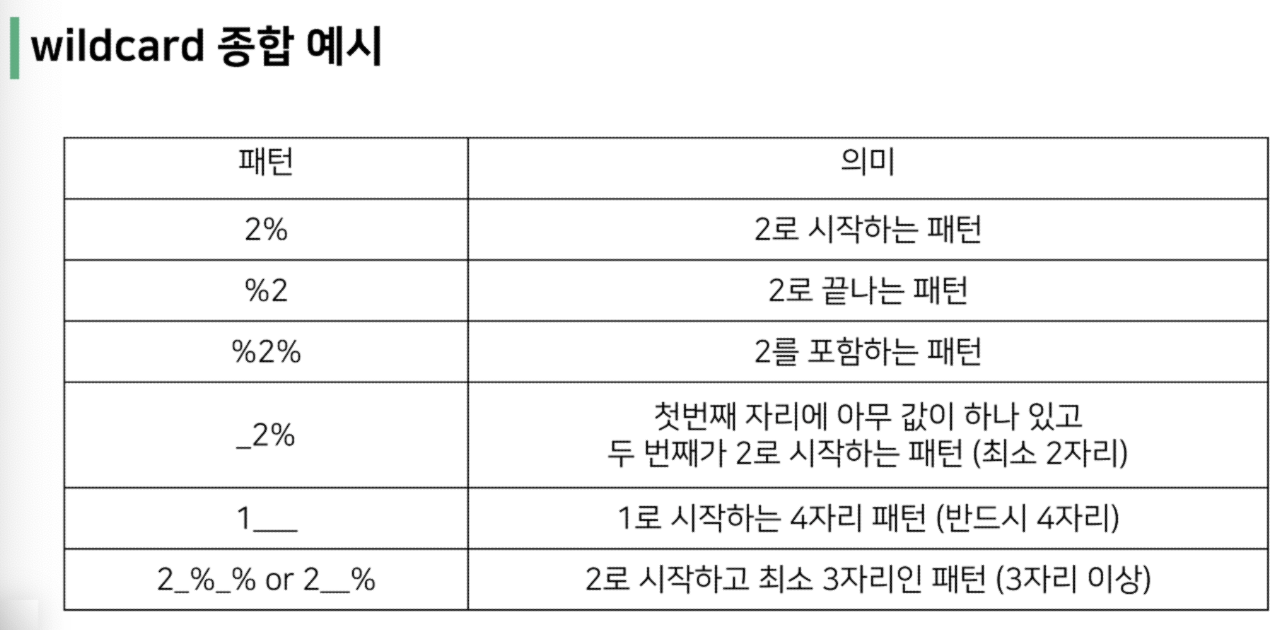
사용 예시
- 이름에 '호'가 포함되는 사람들의 이름과 성 조회
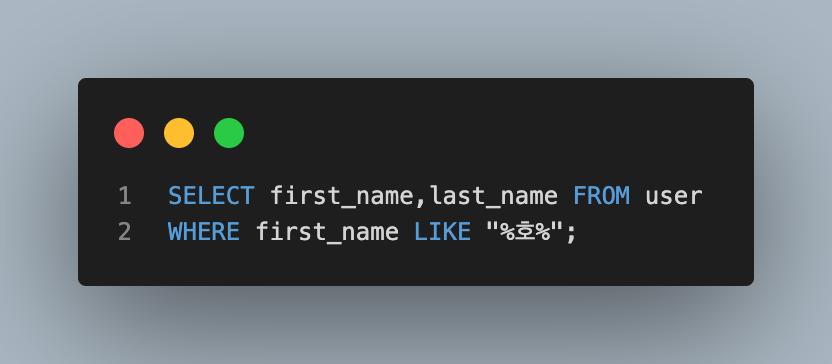
- 서울 지역 번호를 가진 사람들의 이름과 전화번호 조회
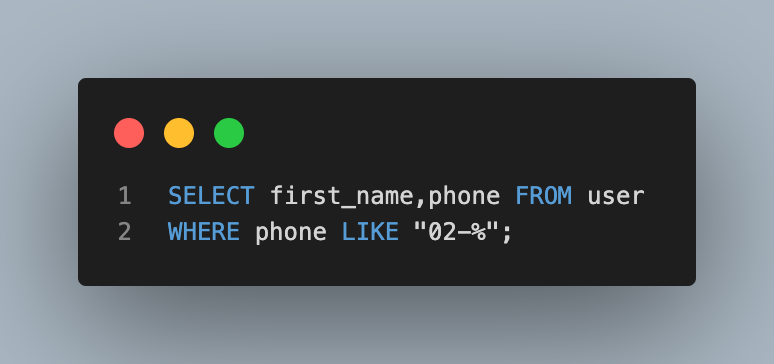
- 나이가 20대인 사람들의 이름과 나이 조회하기
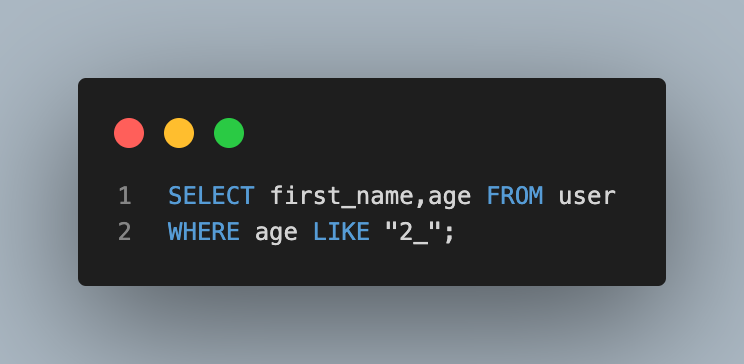
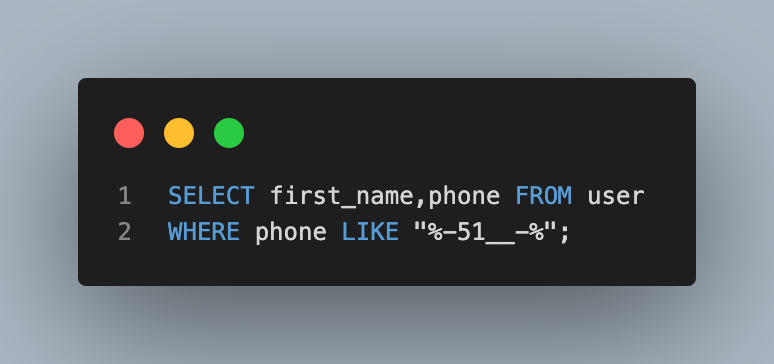
- 전화번호 중간 4자리가 51로 시작하는 사람들의 이름과 전화번호 조회
[IN operator]
- 값이 값 목록 결과에 있는 값과 일치하는지 확인
- 표현식이 값 목록의 값과 일치하는지 여부에 따라 T/F를 반환
- IN 연산자의 결과를 부정하려면 NOT IN 연산자를 사용
사용 예시
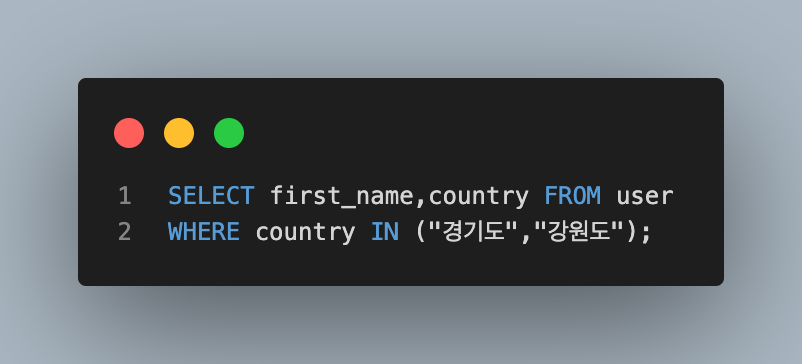
- 경기도 혹은 강원도에 사는 사람들의 이름과 지역 조회하기
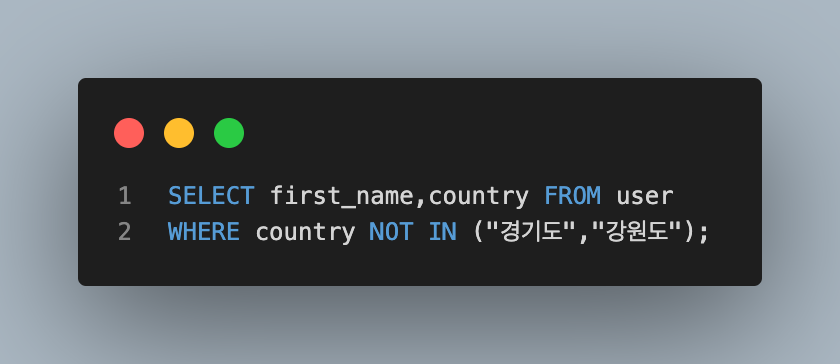
- 경기도 혹은 강원도에 살지 않는 사람들의 이름과 지역 조회하기
[BETWEEN operator]
- 값이 값 범위에 있는지 테스트
- 값이 지정된 범위에 있으면 True
- WHERE 절ㅇ레서 사용
- BETWEEN 연산자의 결과 부정 ➡️ NOT BETWEEN 사용
사용 예시
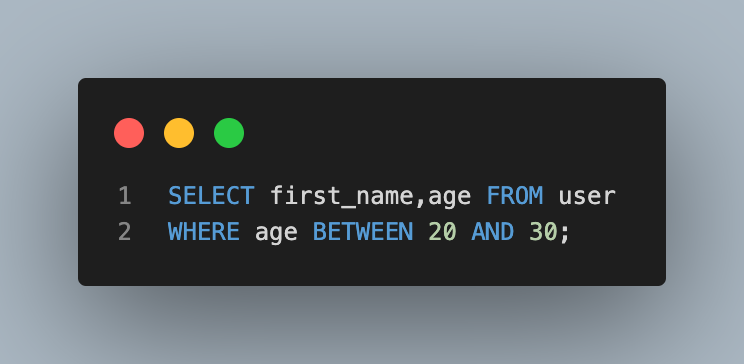
- 나이가 20살 이상, 30살 이하인 사람들의 이름과 나이 조회
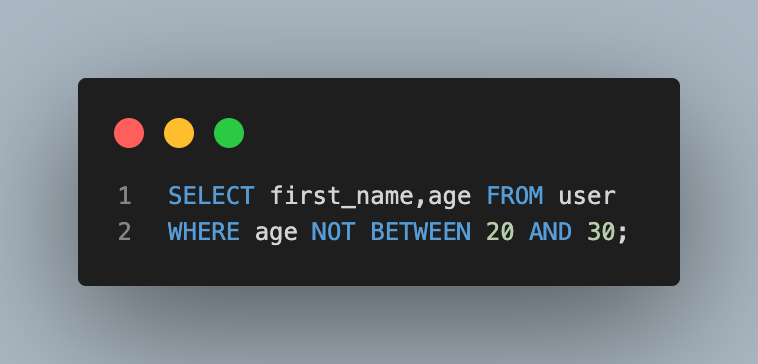
- 나이가 20살 이상, 30살 이하가 아닌 사람들의 이름과 나이 조회하기
[LIMIT clause]
- 쿼리에서 반환되는 행 수를 제한
- SELECT문에서 선택적으로 사용할 수 있는 절
- row_count는 반환되는 행 수를 지정하는 양의 정수를 의미
사용 예시
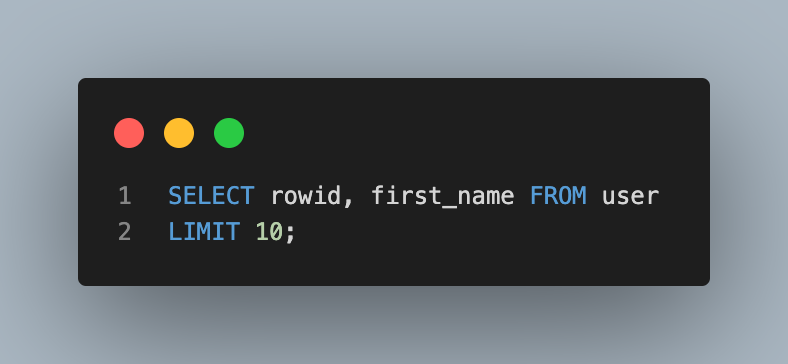
- 첫 번쨰부터 열 번째 데이터까지 rowid와 이름 조회하기
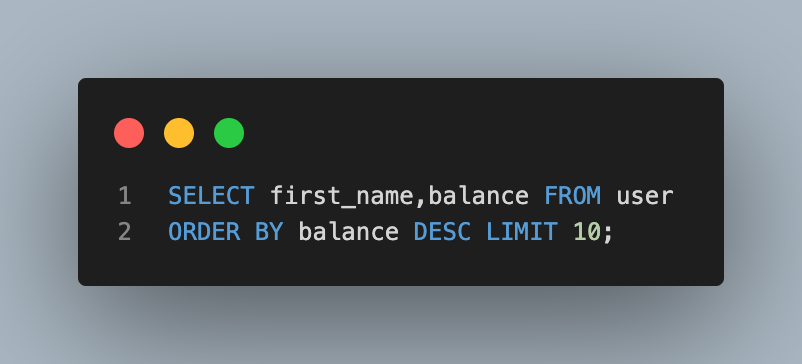
- 계좌잔고가 가장 많은 10명의 이름과 계좌잔고 조회
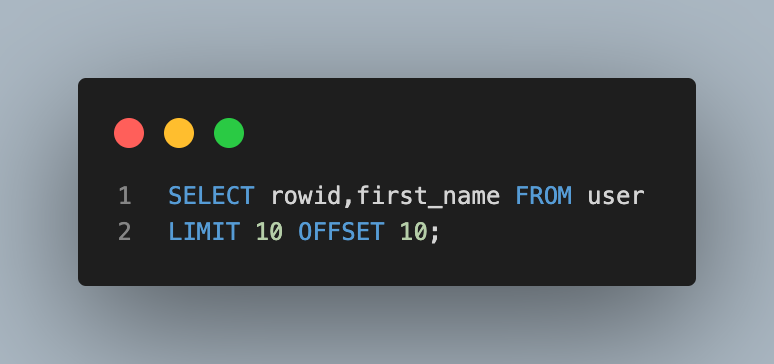
[OFFSET keyword]
- LIMIT 절을 사용하면 첫번쨰 데이터부터 지정한 수 만큼의 데이터를 받아올 수 있지만, OFFSET과 함께 사용하면 특정 지정된 위치에서부터 데이터를 조회할 수 있음
사용 예시
- 11번째부터 20번쨰 데이터의 rowid와 이름 조회