문제
100만 유저가 저장된 DB에서 닉네임 일치 조건으로 유저 조회하기
데이터 생성
JPA Batch Insert?
JPA 에서는 Batch Insert 를 지원하지 않는다
100만건을 일일히 생성하면 당연히 INSERT 쿼리도 100만건 발생하기 때문에 시간이 오래 걸린다.
JPA 의 saveAll() 을 사용한다고 해도, 내부에서는 반복문을 돌며 각 엔티티를 persist()하기 때문에 결국 개별 쿼리가 다수 발생한다.
또한 엔티티의 ID 생성 전략이 GenerationType.IDENTITY 인 경우, JPA에서는 (Hibernate 에서는) batch insert를 지원하지 않는다.
그러므로 JDBC Template+Bulk insert 를 이용하여 대량의 데이터를 하나의 쿼리로 묶어 처리하는 방법을 채택하였다.
그리고 엔티티로 데이터를 저장하면 ORM 변환 단계에서 또 시간이 걸리므로 JPQL 을 사용하여 바로 쿼리를 날리는 방법을 사용하였다.
✅ JDBC Template + Bulk insert
Bulk insert
Bulk insert로 대량의 데이터를 하나의 쿼리로 처리할 수 있다.
예시를 들자면
INSERT INTO table VALUES ('kim', 20, 'USER');
INSERT INTO table VALUES ('lee', 30, 'USER');
...
INSERT INTO table VALUES ('park', 40, 'USER');
이 각각의 쿼리를
INSERT INTO table VALUES ('kim', 20, 'USER'),
('lee', 30, 'USER'),
...
('park', 40, 'USER');
이렇게 데이터만 달리하여 하나의 쿼리로 묶어서 INSERT 작업을 수행한다. (Bulk insert)
설정
application.properties
spring.datasource.url=jdbc:mysql://localhost:3306/DBname?rewriteBatchedStatements=truemysql 사용 시 DB 설정에서 rewriteBatchedStatements=true 를 활성화 한다.
테스트 데이터 생성 코드
@SpringBootTest
public class CreateDummyData {
@Autowired
JdbcTemplate jdbcTemplate;
@Autowired
EntityManager em;
@Test
@DisplayName("100만건 더미 테스트 데이터 생성")
void batchCreateDummyData() {
String INSERT_SQL = "INSERT INTO users (created_at, image_id, modified_at, email, nickname, password, user_role)" +
" VALUES (?, ?, ?, ?, ?, ?, ?)";
int BATCH_SIZE = 1000;
int TOTAL = 1000000;
System.out.println("START INSERT !!!");
for(int i=0; i<TOTAL/BATCH_SIZE; i++) {
System.out.println("NOW BATCH : "+i);
jdbcTemplate.batchUpdate(INSERT_SQL, new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
ps.setTimestamp(1, Timestamp.valueOf(LocalDateTime.now()));
ps.setNull(2, Types.BIGINT);
ps.setTimestamp(3, Timestamp.valueOf(LocalDateTime.now()));
ps.setString(4, UUID.randomUUID()+"@email.com");
ps.setString(5, "name"+UUID.randomUUID());
ps.setString(6, "pw"+UUID.randomUUID());
ps.setString(7, UserRole.USER.name());
}
@Override
public int getBatchSize() {
return BATCH_SIZE;
}
});
}
}
}
먼저 INSERT 쿼리문을 작성해준다.
이때 모든 속성을 다 포함할 필요는 없으며, nullable = false가 아닌 필드라면 생략해도 괜찮다.
ID 값의 경우 GenerationType.IDENTITY 전략을 사용하므로, 쿼리에서 비워두면 DB에서 자동으로 생성된다.
setValues() 메서드에서는 INSERT문의 파라미터 순서에 맞춰 값을 세팅해준다.
getBatchSize() 메서드에서는 설정한 값만큼의 데이터를 모아,
INSERT 쿼리 하나에 여러 건의 데이터를 구성하여 한 번에 실행하게 된다.
이 과정을 총 (전체 데이터 수 / 배치 사이즈)만큼 반복하면 된다.
따라서, 예를 들어 100만건 생성 시 배치 사이즈가 1000일 때 INSERT 쿼리 하나에 1000개의 데이터(VALUES)가 들어가며, 총 1000개의 쿼리가 나간다.
실행 결과
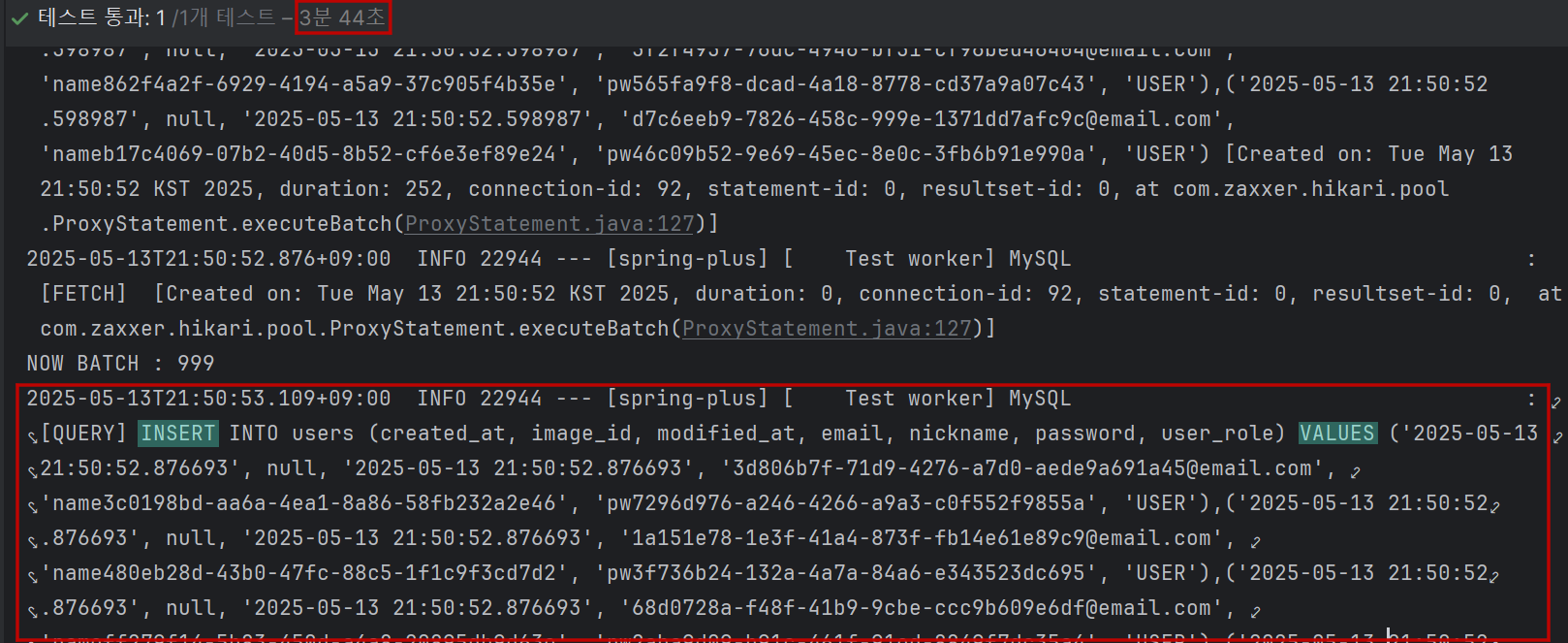
테스트 데이터 100만건 생성에 약 3분 44초 걸렸으며, INSERT 쿼리 하나에 여러개의 데이터가 들어간 것을 확인할 수 있다.
조회 성능 개선
이제 데이터를 생성하였으니 본격적인 조회 성능 개선으로 들어가보겠다.
실행 시간 측정
AOP 를 사용하여 조회 메소드 실행 시간을 측정한다. AOP 구현은 따로 글로 정리해두었다.
개선 전
2025-05-14T01:44:42.905+09:00 INFO 24100 --- [spring-plus] [ Test worker] o.e.e.aop.ExecutionTimeLoggingAspect : END EXECUTION: execution(ResponseEntity org.example.expert.domain.user.controller.UserController.findByNickname(String)) / TIME: 2264 ms개선 전 성능 : 2264 ms
개선 방법
이걸 이제 줄이는 방법을 생각해보자
캐싱은 동일한 요청이 여러번 들어왔을 때의 가정이니까 적합하진 않은 것 같고
일단 기본 조회 성능은 하나씩 차례로 찾아가는 O(N) 성능
더줄일려면? O(log N) < 이걸로 줄이는게?
아근데 유저 목록이니까 하나를 찾는게 아니구나
탐색알고리즘을 SQL에는 적용 못하나
근데 인덱스처럼 정렬된걸 찾는게 아니니까
- 인덱스 설정
- 전체 사이즈를 N개로 쪼갠 후 병렬 스레드 실행 (분할 정복?) 하여 응답?
참고
